

ysyx: 完善库函数
nemu把库函数分为了与架构有关的isa部分和与架构无关的klib部分。这部分的任务,就是完善stdio.c stdlib.c 和string.c,让各种测试集、跑分和demo可以正常运行。值得一提的是,我也是看到这一部分,回看测试集时,才注意到测试集用的其实都是C语言自带的关键字和基本功能,没有使用到特定库函数。在PA2初期,只需要完善少数库函数就可以让hello-str string测试集正常运行,在PA2后期,为了运行demo和更多测试。剩下的函数应该按照讲义尽量都实现。
库函数的实现方面,hello-str的代码如下:

#include "trap.h" char buf[128]; int main() { sprintf(buf, "%s", "Hello world!\n"); check(strcmp(buf, "Hello world!\n") == 0); sprintf(buf, "%d + %d = %d\n", 1, 1, 2); check(strcmp(buf, "1 + 1 = 2\n") == 0); sprintf(buf, "%d + %d = %d\n", 2, 10, 12); check(strcmp(buf, "2 + 10 = 12\n") == 0); return 0; }
可以很清楚的看到,我们需要实现的是sprintf strcmp两个函数,考虑到字符串需要最基本的长度信息,可以考虑用kilb-marco.h里面的LENGTH宏,也可以先实现strlen函数。 我选择先实现strlen函数,然后用strlen完成strcmp。strcmp的实现思路是:不用考虑两个字符串长度相等/不相等分情况,我们只需要直接找出二者中长度较小的值,以此值进行遍历即可。如果字符串在非结尾处就不一样,那么返回值就是str1的对应项减去str2的对应项。如果二者不一样长,其中一个字符串又是另一个字符串的子串,那么直接用\0减去下一个字符就行了:
for(i=0; i<min; i++) { if(s1[i] != s2[i]) { return (unsigned char)s1[i] - (unsigned char)s2[i]; } } return (unsigned char)s1[min] - (unsigned char)s2[min];
sprintf的实现则更有意思一些,扫描到百分号后根据下一字符做switch即可。目前暂时不考虑更多输出格式和长度格式。printf在后面实现时,基本思路也是一样的,只不过需要putch()向缓冲区输出字符。
----------------------
在后面想要运行代码雨等demo时,需要实现malloc函数。在这里我们只需要实现一个简单的malloc功能,但尽管如此,地址对齐也还是要考虑的。可以参考microbench里面的bench.c,它的逻辑基本可以套用在这里。
bench.c里alloc()的实现:
void* bench_alloc(size_t size) { size = (size_t)ROUNDUP(size, 8); char *old = hbrk; hbrk += size; assert((uintptr_t)heap.start <= (uintptr_t)hbrk && (uintptr_t)hbrk < (uintptr_t)heap.end); for (uint64_t *p = (uint64_t *)old; p != (uint64_t *)hbrk; p ++) { *p = 0; } assert((uintptr_t)hbrk - (uintptr_t)heap.start <= setting->mlim); return old; }
bech_alloc使用了ROUNDUP这样一个宏,展开以后是((((uintptr_t)size) + (8) - 1) & ~((8) - 1)) ,它的功能就是做内存对齐,后面的8-1为7,按位取反后,后三位是000,做到了对齐的效果。在我们的malloc里同样可以用这个宏。只不过在用的时候有个小问题:bench这里为什么要用8?这不是64位机才需要的值吗?
同时,在我们的klib里,addr的初始值需要被设置为heap.start,表示堆的起始地址。后续每次malloc都会更新。
----------------------------------------------
想要运行bad apple,还需要实现memmove等函数。memcpy和memmove两个函数的不同之处,就在于memmove更加安全,它会考虑到源地址和目的地址存在重叠的情况。
在源内存和目的内存不重叠的情况下,memmove和memcpy的行为可以是一样的,由于多了判断部分,可能速度会稍微慢一些。在发生重叠时,memcpy就可能出现无法正确复制的情况:
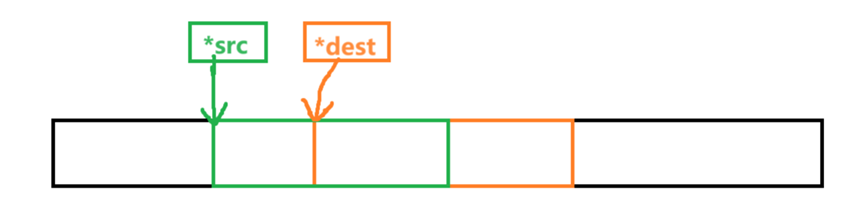
以上面这张图为例,源内存块在前,目的内存块在后,并且存在重叠。如果还是从前往后复制的话,src内存块就会从重叠部分开始被破坏,导致复制错误。面对这种情况,正确做法就是从后往前的顺序逐个复制内存。
同样的,面对这种情况:
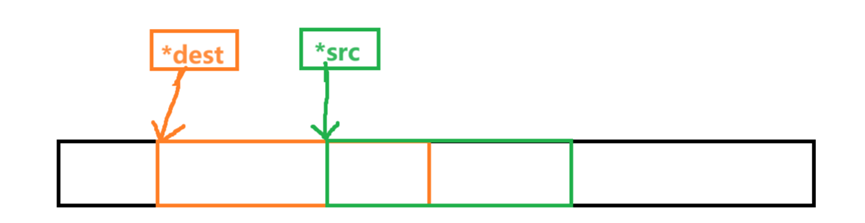
此时就应该使用从前往后的顺序逐个复制,从后往前会破坏内存。
memmove的部分实现:
unsigned char *d = (unsigned char *)dst; const unsigned char *s = (const unsigned char *)src; // 目的地址在前,且内存区域重叠 从前往后复制 if (d < s && d+n > s) { for(size_t i = 0; i < n; i++) { d[i] = s[i]; } } // 目标地址在后,且内存区域重叠 从后往前复制 else if (d>s && s+n > d) { for(size_t i = n; i > 0; i--) { d[i-1] = s[i-1]; } } // 不重叠 else { for(size_t i = 0; i < n; i++) { d[i] = s[i]; } }
别忘了void* 指针要正确++,需要先强制转换为char *指针。
参考:【C语言】memmove()函数详解(拷贝重叠内存块函数)-CSDN博客
-----------------------
关于库函数的实现,标准库函数其实也可能存在漏洞,或者说故意存在漏洞。比如vs下的strncpy函数,它的原型是这样实现的:
char * __cdecl strncpy ( char * dest, const char * source, size_t count ) { char *start = dest; while (count && (*dest++ = *source++) != '\0') /* copy string */ count--; if (count) /* pad out with zeroes */ while (--count) *dest++ = '\0'; return(start); }
这个实现有个隐藏问题:输入参数可能是指针,也可能是字符数组。如果将长字符数组强行复制入短字符数组,就有可能出现问题。
在实现自己的klib时,要采用更安全的实现,还是依照原样由自己决定,因为哪怕函数存在漏洞,人在调用时本身根据用法也应该尽量避免掉。此外,linux下的函数实现似乎也有所不同。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 葡萄城 AI 搜索升级:DeepSeek 加持,客户体验更智能
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