
RCU原理
RCU(Read-Copy Update)是数据同步的一种方式,在当前的Linux内核中发挥着重要的作用。RCU主要针对的数据对象是链表,目的是提高遍历读取数据的效率,为了达到目的使用RCU机制读取数据的时候不对链表进行耗时的加锁操作。这样在同一时间可以有多个线程同时读取该链表,并且允许一个线程对链表进行修改(修改的时候,需要加锁)。RCU适用于需要频繁的读取数据,而相应修改数据并不多的情景,例如在文件系统中,经常需要查找定位目录,而对目录的修改相对来说并不多,这就是RCU发挥作用的最佳场景。
在RCU的实现过程中,我们主要解决以下问题:
1,在读取过程中,另外一个线程删除了一个节点。删除线程可以把这个节点从链表中移除,但它不能直接销毁这个节点,必须等到所有的读取线程读取完成以后,才进行销毁操作。RCU中把这个过程称为宽限期(Grace period)。
2,在读取过程中,另外一个线程插入了一个新节点,而读线程读到了这个节点,那么需要保证读到的这个节点是完整的。这里涉及到了发布-订阅机制(Publish-Subscribe Mechanism)。
3, 保证读取链表的完整性。新增或者删除一个节点,不至于导致遍历一个链表从中间断开。但是RCU并不保证一定能读到新增的节点或者不读到要被删除的节点。

中每行代表一个线程,最下面的一行是删除线程,当它执行完删除操作后,线程进入了宽限期。宽限期的意义是,在一个删除动作发生后,它必须等待所有在宽限期开始前已经开始的读线程结束,才可以进行销毁操作。这样做的原因是这些线程有可能读到了要删除的元素。图中的宽限期必须等待1和2结束;而读线程5在宽限期开始前已经结束,不需要考虑;而3,4,6也不需要考虑,因为在宽限期结束后开始后的线程不可能读到已删除的元素。为此RCU机制提供了相应的API来实现这个功能。

1 void foo_read(void)
2 {
3 rcu_read_lock();
4 foo *fp = gbl_foo;
5 if ( fp != NULL )
6 dosomething(fp->a,fp->b,fp->c);
7 rcu_read_unlock();
8 }
9
10 void foo_update( foo* new_fp )
11 {
12 spin_lock(&foo_mutex);
13 foo *old_fp = gbl_foo;
14 gbl_foo = new_fp;
15 spin_unlock(&foo_mutex);
16 synchronize_rcu();
17 kfee(old_fp);
18 }
其中foo_read中增加了rcu_read_lock和rcu_read_unlock,这两个函数用来标记一个RCU读过程的开始和结束。其实作用就是帮助检测宽限期是否结束。foo_update增加了一个函数synchronize_rcu(),调用该函数意味着一个宽限期的开始,而直到宽限期结束,该函数才会返回。我们再对比着图看一看,线程1和2,在synchronize_rcu之前可能得到了旧的gbl_foo,也就是foo_update中的old_fp,如果不等它们运行结束,就调用kfee(old_fp),极有可能造成系统崩溃。而3,4,6在synchronize_rcu之后运行,此时它们已经不可能得到old_fp,此次的kfee将不对它们产生影响。
宽限期是RCU实现中最复杂的部分,原因是在提高读数据性能的同时,删除数据的性能也不能太差。
订阅——发布机制
当前使用的编译器大多会对代码做一定程度的优化,CPU也会对执行指令做一些优化调整,目的是提高代码的执行效率,但这样的优化,有时候会带来不期望的结果。如例:
1 void foo_update( foo* new_fp )
2 {
3 spin_lock(&foo_mutex);
4 foo *old_fp = gbl_foo;
5
6 new_fp->a = 1;
7 new_fp->b = ‘b’;
8 new_fp->c = 100;
9
10 gbl_foo = new_fp;
11 spin_unlock(&foo_mutex);
12 synchronize_rcu();
13 kfee(old_fp);
14 }
这段代码中,我们期望的是6,7,8行的代码在第10行代码之前执行。但优化后的代码并不对执行顺序做出保证。在这种情形下,一个读线程很可能读到 new_fp,但new_fp的成员赋值还没执行完成。当读线程执行dosomething(fp->a, fp->b , fp->c ) 的 时候,就有不确定的参数传入到dosomething,极有可能造成不期望的结果,甚至程序崩溃。可以通过优化屏障来解决该问题,RCU机制对优化屏障做了包装,提供了专用的API来解决该问题。这时候,第十行不再是直接的指针赋值,而应该改为 :
rcu_assign_pointer(gbl_foo,new_fp);
rcu_assign_pointer的实现比较简单,如下:
<include/linux/rcupdate.h>
1 #define rcu_assign_pointer(p, v) \
2 __rcu_assign_pointer((p), (v), __rcu)
3
4 #define __rcu_assign_pointer(p, v, space) \
5 do { \
6 smp_wmb(); \
7 (p) = (typeof(*v) __force space *)(v); \
8 } while (0)
我们可以看到它的实现只是在赋值之前加了优化屏障 smp_wmb来确保代码的执行顺序。另外就是宏中用到的__rcu,只是作为编译过程的检测条件来使用的。
数据读取的完整性
还是通过例子来说明这个问题:

