Paper Reading:Wide & Deep Learning for Recommender Systems
本篇是论文Wide & Deep Learning for Recommender Systems的阅读笔记,这是谷歌的一篇发表在2016的论文。
ABSTRACT
对于解决regression和classification问题,有两类方法,一种是wide的一种是deep的。wide,通常是linear model,输入特征很多,带有能够实现非线性的交叉特征(所以wide。)。deep,主要就是基于神经网络的模型啦。
任何事情都有两面性,有利就有弊。wide的模型有什么好处呢?特征之间是如何相互作用的,是一目了然的,也就是可解释性好。缺点呢?特征工程很费劲,而且历史数据中没有的模式是学不到的。deep的模型有什么好处呢?更加general,可以学到一些没见过的特征组合(因为是基于对query和item做embedding的)。缺点呢?过分general了,可能会推荐出一些不相关的东西。
这篇论文提出的模型,就是把wide的模型和deep的模型融合到一起,让两种模型相互制约,取两种模型的优点。
如何融合?如何联合训练?为什么效果比单独的linear model或者deep model效果好。是这篇论文最值得研究的点。
这篇论文还从工程的角度,描述了如何部署,这也是值得学习借鉴的。
INTRODUCTION
这个部分作者进一步解释了abstract中提到的几个点。
One challenge in recommender systems, is to achieve both memorization and generalization.
对于memorization和generalization,论文中中有解释:
Memorization can be loosely defined as learning the frequent co-occurrence of items or features and exploiting the correlation available in the historical data.
Generalization, on the other hand, is based on transitivity of correlation and explores new feature combinations that have never or rarely occurred in the past.
我理解,memorization就是总结过去,generalization就是发现未知
