day16 内置函数和匿名函数

复习:
数据类型: int, float, bool,complex
数据结构:dict, tuple,list,set,str
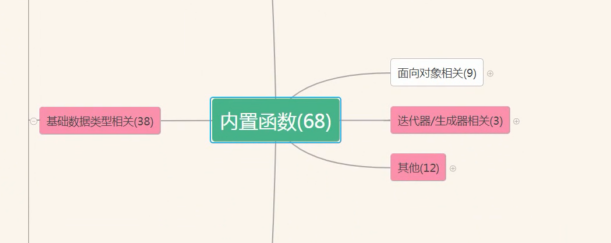
一、内置函数
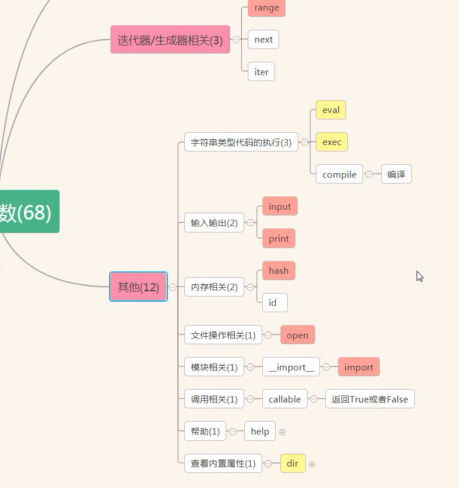
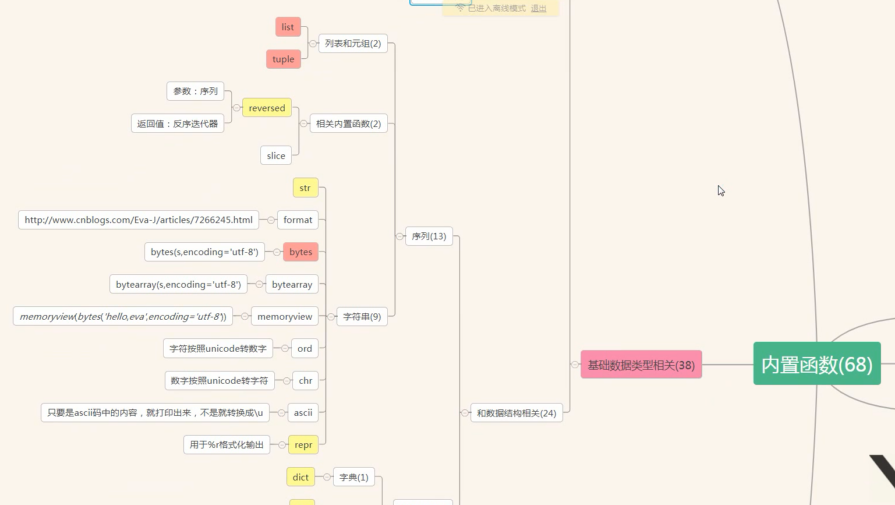
reversed: 保留原列表,返回一个反向的迭代器
# l = [1,2,3,4,5] # l.reverse() # print(l) # l = [1,2,3,4,5] # l2 = reversed(l) # print(l2)
slice:切片
l = (1,2,23,213,5612,342,43) sli = slice(1,5,2) print(l[sli]) print(l[1:5:2])
format:
print(format('test', '<20')) #20空 左对齐 print(format('test', '>20')) #右对齐 print(format('test', '^20')) #居中
bytes:
#bytes 转换成bytes类型 # 我拿到的是gbk编码的,我想转成utf-8编码 # print(bytes('你好',encoding='GBK')) # unicode转换成GBK的bytes # print(bytes('你好',encoding='utf-8')) # unicode转换成utf-8的bytes
# 网络编程 只能传二进制
# 照片和视频也是以二进制存储
# html网页爬取到的也是编码
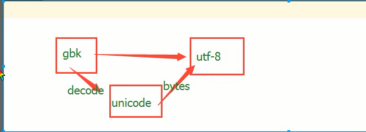
bytearray:
# b_array = bytearray('你好',encoding='utf-8') # print(b_array) # print(b_array[0]) # '\xe4\xbd\xa0\xe5\xa5\xbd' # s1 = 'alexa' # s2 = 'alexb'
memoryview:
# 切片 —— 字节类型 不占内存
# 字节 —— 字符串 占内存
ord:字符按照Unicode转数字
print(ord('a'))
print(ord('好'))
chr:数字按照Unicode转字符
print(chr(97))
ascii:只要是ASCII码中的就原封不动打印出来,不是就转成\u
# print(ascii('好'))
# print(ascii('1'))
repr:
# name = 'egg' # print('你好%r'%name) # print(repr('1')) # print(repr(1))
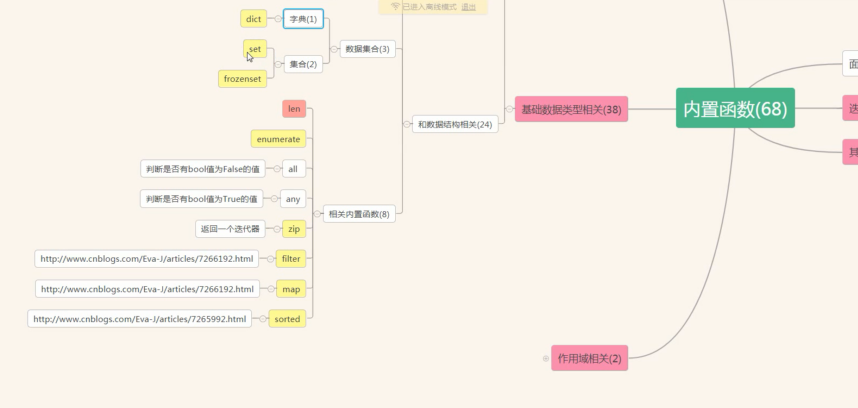
frozenset:不可变
相关内置函数:
len enumerate(枚举)
all:有一个为false就是false
# print(all(['a','',123])) # print(all(['a',123])) # print(all([0,123]))
any:有一个为true就是true
# print(any(['',True,0,[]]))
zip:返回一个迭代器
l = [1,2,3,4,5] l2 = ['a','b','c','d'] l3 = ('*','**',[1,2]) d = {'k1':1,'k2':2} for i in zip(l,l2,l3,d): print(i)
filter:过滤
def is_odd(x): return x % 2 == 1 ret = filter(is_odd, [1,2,3,4,5,6]) print(ret) for i in ret: print(i)
def is_str(s): return s and str(s).strip() ret = filter(is_str, [1, 'hello','',' ',None,[], 6, 7, 'world', 12, 17])
# 对列表中的每个值都代入到is_str中,结果是true就返回到filter中,false就不返回。 print(ret) for i in ret: print(i)
#请用filter过滤出1-100中平方根是整数的数 from math import sqrt
