python企业面试真面持续更新中
- 1.软件的生命周期
- 2.如何知道一个python对象的类型
- 3.简述Django的设计模式MVC,以及你对各层的理解和用途
- 4.什么是lambda函数,说明其使用场景
- 5.python是否支持函数重载和函数重写?若支持,请用代码举例
- 6.python如何判断字符串是浮点数
- 7.查询2016年以来进公司的所有员工中工资最高的员工的信息(SQL语句)
- 8.mysql查询平均工资最高的部门名称和该部门的平均工资
- 9.以下代码输出什么
- 10.请写出一段python代码实现删除一个list里面的重复元素
- 11.HTTP协议基于TCP还是UDP协议,TCP和UDP协议有什么区别
- 12.python写一个判断邮箱地址有效性的函数,判断邮箱地址是否有效
- 13.设计三个线程分别为t1,t2,t3,循环打印数字123,要求输出的数字顺序为 123123123
- 14.给定一个连续且无序的序列1 4 3 2 5 7 9 8 10,其中少了一个数字6,请设计算法找出丢失的数字,算法复杂度越低越好。
- 15.什么是设计模式?简述之前用过的设计模式
- 16.什么叫观察者模式?解决什么问题
- 17.简述面向对象中__new__和__init__区别
- 18.简述with方法打开处理文件帮我我们做了什么?
- 19.列表[1,2,3,4,5],请使用map()函数输出[1,4,9,16,25],并使用列表推导式提取出大于10的数,最终输出[16,25]
- 20.python中生成随机整数、随机小数、0--1之间小数方法
- 21.python中断言方法举例
- 22.数据表student有id,name,score,city字段,其中name中的名字可有重复,需要消除重复行,请写sql语句
- 23.10个Linux常用命令
- 24.python2和python3区别?列举5个
- 25.python异常处理机制和开发中的体会
- 26.python有什么特点和其他语言相比
- 27.补充缺失的代码
- 28.python里如何实现tuple和list的转换
- 29.写出一段Python代码实现删除一个list里面的重复元素
- 30.python用sort()函数对列表进行排序,从最后一个元素开始判断
- 31.Python中如何拷贝一个对象?(赋值、深拷贝、浅拷贝的区别)
- 32.python range()函数的用法
- 33.如何用Python来进行查询和替换一个文本字符串
- 34.代码片段存在的问题
- 35.Python编程——青蛙跳台阶问题
- 36.Python如何进行内存管理的
- 37.用一条SQL语句查询总分为前3名的学生姓名,表名为table
- 38.用一条SQL语句查询出每门课程大于80分的学生姓名,表名为table
1.软件的生命周期
软件生命周期是指软件从开始研制到最终被废弃所经历的各个阶段。在不同的阶段里,由不同1的组织和人员执行不同的任务,需要消耗不同的资源。
生命周期常见的有:瀑布模型、V模型、敏捷开发模型。
阶段:需求分析->软件设计->程序编码->软件测试->运行维护
2.如何知道一个python对象的类型
一、 type() 方法的语法:
type(name, bases, dict),其中name是类的名称,bases是基类的元组,dict是类内定义的命名空间变量。当有一个参数时它的返回值是对象类型, 有三个参数时,返回值是新的类型对象。
二、isinstance() 方法的语法:
isinstance(object, classinfo),其中object 是实例对象,变量,classinfo 可以是直接或间接类名、基本类型或者由它们组成的元组(如tuple,dict,int,str,float,list,set,bool,class类等)。如果对象的类型与classinfo相同则返回 值为True,否则返回值为 False。
重点说一下这两者的区别:
在判断子类上这两个函数不一样。type()不会认为子类是父类的类型,不考虑继承关系;isinstance()会认为子类是父类的类型,考虑继承关系。
3.简述Django的设计模式MVC,以及你对各层的理解和用途
MVC:软件架构思想
简介:
MVC开始是存在于桌面程序中的,M是指业务模型 model,V是指用户界面 view,C则是控制器 controler,使用MVC的目的是将M和V的实现代码分离,从而使同一个程序可以使用不同的表现形式。比如一批统计数据可以分别用柱状图、饼图来表示。C存在的目的则是确保M和V的同步,一旦M改变,V应该同步更新
4.什么是lambda函数,说明其使用场景
Lambda 函数又称匿名函数,有些函数如果只是临时一用,而且它的业务逻辑也很简单时,就没必要非给它取个名字不可
下面的场景是比较适合使用 lambda 表达式的:
你所要做的操作是不重要的: 函数不值得一个名称
使用 lambda 表达式比你所能想到的函数名称让代码更容易理解
你很确定还没有一个函数能满足你的需求
你团队的每个人都了解 lambda 表达式, 并且都同意使用它们
