Hive执行计划详解
什么是Hive SQL执行计划
Hive SQL执行计划描绘了SQL实际执行的整体轮廓,即SQL转化为对应计算引擎的执行逻辑;毫无疑问,这一块对于Hive SQL的优化是非常重要的。
Hive SQL早期是基于规则的方式生成执行计划,在Hive 0.14及之后,集成了Apache Calcite,使得Hive能够基于成本代价来生成执行计划。
Hive目前提供的是预估的执行计划,而非真实的执行计划(SQL实际执行完后才能获得的计划)。
查看Hive SQl执行计划
- explain:查看基本信息
- explain extended:查看扩展信息
- explain dependency:查看SQL数据输入依赖的信息
- explain authorization:查看SQL操作相关权限的信息
- explain vectorization:查看向量化的描述信息
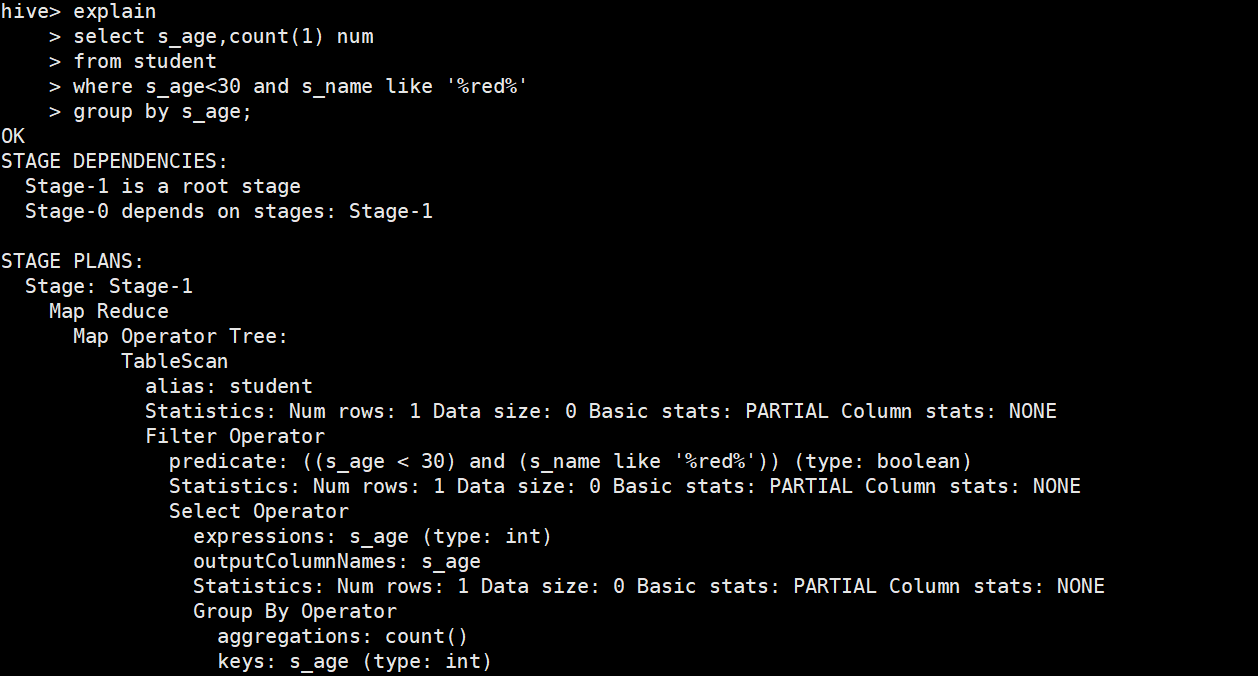
# 看这个前请先理解sql语句
STAGE DEPENDENCIES: # 作业依赖关系
Stage-1 is a root stage # 根stage
Stage-0 depends on stages: Stage-1 # stage-0依赖stage-1
STAGE PLANS:
Stage: Stage-1 # Stage-1详细任务
Map Reduce # 表示当前引擎使用的是 MapReduce
Map Operator Tree: # Map阶段操作信息
TableScan # 对下面alias声明的结果集进行 表扫描操作
alias: student # alias声明student表
Statistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONE # 对当前阶段的统计信息,如当前处理的行和数据量(都是预估值)
Filter Operator # 表示在Tablescan的结果集上进行过滤
predicate: ((s_age < 30) and (s_name like '%red%')) (type: boolean) # 过滤条件
Statistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONE
Select Operator # 表示在过滤后的结果集上进行投影
expressions: s_age (type: int) # 需要投影的列
outputColumnNames: s_age # 输出的列名
Statistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONE
Group By Operator # 在投影后结果集上进行分组聚合
aggregations: count() # 分组聚合使用的算法
keys: s_age (type: int) # 分组的列
mode: hash # 采用hash
outputColumnNames: _col0, _col1 # 输出的列名
Statistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONE
Reduce Output Operator # Map端聚合
key expressions: _col0 (type: int) # Map端输出的key
sort order: + # +表示正序,-表示逆序
