浅谈Unity的渲染优化(1): 性能分析和瓶颈判断(上篇)
|
http://www.taidous.com/article-667-1.html
前言
首先,这个系列文章做个大致的介绍,题目“浅谈Unity”,因为公司和国内大部分3D手游开发还是以Unity3d为主,而Unity不开源的问题,也注定大部分用户是无法在架构和API的层面对它做改造和优化的,所以本文也不会涉太多底层的优化方法,为了争取能让更多制作相关的人员看懂,而是针对Unity的设计,把如何在设计和使用上来规避和利用的“浅显”方法用易懂的方式来描述。“渲染”也限定了本文也仅限定在图像表现相关,现在,互联网上的很多Unity图像优化的分享,也是在Unity的使用方面的注意事项和建议为主。但是,硬件性能每年都在提升,用户的需求也在提升,以及竞品游戏的挑战,一些通用的优化指导方案也会变成得没有太大或是误导,美术的想法或者一些特效,也会因为优化考虑不足,而早早放弃。各个芯片厂商的分析工具和优化指南,与Unity的实现以及具体制作没有直接关联。所以,本文的主题也是希望能在这个问题上提供一些更有建设性的意见和方法,同时也是消除误解,更有优化意识的来制作和开放,从而为图形表现,游戏性能的提升,以及作为副产品的耗电,散热更少等等的用户体验上,争取更大的空间。
由于时间的缘故,同时也需要为论点提供更多数据和测试做论据,本文会拆分为多个章节发布,除了本章节的性能分析和瓶颈判断,CPU,GPU,内存使用各部分的优化会根据内容量占1~3节,Unity自身问题的对应和解决1~2节,而最后架构和API相关会根据具体实现的效果,确定是放在最后还是单独开一个优化系列。计划是每周更新一节。另外,在一些可以深入了解的地方也会留下扩展阅读的链接,这些在分享将来架构和API方面的优化时也会详细的涉及到,建议以前没深入接触过又有兴趣的读者有时间阅读下。
性能分析和瓶颈判断 一 本节概述 本章节标题随是分析相关,但我想最关键的是,不论我们使用的是什么引擎,引擎架构的底层还是通过API和终端硬件交互,为了能够硬件性能,我们的优化也应该针对底层的API和硬件来进行分析,所以,遇到性能问题是这种意识的来分析和解决瓶颈,甚至有意识的来制作场景,特效,那么对游戏性能和效果的提升会有很大帮助。其中,前者遇到问题的分析,大多最后由程序开发背景的技术人员负责,难度并不大,很多项目也早已引入,但在如果在保证制作的同时保证优化,一个是由程序来推动美术,对程序的要求和美术执行力都是一个挑战,而且制作后期发现瓶颈,要返工的成本也是很大,从技术美术的角度,还是在制作中期就可以对一些可能引起瓶颈的效果做评估和优化。所以,本文也尽量简化技术术语,让有一些游戏开发基础的读者就可以理解。
