Automatic Detection of Machine Generated Text: A Critical Survey
1、题目
Automatic Detection of Machine Generated Text: A Critical Survey
Comments: The 28th International Conference on Computational Linguistics (COLING), 2020
Subjects: Computation and Language (cs.CL); Artificial
参考链接:https://ai-scholar.tech/zh/articles/survey/tgmdetector
2、摘要
文本生成模型(TGMs)擅长于生成与人类语言风格相当匹配的文本,这样的TGM可能会被对手滥用,例如,自动生成假新闻和假产品评论,看起来很真实,可以骗过人类。能够将TGM生成的文本与人类书写的文本区分开来的检测器在减轻TGM的这种滥用方面发挥着重要作用。最近,自然语言处理(NLP)和机器学习(ML)社区都有大量的工作,以建立准确的英语检测器。尽管这个问题很重要,但目前还没有任何工作对这些快速增长的文献进行调查,并向新人介绍重要的研究挑战。在这项工作中,作者提供了对这一文献的重要调查和回顾,以促进对这一问题的全面理解。
3、介绍
3.1 存在问题
目前最先进的文本生成模型(TGMs)擅长生成接近人类语言风格的文本,特别是在语法、流畅性、连贯性和现实世界知识的使用方面。TGM在各种应用中都很有用,包括故事生成、对话式回应生成、代码自动完成和放射学报告生成。然而,TGM也可能被滥用于假新闻的生成,假产品评论的生成,以及垃圾邮件/网络钓鱼。因此,建立能够最大限度地减少滥用TGM带来的威胁的工具非常重要。
3.2 解决办法
为应对滥用TGM带来的威胁,常用的方法是将区分TGM生成的文本和人类书写的文本的问题制定为一个分类任务。当TGM生成的文本的意图是滥用时,该分类器(此后称为检测器)可用于自动从社交媒体、电子商务、电子邮件客户端和政府论坛等在线平台删除机器生成的文本。
理想的检测器应该是:
(1)准确:根据应用TGM的在线平台(电子邮件客户端、社交媒体),在假阳性和假阴性之间进行良好的权衡;
(2)数据高效:需要攻击者使用的TGM中尽可能少的例子;
(3)可泛化:检测攻击者使用的TGM的不同建模选择所产生的文本,如模型架构、TGM训练数据、TGM调节提示长度、模型大小和文本解码方法;
(4)可解释的:检测器的决定需要是人类可以理解的;
(5)稳健的:检测器可以处理对抗性例子。
鉴于这个问题的重要性,最近NLP和ML社区在构建有用的检测器方面都有大量的研究。然而,目前还没有任何工作对现有的检测工作进行文献回顾并强调重要的研究挑战。
3.3 文章脉络
在本文中,我们对现有的英语检测研究进行了重要的文献回顾,以帮助理解这一重要领域。我们对调查进行了组织,以引导读者无缝地浏览一些重要的方面,具体如下:
首先,我们建立了检测任务的背景,其中包括TGMs、文本生成的解码方法和TGMs的社会影响(§4)。
第二,我们介绍了大规模TGMs的各个方面,如模型结构、训练成本和可控性(§5)。
第三,我们介绍并讨论了现有的各种检测器的基本方法(§6)。
第四,我们对最先进的检测器的关键问题进行了语言上和计算上的分析(§7)。
第五,我们讨论了有趣的未来研究方向,可以帮助建立有用的检测器(§8)。
3.4 主要贡献
我们的主要贡献有三个方面:
- 我们提供了关于从人类书写的文本中检测机器生成的文本这一重要的、蓬勃发展的领域的第一次调查。
