
Hadoop、Hive和Spark的关系
大数据技术生态中,Hadoop、Hive、Spark是什么关系?| 通俗易懂科普向
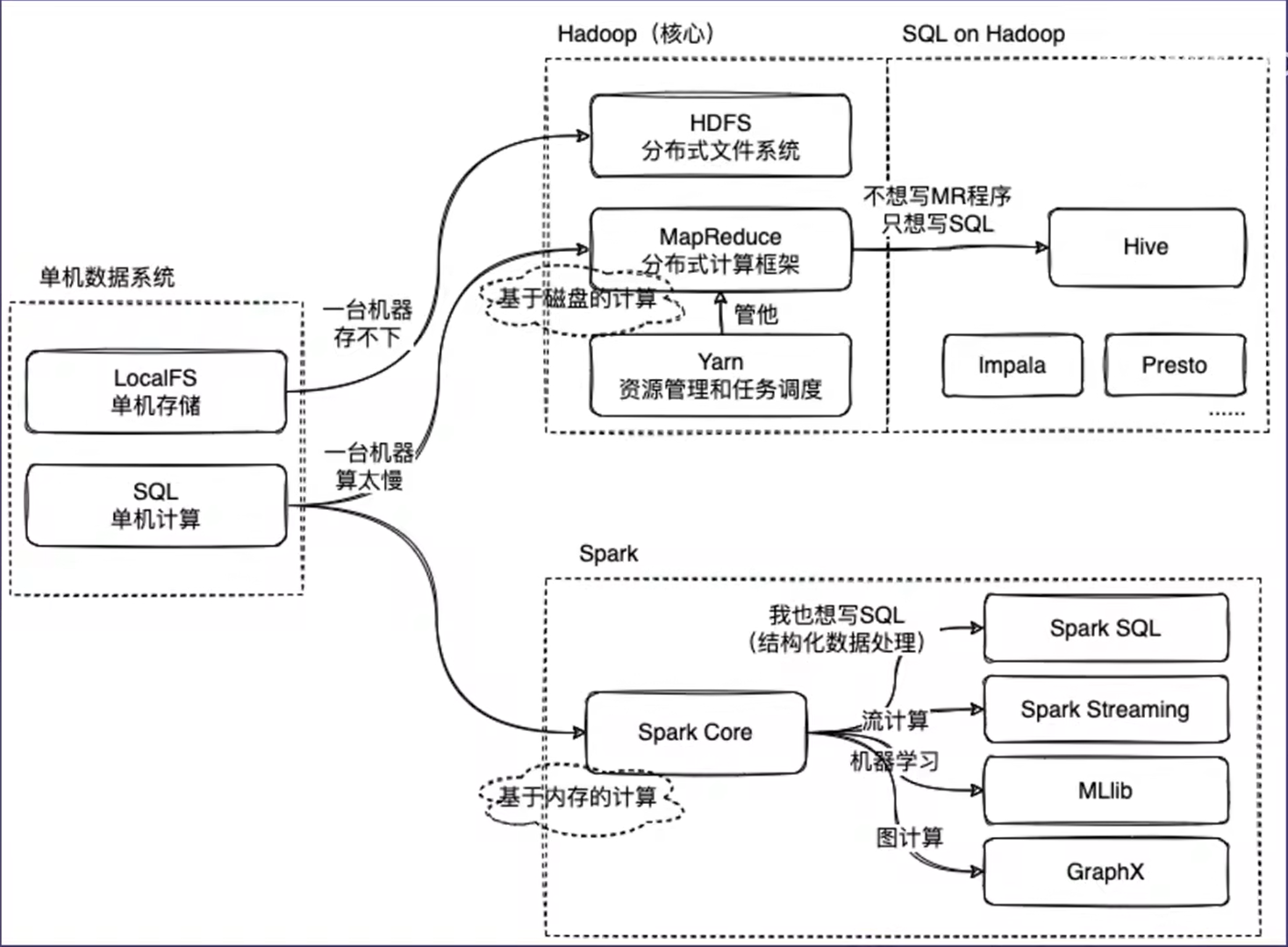
Hadoop、Hive和Spark,都是大数据相关的系统和技术。
大数据也是数据管理系统的范畴。数据管理系统涉及两个方面的问题,一个是数据怎么存储?一个是数据怎么计算?