那么为了能够把这个问题阐述清楚,本节所包括的内容:
1 )图形管线简介
对于“图形管线”这个定义,我这里还是沿用【A trip through the Graphics Pipeline 2011】(中译名:图形管线之旅)这篇系列文章里的介绍,并不仅仅是D3D/OpenGL图形管线,而是涵盖了这些3D API的低级别的GPU和管线描述,也就是说,在了解这些3D API的功能外,你还是需要了解它在操作系统和GPU上的运作,也就是API“为什么这样做”和”如何去做“(这些对于OS/GPU方面来说也仅是上层描述),了解API在操作系统和硬件的运作原理。
不想在开头就太过枯燥,这里还是和【图形管线之旅】一样,在最初还是跳过API细节,以3D API D3D在Windows上运行在DX11等级硬件这个环境来介绍(主要也是没找到移动方面合适的资料,加上大家对PC环境更了解一些)。
这部分引用的资料和图片引用自:
1. A trip through the Graphics Pipeline 2011(图形管线之旅,cnblog上可以找到中译版)
https://fgiesen.wordpress.com/2011/07/09/a-trip-through-the-graphics-pipeline-2011-index/
2. AMD Comments on GPU Stuttering, Offers Driver Roadmap & Perspective onBenchmarking : The Start: The Rendering Pipeline In Detail
http://anandtech.com/show/6857/amd-stuttering-issues-driver-roadmap-fraps/2
3. Windows驱动程序入门,这个了解下用户模式( User-Mode)和内核模式(Kernel-Mode)就好了
https://msdn.microsoft.com/zh-cn/library/windows/hardware/ff554836(v=vs.85).aspx
如果已经看过足够了解的话可以跳过本段,我这里也只做关键点的描述:
首先,引用下图对Windows的图形渲染管线(Graphic Rendering Pipeline)对做一个高层次的预览,【图形管线之旅】里把这部分称作"Software Stack":