- 我们对当前最先进的检测器进行了错误分析,并以机器生成的文本为指导和说明,以阐明现有检测工作的局限性。
- 在我们的分析和现有挑战的激励下,我们提出了一套丰富多样的研究方向,以指导这一令人兴奋的领域的未来工作。
4、背景
在这里,我们提供了从人类书写的文本中检测机器生成的文本问题的背景。具体来说,我们介绍了训练TGM的关键概念,从TGM生成文本,以及在实践中使用TGM的社会影响。现有的检测数据集将在附录中讨论。
4.1 训练TGM
TGM通常是一个神经语言模型(NLM),它被训练用来模拟在文本序列中给定的一个标记的概率,即
请注意,TGM可以是一个非神经模型(如n-gram LM),并基于非传统的LM目标(如掩码语言建模)。在这次调查中,我们主要关注的是神经和基于传统LM目标的英语TGMs,因为它们在生成连贯的英语文本段落方面是成功的。
4.2 从TGM中生成文本
给定一个子序列(前缀),
确定性的方法: 在确定性方法中,延续性完全由TGM参数和前缀决定。两种最常用的确定型解码方法是贪婪搜索和波束搜索。贪婪搜索的工作原理是【在每个时间步骤选择最高概率的标记】:
随机方法: 随机解码方法的工作原理是【在每个时间步骤从一个依赖模型的分布中取样】,
4.3 TGMs的社会影响
偏见: 毫不奇怪,TGM可以捕捉并放大训练数据中存在的社会偏见(对某一特定群体的过度概括性信念,如X群体是坏司机)。研究表明,TGMs反映了性别偏见(例如,偏爱男性而不是女性),种族偏见(例如,偏爱白人而不是黑人),以及宗教偏见(例如,偏爱基督徒而不是穆斯林)。虽然TGM可以作为一种工具,研究训练数据中的模式如何转化为模型输出中的这些意外偏见,但这些偏见会在很多方面对相关群体的人造成伤害。
有益的用法: TGMs被用来创建特定的任务系统,如问题回答、阅读理解、自然语言推理和机器翻译。TGM还可以用来生成与人类语言风格近似的文本,这有利于故事生成、对话式回应生成、代码自动完成和放射学报告生成等应用。
恶意使用: TGMs可以被(甚至是低技能的)对手用于恶意目的,如假新闻的生成,假产品评论的生成,以及垃圾邮件/网络钓鱼。人类只能在偶然水平上发现TGM生成的假新闻文章、假产品评论和假评论。为了对抗此类对手带来的威胁,需要建立能够从人类书写的文本中识别TGM生成的文本的准确模型。这样的模型可以有善意的用途,例如在包括社交媒体、电子邮件客户端、政府网站和电子商务网站在内的脆弱平台上对内容进行审核。
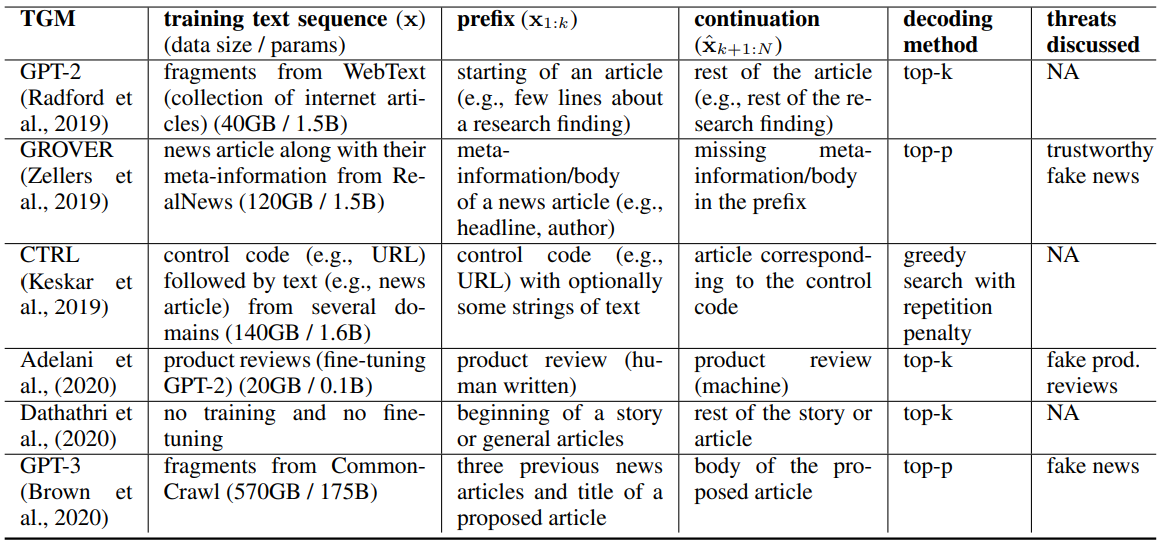
表1:可作为威胁模型的TGM的特征总结。最后一栏对应的是原论文中讨论的威胁。
5、文本生成模型
在本节中,我们将讨论大规模TGMs的各个方面。这些TGMs作为威胁模型,因为它们可以被低技能的对手滥用,例如,通过生成假新闻和假产品评论。表1显示了这些TGMs的关键特征以及它们所构成的威胁(根据原始论文)的摘要。
5.1 模型结构、训练数据、训练成本
模型架构: 所有最先进的TGM的基础模型架构是转化器。与递归神经网络(RNN)相比,转化器模型对最近的标记没有偏见,可以学习长距离的依赖信息。从TGMs(如GPT-2)产生的基于变压器架构的信息往往是语法正确的,连贯的,并使用世界知识。
训练数据: 诸如GPT-2、CTRL和GPT-3等TGMs有数十亿的参数。它们一般使用语言建模目标对来自不同来源(如维基百科、Reddit和新闻来源)的大量原始文本进行训练。作为一个例外,GROVER只对数百万篇新闻文章进行训练。这种经过训练的TGM也可以在特定领域的语料库上为LM任务进行微调,以生成合理匹配各自领域的文本。例如,Adelani等人(2020)在产品评论这一特定领域对GPT-2模型进行了微调,以生成模仿人类评论风格的虚假评论。