5.python是否支持函数重载和函数重写?若支持,请用代码举例
什么是函数重载?简单的理解,支持多个同名函数的定义,只是参数的个数或者类型不同,在调用的时候,解释器会根据参数的个数或者类型,调用相应的函数。
python中参数不明确类型,参数可以有默认值、有变长参数,所以不支持重载
在自定义类内添加相应的方法,让自定义类创建的实例能像内建对象一样进行内建函数操作,这就是函数重写。
对象转字符串函数的重写方法:
repr(obj) 函数的重写方法:
`def __repr__(self):`
str(obj) 函数的重写方法:
`def __str__(self):`
说明:
- str(obj) 函数先查找, obj.str()方法,调用此方法并返回结果
- 如果没有obj.str()方法时,则返回obj.repr()方法的结果并返回
- 如果obj.__repr__方法不存在,则调用object类的__repr__实例方法显示<main.XXXX object at 0xAABBCCDD>格式的字符串
str:在调用print打印对象的时候,会被自动调用,默认返回的对象的地址【给程序员使用的】
repr:在Python解释器中调用的方法【给计算机使用的】
# 此示例示意通过重写 repr 和 str方法改变转为字符串的规则
class MyNumber:
def __init__(self, value):
'构造函数,初始化MyNumber对象'
self.data = value
def __str__(self):
'''转换为普通人识别的字符串'''
# print("__str__方法被调用!")
return "自定义数字类型对象: %d" % self.data
def __repr__(self):
'''转换为eval能够识别的字符串'''
return 'MyNumber(%d)' % self.data
n1 = MyNumber(100)
n2 = MyNumber(200)
print('repr(n1) ====>', repr(n1))
print('str(n2) ====>', str(n2))
结果:
repr(n1) ====> MyNumber(100)
str(n2) ====> 自定义数字类型对象: 200
6.python如何判断字符串是浮点数
str为字符串s为字符串
str.isalnum() 所有字符都是数字或者字母
str.isalpha() 所有字符都是字母
str.isdigit() 所有字符都是数字
str.isspace() 所有字符都是空白字符、\t、\n、\r
isinstance(a,float)
def is_number(str):
try:
# 因为使用float有一个例外是'NaN'
if str=='NaN':
return False
float(str)
return True
except ValueError:
return False
# float例外示例
>>> float('NaN')
nan
7.查询2016年以来进公司的所有员工中工资最高的员工的信息(SQL语句)
select d.name as Department,
e.name as Employee,e.Salary as Salary
FROM Employee e
join Department d
on e.DepartmenId = d.Id
and e.Salary >=
(SELECT max(Salary) FROM Employee e1 having e.DepartmentId = e1.DepartmentId and YEAR(date) > '2016')
8.mysql查询平均工资最高的部门名称和该部门的平均工资
SELECT e.departmentid,AVG(e.salary) avgsal
FROM employee e
GROUP BY departmentid
HAVING
avgsal = (
SELECT
MAX(t.avgsal) maxsal
FROM (
SELECT departmentid,AVG(salary) avgsal
FROM employee
GROUP BY departmentid) t
)
9.以下代码输出什么
def f(x,l=[]):
for i in range(x):
l.append(i*i)
print(l)
f(2)
f(3,[3,2,1])
f(3)
结果:
[0, 1]
[3, 2, 1, 0, 1, 4]
[0, 1, 0, 1, 4]
why:
可以先不看f(3,[3,2,1]),这个就是来迷惑人的,光看f(2),f(3),Python函数在定义的时候,默认参数L,它指向一个对象[ ],这个对象是和函数同生同死的,每次调用该函数,都会默认指向[ ] ,除非传递了第二个参数,则改变了L的指向,但是如果前面修改了这个对象,所以也会在后面体现出来,因为他是一个默认指向的对象。所以,定义默认参数要牢记一点:默认参数必须指向不变对象!
