狂神说redis笔记(二)
四、三种特殊数据类型
Geospatial(地理位置)
使用经纬度定位地理坐标并用一个有序集合zset保存,所以zset命令也可以使用
geoadd key longitud(经度) latitude(纬度) member [..]将具体经纬度的坐标存入一个有序集合geopos key member [member..]获取集合中的一个/多个成员坐标geodist key member1 member2 [unit]返回两个给定位置之间的距离。默认以米作为单位。georadius key longitude latitude radius m|km|mi|ft [WITHCOORD][WITHDIST] [WITHHASH] [COUNT count]以给定的经纬度为中心, 返回集合包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素。GEORADIUSBYMEMBER key member radius...功能与GEORADIUS相同,只是中心位置不是具体的经纬度,而是使用结合中已有的成员作为中心点。geohash key member1 [member2..]返回一个或多个位置元素的Geohash表示。使用Geohash位置52点整数编码。
有效经纬度
- 有效的经度从-180度到180度。
- 有效的纬度从-85.05112878度到85.05112878度。
指定单位的参数 unit 必须是以下单位的其中一个:
m 表示单位为米。
km 表示单位为千米。
mi 表示单位为英里。
ft 表示单位为英尺。
关于GEORADIUS的参数
通过georadius就可以完成 附近的人功能
withcoord:带上坐标
withdist:带上距离,单位与半径单位相同
COUNT n : 只显示前n个(按距离递增排序)
Hyperloglog(基数统计)
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。
因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
其底层使用string数据类型。
什么是基数?
数据集中不重复的元素的个数。
应用场景:
网页的访问量(UV):一个用户多次访问,也只能算作一个人。
传统实现,存储用户的id,然后每次进行比较。当用户变多之后这种方式及其浪费空间,而我们的目的只是计数,Hyperloglog就能帮助我们利用最小的空间完成。
PFADD key element1 [elememt2..]添加指定元素到 HyperLogLog中PFCOUNT key [key]返回给定 HyperLogLog 的基数估算值。PFMERGE destkey sourcekey [sourcekey..]将多个 HyperLogLog 合并为一个 HyperLogLog
代码示例
BitMaps(位图)
使用位存储,信息状态只有 0 和 1
Bitmap是一串连续的2进制数字(0或1),每一位所在的位置为偏移(offset),在bitmap上可执行AND,OR,XOR,NOT以及其它位操作。
应用场景: 签到统计、状态统计
setbit key offset value为指定key的offset位设置值getbit key offset获取offset位的值bitcount key [start end]统计字符串被设置为1的bit数,也可以指定统计范围按字节bitop operration destkey key[key..]对一个或多个保存二进制位的字符串 key 进行位元操作,并将结果保存到 destkey 上。BITPOS key bit [start] [end]返回字符串里面第一个被设置为1或者0的bit位。start和end只能按字节,不能按位
代码示例
五、事务
Redis的单条命令是保证原子性的,但是redis事务不能保证原子性
Redis事务操作过程
- 开启事务(multi)
- 命令入队
- 执行事务(exec)
所以事务中的命令在加入时都没有被执行,直到提交时才会开始执行(Exec)一次性完成。
正常执行
取消事务(discurd)
事务错误
代码语法错误(编译时异常)所有的命令都不执行
代码逻辑错误 (运行时异常) **其他命令可以正常执行 ** >>> 所以不保证事务原子性
监控
悲观锁:
- 很悲观,认为什么时候都会出现问题,无论做什么都会加锁
乐观锁:
- 很乐观,认为什么时候都不会出现问题,所以不会上锁!更新数据的时候去判断一下,在此期间是否有人修改过这个数据
- 获取version
- 更新的时候比较version
使用watch key监控指定数据,相当于乐观锁加锁。
正常执行
测试多线程修改值,使用watch可以当做redis的乐观锁操作(相当于getversion)
我们启动另外一个客户端模拟插队线程。
线程1:
模拟线程插队,线程2:
回到线程1,执行事务:
解锁获取最新值,然后再加锁进行事务。
unwatch进行解锁。
注意:每次提交执行exec后都会自动释放锁,不管是否成功
六、Jedis
使用Java来操作Redis,Jedis是Redis官方推荐使用的Java连接redis的客户端。
1.导入依赖
2.编码测试
连接数据库
操作命令
断开连接
代码示例
输出PONG
常用的API
string、list、set、hash、zset
所有的api命令,就是我们对应的上面学习的指令,一个都没有变化!
七、SpringBoot整合
SpringBoot 操作数据:spring-data jpa jdbc mongodb redis!
SpringData 也是和 SpringBoot 齐名的项目!
说明: 在 SpringBoot2.x 之后,原来使用的jedis 被替换为了 lettuce?
jedis : 采用的直连,多个线程操作的话,是不安全的,如果想要避免不安全的,使用 jedis pool 连接池! 更像 BIO 模式
lettuce : 采用netty,实例可以再多个线程中进行共享,不存在线程不安全的情况!可以减少线程数据了,更像 NIO 模式
源码分析:
整合测试
1.导入依赖
springboot 2.x后 ,原来使用的 Jedis 被 lettuce 替换。
jedis:采用的直连,多个线程操作的话,是不安全的。如果要避免不安全,使用jedis pool连接池!更像BIO模式
lettuce:采用netty,实例可以在多个线程中共享,不存在线程不安全的情况!可以减少线程数据了,更像NIO模式
我们在学习SpringBoot自动配置的原理时,整合一个组件并进行配置一定会有一个自动配置类xxxAutoConfiguration,并且在spring.factories中也一定能找到这个类的完全限定名。Redis也不例外。