如图我们在原list中加入一个节点new到A之前,所要做的第一步是将new的指针指向A节点,第二步才是将Head的指针指向new。这样做的目的是当插入操作完成第一步的时候,对于链表的读取并不产生影响,而执行完第二步的时候,读线程如果读到new节点,也可以继续遍历链表。如果把这个过程反过来,第一步head指向new,而这时一个线程读到new,由于new的指针指向的是Null,这样将导致读线程无法读取到A,B等后续节点。从以上过程中,可以看出RCU并不保证读线程读取到new节点。如果该节点对程序产生影响,那么就需要外部调用做相应的调整。如在文件系统中,通过RCU定位后,如果查找不到相应节点,就会进行其它形式的查找,相关内容等分析到文件系统的时候再进行叙述。
我们再看一下删除一个节点的例子:

如图我们希望删除B,这时候要做的就是将A的指针指向C,保持B的指针,然后删除程序将进入宽限期检测。由于B的内容并没有变更,读到B的线程仍然可以继续读取B的后续节点。B不能立即销毁,它必须等待宽限期结束后,才能进行相应销毁操作。由于A的节点已经指向了C,当宽限期开始之后所有的后续读操作通过A找到的是C,而B已经隐藏了,后续的读线程都不会读到它。这样就确保宽限期过后,删除B并不对系统造成影响。
RCU的基本思想是这样的:先创建一个旧数据的copy,然后writer更新这个copy,最后再用新的数据替换掉旧的数据。这样讲似乎比较抽象,那么结合一个实例来看或许会更加直观。
假设有一个单向链表,其中包含一个由指针p指向的节点:
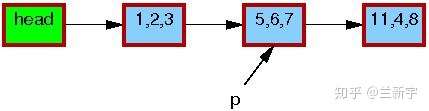
现在,我们要使用RCU机制来更新这个节点的数据,那么首先需要分配一段新的内存空间(由指针q指向),用于存放这个copy。
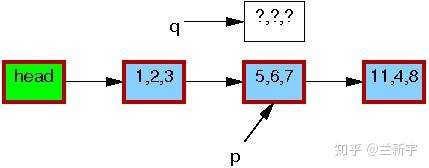
然后将p指向的节点数据,以及它和下一节点[11, 4, 8]的关系,都完整地copy到q指向的内存区域中。
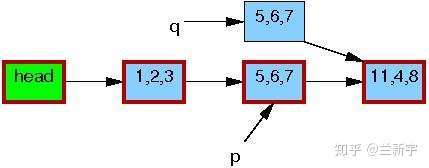
接下来,writer会修改这个copy中的数据(将[5, 6, 7]修改为[5, 2, 3])。
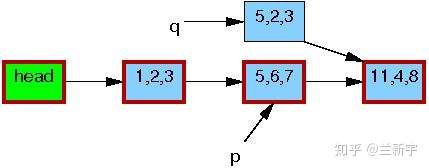
修改完成之后,writer就可以将这个更新“发布”了(publish),对于reader来说就“可见”了。因此,pubulish之后才开始读取操作的reader(比如读节点[1, 2, 3]的下一个节点),得到的就是新的数据[5, 2, 3](图中红色边框表示有reader在引用)。
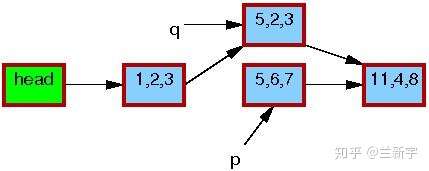
而在publish之前就开始读取操作的reader则不受影响,依然使用旧的数据[5, 6, 7]。
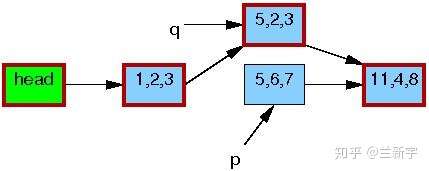
等到所有引用旧数据区的reader都完成了相关操作,writer才会释放由p指向的内存区域。
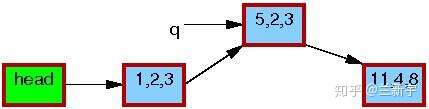
可见,在此期间,reader如果读取这个节点的数据,得到的要么全是旧的数据,要么全是新的数据,反正不会是「半新半旧」的数据,数据的一致性是可以保证的。重要的是,RCU中的reader不用像rwlock中的reader那样,在writer操作期间必须spin等待了。
优点:
1)读者侧开销很少、不需要获取任何锁,不需要执行原子指令或者内存屏障;
2)没有死锁问题;
3)没有优先级反转的问题;
4)没有内存泄露的危险问题;
5)很好的实时延迟;
缺点:
1)写者的同步开销比较大,写者之间需要互斥处理;
2)使用上比其他同步机制复杂;
4.1 核心API
下边的这些接口,不能更核心了。
a. rcu_read_lock() //标记读者临界区的开始
b. rcu_read_unlock() //标记读者临界区的结束
c. synchronize_rcu() / call_rcu() //等待Grace period结束后进行资源回收
d. rcu_assign_pointer() //Updater使用这个宏对受RCU保护的指针进行赋值
e. rcu_dereference() //Reader使用这个宏来获取受RCU保护的指针

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 一个奇形怪状的面试题:Bean中的CHM要不要加volatile?
· [.NET]调用本地 Deepseek 模型
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· .NET Core 托管堆内存泄露/CPU异常的常见思路
· PostgreSQL 和 SQL Server 在统计信息维护中的关键差异
· DeepSeek “源神”启动!「GitHub 热点速览」
· 微软正式发布.NET 10 Preview 1:开启下一代开发框架新篇章
· 我与微信审核的“相爱相杀”看个人小程序副业
· C# 集成 DeepSeek 模型实现 AI 私有化(本地部署与 API 调用教程)
· spring官宣接入deepseek,真的太香了~