10.请写出一段python代码实现删除一个list里面的重复元素
# 例如 lista = (2,4,5,6,5,2,4,7,9,3) ,输出(2,4,6,5,7,9,3)
l1 = (2,4,5,6,5,2,4,7,9,3)
l2 = sorted(set(l1),key=l1.index)
print(l2)
11.HTTP协议基于TCP还是UDP协议,TCP和UDP协议有什么区别
http:是用于www浏览的一个协议。
tcp:是机器之间建立连接用的到的一个协议。
1、TCP/IP是个协议组,可分为三个层次:网络层、传输层和应用层。
在网络层有IP协议、ICMP协议、ARP协议、RARP协议和BOOTP协议。
在传输层中有TCP协议与UDP协议。
在应用层有FTP、HTTP、TELNET、SMTP、DNS等协议。
因此,HTTP本身就是一个协议,是从Web服务器传输超文本到本地浏览器的传送协议。
虽然HTTP本身是一个协议,但其最终还是基于TCP的。
区别:
面向连接的TCP
“面向连接”就是在正式通信前必须要与对方建立起连接。一个TCP连接必须要经过三次“对话”才能建立起来
面向非连接的UDP协议
“面向非连接”就是在正式通信前不必与对方先建立连接,不管对方状态就直接发送。UDP 适用于一次只传送少量数据、对可靠性要求不高的应用环境。
| TCP | UDP | |
|---|---|---|
| 是否连接 | 面向连接 | 面向非连接 |
| 传输可靠性 | 可靠 | 不可靠 |
| 应用场合 | 传输大量的数据,对可靠性要求较高的场合 | 传送少量数据、对可靠性要求不高的场景 |
| 速度 | 慢 | 快 |
12.python写一个判断邮箱地址有效性的函数,判断邮箱地址是否有效
import re
re_email = re.compile(r'^[a-zA-Z\.]+@[a-zA-Z0-9]+\.[a-zA-Z]{3}$')
def is_valid_email(addr):
if re_email.match(addr):
print("True")
m = re.match(r'^([a-zA-Z\.0-9]+)@[a-zA-Z0-9]+\.[a-zA-Z]{3}$',addr)
print(m.group(1))
else :
print('False')
is_valid_email('someone@gmail.com')
13.设计三个线程分别为t1,t2,t3,循环打印数字123,要求输出的数字顺序为 123123123
import threading
import sys
import time
def showa():
while True:
lockc.acquire() # 获取对方的锁,释放自己的锁
print('1', end=',')
sys.stdout.flush() # 释放缓冲区
locka.release()
time.sleep(0.2)
def showb():
while True:
locka.acquire()
print('2', end=',')
sys.stdout.flush()
lockb.release()
time.sleep(0.2)
def showc():
while True:
lockb.acquire()
print('3', end=',')
sys.stdout.flush()
lockc.release()
time.sleep(0.2)
if __name__ == '__main__':
locka = threading.Lock() # 定义3个互斥锁
lockb = threading.Lock()
lockc = threading.Lock()
t1 = threading.Thread(target=showa) # 定义3个线程
t2 = threading.Thread(target=showb)
t3 = threading.Thread(target=showc)
locka.acquire() # 先锁住a,b锁,保证先打印a
lockb.acquire()
t1.start()
t2.start()
t3.start()
14.给定一个连续且无序的序列1 4 3 2 5 7 9 8 10,其中少了一个数字6,请设计算法找出丢失的数字,算法复杂度越低越好。
li=[1,4,3,2,5,7,9,8,10]
for i in range(1,11):
if not li.__contains__(i):
print('丢失的数:',i)
15.什么是设计模式?简述之前用过的设计模式
设计模式(Design pattern)是一套被反复使用、多数人知晓的、经过分类编目的、代码设计经验的总结。使用设计模式是为了可重用代码、让代码更容易被他人理解、保证代码可靠性。