那么就一定还存在一个RedisProperties类

@ConditionalOnClass注解中有两个类是默认不存在的,所以Jedis是无法生效的
然后再看Lettuce:

完美生效。
现在我们回到RedisAutoConfiguratio
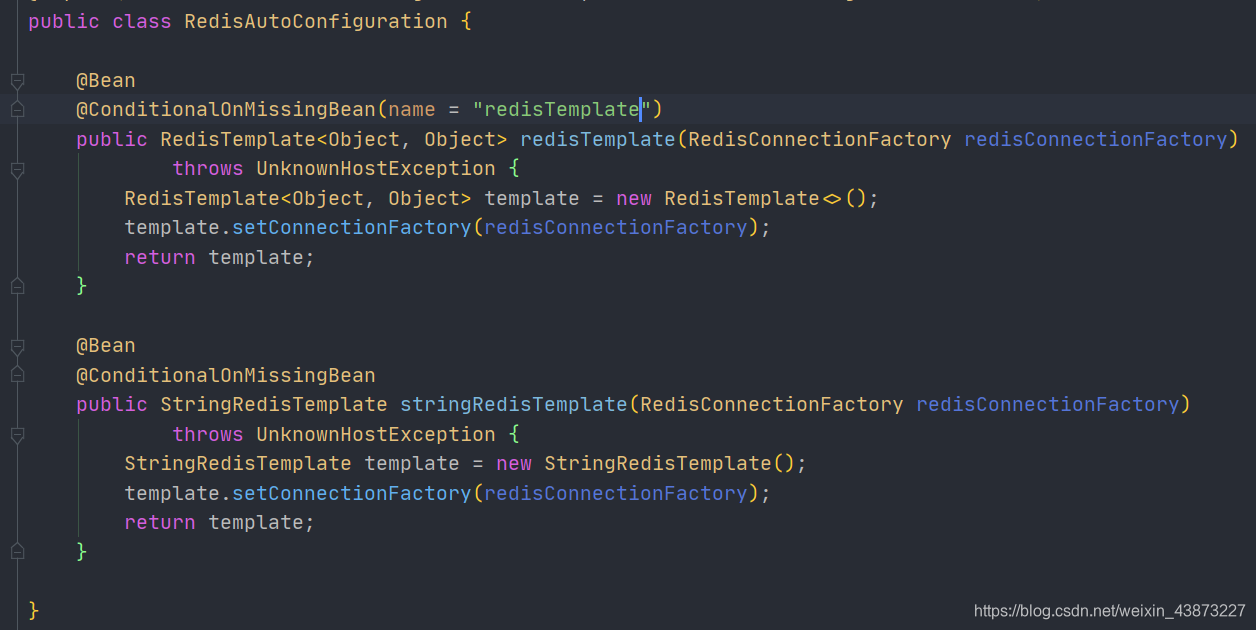
只有两个简单的Bean
- RedisTemplate
- StringRedisTemplate
当看到xxTemplate时可以对比RestTemplat、SqlSessionTemplate,通过使用这些Template来间接操作组件。那么这俩也不会例外。分别用于操作Redis和Redis中的String数据类型。
在RedisTemplate上也有一个条件注解,说明我们是可以对其进行定制化的
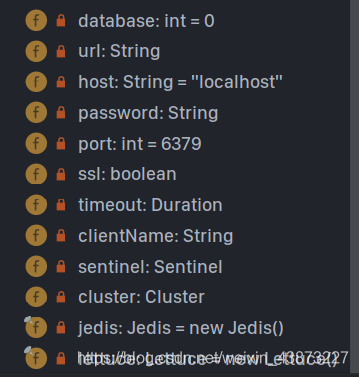
说完这些,我们需要知道如何编写配置文件然后连接Redis,就需要阅读RedisProperties