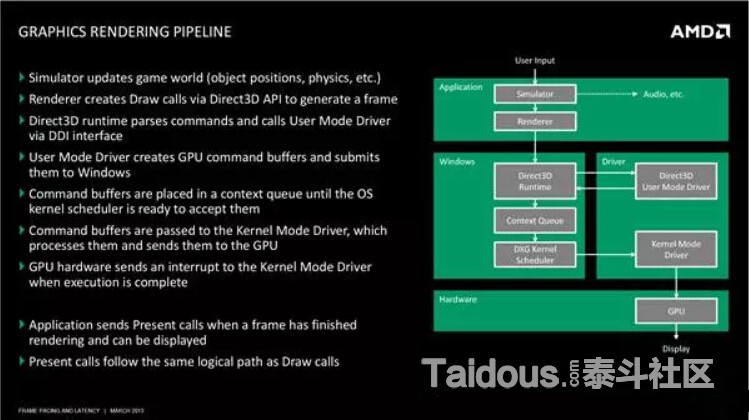 这里我结合【图形管线之旅】的第一节的描述https://fgiesen.wordpress.com/2011/07/01/a-trip-through-the-graphics-pipeline-2011-part-1/ ,对这个流程做下介绍,核心思想就如上图所示,我们调用API(Draw Call),并不是直接操作GPU,其中还要经过操作系统和驱动的处理,最终通过总线传到GPU。PS:这里应该也是本节比较枯燥的部分了(大部分也是拷贝粘贴的),具体每个绘制阶段,我会在具体的优化实例里在提及。
Application
可以是一个简单3D应用或者3d游戏或者游戏引擎,在上图中,我们把App简略分为模拟器(Simulator)和渲染器(Renderer),模拟器来更新游戏世界,比如每帧的动画,物体对象的位置更新等等,模拟后的结果,由渲染器创建Draw
Calls 通过DirectX或OpenGL的API生成一帧。
API(Direct3D) Runtime
通过API创建资源(Resource) 状态 (State)和绘制(DrawCall),并负责跟踪状态,分析验证参数,处理错误,检测一致性,验证Shader,Link Shader(OpenGL是在驱动层),再传递给用户驱动(User-Mode Driver)来处理所有事情。
(Direct3D) User Mode Driver (or UMD)
这个也是游戏玩家比较熟悉的“图形驱动”了,或许大家都有过一个新出的PC游戏玩起来非常卡或者各种bug,Nivdia或Amd更新一个新版本显卡驱动就什么问题都没有了的情况,它其实就是在PC上是一个由GPU开发商提供的DLL,通常是叫做"Nvd3dum.dll"(NVidia)或"atiumd*.dll"(AMD) ,和你的APP一样,运行在同一个Context和地址空间里。
UMD负责的有,Shader的高层优化,比如循环的优化,分支预测等等,以及底层优化,寄存器分配,循环的展开等等。 像Nvidia的话,我们还可以看到它对特定游戏特定硬件的优化等等。然后是,Shader运行前的创建/编译,但这个过程是在第一次Draw Call运行并使用时才会执行,所以会遇到一个使用新Shader物体第一次显示时的卡顿现象。其他的功能就像内存管理,通过后面讲到KMD()分配出一块内存,给Texture分配空间。最后,UMD还有一个主要职责,就是把API
Runtime的输出,转化为GPU可以处理Command Buffer(之后还有多个叫这个的,别搞混了),或者叫DMA(Direct Memory Access)Buffer,也就是把状态变化和绘制操作转化为硬件可识别的指令,在把它再传回到API Runtime。下图就是一个Command Buffer的逻辑视图。