为了方便理解,我们需要从单机的时代来讲解。
在单机的数据管理系统时代,我们用一台服务器进行数据的存储和计算,计算任务都是IO密集型的,不是CPU密集型的。
随着信息时代的发展,大数据量爆发。我们用一台服务器没办法保存所有的数据,所以我们用多台服务器来保存数据。但这时候就涉及到一个问题,假如我们有100台服务器,怎么做到统一管理呢?就像我们没办法让一个老板直接对100个员工发号施令,必须要有一些经理的角色对这100个员工进行管理,让他们看起来是一个团队。
在Hadoop生态当中,HDFS扮演着经理的角色,HDFS会统一管理这100台服务器的存储空间,对外提供一个接口。让这100台服务器的存储空间,像一台服务器的存储空间。让用户感觉这是一个无限大的存储空间,然后再基于这个去编写应用程序。
说完了数据存储,再说下数据计算。数据分布式的存储到不同服务器上,每台服务器上都有自己的CPU和内存。如果能充分的利用这些资源,让数据计算更快的完成,就变成了一个顺理成章的事情。但问题又来了?如果我们是程序员,如何编写程序操作这100台服务器协作完成了一个计算任务。比如任务怎么分配到这些机器上?这些任务之间怎么去做同步?如果在这过程中有一台机器掉链子了怎么办?这些都是很典型的并行编程问题。
为了解决这个问题,HDFS引入了一个模块,就是大名鼎鼎的MapReduce。MapReduce实际提供了一个任务并行的框架,通过它的API抽象。将并行程序划分成两个阶段,一个是map阶段,一个是reduce阶段。map阶段也就是说你有一个任务量很大的活,你找了100个帮手,把任务平均分成了100份,每个人做一份。reduce阶段也就是说,你等这100个帮手计算完任务之后,把结果汇总到你这里,然后再对结果进行一个集中的处理后输出一个最终结果。
到现在为止Hadoop里面有HDFS来处理存储,MapReduce来处理计算。看起来一切都很美好,但是科技总是有一些懒人来推动的。
技术的发展是为了更高效的处理数据,简化使用者的操作难度。
在单机数据库的时代,有些人可以使用sql来处理复杂的业务逻辑。sql是一个很伟大的发明,降低了数据处理门槛。
而大数据时代这些人发现不能写sql了,而是要编写MapReduce程序,而且还是一个特别专业的分布式处理程序。这就需要很强的计算机背景,而这批用户的核心需求是我能不能在Hadoop上也写sql,所以Hive就出现了。
Hive实际上是一个在Hadoop上处理结构化数据的一种解决方案。为了让用户使用SQL处理数据,那么数据就需要进行结构化的处理。毕竟SQL的S就是结构化处理的意思。如果不对数据进行结构化处理,那么我们要怎样去查询呢?Hive里面的一个核心模块metastore,它是用来存储这些结构化的信息。简单来说就是"表"的信息,包括都有什么字段、字段的数据结构。Hive的执行引擎会对SQL进行语法分析,分析成一个语法树。这个两个步骤和普通的数据库没有什么区别。区别主要在执行阶段,Hive执行引擎会将SQL翻译成MapReduce任务去执行,并对执行结果进行加工,返回给用户。这就是一个完整的HQL处理数据的流程。Hive的出现让大部分大数据开发工程师变成了sql boy/girl。
从工程的角度来看,效率和灵活性就是一对矛盾体。Hive的出现使大数据处理任务的开发效率提高了,但是在数据的表达力和灵活性上。肯定不如直接写MapReduce程序。所以这两个技术也不是相互替代的关系。需要根据实际的场景去选择。
最后再来说一下Spark,Spark经常用来和Hadoop进行对比,主要是和Hadoop的MapReduce对比。Spark本身也是一个计算框架,它和MapReduce的区别主要在于Spark是基于内存的计算,而MapReduce是基于磁盘的计算。所以Spark的卖点就是快。举一个极端的例子,如果数据集不是特别大,计算可以在服务器的内存中完成,那么Spark的计算速度比MapReduce快100倍,因为内存的读取速度比磁盘的读取速度快很多。一般会认为,Spark比MapReduce处理程序快2~3倍左右。Spark的核心模块和MapReduce在使用体验上有些类似的地方,他们都提供一系列API,让开发者去写数据的处理程序,并且在MapReduce上有和Hive类似的处理方案,让用户可以写SQL处理数据。在Spark生态里面有SparkSQL模块,让用户在Spark的API里面写SQL。
Spark作为计算引擎,还提供了其他的上层的抽象,帮助用户去写其他类型的数据处理程序。比如Spark提供了Streaming模块,让用户去写流处理的程序。提供MLlib模块,让用户去写机器学习的程序。以及图处理模块GraphX。
有的时候一个好的问题定义,会比一个解决方案更重要!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号