day18 正则表达式和re模块
一、复习
# 超过最大递归限制的报错
# 只要写递归函数,必须要有结束条件。
# 返回值
# 不要只看到return就认为已经返回了。要看返回操作是在递归到第几层的时候发生的,然后返回给了谁。
# 如果不是返回给最外层函数,调用者就接收不到。
# 需要再分析,看如何把结果返回回来。
# 斐波那契 # 问第n个斐波那契数是多少
def fib(n): if n == 1 or n==2: return 1 return fib(n-1) + fib(n-2) print(fib(50))
def fib(n,l = [0]): l[0] +=1 if n ==1 or n == 2: l[0] -= 1 return 1,1 else: a,b = fib(n-1) l[0] -= 1 if l[0] == 0: return a+b return b,a+b print(fib(8))
def fib(n,a=1,b=1): if n==1 : return a return fib(n-1,b,a+b) print(fib(8))
阶乘:
def fac(n): if n == 1 : return 1 return n * fac(n-1) print(fac(10))
二、正则表达式——对字符串的匹配操作
判断手机号是否合法:
import re phone_number = input('please input your phone number : ') if re.match('^(13|14|15|18)[0-9]{9}$',phone_number): print('是合法的手机号码') else: print('不是合法的手机号码')
在线测试工具 http://tool.chinaz.com/regex/
检测工具(可复制代码):https://regex101.com/
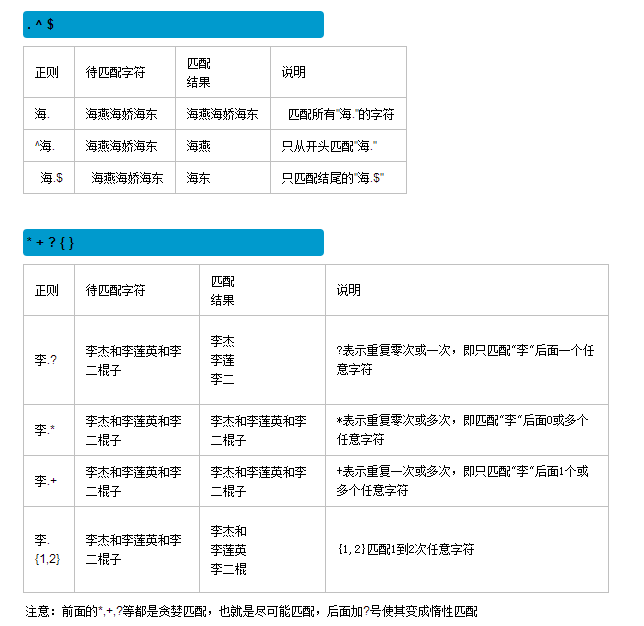
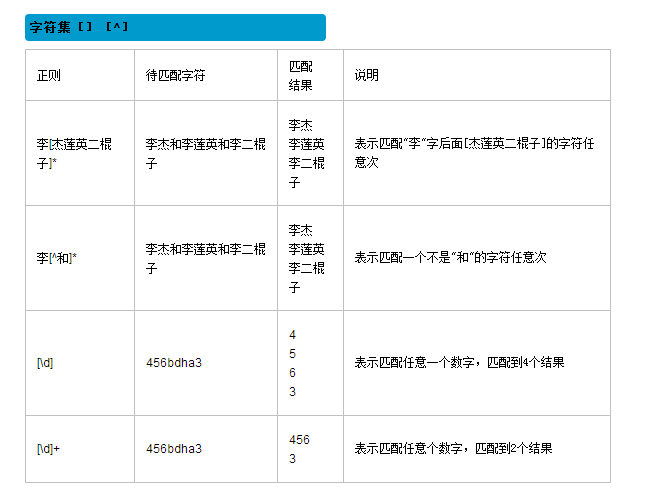
1、字符组:
字符组 : [字符组] 在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示 字符分为很多类,比如数字、字母、标点等等。 假如你现在要求一个位置"只能出现一个数字",那么这个位置上的字符只能是0、1、2...9这10个数之一。
[A-Za-z0-9]
2、字符

重要的字符:






