数据倾斜问题
数据倾斜的简介
数据倾斜即单个节点任务处理的数据量远高于同类型任务处理的数据量,成为整个作业的性能瓶颈。
本文将从产生数据倾斜的原因、不同计算引擎下的解决方法讨论。
数据倾斜的场景和对应的解决方案
Suffle过程
数据倾斜和Suffle过程是密不可分的,Suffle过程在MR和Spark中大体思想上是相差不大的,下面以Spark1.2以前的HashSuffle来简单描述一下。
Shuffle过程可以分为Suffle Write阶段和Suffle Read阶段。如下图所示。
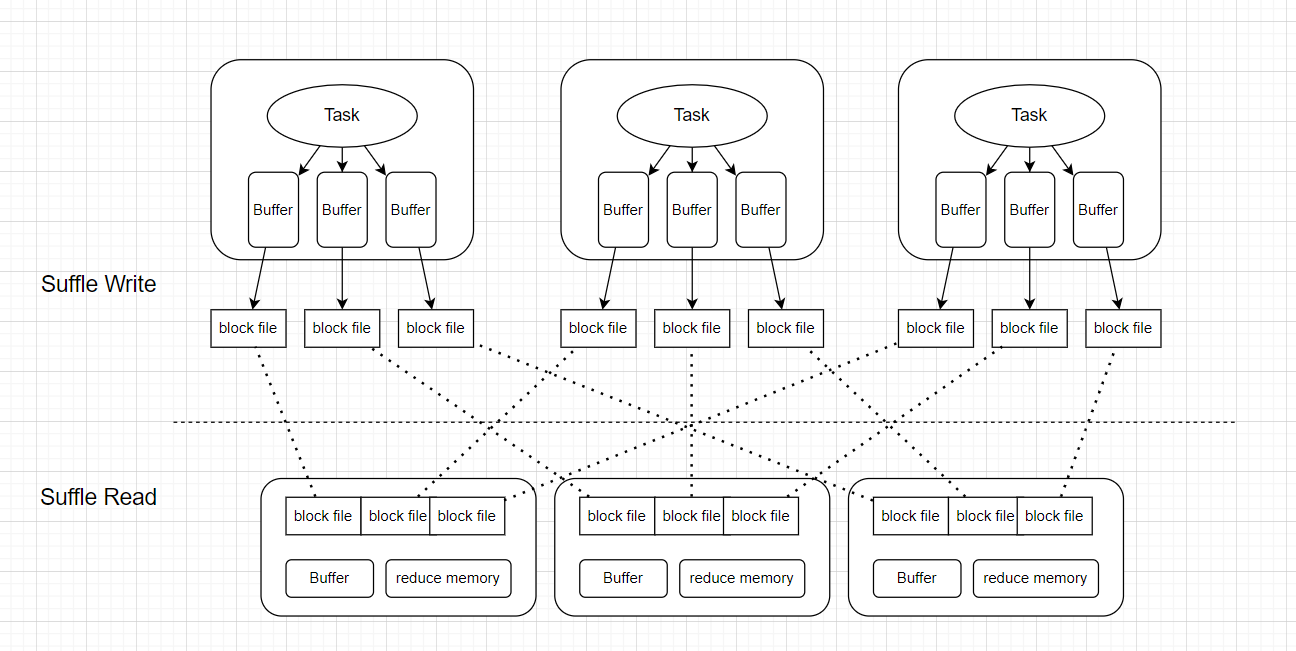
以上哪些场景会出现数据倾斜呢?如下所示
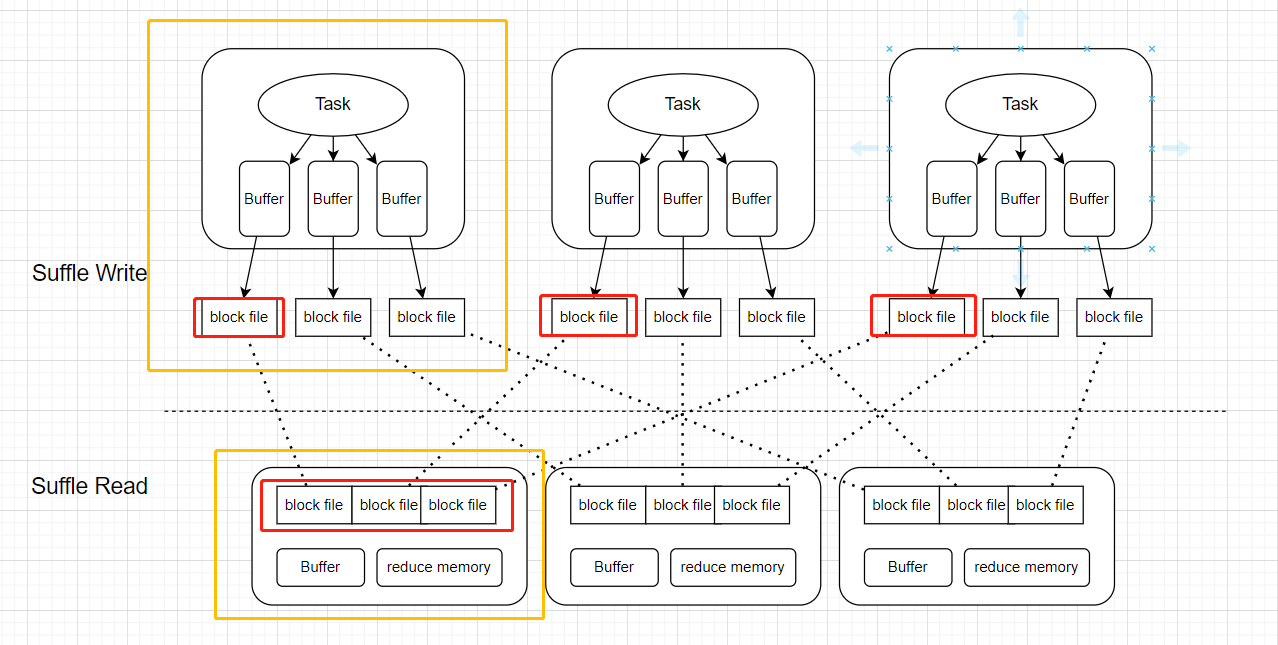
主要可以分为Suffle Write阶段的数据倾斜和Suffle Read阶段的数据倾斜
Suffle Write阶段的数据倾斜
当write阶段的某一个task处理的数据特别多,就会导致该task成为瓶颈;那为什么这个task会处理相比于其他task多那么多的数据呢?所以需要看到源头。
不管是MR还是Spark,在输入数据的时候都会进行切片,当HDFS中某个文件非常大且压缩后不可切分的话,这个文件就只会由一个task进行处理,因此会导致这个task处理数据量相比于同类型任务非常大(如果是每个task的数据量都很大,就需要考虑切片数量的问题,在MR中可以通过调maxSize,在Sprak中可以调整average_size(total_size/minPartition))。解决方案是将文件改为可切分的压缩格式,如bzip2,Zip。
Suffle Read阶段的数据倾斜
这阶段的数据倾斜本质上就是因为数据中含有大量相同key,相同key通过hash code取模后会进入相同的分区导致某个task的处理数量量非常大。
同时,这种情景还可以分单key导致的倾斜和多key导致的倾斜;多key指的是单个key在一个task中可能可以接受,但是由于分区规则,导致多个中等大小的key都分到了一个task,这样这个task的任务依旧很重。单key指的是单个key它的数据量就非常大了。
减少Suffle或去除Suffle
不管哪种场景,首先考虑的是能不能减少Suffle甚至不要Suffle。就算不会数据倾斜,Suffle也是性能瓶颈的重要因素。
一个典型的场景就是大表join小表,通过将小表发给大表的task,直接在Map端进行join,从而避免Suffle过程。下面也从Hive和Spark分别说以下具体的措施。
Hive处理的大表join小表
Hive 处理就是将Repartition Join转为common mapJoin
common mapJoin的原理:MapJoin是先启动一个作业,读取小表的数据,在内存中构建哈希表,将哈希表写入本地磁盘,然后将哈希表上传到HDFS并添加到分布式缓存中。再启动一个任务读取B表的数据,在进行连接时Map会获取缓存中的数据并存入到哈希表中,B表会与哈希表的数据进行匹配,时间复杂度是O(1),匹配完后会将结果进行输出。具体可以看:https://blog.csdn.net/xiaozhaoshigedasb/article/details/105245698