This paper present the Wide & Deep learning framework to achieve both memorization and generalization in one model, by jointly training a linear model component and a neural network component.
RECOMMENDER SYSTEM OVERVIEW
这里作者对推荐系统做了介绍,言简意赅。
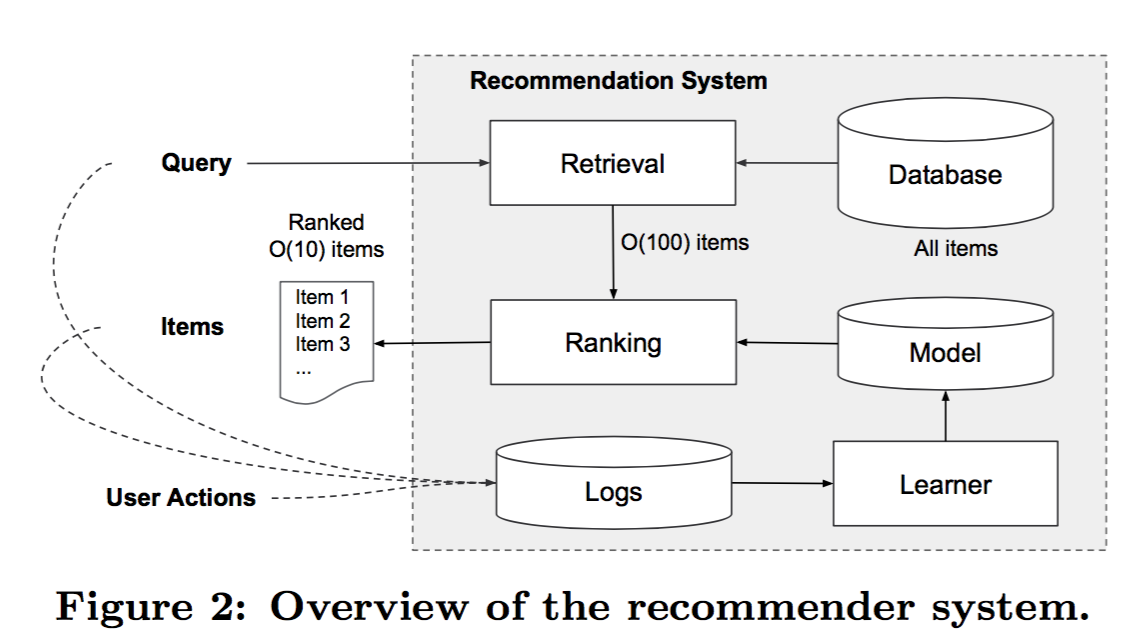
首先是retrieval过程,因为候选实在太多了,不能每个都计算个分值,所以先筛选,缩小候选集合,这一步通常是通过简单的模型或者规则完成。
接下来是rank,给候选一个分值。
WIDE & DEEP LEARNING
接下来就介绍这模型到底是怎么构建的了。
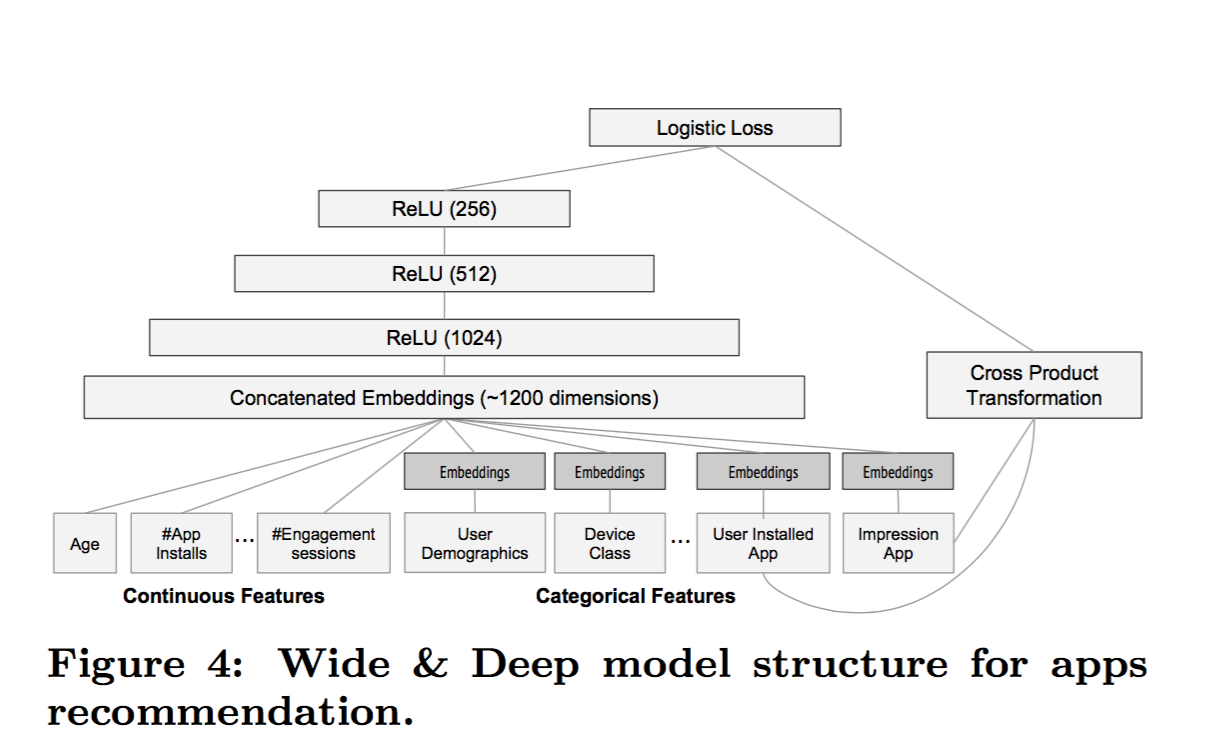
1,the wide component
线性模型,通过cross-product产生交叉特征
2,the deep compoent
feed-forward neural network
上面的图展示的比较清楚,连续特征直接输入,category特征进行embedding。
3,join training

损失函数采用的是log-loss.
对于wide部分,采用的是FTRL with L1正则作为优化方法,deep部分采用的是AdaGrad.
SYSTEM IMPLEMENTATION
这部分讲述了一些构建和部署模型的细节,有几个点比较有意思
1,data gengeration
对categorical的特征映射到ID,对连续特征映射通过它的累计分布映射到0-1
2,model traing
这里categorical特征映射到一个32维的embedding,然后与连续特征拼接到一起,构成一个大概1200维的向量
这里有一个值得注意的,对于新来的数据,论文采用一种warm-starting的方法,用原来的模型的embeding和linear模型的参数作为新模型的起始参数。
3,model serving
服务时间低于10ms,并行。
EXPERIMENT RESULT
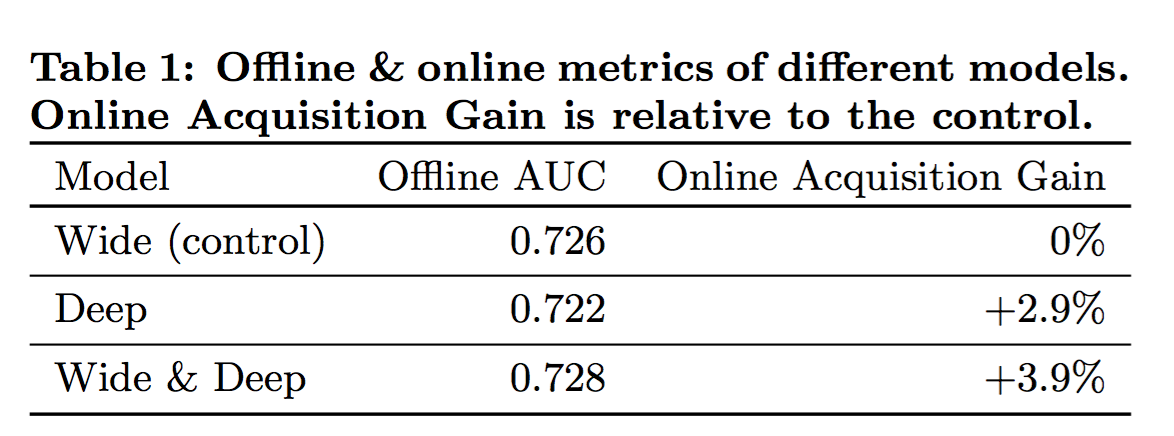
从实验上看,离线的AUC,深度学习的不如linear model,wide&deep最好,在线的效果更加突出。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号