

IDMapping实现详解
IDMapping的意义
现实存在的问题:
对于一个系统而言,标识用户的方式有很多,用户ID、手机号、身份证号、设备ID等等;那如何确认用户的唯一标识呢?如果只是采用用户ID,那么如果用户没有登录的日志记录就失去价值了;
再对于多个系统而言,如何让多系统中的一个自然人只有一个唯一标识呢?系统之间的id打通可以通过手机号、身份证号等,也就是阿里OneData的OneID思想,通过统一的实体识别和连接,打破数据孤岛,实现数据通融。
解决方案:
构建id映射字典,例如
id(用户id或设备id或等等其他) guid(全局唯一标识)
135134111xx uid01
440xxxxxxxxxxxxxxx uid01
00-16-EA-AE-3C-40 uid01
191134111xx uid02
24-16-EA-AE-3C-40 uid03
ID-Mapping,就是将设备 ID(例如手机 MAC、IMEI、IMSI 等),手机号、身份证号、邮箱地址、PC 端的 Cookie,用户名等信息,结合标签体系、知识图谱、机器学习等技术和算法,将各种 ID 都映射到统一的 ID 上。
实现方案
实现思路
由于 ID 识别天然地是一个关联关系问题,也是一个典型的图、图数据库应用场景。
将日志记录中每行记录中,每个可以唯一标识用户的字段抽象为顶点,顶点同属于一个用户抽象为边;由于同一条记录的顶点肯定属于同一用户,因此可以得到如下图。
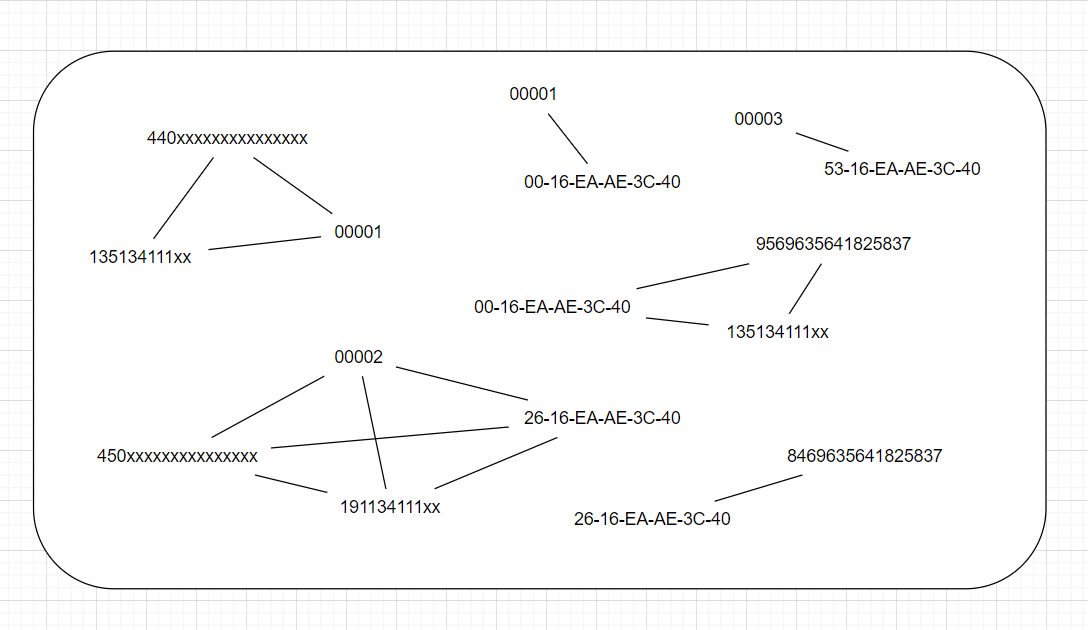
合并相同的顶点可以得到
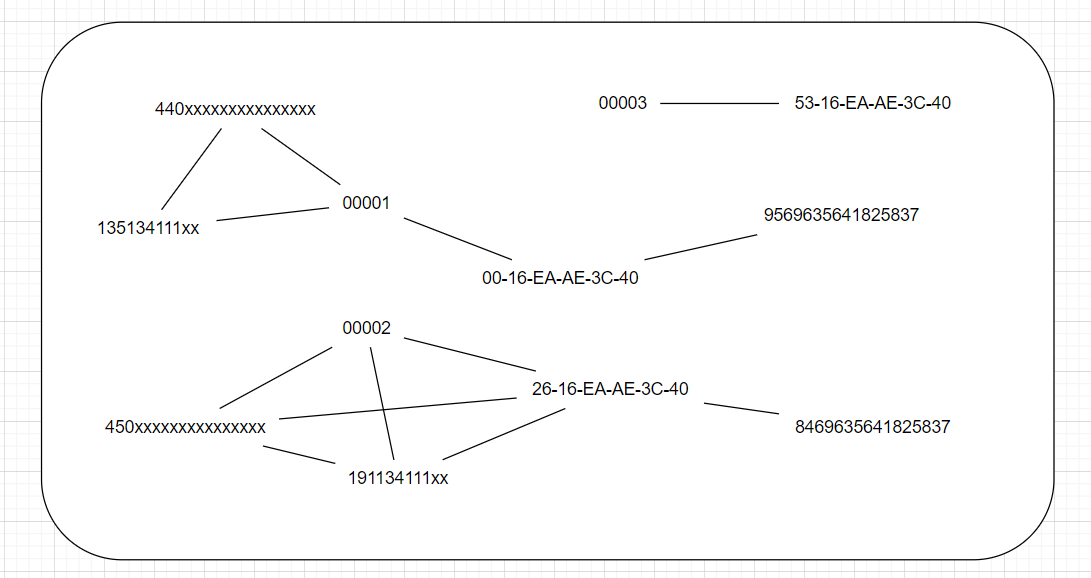
不难理解,一个极大无向连通子图就可以代表一个自然人用户,进而构建id映射字典,全局唯一标识id可以用连通子图的最小顶点值表示。
id(用户id或设备id或等等其他) guid(全局唯一标识)
00001 00001
135134111xx 00001
440xxxxxxxxxxxxxxx 00001
00-16-EA-AE-3C-40 00001
9569635641825837 00001
00002 00002
450xxxxxxxxxxxxxxx 00002
26-16-EA-AE-3C-40 00002
8469635641825837 00002
191134111xx 00002
00003 00003
53-16-EA-AE-3C-40 00003
具体实现
对于每日的日志记录,我们都需要对日志记录集成全局唯一标识(guid)信息。考虑到用户可能是第一次访问这个网站,id映射字典并没有该用户的guid,因此需要在数据集成之前,做一次IDMapping,也就是每日都需要IDMapping。
那如何计算当日的id映射字典呢?历史的映射字典+今日的日志记录,进一步说,历史映射字典生成的图+今日日志记录生成的图。
首先考虑今日日志记录生成图。思路如下:
- 解析日志数据,取出每个可以唯一标识用户的字段的值作为顶点,同一行日志记录的顶点之间构建边;
- 调用Spark GraphX 的Connected Components方法,即连通体算法用id标注图中每个连通体,将连通体中序号最小的顶点的id作为连通体的id。
object TestIDMapping {
def main(args: Array[String]): Unit = {
val spark = SparkUtil.getSparkSession(this.getClass.getSimpleName,master = "local[1]")
// 读取日志文件
val log: Dataset[String] = spark.read.textFile("G:\\delta_logs\\2020-01-11\\app")
