flume实时采集mysql数据到kafka中并输出
环境说明
- centos7(运行于vbox虚拟机)
- flume1.9.0(flume-ng-sql-source插件版本1.5.3)
- jdk1.8
- kafka(版本忘了后续更新)
- zookeeper(版本忘了后续更新)
- mysql5.7.24
- xshell
准备工作
flume安装
暂略,后续更新
flume简介
Apache Flume是一个分布式的、可靠的、可用的系统,用于有效地收集、聚合和将大量日志数据从许多不同的源移动到一个集中的数据存储。在大数据生态圈中,flume经常用于完成数据采集的工作。
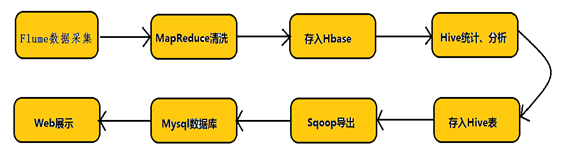
其实时性很高,延迟大约1-2s,可以做到准实时。
又因为mysql是程序员常用的数据库,所以以flume实时采集mysql数据库为例子。要了解flume如何采集数据,首先要初探其架构:
Flume 运行的核心是 Agent。Flume以agent为最小的独立运行单位。一个agent就是一个JVM。它是一个完整的数据收集工具,含有三个核心组件,分别是
source、 channel、 sink。通过这些组件, Event 可以从一个地方流向另一个地方,如下图所示。
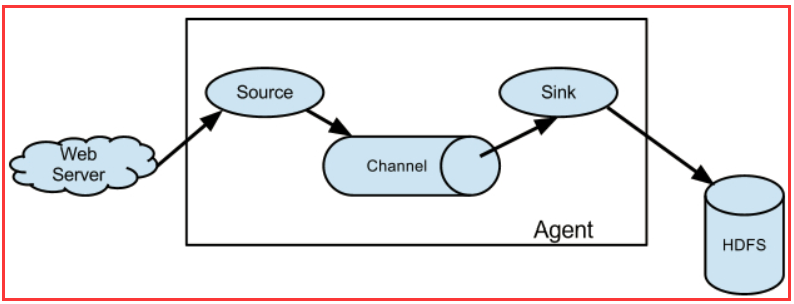
三大组件
source
Source是数据的收集端,负责将数据捕获后进行特殊的格式化,将数据封装到事件(event) 里,然后将事件推入Channel中。
Flume提供了各种source的实现,包括Avro Source、Exce Source、Spooling Directory Source、NetCat Source、Syslog Source、Syslog TCP Source、Syslog UDP Source、HTTP Source、HDFS Source等。如果内置的Source无法满足需要, Flume还支持自定义Source。
可以看到原生flume的source并不支持sql source,所以我们需要添加插件,后续将提到如何添加。
channel
Channel是连接Source和Sink的组件,大家可以将它看做一个数据的缓冲区(数据队列),它可以将事件暂存到内存中也可以持久化到本地磁盘上, 直到Sink处理完该事件。
Flume对于Channel,则提供了Memory Channel、JDBC Chanel、File Channel,etc。
- MemoryChannel可以实现高速的吞吐,但是无法保证数据的完整性。
- MemoryRecoverChannel在官方文档的建议上已经建义使用FileChannel来替换。
- FileChannel保证数据的完整性与一致性。在具体配置不现的FileChannel时,建议FileChannel设置的目录和程序日志文件保存的目录设成不同的磁盘,以便提高效率。
sink
Flume Sink取出Channel中的数据,进行相应的存储文件系统,数据库,或者提交到远程服务器。
Flume也提供了各种sink的实现,包括HDFS sink、Logger sink、Avro sink、File Roll sink、Null sink、HBase sink,etc。
Flume Sink在设置存储数据时,可以向文件系统中,数据库中,hadoop中储数据,在日志数据较少时,可以将数据存储在文件系中,并且设定一定的时间间隔保存数据。在日志数据较多时,可以将相应的日志数据存储到Hadoop中,便于日后进行相应的数据分析。
这个例子中,我使用了kafka作为sink
下载flume-ng-sql-source插件
到这里下载flume-ng-sql-source,最新版本是1.5.3。
下载完后解压,我通过idea运行程序,使用maven打包为jar包,改名为flume-ng-sql-source-1.5.3.jar
编译完的jar包要放在放到FLUME_HOME/lib下,FLUME_HOME是自己linux下flume的文件夹,比如我的是 /opt/install/flume
kafka安装
我们使用flume将数据采集到kafka, 并启动一个kafak的消费监控,就能看到实时数据了
jdk1.8安装
暂略,后续更新
zookeeper安装
暂略,后续更新
kafka安装
暂略,后续更新
mysql5.7.24安装
暂略,后续更新
flume抽取mysql数据到kafka实战
新建一个数据库和表
在完成上述的安装工作后就可以开始着手实现demo了
首先我们要抓取mysql的数据,那么必然需要一个数据库和表,并且要记住这个数据库和表的名字,之后这些信息要写入flume的配置文件。
创建数据库:
创建表:
新增配置文件(重要)
cd 到flume的conf文件夹中,新增一个文件mysql-flume.conf
注:mysql-flume.conf本来是没有的,是我生成的,具体配置如下所示
在这个文件中写入:
这是我的文件,其中一些隐私信息已被我用其他字符串替代了,在写mysql-flume.conf时你可以复制上面的一段代码。下面是这段代码的详细注释,你可以更加带注释版本的代码来修改自己的conf文件
添加mysql驱动到flume的lib目录下
启动zookeeper
启动kafka前要启动zookeeper
cd 到zookeeper的bin目录下
启动:
等待运行
启动kafka
xshell中打开一个新窗口,cd到kafka目录下,启动kafka
新建一个topic
注1:testTopic就是你使用的topic名称,这个和上文mysql-flume.conf里的内容是对应的。
注2:可以使用bin/kafka-topics.sh --list --zookeeper localhost:2181来查看已创建的topic。
启动flume
xshell中打开一个新窗口,cd到flume目录下,启动flume
等待他运行,同时我们可以打开一个新窗口连接数据库,使用我们新建的test数据库和fk表。
实时采集数据
flume会实时采集数据到kafka中,我们可以启动一个kafak的消费监控,用于查看mysql的实时数据
这时就可以查看数据了,kafka会打印mysql中的数据
然后我们更改数据库中的一条数据,新读取到的数据也会变更
before:

after:
.png)
__EOF__

本文链接:https://www.cnblogs.com/namelessguest/p/14137607.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· 因为Apifox不支持离线,我果断选择了Apipost!