训练成本: 在数以百万计的文件上用数十亿的参数训练TGM,需要巨大的计算预算,高能量成本,以及长的训练时间。不幸的是,在每个研究出版物中报告财务(与能源与计算)预算还不是一个标准做法。这使得我们很难进行TGM训练的可行性研究。一个例外是Zellers等人(2019)所做的工作,他们明确提到他们提出的TGM模型GROVER花了两周的时间进行训练,成本为2.5万美元(包括数据采集的成本)。我们注意到,尽管这可能是一个昂贵的预算,但这绝不是低资源组织所能承受的,更不用说民族国家了。这意味着规模和资源能力各不相同的实体可以实际部署使用TGM传播虚假信息的模型。
5.2 可控的生成
可控的TGM拥有控制生成方面的能力,如文章的主题和情感。GPT-2和GPT-3假设前缀为任何自然语言文本,这在以明确方式控制生成方面可能过于粗糙。研究人员设计了两种方法来设计可控的TGM:
用控制令牌进行训练: 第一种方法是利用文章的元信息,如作者、创作日期、源域等,并在训练TGM之前,将这些信息作为额外的标记预置到输入序列。这些标记作为文章的额外背景,允许TGM学习元信息和原始文章之间的关系。一旦训练完成,TGM模型就可以通过提示用户感兴趣的元信息来控制。第一个提出的可控制的TGM是GROVER模型,它可以根据新闻文章的元信息(如标题、作者和日期)生成一篇新闻文章。GROVER模型可以创造出值得信赖的假新闻,与人类编写的假新闻相比,人类更难识别,因此可以构成重大威胁。与GROVER模型类似,CTRL模型通过利用自然发生的控制代码(如新闻文章的URL)对文本(如新闻文章正文)进行条件控制,对生成文本的特定方面进行明确控制。这些控制代码管理风格(例如,体育与政治,福克斯体育与CNN体育)、内容(例如,维基百科与书籍)和特定任务行为(例如,问题回答与机器翻译)。
使用属性分类器进行控制: 设计可控TGM的第二种也是最近的方法是将预训练的TGM(如GPT-2)与指导文本生成的一个或多个属性分类器(如情感分类器)相结合。属性模型衡量所需属性在一段文本中的编码程度。在每个时间点,GPT-2根据迄今为止生成的文本的属性模型的梯度来更新其潜像,以增加生成的文本具有所需属性的可能性。更新后的潜像被用来计算一个新的下一个标记分布,并从中抽取一个要生成的标记。这种方法的有趣特性是TGM模型不需要重新训练,从而避免了重新训练的巨大成本。
6、检测器
在本节中,我们将讨论各种用于识别机器生成的文本和人类书写的文本的检测器。为了帮助理解这些文献,我们根据它们所基于的基本方法来组织这些检测器。
6.1 从头开始训练的分类器
字袋分类器: 一些检测器采用经典的机器学习方法,如逻辑回归,从头开始训练一个模型来区分TGM生成的文本和人类书写的文本。Solaiman等人(2019年)在逻辑回归模型之上使用一个简单的基线模型,用tf-idf向量(unigrams和bigrams)表示文档,将WebText文章(在线网页)与使用GPT-2模型生成的文本区分开。他们研究了不同规模的GPT-2模型,这些模型在参数数量上有所不同(117M、345M、762M、1542M)和不同的采样技术(纯采样、top-k采样和top-p采样)。他们观察到,与较小的模型相比,较大的GPT-2模型的生成很难被发现,这表明TGM越大,生成文本的风格就越接近人类书写的文本。Top-k样本更容易检测,而核样本更难检测。这个结果源于top-k采样器通常会过度生成常用词,留下统计学上的异常,很容易被检测器发现。此外,Solaiman等人(2019年)对亚马逊产品评论的GPT-2模型进行了微调,并表明由微调的GPT-2模型生成的文本更难检测,因为微调的特定领域TGM比通用TGM(即原始GPT-2模型)更像人类。