Map-reduce partition columns: _col0 (type: int) # 分区字段
Statistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONE
value expressions: _col1 (type: bigint) # Map端输出的value
Execution mode: vectorized
Reduce Operator Tree:
Group By Operator
aggregations: count(VALUE._col0) # 对Map value的第一个值进行聚合算法
keys: KEY._col0 (type: int) # key是Map Key的第一个值
mode: mergepartial
outputColumnNames: _col0, _col1 # 输出列名
Statistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONE
File Output Operator # 对上面的结果集进行文件输出
compressed: false # 不压缩
Statistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat # 输入文件类型
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat # 输出文件类型
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe # 序列化、反序列化方式
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
可以看到有两部分内容:STAGE DEPENDENCIES(作业的依赖关系图)、STAGE PLANS(每个作业的详细信息)。以及标注的详细解释。
执行计划归类
只有Map阶段的类型
-
select-from-where型:简单的SQL执行计划,不包含列操作、条件过滤、UDF、聚合、连接等操作的SQL。
由于不需要经过聚合,所以只有Map阶段操作,如果文件大小控制合适的话,可以完全发挥任务本地化执行的优点,也就是不需要跨节点,非常高效!
hive> explain > select s_age,s_name > from student > where s_age=10; OK STAGE DEPENDENCIES: Stage-0 is a root stage STAGE PLANS: Stage: Stage-0 Fetch Operator limit: -1 Processor Tree: TableScan alias: student Statistics: ... Filter Operator predicate: (s_age = 10) (type: boolean) Statistics: ... Select Operator expressions: 10 (type: int), s_name (type: int) outputColumnNames: _col0, _col1 Statistics: ... ListSink -
select-func(col)-from-where-func(col) / select-operation-from-where-operation型:只带普通函数(除UDTF、UDAF、窗口函数)
同样只有Map阶段,非常高效!