这是一些基本的配置属性。
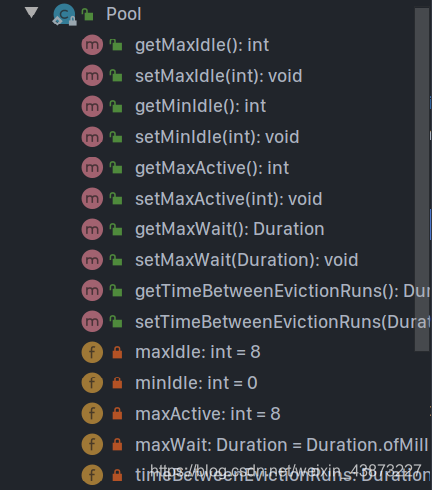
还有一些连接池相关的配置。注意使用时一定使用Lettuce的连接池。
2.编写配置文件
3.使用RedisTemplate
4.测试结果
此时我们回到Redis查看数据时候,惊奇发现全是乱码,可是程序中可以正常输出。这时候就关系到存储对象的序列化问题,在网络中传输的对象也是一样需要序列化,否者就全是乱码。
RedisTemplate内部的序列化配置是这样的
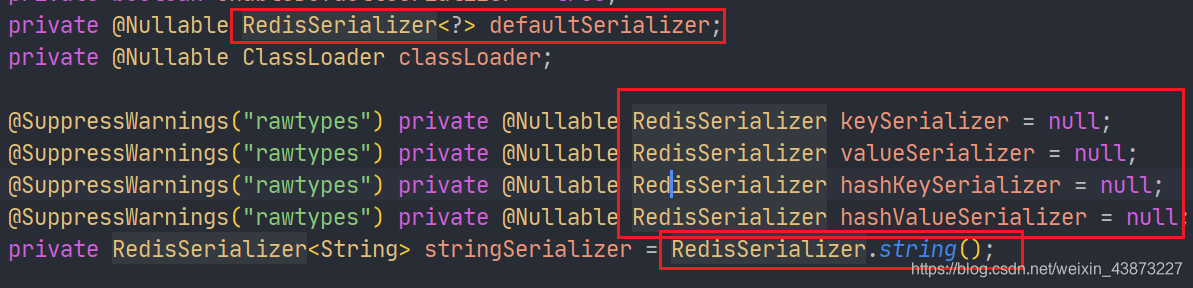
默认的序列化器是采用JDK序列化器
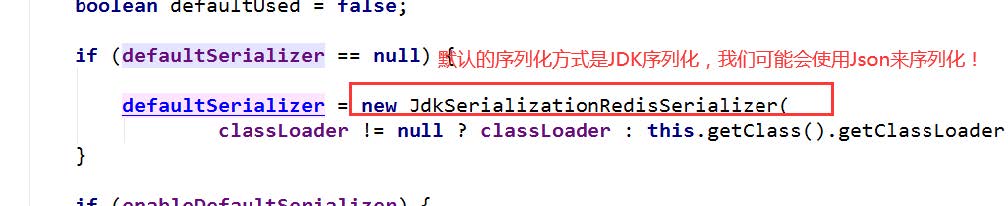
后续我们定制RedisTemplate就可以对其进行修改。
RedisSerializer提供了多种序列化方案:
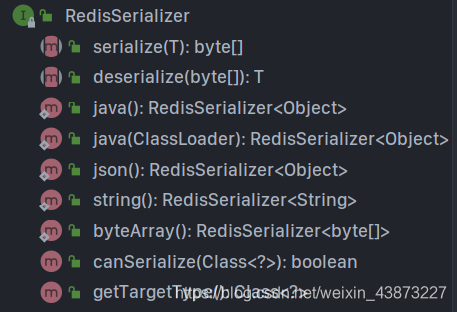
我们来编写一个自己的 RedisTemplete
所有的redis操作,其实对于java开发人员来说,十分的简单,更重要是要去理解redis的思想和每一种数据结构的用处和作用场景!
__EOF__

本文链接:https://www.cnblogs.com/namelessguest/p/13770081.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· 因为Apifox不支持离线,我果断选择了Apipost!