 这里要额外说一下的是,DirectX可以直接用HLSL编译生成ASM来做Cache,而GLSL需要在真机上通过不同芯片商的驱动编译运行一次再进行Cache, 这也就产生一定的Shader验证困难,比如某个特定的Shader在某个特定芯片的手机上显示错误的问题,都必须在出问题的终端设备上进行分析和调试。
Context Queue
当UMD工作完成后,他会把Command Buffer传递到Context Queue(上下文队列),也叫做[AMD] Flip Queue / [Nvidia] Pre-rendered Frames Queue。上下文队列的目的,是为了排列每个Command Buffer,并保证CPU和GPU同步没有STALL,当CPU提交绘制命令提交到GPU后,GPU开始进行渲染需要一定时间,这时如果CPU停下来等,就浪费了CPU的计算资源,于是就当前帧的绘制放入队列,CPU继续进行下一帧的模拟和渲染提交,这样的好处是CPU可以持续的为GPU提供数据,也就提高了效率,而缺点则是会增加一定的延迟(Latency),DX12硬件规格之前的PC,默认CPU比GPU会快三帧的说法,也是来源于此,我们实际看到的画面是CPU三帧前就模拟和提交渲染的。
3帧延迟也同样导致了一些问题,比如输入响应的滞后,硬件Occlusion Cull查询的滞后,一些每帧要从CPU->GPU传递的数据(比如顶点动画Mesh)可能会有预留在驱动中。
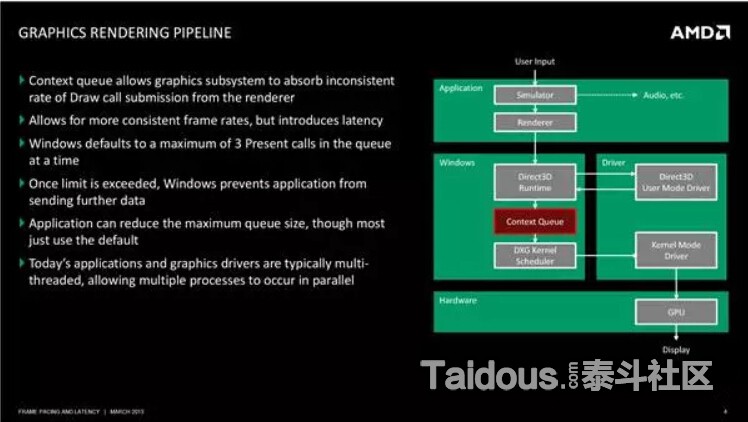 移动终端上。GLES也有类似的延迟处理方式,但和PC还是有所不同的,引用http://community.arm.com/groups/arm-mali-graphics/blog/2014/02/03/the-mali-gpu-an-abstract-machine-part-1
如果没有驱动这些中间层的协调,你的CPU和GPU的同步可能会是这样,灰色空白区域都是浪费的空闲时间
如果驱动处理后,就可以在Frame1的GPU处理时,提前进行Frame2的CPU处理,这时GPU几乎没有空闲,可以不间断的获得绘制指令。
而现在通用的Tiled-Base的GPU架构大多是这样,CPU是第N-2 帧,N-1帧是GPU的顶点处理(Vertex Processing),N帧是GPU的片元处理(Fragment Processing),所以移动终端上也有类似的延迟问题。
上图如果考虑到同步的话,因为GPU的片元处理时间过长,所以会出现CPU等待的情况,那么实际大概是下图这样:
具体的移动架构的优缺点和解决,我想还是到具体GPU优化时再结合案例来介绍好一些,暂时介绍到这。
DXG Kernel Scheduler
