深入MapReduce计算引擎
深入MapReduce计算引擎
MapReduce整体处理过程
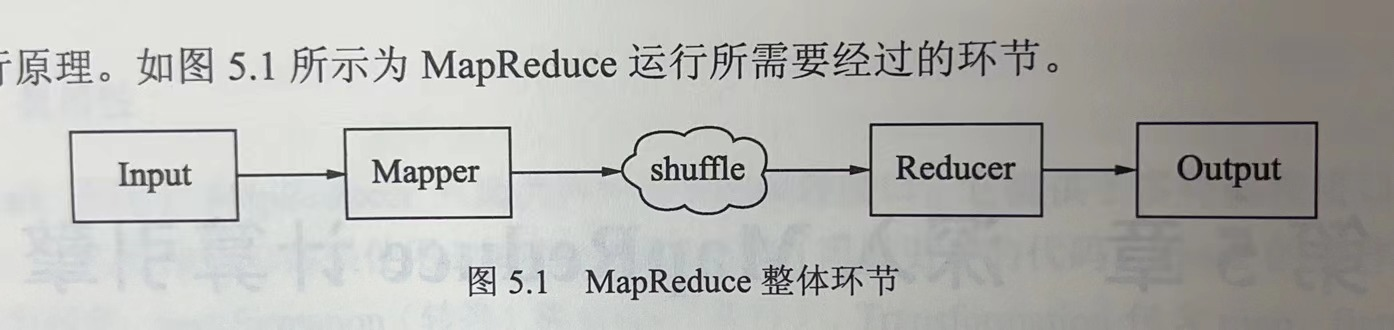
MapReduce的运行需要经过input(作业输入)--mapper(业务处理接口)--shuffle(map到reduce之间的数据传输环节)--reducer(业务处理接口)--output(作业输出)
整个过程由Driver作为主入口,如下示例代码:
Driver code
Configuration conf= new Configuration();
Job job = new Job(conf,"My Word Count Program");
job.setJarByClass(WordCount.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
Path outputPath = new Path(args[1]);
//Configuring the input/output path from the filesystem into the job
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
Input
作业输入的核心是InputFormat类,作用是规范作业输入和读取数据的格式。
InputFormat涉及三个接口:InputFormat,InputSplit,RecordReader。
InputFormat Interface
包含两个方法
- getSplit():获取逻辑分片(InputSplit),逻辑分片用于指定输入到每个Mapper任务的文件大小;
- getRecordReader():获取记录读取器,记录读取器根据逻辑分配读取文件相应位置的数据,以kv的形式传给Mapper。
InputSplit Interface
包含两个方法:
- getLength():获取每个分片的大小;
- getLocations():获取每个分片所在的位置。
RecordReader Interface
包含五个方法:
- close():close the record reader;
- getCurrentKey():获取当前的key;
- getCurrentValue():获取当前的value;