单例模式:Python 的单例模式最好不要借助类(在 Java 中借助类是因为 Java 所有代码都要写在类中),而是通过一个模块来实现。一个模块的模块内全局变量、模块内全局函数,组合起来就是一个单例对象了。
模板方法模式:这个可以像其他语言一样实现,但是如果要遵循鸭子类型原则的话,应该删除公有的抽象父类(或接口),从而追求灵活性。
工厂方法模式、多例模式:这个也不用借助类,直接写一个全局函数作为工厂函数即可。因为 Python 中实例化是通过 call 类来完成的,现在改成 call 工厂函数,对客户抠码者是透明的。(从这点我表示理解 Python 没有 new 操作符的好处了,使用通用的 call 定义,正交性极强)
装饰器模式、代理模式:这个接触过 Python 就不会不知道了,Python 内置的 decorator 语法如此著名。装饰器模式和代理模式都可以通过这种方式完成。另外一种是对对象的装饰或代理,这个也不需要按照契约编程的风格,让代理对象实现被代理对象的抽象。一切动态代理,只需要通过重载属性访问操作符,神马都简单了(和 PHP 通过 __get、__set、__call 来实现动态代理很类似)。
原型模式:这个在 Python 中实现的不是那么爽快,需要调用 copy 来克隆原型对象。但是其实有另一种实现方式:之所以使用原型模式,是因为对象初始化需要较大开销。我们只需要保存初始化的结果,并在产生新对象的时候赋予新对象即可。所以,通过元类控制对象被创建的过程,来实现原型模式,也是一种选择。
https://www.cnblogs.com/tangkaishou/p/9246353.html代码实现
16.什么叫观察者模式?解决什么问题
观察者模式:观察者模式定义了对象之间的一对多依赖,这样当一个对象改变状态时,它的所有对象都会收到依赖并且自动更新。
为了交互对象之间的松耦合而努力。
1.白话栗子
市里新修了一个图书馆,现在招募一个图书管理员叫T,T知道图书馆里的图书更新和借阅等信息。现在有三个同学甲乙丙想去了解以后几个月的图书馆图书信息和借阅信息,于是它们去T那里注册登记。当图书馆图书更新后,T就给注册了的同学发送图书更新信息。三个月后,丙不需要知道图书更新信息了,于是就去T那儿注销了它的信息。所以,以后,只有甲乙会收到消息。几个月后,丁也去图书馆注册了信息,所以以后甲乙丁会收到图书更新信息。
2.原理
当我们遇到一个多对一的依赖关系时,就可以用观察者模式。观察者模式有一个被观察者(subject)和多个观察者(observer)。被观察者提供注册、删除、通知的功能,观察者提供数据更新和展示等功能。
上面栗子中,T就是一个被观察者,T提供了注册身份信息的功能、删除信息的功能和给甲乙丙丁发送通知的功能,而甲乙丙丁就是观察者,更新它们从T那个获取的信息。
3.好处
独立封装,互不影响:观察者和被观察者都是独自封装好的,观察者之间并不会相互影响
热插拔:在软件运行中,可以动态添加和删除观察者
class Subject(object):
def __init__(self):
self._observers = [] #观察者列表
#注册功能
def attach(self, observer):
if observer not in self._observers:
self._observers.append(observer)
#删除功能
def delete(self, observer):
try:
self._observers.remove(observer)
except ValueError:
pass
#通知功能
def notify(self, modifier=None):
for observer in self._observers:
if modifier != observer:
observer.update(self)
#被观察者数据来源
class Data(Subject):
def __init__(self, name=''):
Subject.__init__(self)
self.name = name
self._data = 0
@property
def data(self):
return self._data
@data.setter
def data(self, value):
self._data = value
self.notify()
#观察者
class Viewer:
def __init__(self, name=''):
self._name = name
def update(self, subject):
print('my name is ', self._name, 'and', subject.name, '***', subject.data)
if __name__ == '__main__':
data1 = Data('管理员T')
view1 = Viewer('甲')
data1.attach(view1)
view2 = Viewer('乙')