hive> explain > select case when s_age>20 then 'over 20' when s_age=20 then 'equal 20' else 'other' end age > from student > where s_name is not null; OK STAGE DEPENDENCIES: Stage-0 is a root stage STAGE PLANS: Stage: Stage-0 Fetch Operator limit: -1 Processor Tree: TableScan alias: student Statistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONE Filter Operator predicate: s_name is not null (type: boolean) Statistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONE Select Operator expressions: CASE WHEN ((s_age > 20)) THEN ('over 20') WHEN ((s_age = 20)) THEN ('equal 20') ELSE ('other') END (type: string) outputColumnNames: _col0 Statistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONE ListSink
Map+Reduce类型
-
select-aggr_func-from-where-groupby类型:带聚合函数的SQL。这类SQL可以分为如下几类:在Reduce阶段聚合的SQL执行计划、在Map和Reduce都有聚合的SQL计划、高级分组聚合的执行计划。
hive中可以通过配置hive.map.aggr来设定是否开启Combine。
高级分组聚合指的是聚合时使用:grouping sets、cube、rollup(使用高级分组聚合需要确保Map端reduce开启)。使用高级分组聚合可以将union需要多次的作业塞到一个作业中,可以减少多作业在磁盘和网络IO中的消耗,是一种优化。但是需要注意,这种聚合会造成数据极速膨胀;如果基表的数据量很大,容易导致Map或者Reduce任务因为硬件资源不足而崩溃,Hive中可以使用hive.new.job.grouping.set.cardinality配置这个问题。
-
带窗口函数的SQL执行计划
hive> explain > select s_name,row_number() over(partition by s_age order by s_score) rk > from student; OK STAGE DEPENDENCIES: Stage-1 is a root stage Stage-0 depends on stages: Stage-1 STAGE PLANS: Stage: Stage-1 Map Reduce Map Operator Tree: TableScan alias: student Statistics: ... Reduce Output Operator key expressions: s_age (type: int), s_score (type: int) sort order: ++ Map-reduce partition columns: s_age (type: int) Statistics: ... value expressions: s_name (type: string) Execution mode: vectorized Reduce Operator Tree: Select Operator expressions: VALUE._col0 (type: string), KEY.reducesinkkey0 (type: int), KEY.reducesinkkey1 (type: int) outputColumnNames: _col0, _col1, _col2 Statistics: ... PTF Operator # 窗口函数分析操作 Function definitions: Input definition input alias: ptf_0 output shape: _col0: string, _col1: int, _col2: int type: WINDOWING Windowing table definition input alias: ptf_1 name: windowingtablefunction order by: _col2 ASC NULLS FIRST # 窗口函数排序列 partition by: _col1 # 窗口函数分区列 raw input shape: window functions: window function definition alias: row_number_window_0 name: row_number # 窗口函数的方法 window function: GenericUDAFRowNumberEvaluator window frame: ROWS PRECEDING(MAX)~FOLLOWING(MAX) # 表示当前窗口函数上下边界 isPivotResult: true Statistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONE Select Operator expressions: _col0 (type: string), row_number_window_0 (type: int) outputColumnNames: _col0, _col1 Statistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONE File Output Operator compressed: false Statistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONE table: input format: org.apache.hadoop.mapred.SequenceFileInputFormat output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe Stage: Stage-0 Fetch Operator limit: -1 Processor Tree: ListSink
表连接的SQL计划
Hive表连接类型可以分为以下六种:
- inner join
- full outer join
- left outer join
- right outer join
- left semi join:返回左表中与右表的匹配记录
- cross join:返回两表连接字段的笛卡尔积
以下举例inner join
hive> explain
> select a.s_no
> from a a inner join b b on a.s_no=b.s_no;
OK
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan # 扫描表a
alias: a
Statistics: ...
Filter Operator
predicate: s_no is not null (type: boolean) # inner join 内置过滤
Statistics: ...
Select Operator
expressions: s_no (type: int)
outputColumnNames: _col0
Statistics: ...
Reduce Output Operator
key expressions: _col0 (type: int)
sort order: +
Map-reduce partition columns: _col0 (type: int)
Statistics: ...
TableScan # 扫描表b
alias: b
Statistics: ...
Filter Operator
predicate: s_no is not null (type: boolean)
Statistics: ...
Select Operator
expressions: s_no (type: int)
outputColumnNames: _col0
Statistics: ...
Reduce Output Operator
key expressions: _col0 (type: int)
sort order: +
Map-reduce partition columns: _col0 (type: int)
Statistics: ...
Reduce Operator Tree:
Join Operator # 表连接操作
condition map:
Inner Join 0 to 1 # inner join 0 1 ;0 1指代的信息在下面
keys:
0 _col0 (type: int) # 0表示map阶段一个表的数据集 _col0表示连接字段
1 _col0 (type: int) # 1表示map阶段另一个表的数据集 _col0表示连接字段
outputColumnNames: _col0
Statistics: ...
File Output Operator
compressed: false
Statistics: ...
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink

 浙公网安备 33010602011771号
浙公网安备 33010602011771号