检测机器配置: Tay等人(2020年)研究了不同的建模选择(解码方法、TGM模型大小、提示长度)在生成的文本中留下的伪影(由建模选择产生的可检测特征)的程度。他们提出的任务是,鉴于TGM生成的文本,识别TGM的建模选择。他们表明,一个分类器可以被训练来预测建模选择,远远超过偶然水平,这就确定了由TGM生成的文本可能比以前认为的对TGM建模选择更敏感。他们还发现,所提出的识别由不同的TGM建模选择产生的文本的检测任务,其难度低于从人类书写的文本中识别由TGM产生的文本以及不同的TGM建模选择的任务。他们表明,词序并不重要,因为词包检测器的表现与基于复杂编码器(如变换器)的检测器非常相似。这一结果与Uchendu等人最近完成的工作一致,(2020年)表明简单的模型(根据心理特征和简单的神经网络架构训练的传统ML模型)在三种情况下表现良好:
(1) 对两篇给定的文章是否由同一TGM生成进行分类;
(2) 对给定的文章是由人类还是TGM撰写进行分类(原始检测问题);
(3) 识别生成给定文章的TGM。
对于原始检测问题,作者发现由GPT-2模型生成的文本在几个TGM中很难检测出来(研究的TGM列表见附录)。
6.2 零点分类器
在零次分类设置中,采用预训练的TGM(例如GPT-2,GROVER)来检测来自自身或类似模型的代数。该检测器不需要监督检测的例子来进一步训练(即微调)。
总对数概率: Solaiman等人(2019)提出了一个基线,使用TGM来评估总对数概率,并根据这个概率的阈值来进行预测。例如,如果根据GPT-2模型,文本的总体可能性接近所有机器生成的文本的平均可能性,而不是人类书写的文本的平均可能性,则文本被预测为机器生成的。然而,他们发现,与之前讨论的基于逻辑回归的分类器相比,这个分类器的性能很差(§4.1)。
巨大的语言模型测试室(GLTR)工具: GLTR工具提出了一套基线统计方法,可以突出GPT-2模型生成的文本和人类书面文本的分布差异。具体来说,GLTR能够通过可视化每个标记的模型概率、预测的下一个标记分布中每个标记的等级以及预测的下一个标记分布的熵来研究一段文本。基于这些可视化,该工具清楚地表明,TGMs从自然语言的真实分布的有限子集中过度生成。事实上,由GPT-2模型生成的文本中的罕见词用法与人类书写的文本相比明显减少。该工具可以让人类(包括非专家)研究一段文本,但是一旦TGM开始生成缺乏统计学异常的文本,其效果可能会大打折扣。
6.3 微调NLM
在这个设置中,预训练的语言模型(例如BERT)被微调,以检测由其自身或类似模型生成的文本。与零点分类设置不同,该检测器确实需要有监督的检测实例来进一步训练。
GROVER检测器: Zellers等人(2019)提出了一个基于GROVER模型之上的线性分类器的检测器,其性能优于现有的检测器(fastText),并由此得出结论,生成神经虚假信息的最佳模型也是检测自己生成的最佳模型。这一结果表明,有必要将GROVER和GPT-2等生成器公开。尽管如此,作者并没有用BERT模型进行实验来观察类似的模式,即BERT模型在检测自己编写的文本方面也很出色,因为BERT检测器和BERT生成器拥有类似的感应偏差。研究表明,现成的GROVER检测器在检测原始GROVER模型以外的TGM生成的文本方面表现不佳。