data1.attach(view2)
view3 = Viewer('丙')
data1.attach(view3)
print('data1初始值')
print(data1.data)
print('改变data1的值')
data1.data = 5
print('再次改变data1的值')
data1.data = 10
print('删除view3后')
data1.delete(view3)
data1.data = 90
17.简述面向对象中__new__和__init__区别
__init__是初始化方法,创建对象后,就立刻被默认调用了,可接收参数,如图

1、__new__至少要有一个参数cls,代表当前类,此参数在实例化时由Python解释器自动识别
2、__new__必须要有返回值,返回实例化出来的实例,这点在自己实现__new__时要特别注意,可以return父类(通过super(当前类名, cls))__new__出来的实例,或者直接是object的__new__出来的实例
3、__init__有一个参数self,就是这个__new__返回的实例,__init__在__new__的基础上可以完成一些其它初始化的动作,__init__不需要返回值
4、如果__new__创建的是当前类的实例,会自动调用__init__函数,通过return语句里面调用的__new__函数的第一个参数是cls来保证是当前类实例,如果是其他类的类名,;那么实际创建返回的就是其他类的实例,其实就不会调用当前类的__init__函数,也不会调用其他类的__init__函数。

18.简述with方法打开处理文件帮我我们做了什么?

打开文件在进行读写的时候可能会出现一些异常状况,如果按照常规的f.open
写法,我们需要try,except,finally,做异常判断,并且文件最终不管遇到什么情况,都要执行finally f.close()关闭文件,with方法帮我们实现了finally中f.close
(当然还有其他自定义功能,有兴趣可以研究with方法源码)
19.列表[1,2,3,4,5],请使用map()函数输出[1,4,9,16,25],并使用列表推导式提取出大于10的数,最终输出[16,25]
map()函数第一个参数是fun,第二个参数是一般是list,第三个参数可以写list,也可以不写,根据需求

20.python中生成随机整数、随机小数、0--1之间小数方法
随机整数:random.randint(a,b),生成区间内的整数
随机小数:习惯用numpy库,利用np.random.randn(5)生成5个随机小数
0-1随机小数:random.random(),括号中不传参

21.python中断言方法举例
assert()方法,断言成功,则程序继续执行,断言失败,则程序报错
'''
断言
'''
a = 5
assert (a>1)
print("断言成功,程序继续进行")
assert (a>7)
print("断言失败,程序报错")
22.数据表student有id,name,score,city字段,其中name中的名字可有重复,需要消除重复行,请写sql语句
select distinct name from student
23.10个Linux常用命令
ls pwd cd touch rm mkdir tree cp mv cat more grep echo
24.python2和python3区别?列举5个
1、Python3 使用 print 必须要以小括号包裹打印内容,比如 print('hi')
Python2 既可以使用带小括号的方式,也可以使用一个空格来分隔打印内容,比如 print 'hi'
2、python2 range(1,10)返回列表,python3中返回迭代器,节约内存
3、python2中使用ascii编码,python中使用utf-8编码
4、python2中unicode表示字符串序列,str表示字节序列
python3中str表示字符串序列,byte表示字节序列
5、python2中为正常显示中文,引入coding声明,python3中不需要
6、python2中是raw_input()函数,python3中是input()函数
25.python异常处理机制和开发中的体会
无论是多优秀的程序员,都无法保证自己写的程序永远不会出错,即便程序没有错误,也无法保证用户总是按自己的意愿来输入,就算用户都是非常“聪明而且配合”的,也无法保证运行该程序的操作系统永远稳定,无法保证运行该程序的硬件不会突然坏掉,无法保证网络永远通畅……无法保证的情况太多了。但作为一个程序设计人员,我们需要尽可能预知所有可能发生的情况,尽可能保证程序在所有糟糕的情形下都能正常运行。
在代码开发的过程中,经常或碰到一些错误异常情况,对于Python来说,自有一套规范的处理体系
try...except...finally...