// 提取可以标识用户的字段值
val flagsArray: RDD[Array[String]] = extractFlags(log)
// 将字段值转化为顶点,VertexId为字段值的哈希值,attribute为字段值本身
// Vertices:由VertexId(Long类型)、attribute(属性描述或距离)构成。如,(3L, ("San Francisco", "CA")),(1L, 10)
val todayLogVertexes: RDD[(Long, String)] = flagsArray.flatMap(flags => {
for (flag <- flags) yield (flag.hashCode.toLong, flag)
})
// 同一行日志记录的顶点相互构成边(无向)
// Edges:由srcId(起始节点VertexId)、dstId(终止节点VertexId)、attribute(边的权值)构成。如,Edge(1L, 2L, 20)
val todayLogEdges: RDD[Edge[Int]] = flagsArray.flatMap(flags => {
for (i <- 0 to flags.length - 2; j <- i to flags.length - 1)
yield Edge(flags(i).hashCode.toLong, flags(j).hashCode.toLong, 1)
})
.map(edge=>(edge,1)) // 上面生成的边肯定会有重复的
.reduceByKey(_+_) // 这里按edge进行聚合,顺便统计一下相同边的数量
.filter(tp => tp._2 > 2) // 如果相同边小于等于2,可能是偶然事件,就剔除掉 tp == (edge,count(1))
.map(tp => tp._1) // 恢复成edge,此时以及完成了去重和清洗
// 构建图并调用connectedComponents生成极大连通子图
val todayConnectedComponent: VertexRDD[VertexId] = Graph(todayLogVertexes, todayLogEdges)
.connectedComponents()
.vertices
// VertexRDD[VertexId] ==> RDD[(flag.hashcode,guid(最小的flag.hashcode))]
val idMappingDict: RDD[(VertexId, VertexId)] = todayConnectedComponent.map(tp => {
(tp._2, tp._1)
})
}
/**
* 抽取可以用于标识用户的字段值
*/
def extractFlags(logDs: Dataset[String]):RDD[Array[String]] = {
logDs.rdd.map(logText=>{
/**
* 日志内容可标识字段概况
* {
* ... ,
* "user":{
* "uid" : "",
* "account" : "",
* "email" : "",
* "phoneNbr" : "",
* "phone" : {
* "imei": "9569635641825837", //imei
* "mac": "2f-93-d1-e4-5e-35-36", //mac
* "imsi": "1706694213462619", //imsi
* "deviceId": "", //设备id
* "uuid": "sarSfmG2p7RFG1z3", //uuid
* ...
