问题排查org
问题排查org.apache.hadoop.ipc.Client
背景是在三台云服务器上部署Hadoop集群,当提交job到yarn上执行时,一直处在map阶段,记录一下排查问题的过程。
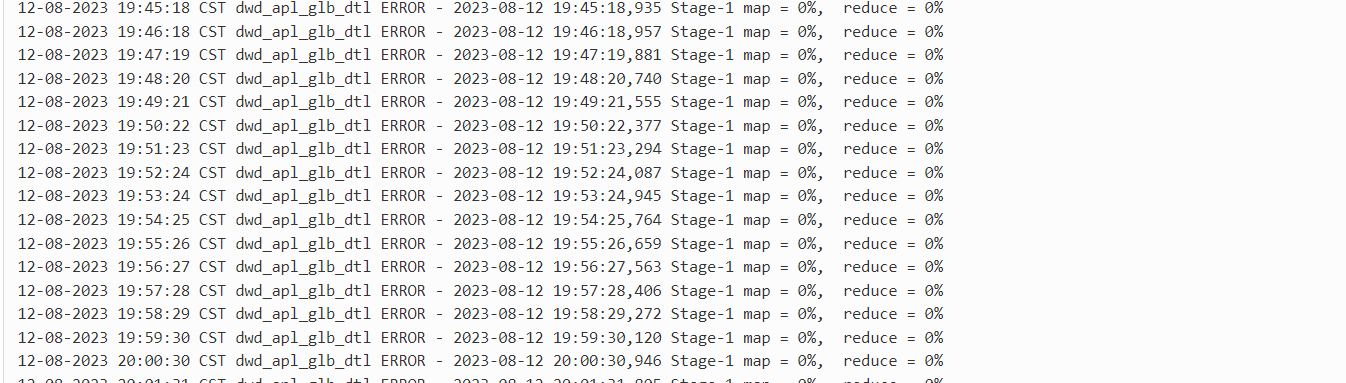
排查思路
- 都已经到map阶段了,说明ApplicationMaster(AM)已经起了,所以我打算查看AM的日志。
如何知道AM起在哪台机器呢?appllicationID是知道的,在web端就可以看到。因为AM的container是由ResourceManager分配的,因此RM的log一定知道起在哪台机器。
所以我查看了RM的日志,用applicationID搜到了那段日志;
less查看日志
less log.log
shift + G 命令到文件尾部 然后输入 ?加上你要搜索的关键字例如 ?1213
按 n 向上查找关键字
shift+n 反向查找关键字

ok,知道在nanguaHost6这台机器起的AM了。
-
查看AM log
在{Hadoop_HOME}/logs/userlogs/下就有application日志目录,一直进到里面,可以看到如下文件:

-
stderr:输出System.err输出信息;
-
stdout:输出System.out输出信息;
-
syslog:输出日志工具(log4j)输出的信息。
查看syslog
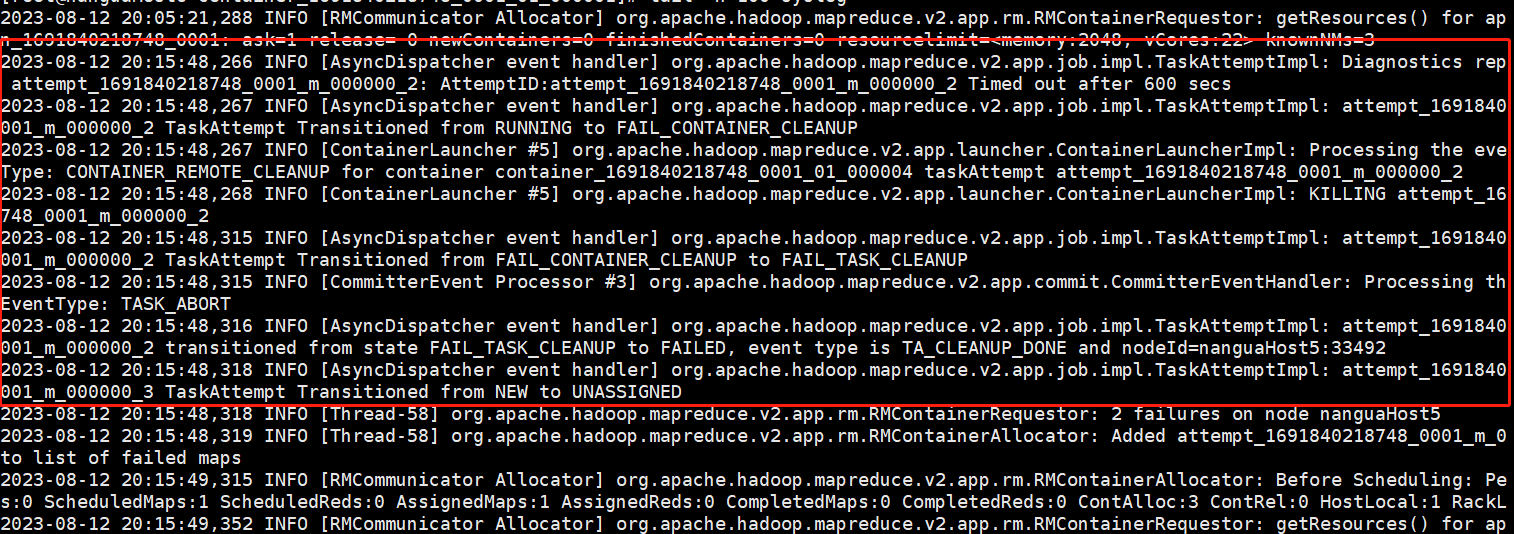
`截取三句主要的信息`
2023-08-12 20:15:48,266 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: Diagnostics repo attempt_1691840218748_0001_m_000000_2: AttemptID:attempt_1691840218748_0001_m_000000_2 Timed out after 600 secs
`这里是说有task_attempt attempt_1691840218748_0001_m_000000_2超时了`
2023-08-12 20:15:48,267 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: attempt_16918402001_m_000000_2 TaskAttempt Transitioned from RUNNING to FAIL_CONTAINER_CLEANUP
`这里说将这个attempt_1691840218748_0001_m_000000_2的状态从运行转为失败容器cleanup,也就是说这个attempt失败了`
2023-08-12 20:15:48,316 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: attempt_16918402001_m_000000_2 transitioned from state FAIL_TASK_CLEANUP to FAILED, event type is TA_CLEANUP_DONE and nodeId=nanguaHost5:33492
`这里可以看出这个attempt是跑在nanguaHost5上面的`
- 查看nanguaHost5的syslog。
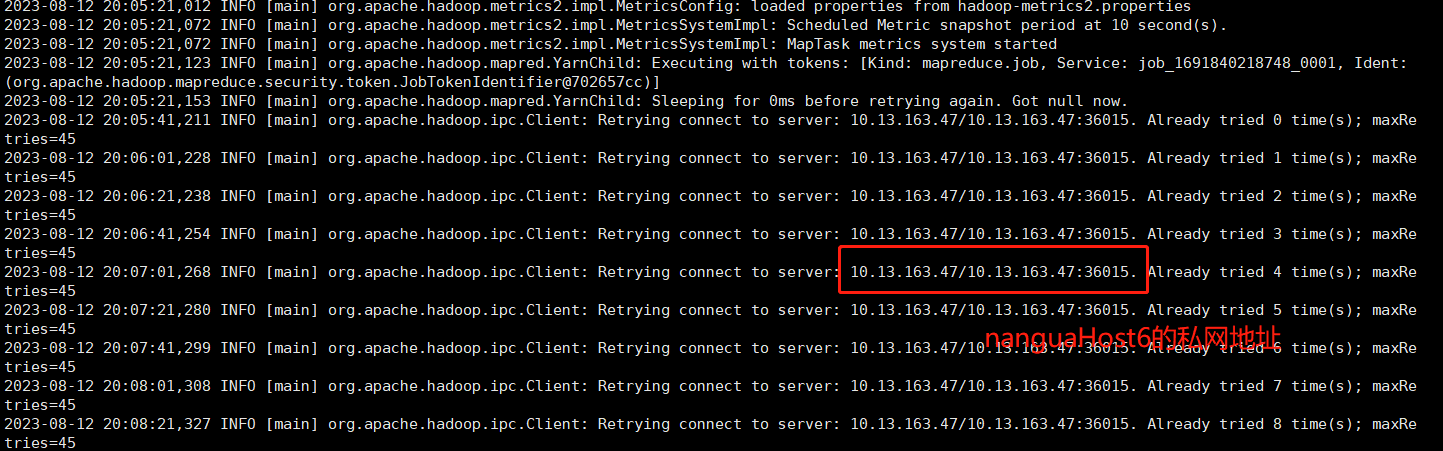
发现nanguaHost5一直向nanguaHost6的私网地址发送信号,这肯定是连不通的。
解决方案
我查了一些资料,发现可能是/etc/hosts的配置问题。
将全部节点的127.0.1.1 xxxxxx的行数据全部注释掉后,重启yarn集群。

重新跑job,发现问题解决,nanguaHost5已经通过公网地址连接nanguaHost6了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号