26.python有什么特点和其他语言相比
Python 是一种面向对象、解释型的脚本语言,同时也是一种功能强大而完善的通用型语言。相比其他编程语言(比如 Java),Python 代码非常简单,上手非常容易。
Python优点:
(1)简单易学
(2)开源
(3)高级语言
(4)解释性语言
一个用编译型语言(如 C 或 C++)写的程序,可以从源文件转换到一个计算机使用的语言。这个过程主要通过编译器完成。当运行程序的时候,我们可以把程序从硬盘复制到内存中并且运行。而 Python 语言写的程序,则不需要编译成二进制代码,可以直接从源代码运行程序。在计算机内部,由 Python 解释器把源代码转换成字节码的中间形式,然后再把它翻译成计算机使用的机器语言并运行。
(5)可移植性
由于 Python 是开源的,它已经被移植到许多平台上。如果能够避免使用依赖系统的特性,那就意味着,所有 Python 程序都无需修改就可以在好多平台上运行,包括 Linux 、Windows、FreeBSD、Solaris 等等,甚至还有 PocketPC、Symbian 以及 Google 基于 Linux 开发的 Android 平台。
(6)强大的功能
从字符串处理到复杂的 3D 图形编程,Python 借助扩展模块都可以轻松完成。
(7)可扩展性
Python 的可扩展性体现为它的模块,Python 具有脚本语言中最丰富和强大的类库,这些类库覆盖了文件 I/O、GUI、网络编程、数据库访问、文本操作等绝大部分应用场景。
Python 可扩展性一个最好的体现是,当我们需要一段关键代码运行的更快时,可以将其用 C 或 C++ 语言编写,然后在 Python 程序中使用它们即可。
缺点:
- 速度慢:Python 程序比 Java、C、C++ 等程序的运行效率都要慢。
- 源代码加密困难:不像编译型语言的源程序会被编译成目标程序,Python 直接运行源程序,因此对源代码加密比较困难。
27.补充缺失的代码
def print_directory_contents(sPath):
"""
这个函数接受文件夹的名称作为输入参数,
返回该文件夹中文件的路径,
以及其包含文件夹中文件的路径。
"""
import os
def print_directory_contents(sPath):
# 遍历指定文件夹sPath包含的文件或文件夹的列表
for sChild in os.listdir(sPath):
# 获取指定文件夹下的子文件夹,os.path.join()函数用于路径拼接文件路径
sChildPath=os.path.join(sPath,sChild)
# 判断sChildPath路径是否为目录
if os.path.isdir(sChildPath):
# 若是,开始递归
print_directory_contents(sChildPath)
else:
print(sChildPath)
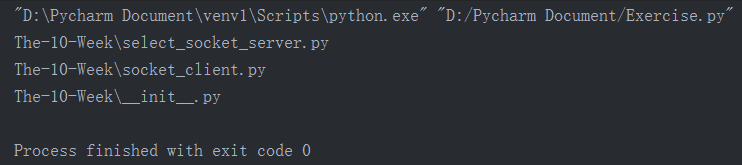
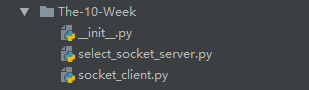
print_directory_contents("The-10-Week")
28.python里如何实现tuple和list的转换
#list to tuple
lis=[1,2,3,4,5,6]
x=tuple(lis)
print(type(x),x)
#tuple to list
tup=(1,2,3,4,5,6)
y=list(tup)
print(type(y),y)
29.写出一段Python代码实现删除一个list里面的重复元素
1.使用set函数
>>> list1 = [7,8,7,8,9,10]
>>> set(list1)
{8, 9, 10, 7}
2.使用字典函数
>>> list1 = [7,8,7,8,9,10]
>>> b = dict.fromkeys(list1)
>>> b
{7: None, 8: None, 9: None, 10: None}
>>> c = list(b.keys())
>>> c
[7, 8, 9, 10]
30.python用sort()函数对列表进行排序,从最后一个元素开始判断
a = [1, 2, 3, 4, 4, 5, 6, 7, 7, 9, 0]
a.sort()
last = a[-1]