前面提到,UMD只是挂在应用进程中的DLL,如果多应用进程都想要调用GPU的话,那么就需要调度器来决定不同的应用之间何时访问,来保证同一时间只有一个应用进程可以提交command到GPU
Kernel Mode Driver (or KMD)
KMD是实际处理硬件的,KMD永远只有一个,负责管理实际的Command Buffer,初始化重置GPU等等,并向Main Command Buffer(一个很小的Ring Buffer)写入系统和初始化,以及真正的3D指令,提供给GPU使用。
System Bus
PC平台上,CPU并不能直接访问GPU,而是要通过PCI Express总线。不过移动终端的芯片大多是SoC(System on a chip),并没有bus。
Command Processor
命令处理器就是GPU的前端,负责读取KMD写入的Command buffer,然后就是GPU的工作了。
最后,当我们把一帧渲染到GPU的back-buffer后,调用Direct3D Present() 或OGLeglSwapBuffers(),这标志着你一帧的绘制已经结束,并且要把back-buffer的内容flip到前端来显示了。
而GPU方面的话,我想还是结合后面具体优化方案,再进行详细介绍吧。
2) CPU优化基础
和渲染管线一样,这里也是会涉及一些和硬件相关的低级别的概念。概述中提到,这部分的优化因为Unity源码的限制,无法在架构设计或者API调用上直接做优化和修改,希望在这里做一个简单的介绍,来了解一款设计优先的游戏引擎的潜力。作为介绍的切入点,我们从最近几款iOS移动设备芯片的比较开始:
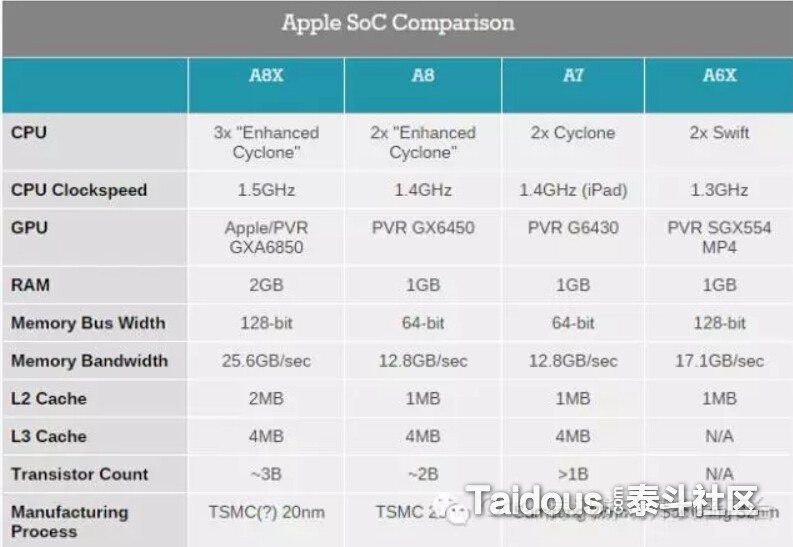 上图中,各个Soc分别对应的是A8X(iPad Air 2),A8(iPhone 6),A7(iPad Air / iPhone 5S / iPad Mini2),A6X(iPhone5 / iPad4), 对应的硬件参数,这里列下和CPU性能相关的参数:
CPU:3x "Enhanced Cyclone",这里3x就代表3核
CPU Clockspeed : 每个CPU核心的时钟频率。
RAM : 内存,对游戏效率并没有直接影响,但内存不够的话游戏很难能运行起来,或者是容易崩溃。
L1 ~ L3 Cache : CPU高速缓存,A8X的L1 Cache应该是每个核 64 KB instruction + 64 KB data。
要解释这些的话,如果我们配电脑或买手机,CPU的核心数量和每个核心的时钟频率一般都是各个厂商的主要宣传的部分,“核越多,主频越高,设备性能也越好”。而RAM(和PC不同,一些商家和用户会错把移动设备ROM也叫做“内存”,比如64G内存的iPhone6一类),目前最新iOS设备iPhone6S是2GB外,大部分还是1GB,Android的话,今年像小米note增强版达到4GB外,大多旗舰机种也是3G作为标准了。