* }
* }
* ...
* }
*/
// 解析日志json
val logJSON = JSON.parseObject(logText)
// 获取 日志json中 嵌套的 用户json对象
val userJSON = logJSON.getJSONObject("user")
// 获取用户json对象中的标识字段
val uid = userJSON.getString("uid") // 用户id
val account = userJSON.getString("account") // 用户账号
val phoneNbr = userJSON.getString("phoneNbr") // 电话号码
// 获取 用户json对象 中嵌套的 设备json对象
val phoneJSON = userJSON.getJSONObject("phone")
val imei = phoneJSON.getString("imei")
val mac = phoneJSON.getString("mac")
val imsi = phoneJSON.getString("imsi")
val deviceId = phoneJSON.getString("deviceId")
val uuid = phoneJSON.getString("uuid")
Array(uid,account,phoneNbr,imei,mac,imsi,deviceId,uuid)
}
)
}
}
此时已经可以得到当日的id映射字典了,然后开始考虑整合历史的id映射字典。
主要问题:
-
历史的id映射字典是以什么方式存储的,怎么读回?
每日的id映射字典以parquet方式存储在HDFS,程序可以直接读回结构化数据。
-
整合是怎么做到的?
首先,将历史的id映射字典重新转化为顶点和边,顶点是每个用户的每个标识字段,边是标识字段与guid的连接,如下图所示。
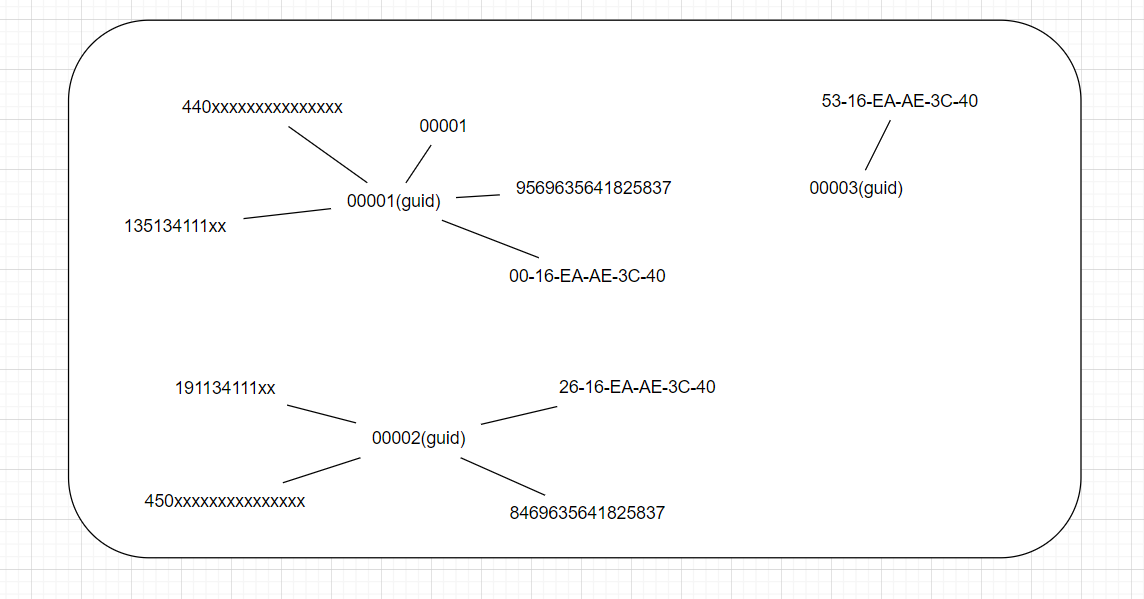
再和今日的顶点和边union成一个更大的图,图里包含了今日的子图和历史的子图。
再重新调用Connected Components方法,生成大图的极大连通子图,就可以实现历史和今日的整合。
但是需要考虑一个问题,由于Connected Components方法生成的guid是连通子图最小的字段值,那如果今日的字段值是最小的,就会改变这个用户的guid,这显然是不合理的,因为历史的guid已经集成到数据中了。因此需要将这种情况的guid保留为历史的guid。具体实现如下:
/**
* 完整实现生成id映射字典
*/
object TestIDMapping {
def main(args: Array[String]): Unit = {
val spark = SparkUtil.getSparkSession(this.getClass.getSimpleName,master = "local[1]")
// 读取今日日志文件
val log: Dataset[String] = spark.read.textFile("G:\\delta_logs\\2020-01-11\\app")
// 提取可以标识用户的字段值
val flagsArray: RDD[Array[String]] = extractFlags(log)
// 将字段值转化为顶点,VertexId为字段值的哈希值,attribute为字段值本身
val todayLogVertexes: RDD[(Long, String)] = flagsArray.flatMap(flags => {
for (flag <- flags) yield (flag.hashCode.toLong, flag)
})
// 同一行日志记录的顶点相互构成边(无向)
val todayLogEdges: RDD[Edge[Int]] = flagsArray.flatMap(flags => {
for (i <- 0 to flags.length - 2; j <- i to flags.length - 1)
yield Edge(flags(i).hashCode.toLong, flags(j).hashCode.toLong, 1)
})
.map(edge=>(edge,1)) // 上面生成的边肯定会有重复的
.reduceByKey(_+_) // 这里按edge进行聚合,顺便统计一下相同边的数量
.filter(tp => tp._2 > 2) // 如果相同边小于等于2,可能是偶然事件,就剔除掉 tp == (edge,count(1))