RoBERTa检测器: Solaiman等人(2019年)对检测任务的RoBERTa语言模型进行了微调实验,并在识别由最大的GPT-2模型生成的网页方面确立了最先进的性能,准确率达95%∼。在top-p例子上训练的RoBERTa检测器很好地转移到所有其他解码方法(纯和top-k)的例子上。无论检测器模型的能力如何,当对较大的GPT-2模型的例子进行训练时,检测器表现良好,并能很好地转移到由较小的GPT-2模型产生的例子。另一方面,在较小的GPT-2模型的输出上进行训练,在对较大的GPT-2模型的输出进行分类时,表现不佳。这项工作最有趣的发现是,使用RoBERTa模型进行微调比对具有同等能力的GPT-2模型进行微调获得了更高的准确性。这一结果可能是由于RoBERTa语言模型与GPT-2语言模型相比,所采用的掩蔽语言建模目标中固有的双向表征的质量较高,后者只受限于学习单向表征(从左到右)。这一发现与GROVER工作相矛盾,作者得出结论,从TGM中检测神经假信息的最佳模型是TGM本身。最近,研究表明,RoBERTa检测器在从人类撰写的推文中准确发现机器生成的推文方面建立了最先进的性能,比传统的ML模型(如词包)和复杂的神经网络模型(如RNN、CNN)都要好得多。这一有趣的结果表明,RoBERTa检测器可以推广到其预训练期间未见的出版物来源,如Twitter。RoBERTa检测器在发现由几个TGMs生成的新闻文章和由GPT-2模型在亚马逊产品评论上微调生成的产品评论方面也优于现有检测器。
6.4 人机协作
除了建立一个统计模型来检测在线虚假信息外,人们还可以建立一个可以利用人类视觉解读技能和常识性知识的系统。
人和机器检测器的差异: 通过研究人类和自动检测器识别TGM生成的文本的能力差异。作者观察到:
(1)人类评分者善于注意到TGM生成的文本中的矛盾或语义错误(如不连贯),而自动检测器在这方面很弱,因为缺乏深层次的语义理解;
(2)当TGM生成的文本包含高概率词的过度代表时,自动检测器很好(§2.2中讨论的top-k采样的注意事项),而人类评分者就不好。
总的来说,自动检测器明显优于人类评分者,但对由未见过的解码方法产生的文本的概括性较差。
支持未经训练的人类: 如前所述,GLTR工具可以通过可视化文本的属性来帮助人类,如意外和断章取义的单词。GLTR的主要优点是,它可以【促进未经训练的人类准确地检测合成文本(从54%到72%的准确性)】。然而,GLTR很容易标志出机器生成的文本,但很难确信该文本不是机器生成的。这一结果表明,需要人机协作来解决检测任务。
真实或虚假文本(RoFT)工具: RoFT工具侧重于评估人类对TGM生成的文本的检测,要求人类检测文本从人类书写的文本过渡到机器生成的文本时的句子边界。主要的假设是,如果人类的猜测与真正的句子边界相差甚远,那么TGM就会成功骗过人类。目前的TGM可以欺骗人类一到两个句子。RoFT工具的核心优势包括其引人入胜的注释界面,收集用户对其猜测的自由文本解释,并有可能扩展到不同的文本领域以及不同的TGM建模选择。该工具的主要局限性是,显示给人类的文本可能充斥着人类生成的句子,因此不能反映来自TGM的有机生成。
7、最先进的检测器的问题
在这一节中,我们讨论了基于RoBERTa模型的最先进的检测器的开放性问题,该模型在检测TGM基于新闻文章、产品评论、推特和网页产生的文本方面表现出色(见§4.3)。我们专注于检测GPT-2模型从人类撰写的亚马逊产品评论中生成的文本,鉴于评论的简短性,这是一项具有挑战性的任务。我们在公开的数据集上使用RoBERTa检测器,其中包含GPT-2模型(1542M参数)的几代人,基于纯、top-k和top-p抽样以及人类写的评论(数据集详情见附录)。在图1中,我们绘制了检测器的准确性与每类训练实例的数量的关系,在十次随机初始化中的平均值,以控制初始化效应。我们观察到,RoBERTa检测器需要几千个例子才能达到高准确度。具体来说,它需要20万、1.5万和5万个训练例子,才能在识别纯洁、top-k和top-p的例子上分别达到90%的准确率,这是不现实的。鉴于为检测任务创建大型数据集是很难的,研究RoBERTa检测器的数据效率是否能得到明显改善是很重要的。