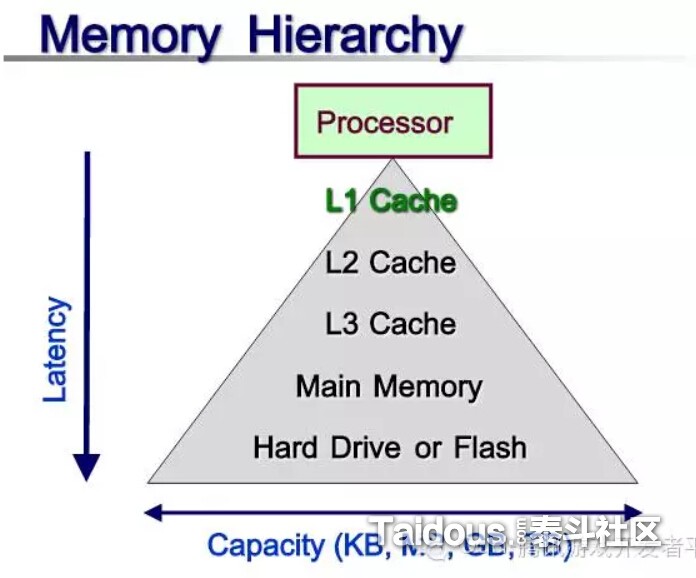 上面是CPU Cache的示意图,因为硬件设计的限制,CPU的加载和存储单元,以及指令的获取,都不能直接访问内存,而是告诉L1 Cache你要处理什么,但由于成本缘故,L1 Cache的容量不能做的太大,为了可以提高速度,就要再配置容量比L1大一些速度也慢一些的成本更低的L2 Cache以及L3 Cache,最后就是通过L3和内存直接操作。
之所以这么设计,是因为普通内存的频率比起CPU的主频还是慢太多,为了减少不必要的等带时间,需要更快速的Cache来做存储,多层设计也是成本的考虑。而CPU在工作时,先会判断要访问的内容是否在Cache中,如果有,那就是“Cache Hit”,那样就可以直接高速的从Cache中调用,没有的话,那就是“Cache Miss”,如果L1~L3的Cache里都没有,那么就只能从最慢的内存里读取了。如果我们能保证CPU处理的内容,尽量都在cache里的话,比如一块连续物理内存地址的数据做操作时,那么就可能获得更高的效率。为了争取“Cache
Hit”的连续性,多一些额外的内存使用和数据传递是可以的。
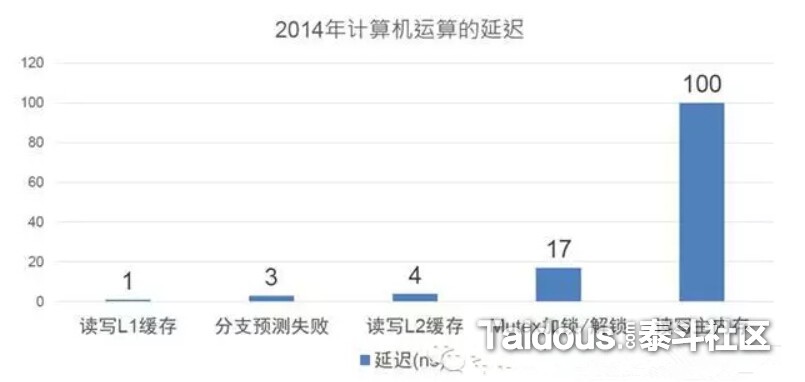 上图是叶劲峰 (Milo Yip) 在 CGDC2015的讲座【为实现极限性能的面向数据编程范式】,里面的几个面向数据设计的案例也可以参考,包括Milo开发的rapidjson,也是一个充分利用cache的例子。图中可以看到L1 Cache读取和内存读取的速度差别,另外占17ns的是“Mutex加锁/解锁”了,在利用CPU的多核做多线程并行时,为了保证线性安全,需要对他们共享的内存进行加锁/解锁的操作,如何尽量减少锁竞争的消耗和它锁住资源时导致其他线程的查询等待的消耗,也是多线程并行开放的一个关键问题。
到此,游戏引擎架构的CPU优化的目标大概也能确定了,“充分利用多线程”,“尽量降低Lock Free的消耗”,“足够高的Cache hit”,也是这些年各大游戏厂商的游戏引擎的一个研发方向。Cache和内存使用,数据结构的设计都有联系,细节还是在实际优化案例里再阐述吧,下面链接是内存,Cache方面的CPU优化的一些扩展阅读,有兴趣的话可以确认下有没有以前没看过的:
Memory, Cache, CPU optimization links
https://gist.github.com/ocornut/cb980ea183e848685a36