for i in range(len(a)-2, -1, -1):
if last == a[i]:
del a[i]
else:
last = a[i]
print(a)
运行结果:[0, 1, 2, 3, 4, 5, 6, 7, 9]
31.Python中如何拷贝一个对象?(赋值、深拷贝、浅拷贝的区别)
在python中,对象赋值实际上是对象的引用。当创建一个对象,然后把它赋给另一个变量的时候,python并没有拷贝这个对象,而只是拷贝了这个对象的引用
赋值(=),就是创建了对象的一个新的引用,修改其中任意一个变量都会影响到另一个。
浅拷贝:创建一个新的对象,但它包含的是对原始对象中包含项的引用(如果用引用的方式修改其中一个对象,另外一个也会修改改变){1,完全切片方法;2,工厂函数,如list();3,copy模块的copy()函数}
深拷贝:创建一个新的对象,并且递归的复制它所包含的对象(修改其中一个,另外一个不会改变){copy模块的deep.deepcopy()函数}
32.python range()函数的用法
一、在Python开发应用中 range函数相当重要,也比较常用:
首先看range函数的原型: range(start, end, scan)
参数解析:
start:计数从start开始。默认是从0开始。例如range(5)等价于range(0, 5);
end:技术到end结束,但不包括end.例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5(俗称:包前不包后)
scan:每次跳跃的间距,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)33.
33.如何用Python来进行查询和替换一个文本字符串
可以使用sub()方法来进行查询和替换,sub方法的格式为:sub(replacement, string[, count=0])
replacement是被替换成的文本
string是需要被替换的文本
count是一个可选参数,指最大被替换的数量
例子:
import re
p = re.compile(‘(blue|white|red)’)
print(p.sub(‘colour’,'blue socks and red shoes’))
print(p.sub(‘colour’,'blue socks and red shoes’, count=1))
输出:
colour socks and colour shoes
colour socks and red shoes
34.代码片段存在的问题
一道改错的题目, 可以获得很多启发, 题目如下:
from amodule import * # amodule is an exist module
class dummyclass(object):
def __init__(self):
self.is_d = True
pass
class childdummyclass(dummyclass):
def __init__(self, isman):
self.isman = isman
@classmethod
def can_speak(self): return True
@property
def man(self): return self.isman
if __name__ == "__main__":
object = new childdummyclass(True)
print object.can_speak()
print object.man()
print object.is_d
解答:
- 警告: object是python新形式(new style)的一个基础类, 不应该被重新定义;
- 警告: 类方法(classmethod)是类所拥有的方法, 传入的参数应该是cls, 而不是self;
- 错误: Python没有new关键字, 如需修改new, 如单例模式, 可以重写(override)new;
- 错误: @property, 表示属性, 不是方法, 则不需要加括号”()”, 直接调用object.man,即可;
- 错误: 如果想使用基类的成员, 则需要初始化(init)基类, 如dummyclass.init(self),即可;
- 额外: 类名尽量使用大写.