使用common mapjoin有两种方式:一、使用MapJoin的hint语法;二、使用Hive配置MapJoin。
一、在实际生产环境中,不建议使用hint语法;因为如果小表的数据量在业务过程中激增,那hint关键字会强制进行mapJoin,最坏的情况会导致OOM。
二、使用Hive配置需要以下几项:
- hive.auto.convert.join:在Hive0.11后,默认为true;
- hive.smalltable.filesize:默认是25000000bytes;当小表小于这个值,会自动将repartition Join转为common map join。
Spark处理的大表join小表
思想是一样的,不过common map join在Spark中是Broadcast Join,就是将小表广播出去,让大表join。
我们可以在Spark Core中自己写代码广播小表,而在Spark SQL中可以更方便做这件事。
Spark SQL会自动检查数据量大小,把小的数据量广播出去。它会认为表的数据量小于spark.sql.autoBroadcastJoinThreshold=10M,就是小表。当然我们可以自己配置这个值。而Spark SQL获取表大小的信息是从metastore获取的,如果极端情况下metastore数据出错了,小表数据量实际很大,那么会导致广播后OOM;所以也可以配置spark.sql.statistics.fallBackToHdfs=true,从HDFS计算表大小。
Suffle不可避免
对于这种情景,我认为有一定的处理流程,
排查业务数据问题 ---> 倾斜key的判断 ---> 针对性措施
排查业务数据问题
- 过滤大量无意义数据:如果数据存在大量业务含义是无意义的,例如空值或者空字符串,那么可以先将这些值过滤掉,Hive中where,Spark中filter这类措施。
- 不能过滤的异常数据:在不影响其他指标的情况下,用随机数填充。
倾斜key的判断
判断的基本思路是通过对数据集进行抽样,了解key的大概情况。Hive的抽样函数,Spark的sample算子。
多次抽样后可以大致得到倾斜的key是哪个。
针对性措施
- 如果是多key导致的数据倾斜,可以尝试调整并行度,有一点的缺点就是,并行度只能凭感觉给,不过最好不要是之前并行度的倍数。
- 将相同key分散开来,分为两阶段聚合;具体做法是,在造成倾斜的key后面加一个随机数,先进行一次聚合,然后再去掉加上的随机数,再进行一次聚合。
情景:大表join大表发生数据倾斜
两个大表连接,如果连接键存在倾斜,必定会引发数据倾斜。此时的解决思路可以是如下:假设存在大表A和B,可以先对两表正常的key过滤出来join;而倾斜key则单独处理,将表A的key进行定制化加盐(假设在key后加一个1-20的随机数),对于表B的key进行定制化扩容(每一个key都新增1-20数的记录,相当于扩容20倍),然后进行一阶段join,然后再把随机数抹除掉,进行全局join。最后把正常key和倾斜key的结果union起来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号