虽然还没进入本篇主题,但接下来还是要花一些篇幅来“多线程”技术阐述一下:
多线程渲染 Multi-thread Rendering:
首先要了解的,“多线程并发(Concurrency )的并行 (Parallelism) ”和“多线程渲染Multi-thread Rendering ”是两个概念,“多线程渲染”简单来讲是指在多个线程同时提交Draw Call(Commands),同时写入到GPU可识别的Command,这样就可以提交更多的Draw Call了。而因为硬件,驱动,操作系统上的一些历史缘故,直到最近的Windows
10 + D3D12上,才真正意义上支持了“多线程渲染”。
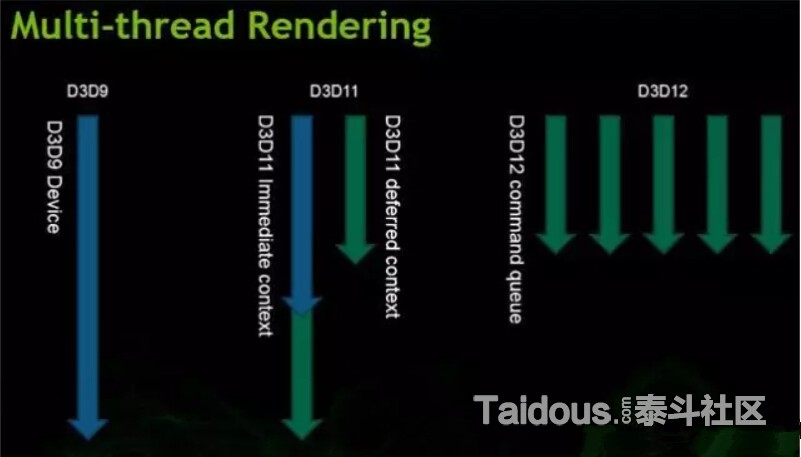 上图是Nvidia的一张D3D多线程渲染的示意,左边的D3D9和D3D10,只能有一个线程调用图形API,通过驱动来直接写入到实际的Command Buffer,再提供给GPU调用。而D3D11里所提到的“多线程渲染”,只是分出了Immediate Rendering和Deferred Rendering,Deferred Context 可以记录中通过多个线程写入的命令,但实际的推送,还是要靠主线程中Immediate
context来做推送,而D3D12里,真正实现多个线程对应多个Command list写入指令和数据,并按指定顺序来执行"多线程渲染",主要还是得益于Windows10和D3D12的改变,同时也是把驱动的部分任务移交给了开发者。我自己没接触过实际的D3D12开发,这里也就不多说了。
再来说移动平台,和D3D对应来说的话,GLES3.1和iOS的Metal API大概就是D3D11的等级,之前的ES2.0和3.0和D3D9差不多,所以移动上的真正的“多线程渲染”可以暂时不用考虑。
既然D3D12之前,无法做到多个线程同时调用图形API ,那么只能尽量在一个线程里高效的调用了。那么,最好的方法就是有一个专门的渲染线程,独占一个CPU的线程来提交API指令,像大家熟悉的商业引擎,CryEgnine,Unreal Engine,Unity3D等,都是这种方法,接下来结合Frankan(安柏霖)【《天涯明月刀》多线程渲染解决方案分享】中的几张图来介绍这种渲染线程技术:
幻灯片的链接 http://gad.qq.com/college/articledetail/91