- nextKeyValue():读取下一个key-value对;
- getProgress():读取当前逻辑分片的进度。
Mapper
Mapper类负责MapReduce计算引擎在Map阶段的业务逻辑处理。其输入输出均是kv形式,具体的业务逻辑由用户自主开发。核心是Map()。
以下为wordcount的mapper类:
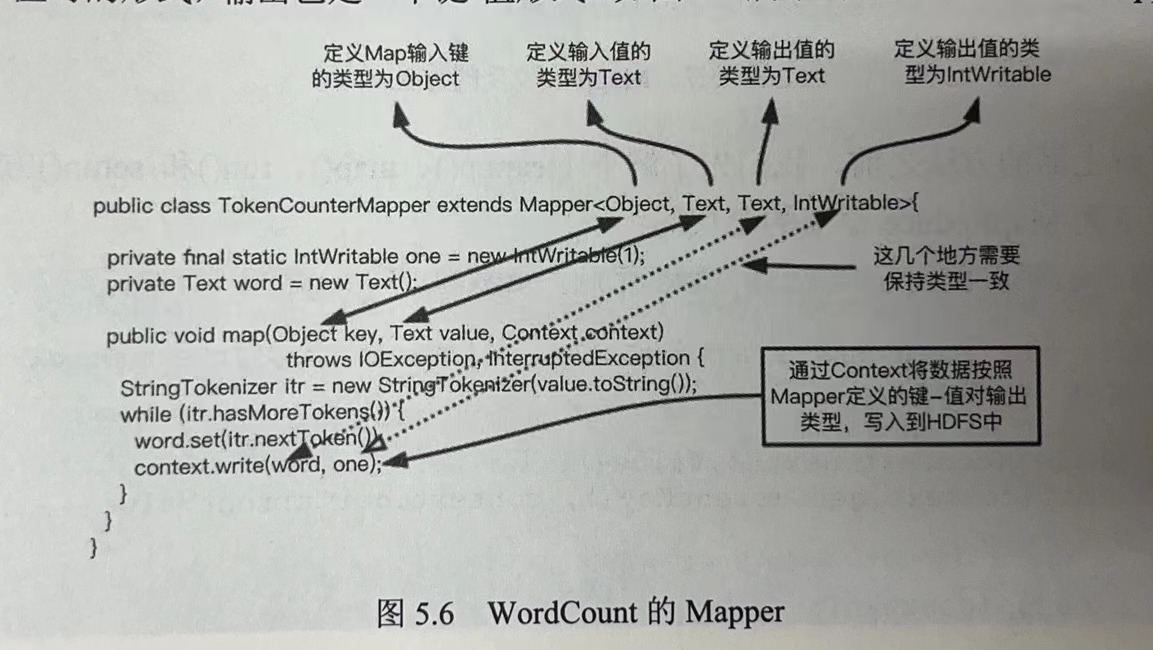
mapper类除了提供map方法外,还提供了其他一些api
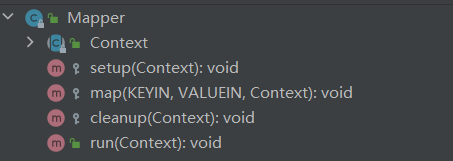
run()方法的源码如下:
public void run(Context context) throws IOException, InterruptedException {
setup(context);
try {
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
} finally {
cleanup(context);
}
}
调用run(),通过run()调用setup(),初始化一些信息;再进行一个while循环,将数据一行行循环调用map()方法,最后跳出循环cleanup()释放资源。
扩展:
1. Mapper阶段是一种只移动数据计算逻辑,而不移动数据的模式;mapper中的逻辑会分发到集群的各个节点,并读取节点的本地数据进行处理,最后再写入本地。
2. MapReduce只简单定义了业务处理的输入输出规范,没有丰富的api供业务逻辑开发。相较于Spark来说不易使用。
Reducer
Recuder也是一个业务逻辑实现类,但是输入不同与Mapper,由于Reduce阶段将key相同的value聚集,因此输入的value是集合类型;而输出则同Mapper一致,是kv对形式。Reducer的核心是reduce()。
以下为wordcount的reducer类:

Reducer除了reduce(),同样提供了cleanup() run() setup()。
MapReduce Shuffle
shuffle在官方定义是Mapper输出到Reducer输入的整个,而《Hive性能调优实战》的作者认为shuffle是Mapper类的map()的输出到Reducer类的reduce()的输入整个过程。
