会员
周边
新闻
博问
闪存
赞助商
YouClaw
所有博客
当前博客
我的博客
我的园子
账号设置
会员中心
简洁模式
...
退出登录
注册
登录
nangk
博客园
首页
新随笔
联系
订阅
管理
2023年8月28日
IDMapping实现详解
摘要: ## IDMapping的意义 现实存在的问题: 对于一个系统而言,标识用户的方式有很多,用户ID、手机号、身份证号、设备ID等等;那如何确认用户的唯一标识呢?如果只是采用用户ID,那么如果用户没有登录的日志记录就失去价值了; 再对于多个系统而言,如何让多系统中的一个自然人只有一个唯一标识呢
阅读全文
posted @ 2023-08-28 17:43 nangk
阅读(1176)
评论(0)
推荐(0)
2023年8月22日
Hive执行计划详解
摘要: ## 什么是Hive SQL执行计划 Hive SQL执行计划描绘了SQL实际执行的整体轮廓,即**SQL转化为对应计算引擎的执行逻辑**;毫无疑问,这一块对于Hive SQL的优化是非常重要的。 Hive SQL早期是基于规则的方式生成执行计划,在Hive 0.14及之后,集成了Apache Ca
阅读全文
posted @ 2023-08-22 20:59 nangk
阅读(888)
评论(0)
推荐(0)
2023年8月21日
数据存储与压缩问题
摘要: > 选择适合的底层数据存储格式,可以极大得提升性能。 ## MR中常见的数据压缩格式  ## Hive数据存储格式
阅读全文
posted @ 2023-08-21 15:24 nangk
阅读(198)
评论(0)
推荐(0)
小文件问题
摘要: ## Hadoop小文件问题 **小文件是指比HDFS默认块大小明显小得多的文件。** ### 小文件导致了什么问题 对于存储层来说,大量小文件会产生大量的元数据信息;当NN重启时,必须将元数据信息加载到内存中,大量元数据信息会导致NN重启速度非常慢;并且,太多小文件也会导致NN在DN耗尽磁盘空间之
阅读全文
posted @ 2023-08-21 10:13 nangk
阅读(96)
评论(0)
推荐(0)
2023年8月20日
数据倾斜问题
摘要: ## 数据倾斜的简介 数据倾斜即单个节点任务处理的数据量远高于同类型任务处理的数据量,成为整个作业的性能瓶颈。 本文将从产生数据倾斜的原因、不同计算引擎下的解决方法讨论。 ## 数据倾斜的场景和对应的解决方案 ### Suffle过程 数据倾斜和Suffle过程是密不可分的,Suffle过程在MR和
阅读全文
posted @ 2023-08-20 15:09 nangk
阅读(169)
评论(0)
推荐(0)
2023年8月16日
数据及报表概况
摘要: # 数据及报表概况 ## 数据概况 由于是模拟日志,因此日志包含的信息是已知可控的。如果是生产场景的话,是需要进行ETL的,即需要从多个业务系统抽取数据到数仓。ETL的工作包含:数据探索、ETL策略、数据映射和存储过程开发。 - 数据探索:从技术上看,业务系统的数据库信息、库表信息、字段信息可能是模
阅读全文
posted @ 2023-08-16 21:46 nangk
阅读(70)
评论(0)
推荐(0)
项目概况与技术方案
摘要: # 项目概况与技术方案 ## 概述 该项目是一个针对用户行为日志分析的T+1离线数仓项目;通过构建数仓分析,了解用户的活跃情况、交互情况、流量概况等信息。数仓通过云服务器集群进行部署,开发后端程序提供服务接口。参考《大数据之路:阿里巴巴大数据实践》,该数仓构建了ODS层、DWD层、DWS层、AD
阅读全文
posted @ 2023-08-16 20:59 nangk
阅读(135)
评论(0)
推荐(0)
2023年8月13日
深入MapReduce计算引擎
摘要: # 深入MapReduce计算引擎 ## MapReduce整体处理过程 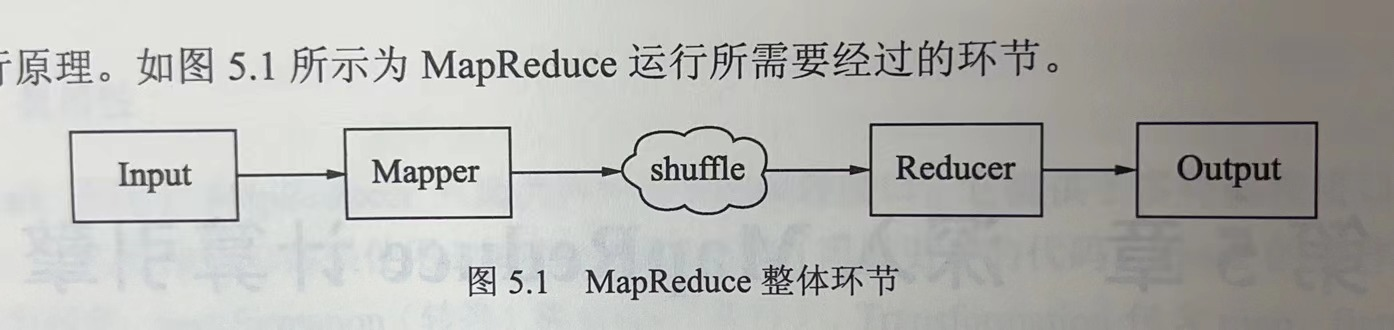 MapReduce的运行需要经过inpu
阅读全文
posted @ 2023-08-13 20:53 nangk
阅读(93)
评论(0)
推荐(0)
问题排查Hive本地计算模式失败
摘要: # 问题排查Hive本地计算模式失败 ==查看hive.log后发现是**java space heap**,也就是java内存溢出。== ### 解决方案: 1. 配置yarn集群的资源分配。 - 由于是本地计算,因此container一定是申请在本地的,限制AM申请container容器资源的大
阅读全文
posted @ 2023-08-13 20:25 nangk
阅读(114)
评论(0)
推荐(0)
问题排查org
摘要: # 问题排查org.apache.hadoop.ipc.Client > 背景是在三台云服务器上部署Hadoop集群,当提交job到yarn上执行时,一直处在map阶段,记录一下排查问题的过程。 
评论(0)
推荐(0)
下一页
公告
 浙公网安备 33010602011771号
浙公网安备 33010602011771号