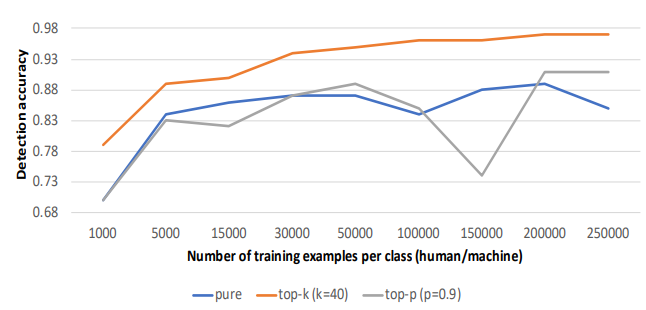
图1:RoBERTa检测器的检测精度与每类训练实例的数量有关、 十次随机初始化的平均数。
我们手动检查了100个随机挑选的假阳性(机器生成的产品评论被错误地预测为人类写的产品评论)的RoBERTa检测器,这些检测器分别从top-p世代和人类写的评论中训练了15K个例子。下面,我们列出了我们已经确定的错误类别,并为每个错误类别提供至少一个例子。
流畅性: 在错误的正面评论中,我们发现有73条评论非常流畅,甚至可以迷惑人类(1)。
(1)我喜欢这部电影。我真的无法解释原因,但当我第一次看到它时,它给我的印象是怪异的,几乎是奇特的,但我很快就克服了这一点,并记住我喜欢奇特的电影。这是一部80年代早期的电影。在一个阴沉的雨夜里看的一部好电影。这部影片充满悬念,充满诡异。把这个加入你的收藏。
短小精悍: 在这73条被确认为流畅的评论中,有27条评论非常短,中位数为24字。我们在下面给出两个例子:
(2)喜欢它。最好的扫地机器人。
(3)我最喜欢的组合。总是有效,而且通常能使我的系统冷却到启动。很高兴我得到了这些而不是其他品牌。
事实性: 我们发现10条虚假的正面评论包含事实错误。
(4) 这部电影得到了明星的青睐,代表了这个系列中最好的,但也有更好的生物电影,包括1960年代由柯克-道格拉斯和哈里森-福特翻拍的《德古拉》。
(5)就是喜欢本-阿弗莱克! 在另一部非常好的电影中不会错过他。值得一看,特别是如果你喜欢本!
关于产品 "环球影城经典怪物系列 "的评论(4)包含了哈里森-福特在《德古拉》电影中的错误事实,另一个关于《失控的陪审团》电影的评论(5)包含了本-阿弗莱克在该电影中的错误事实。
虚假的实体: 在4条假阳性评论中,我们发现评论中含有与产品领域无关的新实体。例如,关于 "Junkfood "音乐产品的评论(6)包含新的实体 "Grisberg",这与音乐领域无关。
(6) Grisberg的另一个经典之作,我喜欢Stevie,她是最伟大的R&B歌手之一,我知道Darwin Halstead指导她,所以她是一个大粉丝,请帮你自己一个忙,买这个dvd,它很好,它绝对令人惊讶,这个女人有一个非常Yorfelt的方法来对R&B音乐。
矛盾之处: 我们发现有一条评论(7)含有矛盾之处,即主体(丈夫)声称自己不是一个产品的大粉丝,但也喜欢同一产品。
(7)我丈夫喜欢喝黑咖啡,所以他喜欢有香味的咖啡,但又不是有香味的咖啡的大粉丝。
复述: 在两个虚假的正面评论中,事实经历了重复。
(8) 伟大的电影,虽然一开始花了点时间看,但它保持了我的兴趣,让我很感兴趣,另外我认为它非常好。
常识性的推理: 我们发现一个假的正面评论,描述了一个不可能的事件,也就是违反了常识推理。
(9) ......我同时收到了亚马逊的Prime和沃尔玛的快递,它们都准时到达。我喜欢它,并强烈推荐它!
对某一特定音频播放器产品的评论(9)提到,用户同时从两家电子商务公司收到同一产品,这很可能是一个不可能的事件。
错别字和语法错误: 有7条假阳性评论拥有印刷和语法错误(10)和(11)。我们注意到,这种错误(尤其是拼写错误)在网上评论中并不罕见,包括那些由人写的评论。
(10) Once they are on they aren’t wrinkled or lose they shape.