下图是MapReduce整体环节的拆解:
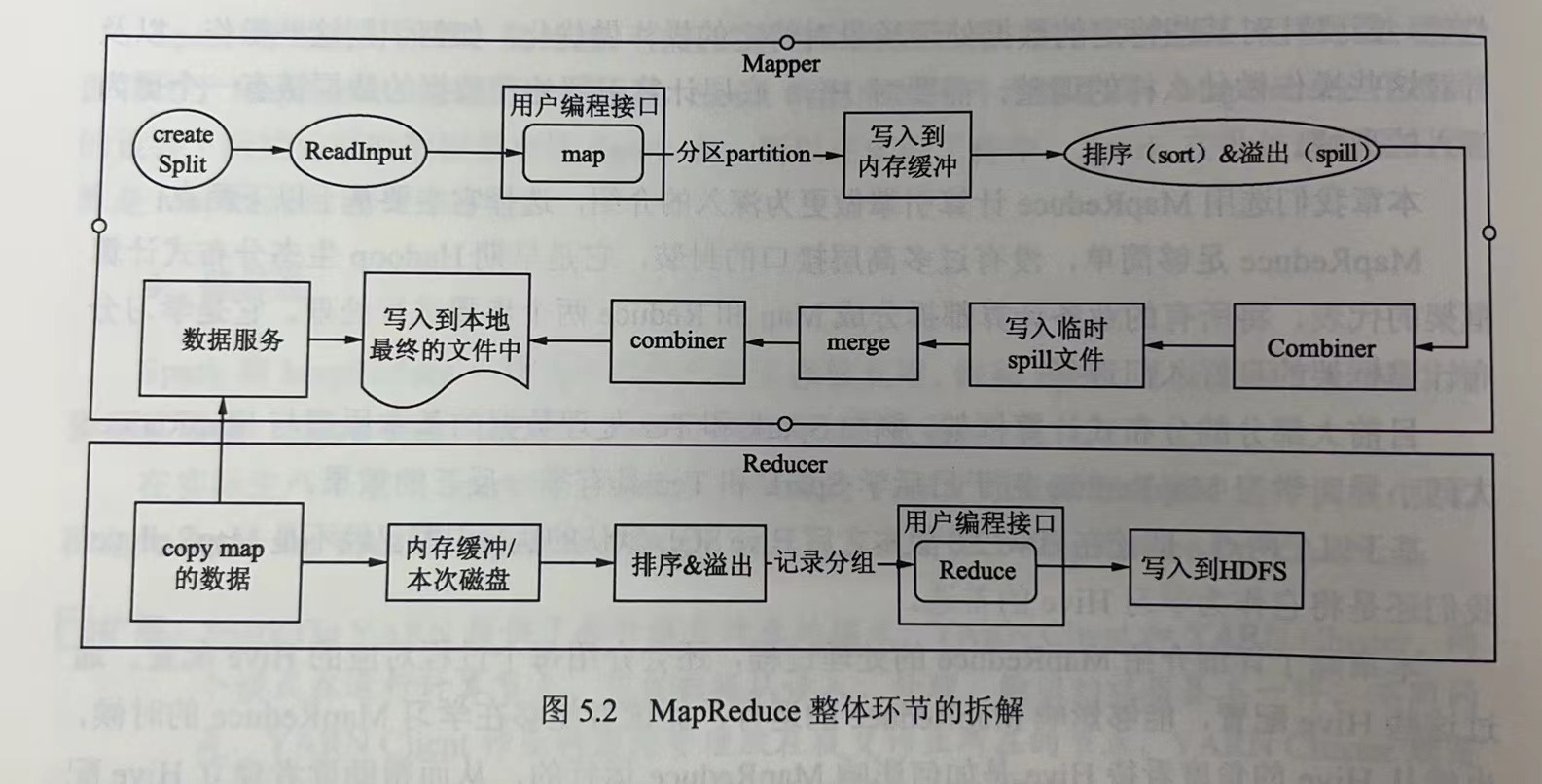
可以清晰得看到,map方法结束到reduce方法开始中间经历的步骤。
-
在map()方法中,会调用context.write()会将数据计算分区后写入到内存缓冲,当写入数据达到缓冲区(缓冲区大小mapreduce.task.io.sort.mb=100MB)的80%(mapreduce.map.sort.spill.percent=0.8)后,会重新启动一个线程将缓冲区数据写入到hdfs临时目录中。
-
在写入hdfs临时目录时,会将数据进行排序,当整个Map阶段结束后,再将临时文件合并成一个文件。
排序的好处:如果不进行排序,后续Reducer读取该份数据时就需要频繁搜索磁盘,将顺序读变为随机读,会极大降低效率。
-
Combiner可以进行Map端的聚合(Map端聚合通常指实现Combiner类)。所谓Map端聚合就是在节点先对本地的Mapper进行一次数据聚合,此次数据聚合可以重新编写Conbiner类,也可以使用Reducer类实现业务逻辑。示例如下:
job.setCombinerClass(IntSumReducer.class)Map端聚合的好处,限制MapReduce任务的一大瓶颈就是网络传输和io读写。先进行Map端聚合可以减少Suffle过程的数据量,减轻系统磁盘和网络的压力。
-
Output
Output作业输出主要包含两个类:OutputFormat和OutputCommitter
OutputFormat
包含三个方法:
- checkOutputSpecs():校验作业的输出规范;
- getOutputCommitter():获取OutputCommitter对象;
- getRecordWriter():获取RecordWriter对象,通过该对象将数据写入到HDFS。
OutputCommitter
主要工作:
- 初始化期间,做作业运行的准备工作;如创建临时目录;
- 作业完成后,清理作业遗留的文件目录;
- 检查任务是否需要提交;
- 提交输出任务,任务完成后就需要提交任务;
- 丢弃任务提交,任务失败或终止,清理输出。
参考资料:
- 《Hive性能调优实战》,林志煌编著。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号