结果
class dummyclass(object):
def __init__(self):
self.is_d = True
pass
class childdummyclass(dummyclass):
def __init__(self, isman):
dummyclass.__init__(self) #init
self.isman = isman
@classmethod
def can_speak(cls): return True #cls
@property
def man(self): return self.isman
if __name__ == "__main__":
o = childdummyclass(True) #new, object
print o.can_speak()
print o.man #property
print o.is_d
输出
True True True
35.Python编程——青蛙跳台阶问题
一只青蛙一次可以跳上1级台阶,也可以跳上2级。求该青蛙跳上一个n级的台阶总共有多少种跳法。
- 分析
假设只有1个台阶,则总共有f(1)=1种跳法;
假设有2个台阶,则总共有f(2)=2种跳法;
假设有n个台阶,那么第1步就有两种情况,跳1步和跳2步:
跳1步,那么接下去的就是跳f(n-1);
跳2步,那么接下去的就是跳f(n-2);
所以,总数是f(n-1)+f(n-2)。
def frog(num):
if num <= 2:
return num
t1, t2 = 1, 2
for _ in range(3, num+1):
t1, t2 = t2, t1+t2
return t2
题目二(变态跳台阶)
一只青蛙一次可以跳上1级台阶,也可以跳上2级......它也可以跳上n阶。求该青蛙跳上一个n级的台阶总共有多少种跳法
分析:
相比之前的跳台阶,这次可以从任意台阶跳上n级,所以总体来看与上一个问题差不多,只不过递归公式应该是各个台阶之和再加上直接跳上去的情况,所以总数应该是f(n-1)+f(n-2)+f(n-3)+...+f(2)+f(1)=2**n-1。
主要代码:
def frog(num):
if num==0:
return 0
return 2**(num-1)
36.Python如何进行内存管理的
Python引入了一个机制:引用计数。
python内部使用引用计数,来保持追踪内存中的对象,Python内部记录了对象有多少个引用,即引用计数,当对象被创建时就创建了一个引用计数,当对象不再需要时,这个对象的引用计数为0时,它被垃圾回收。
垃圾回收
1、当内存中有不再使用的部分时,垃圾收集器就会把他们清理掉。它会去检查那些引用计数为0的对象,然后清除其在内存的空间。当然除了引用计数为0的会被清除,还有一种情况也会被垃圾收集器清掉:当两个对象相互引用时,他们本身其他的引用已经为0了。
2、垃圾回收机制还有一个循环垃圾回收器, 确保释放循环引用对象(a引用b, b引用a, 导致其引用计数永远不为0)。
在Python中,许多时候申请的内存都是小块的内存,这些小块内存在申请后,很快又会被释放,由于这些内存的申请并不是为了创建对象,所以并没有对象一级的内存池机制。这就意味着Python在运行期间会大量地执行malloc和free的操作,频繁地在用户态和核心态之间进行切换,这将严重影响Python的执行效率。为了加速Python的执行效率,Python引入了一个内存池机制,用于管理对小块内存的申请和释放。
内存池机制
Python提供了对内存的垃圾收集机制,但是它将不用的内存放到内存池而不是返回给操作系统。
Python中所有小于256个字节的对象都使用pymalloc实现的分配器,而大的对象则使用系统的 malloc。另外Python对象,如整数,浮点数和List,都有其独立的私有内存池,对象间不共享他们的内存池。也就是说如果你分配又释放了大量的整数,用于缓存这些整数的内存就不能再分配给浮点数。
37.用一条SQL语句查询总分为前3名的学生姓名,表名为table
SELECT name FROM table GROUP BY name ORDER BY sum(fenshu) DESC LIMIT 0,3;
38.用一条SQL语句查询出每门课程大于80分的学生姓名,表名为table
select distinct name from aa where name not in (select distinct name from aa where fengshu<=80)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号