(11) Had to unplug thing to get the hard drive to work. Would rather have don batteries in the
olden days..
不连贯: 有3条虚假的正面评论,看起来不连贯。电影评论(12)以不连贯的方式在演员(Sophia和Duchovny)和故事线之间切换话语焦点,这违反了话语分析中的中心化理论。
(12) ... 索菲亚-罗兰饰演的 "玛丽安 "是一个 "艳舞女郎",因其狂野的风格而被体制内的人挑剔。... 杜丘尼的角色在商业世界中也是'在行的'。... 故事情节是如此的引人入胜和不可预测。... 索菲亚-罗兰的演技实在是太棒了,她的衣着打扮也非常完美 如果你喜欢性和裸体***,你将会非常高兴。
8、未来的研究方向
在这一节中,我们讨论了一系列未来的研究方向,这些方向可以帮助建立有用的检测器。
8.1 利用辅助信号
现有的检测器并不利用关于文本源的辅助信号。7 例如,第5节中研究的RoBERTa检测器忽略了关于评论(例如,有用性)和产品(例如,描述)的辅助信号。这种辅助信号可以作为检测任务中来自文本源的语言信号的补充。鉴于构建智能TGM的研究迅速发展,缩小了自然语言文本的机器和人类分布之间的差距,辅助信号可以在减轻TGM带来的威胁方面发挥关键作用。
8.2 评估文本的真实性
现有的检测器有一个假设,即假文本是由产生文本的来源(如TGM)决定的。这一假设在两种实际情况下并不成立:
(i) 真正的文本在类似于假文本的过程中自动生成;
(ii) 对手通过修改源自合法人类来源的文章来创造假文本。
Schuster等人(2020年)表明,现有的检测器在这两种情况下表现不佳,因为它们过于依赖分布特征,而这些特征不能帮助区分来自类似来源的文本。因此,我们呼吁对检测器进行更多的研究,通过咨询外部来源,如知识库和扩散网络,评估机器生成文本的真实性,而不是仅仅依赖来源。
8.3 构建可通用的检测器
现有的检测器表现出较差的跨域准确性,也就是说,它们不能通用于不同的出版物格式(维基百科、书籍、新闻来源)。除了出版物格式和主题(如政治、体育),检测器还应该转移到未见过的TGM设置,如模型架构、不同的解码方法(如top-k、top-p)、模型大小、不同的前缀长度和训练数据。
8.4 构建可解释的检测器
我们在第4.4节中讨论了人类评分者与自动检测器配对的重要性。这种合作的一个可行方法是使自动检测器所做的决定具有可解释性(比如在GLTR中),这样人类评分者就可以对模型的决定进行逻辑分组(比如矛盾),人类可以 "接受"、"修改 "或 "拒绝 "这些决定。这就要求在建立检测器方面进行更多的研究,这些检测器可以为其决定提供解释,而这些解释对人类来说是可以理解的。
8.5 构建对对抗性攻击具有鲁棒性的检测器
现有的检测器是很脆的,即检测器的决定会因文本输入的微小变化而发生很大变化。例如,Wolff(2020)表明,RoBERTa检测器可以使用简单的方案进行攻击,如用同音字替换字符和拼错一些单词。这两种攻击使检测器在TGM生成的文本中的召回率从97.44%分别降低到0.26%和22.68%。因此,必须研究各种对抗性攻击,从简单的攻击(如拼写错误)到高级攻击(如通用攻击(Wallace等人,2019)),并创建对抗性例子,目的是描述检测器的脆弱性,以及使检测器对各种攻击具有鲁棒性。
9、结论
能够将机器生成的文本与人类书写的文本区分开来的检测器,可以在减轻对TGM的滥用方面发挥重要作用,例如在自动创建假新闻和假产品评论方面。我们将现有的检测器和相关问题分为从头开始训练的分类器、零点分类器、微调NLMs和人机协作,可以帮助读者将每个检测器与快速增长的文献结合起来。我们也希望我们对最先进的检测器的计算和语言学动机的错误分析可以使读者了解在建立有用的检测器方面的许多现有挑战。我们丰富多样的研究方向也有可能指导这个令人兴奋的领域的未来工作。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律