.map(tp => tp._1) // 恢复成edge,此时以及完成了去重和清洗
// 读取历史的id映射字典
val historyIdMappingDict = spark.read.parquet("data/idmp/2020-02-11")
// 得到历史字典的所有顶点
val historyLogVertexes: RDD[(VertexId, String)] = historyIdMappingDict.rdd.map({
case Row(flagHashCode: VertexId, guid: VertexId) => (flagHashCode, "")
})
// 构建历史字典的边
val historyLogEdges: RDD[Edge[Int]] = historyIdMappingDict.rdd.map(row => {
Edge(row.getAs[VertexId]("flagHashCode"), row.getAs[VertexId]("guid"), 1)
})
// 构建图并调用connectedComponents生成极大连通子图(历史+今天)
// 注:VertexRDD[VertexId] ==> RDD[(flag.hashcode,guid(最小的flag.hashcode))]
val unifiedConnectedComponent: VertexRDD[VertexId] =
Graph(todayLogVertexes.union(historyLogVertexes), todayLogEdges.union(historyLogEdges))
.connectedComponents()
.vertices
// 解决guid历史存在但可能被更换的问题
// 遍历 unifiedConnectedComponent(统一连通分量) 的 flag,
// 如果在 历史 guid 中发现存在,
// 说明该用户已经存在guid了,可以将 该flag所在的统一连通分量的guid 改为 历史的guid
// 将历史的id映射字典收集到Driver端,然后广播(广播是由于接下来需要在map中使用外部变量)
val historyIdMappingDict_bc = historyIdMappingDict.rdd.map(row => {
(row.getAs[VertexId]("flagHashCode"), row.getAs[VertexId]("guid"))
}).collectAsMap()
val bc = spark.sparkContext.broadcast(historyIdMappingDict_bc)
// 将统一连通分量 按guid 分组
val finalConnectedComponent = unifiedConnectedComponent.map(tp => (tp._2, tp._1))
.groupByKey() // 得到(guid,Iterator(flag))
.map(tp => {
var guid = tp._1
val flags = tp._2
val historyIdMappingDict_bc = bc.value
// 遍历这组flags,看有没有和历史guid一致的,如果有就替换
var caught = false;
for (flag <- flags if !caught) {
if (historyIdMappingDict_bc.get(flag).isDefined) {
caught = true;
guid = historyIdMappingDict_bc.get(flag).get
}
}
(guid, flags)
})
.flatMap(tp => {
for (flag <- tp._2) yield (flag, tp._1) // 恢复分组前 (flag,guid)
})
// 保存结果
import spark.implicits._
finalConnectedComponent.toDF("flagHashCode", "guid")
.coalesce(1)
.write.parquet("data/idmp/xxxx")
spark.close()
}
/**
* 抽取可以用于标识用户的字段值
*/
def extractFlags(logDs: Dataset[String]):RDD[Array[String]] = {
...
}
}

