import re
import requests
from parsel import Selector
class DaZongDianPing:
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36',
'Host': 'www.dianping.com',
}
self.main()
def main(self):
html = self.get_index()
css_url, class_name = self.get_url_and_tag(html)
di = self.get_css_and_svg(css_url, class_name)
self.parse_index(html, di)
def get_index(self):
url = 'http://www.dianping.com/shop/G8svaNSPiUlDoeYK/review_all'
resp = requests.get(url, headers=self.headers)
if resp.status_code == 200:
return resp.text
def get_url_and_tag(self, html):
'''获取css_url和网页中的加密字体标签的class名'''
css_url = re.findall(r'href="(.*?svgtextcss.*?)"', html)
if css_url:
css_url = 'http:' + css_url[0]
# print(css_url)
# 加密字体的class名
class_name = re.findall(r'<svgmtsi class="(.*?)">', html)
return css_url, class_name
def get_css_and_svg(self, css_url, class_name):
'''
获取css属性和svg地址,根据css属性查找真实数据,构建替换字典
svg地址有3个
cc[class^="wgx"] 电话
bb[class^="wnu"] 地址
svgmtsi[class^="kvg"] 评论
'''
css_resp = requests.get(css_url).text.replace("\n", "").replace(" ", "")
# print(css_resp)
# 获取评论的svg地址
svg_url = re.findall(r'svgmtsi.*?url\((.*?)\);', css_resp)
if svg_url:
svg_url = 'http:' + svg_url[0]
# print(svg_url)
svg_resp = requests.get(svg_url).text
# 获取css属性值 对应的坐标值
d = {}
for name in class_name:
coord = re.findall(r"%s{background:-(.*?)px-(.*?)px;}" % name, css_resp)
x, y = coord[0]
css_x, css_y = int(float(x)), int(float(y))
# 获取svg标签对应的y值,规则是svg_y>=css_y
svg_data = Selector(svg_resp)
tests = svg_data.xpath('//text')
# 3.如何选择svg_y?比较y坐标,选择大于等于css_y的最接近的svg_y
svg_y = [i.attrib.get('y') for i in tests if css_y <= int(i.attrib.get('y'))][0]
# 根据svg_y确定具体的text的标签
svg_text = svg_data.xpath(f'//text[@y="{svg_y}"]/text()').extract_first()
# 4、确认SVG中的文字大小
font_size = re.findall(r'font-size:(\d+)px', svg_resp)[0]
# 5、得到css样式vhkbvu属性映射svg的位置
# css_x // 字体大小 的值就是数值的下标
position = css_x // int(font_size)
s = svg_text[position]
d[name] = s
# 加密字体整个标签与真实值之间的字典
di = {f'<svgmtsi class="{k}"></svgmtsi>': v for k, v in d.items()}
return di
def parse_index(self, html, di):
'''解析网页数据'''
for key, value in di.items():
if key in html:
html = html.replace(key, value)
# print(html)
selector = Selector(html)
# 评论摘要
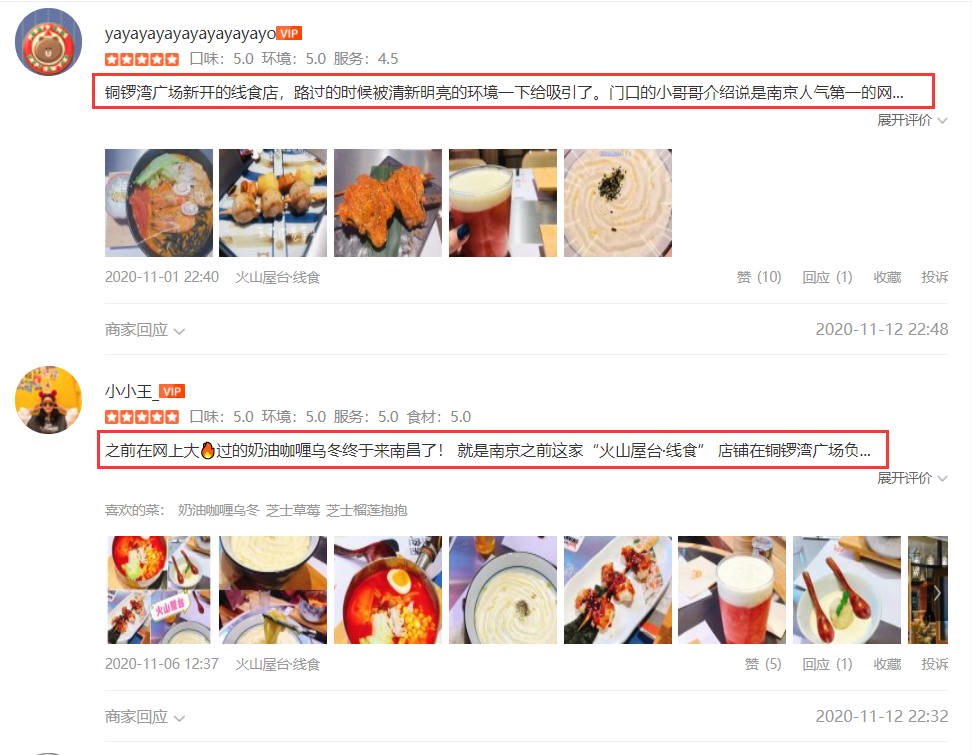
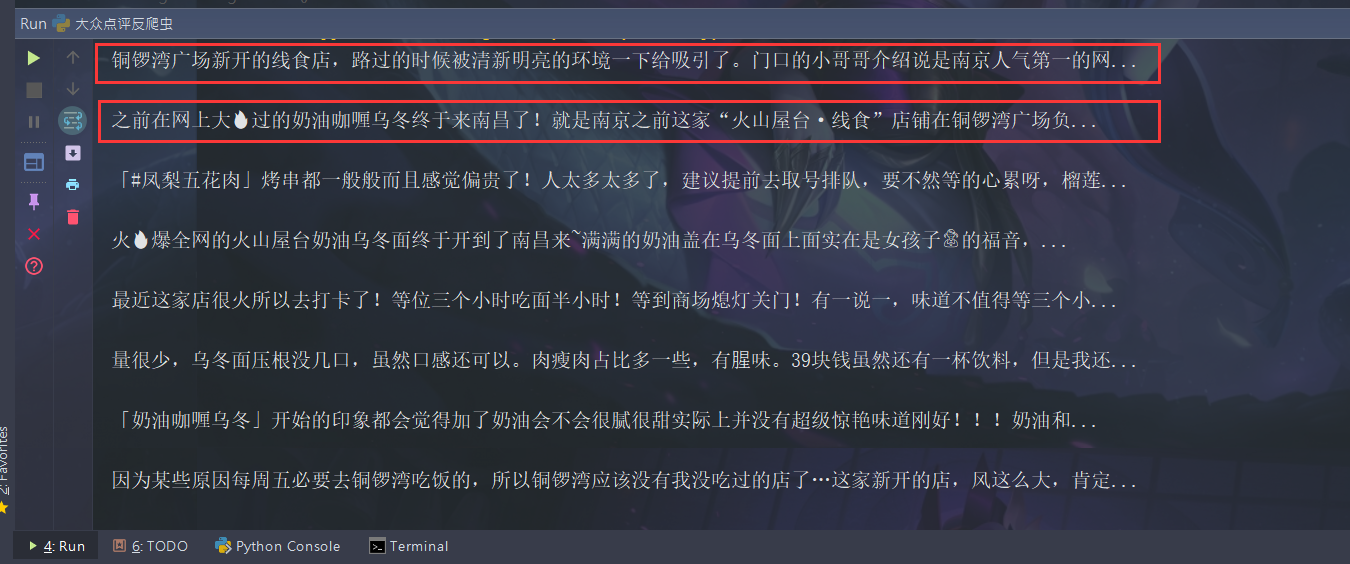
desc_li = selector.xpath('//div[@class="review-truncated-words"]/text()').extract()
for desc in desc_li:
desc = desc.replace('\t', '').replace('\n', '').replace(' ', '')
print(desc)
if __name__ == '__main__':
a = DaZongDianPing()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号