几个常用的非贪婪匹配Pattern:
*? 重复任意次,但尽可能少重复 +? 重复1次或更多次,但尽可能少重复 ?? 重复0次或1次,但尽可能少重复 {n,m}? 重复n到m次,但尽可能少重复 {n,}? 重复n次以上,但尽可能少重复
.*?的用法
. 是任意字符 * 是取 0 至 无限长度 ? 是非贪婪模式。 何在一起就是 取尽量少的任意字符,一般不会这么单独写,他大多用在: .*?x 就是取前面任意长度的字符,直到一个x出现
三、re模块
1、findall
import re #ret = re.findall('a','eva egon yuan') ret = re.findall('[a-z]+', 'eva egon yuan') # 返回所有满足匹配条件的结果,放在列表里 print(ret)
2、search
import re ret = re.search('a', 'eva egon yuan') if ret: print(ret.group()) # 从前往后,找到一个就返回,返回的变量需要调用group才能拿到结果 # 如果没有找到,那么返回None,调用group会报错
#没有找到是不会报错的,只会返回none,none是没有group的,所以才会报错。
3、match
import re ret = re.match('[a-z]+', 'eva egon yuan') if ret: print(ret.group()) # match是从头开始匹配,如果正则规则从头开始可以匹配上,就返回一个变量。 # 匹配的内容需要用group才能显示 # 如果没匹配上,就返回None,调用group会报错
4、split
import re ret = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割 print(ret) # ['', '', 'cd']
5、sub
import re ret = re.sub('\d', 'H', 'eva3egon4yuan4',1) # 将数字替换成'H',参数1表示只替换1个 print(ret) #evaHegon4yuan4
6、subn
import re ret = re.subn('\d', 'H', 'eva3egon4yuan4') #将数字替换成'H',返回元组(替换的结果,替换了多少次) print(ret)
7、compile
import re obj = re.compile('\d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字 ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串 print(ret.group()) #结果 : 123 ret = obj.search('abcashgjgsdghkash456eeee3wr2') #正则表达式对象调用search,参数为待匹配的字符串 print(ret.group())
8、finditer
import re ret = re.finditer('\d', 'ds3sy4784a') #finditer返回一个存放匹配结果的迭代器 print(ret) # <callable_iterator object at 0x10195f940> # print(next(ret).group()) #查看第一个结果 # print(next(ret).group()) #查看第二个结果 # print([i.group() for i in ret]) #查看剩余的左右结果 for i in ret: print(i.group())
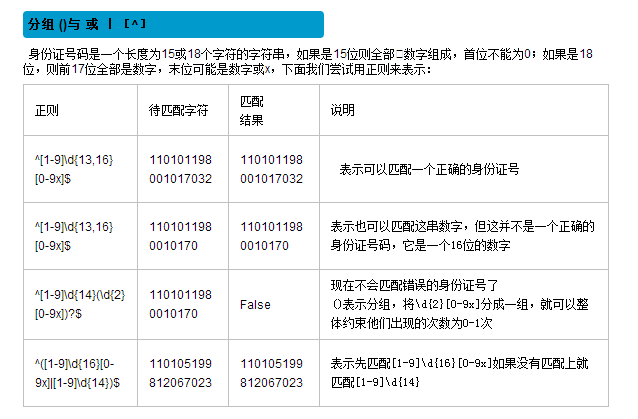
9、search 分组取值
import re ret = re.search('^[1-9](\d{14})(\d{2}[0-9x])?$', '110105199912122277') print(ret.group()) print(ret.group(1)) print(ret.group(2))
10、findall 优先级查询
import re ret = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com') print(ret) # ['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可 ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com') print(ret) # ['www.oldboy.com']
注:?的作用:量词:匹配0次或1次
非贪婪
取消分组优先
11.split 优先级查询
import re ret=re.split("\d+","eva3egon4yuan") print(ret) #结果 : ['eva', 'egon', 'yuan'] ret=re.split("(\d+)","eva3egon4yuan") print(ret) #结果 : ['eva', '3', 'egon', '4', 'yuan']
四、爬虫的例子


import re from urllib.request import urlopen def getPage(url): response = urlopen(url) return response.read().decode('utf-8') def parsePage(s): ret = re.findall( '<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>' '.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>',s,re.S) return ret def main(num): url = 'https://movie.douban.com/top250?start=%s&filter=' % num response_html = getPage(url) ret = parsePage(response_html) print(ret) count = 0 for i in range(10): # 10页 main(count) count += 25 # url从网页上把代码搞下来 # bytes decode ——> utf-8 网页内容就是我的待匹配字符串 # ret = re.findall(正则,带匹配的字符串) #ret是所有匹配到的内容组成的列表
import requests import re import json def getPage(url): response=requests.get(url) return response.text def parsePage(s): com=re.compile('<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>' '.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>',re.S) ret=com.finditer(s) for i in ret: yield { "id":i.group("id"), "title":i.group("title"), "rating_num":i.group("rating_num"), "comment_num":i.group("comment_num"), } def main(num): url='https://movie.douban.com/top250?start=%s&filter='%num response_html=getPage(url) ret=parsePage(response_html) print(ret) f=open("move_info7","a",encoding="utf8") for obj in ret: print(obj) data=json.dumps(obj,ensure_ascii=False) f.write(data+"\n") if __name__ == '__main__': count=0 for i in range(10): main(count) count+=25
import re import json from urllib.request import urlopen def getPage(url): response = urlopen(url) return response.read().decode('utf-8') def parsePage(s): com = re.compile( '<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>' '.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>', re.S) ret = com.finditer(s) for i in ret: yield { "id": i.group("id"), "title": i.group("title"), "rating_num": i.group("rating_num"), "comment_num": i.group("comment_num"), } def main(num): url = 'https://movie.douban.com/top250?start=%s&filter=' % num response_html = getPage(url) ret = parsePage(response_html) print(ret) f = open("move_info7", "a", encoding="utf8") for obj in ret: print(obj) data = str(obj) f.write(data + "\n") count = 0 for i in range(10): main(count) count += 25 简化版
flags有很多可选值: re.I(IGNORECASE)忽略大小写,括号内是完整的写法 re.M(MULTILINE)多行模式,改变^和$的行为 re.S(DOTALL)点可以匹配任意字符,包括换行符 re.L(LOCALE)做本地化识别的匹配,表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境,不推荐使用 re.U(UNICODE) 使用\w \W \s \S \d \D使用取决于unicode定义的字符属性。在python3中默认使用该flag re.X(VERBOSE)冗长模式,该模式下pattern字符串可以是多行的,忽略空白字符,并可以添加注释 flags