def z_sqrt(x): return sqrt(x) % 1 == 0
ret = filter(z_sqrt,range(1,101))
for i in ret: print(i, end=' ')
map:
ret = map(abs,[1,-4,6,-8]) print(ret) for i in ret: print(i)
filter与map比较:
# filter 执行了filter之后的结果集合 小于等于 执行之前的个数
# filter只管筛选,不会改变原来的值
# map 执行前后元素个数不变
# 值可能发生改变
sorted:
l = [1,-4,6,5,-10] l.sort(key = abs) # 在原列表的基础上进行排序 print(l) print(sorted(l,key=abs)) # 生成了一个新列表 优点:不改变原列表 缺点:占内存 print(sorted(l,key=abs,reverse=True)) # reverse 翻转 print(l)
# 列表按照每一个元素的len排序 l = [' ',[1,2],'hello world'] print(sorted(l,key = len))
二、匿名函数
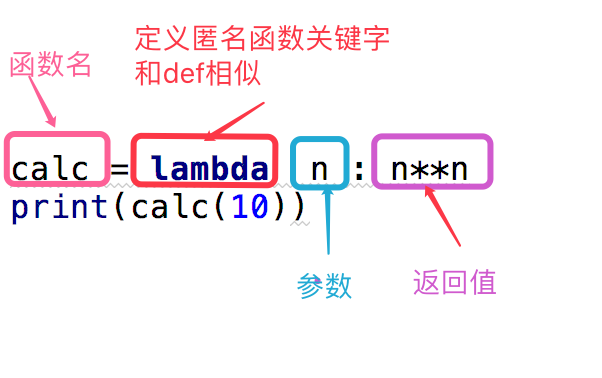
为了解决那些功能很简单的需求而设计的一句话函数
#这段代码 def calc(n): return n**n print(calc(10)) #换成匿名函数 calc = lambda n:n**n print(calc(10))
#打印dic中value值最大的对应的key dic={'k1':10,'k2':100,'k3':30} print(max(dic)) #直接打印‘k3’ print(max(dic,key=lambda key:dic[key])) #k2 print(dic[max(dic,key=lambda k:dic[k])]) #100
min,max,filter,map,sorted含有key关键字,且可以与lambda结合使用
res = filter(lambda x:x>10,[5,8,11,9,15]) for i in res: print(i) res = map(lambda x:x**2,[1,5,7,4,8]) for i in res: print(i)
example :
d = lambda p:p*2 t = lambda p:p*3 x = 2 x = d(x) #x = 4 x = t(x) #x = 12 x = d(x) #x = 24 print(x)
#现有两元组(('a'),('b')),(('c'),('d')), # 请使用python中匿名函数生成列表[{'a':'c'},{'b':'d'}] ret = zip((('a'),('b')),(('c'),('d'))) # def fun(tup): # return {tup[0]:tup[1]} # res = map(fun,ret) res = map(lambda tup:{tup[0]:tup[1]},ret) print(list(res))
本章小结
说学习内置函数,不如说整理自己的知识体系。其实整理这些内置函数的过程也是在整理自己的知识体系。
我们讲课的时候会归类:常用或者不常用,主要还是根据场景而言。
一个优秀的程序员就应该是在该用这个方法的时候信手拈来,把每一个内置的函数都用的恰到好处。
要想做到这一点,至少要先了解,才能在需要的时候想起,进而将它用在该用的地方。
但是在这里,我还是以自己的一点经验之谈,把几个平时工作中相对更常用的方法推荐一下,请务必重点掌握:
其他:input,print,type,hash,open,import,dir
str类型代码执行:eval,exec
数字:bool,int,float,abs,divmod,min,max,sum,round,pow
序列——列表和元组相关的:list和tuple
序列——字符串相关的:str,bytes,repr
序列:reversed,slice
数据集合——字典和集合:dict,set,frozenset
数据集合:len,sorted,enumerate,zip,filter,map

