python爬虫小练习
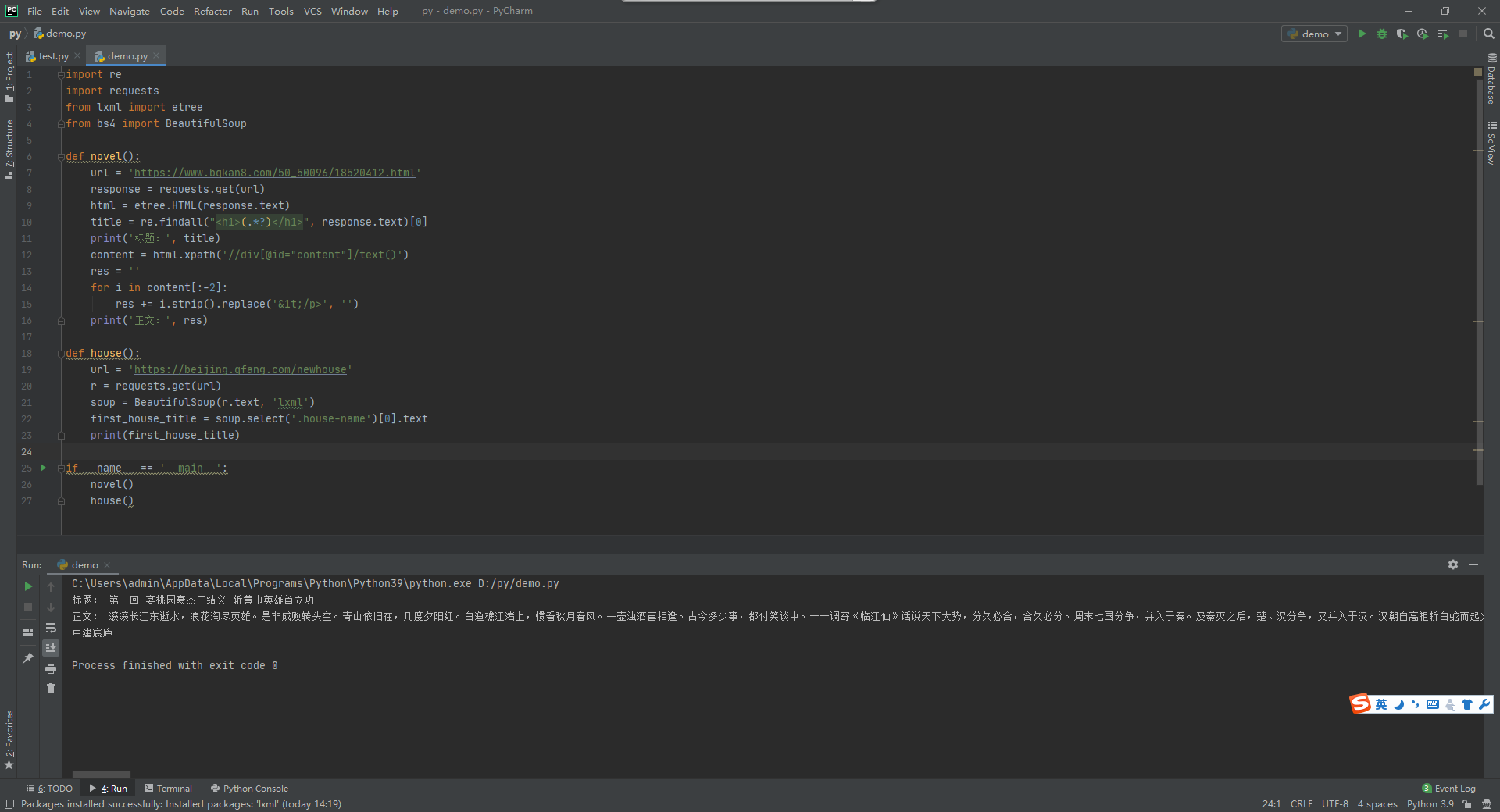
import re import requests from lxml import etree from bs4 import BeautifulSoup def novel(): url = 'https://www.bqkan8.com/50_50096/18520412.html' response = requests.get(url) html = etree.HTML(response.text) title = re.findall("<h1>(.*?)</h1>", response.text)[0] print('标题:', title) content = html.xpath('//div[@id="content"]/text()') res = '' for i in content[:-2]: res += i.strip().replace('&1t;/p>', '') print('正文:', res) def house(): url = 'https://beijing.qfang.com/newhouse' r = requests.get(url) soup = BeautifulSoup(r.text, 'lxml') first_house_title = soup.select('.house-name')[0].text print(first_house_title) if __name__ == '__main__': novel() house()
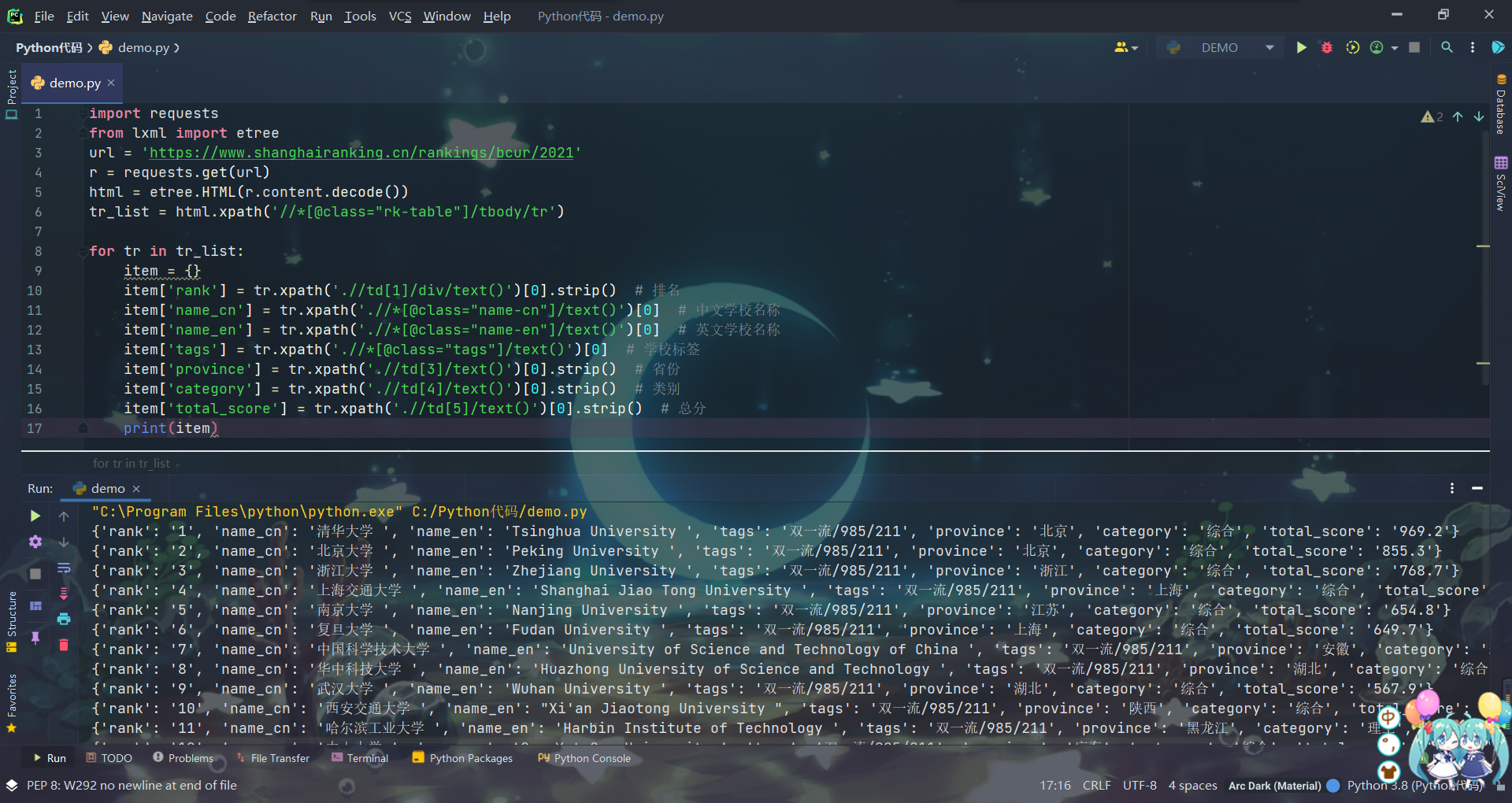
import requests from lxml import etree url = 'https://www.shanghairanking.cn/rankings/bcur/2021' r = requests.get(url) html = etree.HTML(r.content.decode()) tr_list = html.xpath('//*[@class="rk-table"]/tbody/tr') for tr in tr_list: item = {} item['rank'] = tr.xpath('.//td[1]/div/text()')[0].strip() # 排名 item['name_cn'] = tr.xpath('.//*[@class="name-cn"]/text()')[0] # 中文学校名称 item['name_en'] = tr.xpath('.//*[@class="name-en"]/text()')[0] # 英文学校名称 item['tags'] = tr.xpath('.//*[@class="tags"]/text()')[0] # 学校标签 item['province'] = tr.xpath('.//td[3]/text()')[0].strip() # 省份 item['category'] = tr.xpath('.//td[4]/text()')[0].strip() # 类别 item['total_score'] = tr.xpath('.//td[5]/text()')[0].strip() # 总分 print(item)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号