
Hive 基础入门
Hive的官方网站:
Hive简介:
Hive 是基于Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射成一张表,并提供类SQL查询功能。
Hive在企业中作为一种工作,可以很容易的对数据进行ETL。
Hive可以对各种各样的数据进行一种结构化的查询。(按照一定结构进行查询)。
Hive 处理的数据都是存在 HDFS 之上,并且能够与 HBase 进行集成。
分析数据底层的实现都是 MapReduce ,运行都是运行在 yarn 上边。
Hive的用途:
数据的查询、数据的管理。
ETL简介 :
E : 提取数据
T:转换数据
L:加载数据
HQL:
HQL 就是 Hive 查询使用的语句。
Hive本质 :
就是将 HQL 语句转化为 MapReduce 。
Hive 和 Hadoop 之间的关联:
都是使用 HDFS 进行数据存储。
都是使用 yarn 进行资源管理。
都是使用 MapReduce 进行数据处理。
Hive的执行方式:
Hive 就是将数据映射成一个关系型数据库(RDBMS)的表。而执行方式就是 SQL 语句。
执行SQL语句,底层就会自动的将语句翻译为MapReduce程序,提交给 YARN 去执行。
Hive 在 Hadoop 生态系统中的地位:
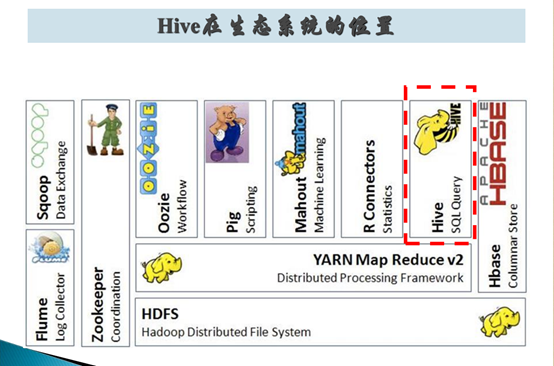
Hive 的架构:

Hive的优点及使用场景
优点:
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手);
- 避免了去写MapReduce,减少开发人员的学习成本;
- 统一的元数据管理,可与impala/spark等共享元数据;
- 易扩展(HDFS+MapReduce:可以扩展集群规模;支持自定义函数
使用场景:
- 数据的离线处理;比如:日志分析,海量结构化数据离线分析…
- Hive的执行延迟比较高,因此hive常用于数据分析的,对实时性要求不高的场合;
- Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号