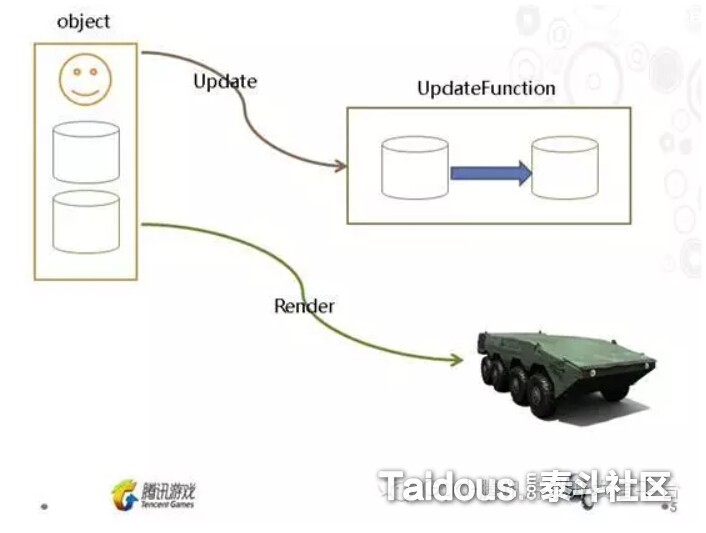 一开始提到,Application包括模拟器和渲染器,也就是上图中,物体对象的更新(模拟)和模拟。如果是单线程运行的话,就是先执行完Upadte,再根据这些数据进行Render。而多线程进行的方式是,是通过创建CommandRingBuffer,一般是一个环形的队列,主线程的物体对象Update后,就把数据和绘制命令添加到CommandRingBuffer,然后渲染线程再从这个Buffer取得命令来实际执行。这样,Render就可以渲染线程不受阻塞的高效提交绘制命令了。也就是下图这样:
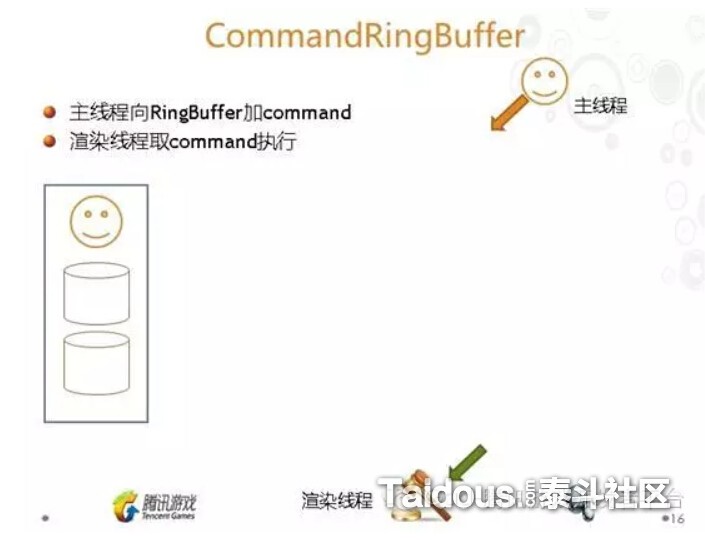 前面也提到,多线程的另外一个难题,就是共享内存的线程安全,因为主线程和渲染线程是并行处理的,一些在主线程每帧更新的数据,无法直接就把数据地址传入到CommandRingBuffer,让渲染线程取来使用,简单的方法就是对这些数据的副本传入。而天刀中使用“GraphicAsyncObject”进行封装。有兴趣可以看看PPT,这里就不多做介绍。
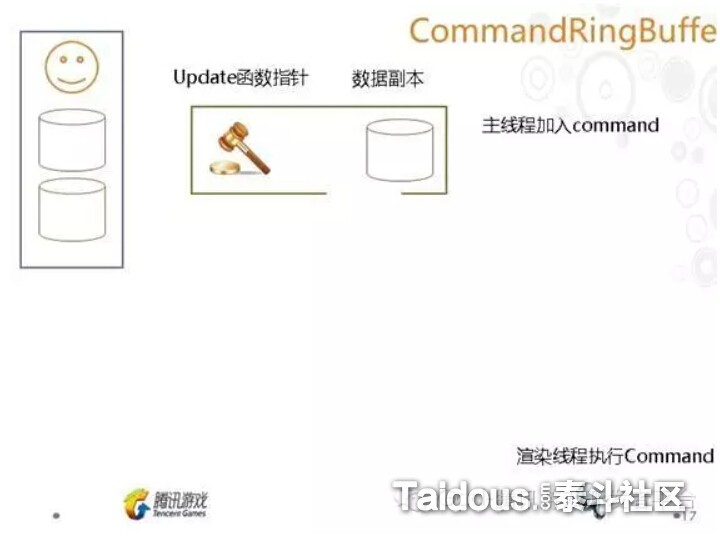 这样,我们的CPU核心,已经有主线程和渲染线程两个线程占用了,对于渲染线程这个设计,我想在D3D12真正普及和对应的引擎设计成熟前,不会有太多改变了,做移动平台的话就更是如此。我们也知道,不论是PC还是移动终端,CPU的核心数也越来越多(Intel超线程技术可以让一个核心当两个线程用),接下来要提及的就是如何让物体对象的Update,以及各种游戏功能,可以更高效的利用剩余的CPU核心。
多线程的并发与并行
游戏中有大量需要Update的物体对象的,各种动画,粒子,物理模拟等,还有游戏逻辑相关的处理,如果都在一个主线程,那CPU就会成为瓶颈,每次GPU都要等待CPU的处理。为了尽量让每个CPU核心可以跑满,一般游戏会创建线程池,一种用法把一类物体对象的更新,比如粒子或动画,也放到专用线程里,其他还在主线程进行。虽然每个核心分担了一部分处理,但分担的并不平均,还是会有空闲。或者就是一个进程同时运行10多个线程,但同样要考虑到线程的切换开销,以及共享内存Lcok/Free的消耗和其他线程的等待等等。为此,需要一种线程的使用更充分和平均,锁竞争和线程切换引起的开销更小的设计。
为了下面的介绍可以更好理解,这里先对两种锁机制Spinlock和Mutex区别做个对比:
Mutex(或Semaphore):
属于sleep-waiting类型,通过Critical Section 方式实现,比如有双核CPU上有两个线程A和B,A去获取Critical Section的锁,发现这个锁被B持有,那么它会选择Sleep,进入内核态,要很昂贵的系统调用,这时线程A占用CPU核心也会进行上下文切换(Context Switch),把A放入等待队列里,然后去运行线程C的任务,而不是一直等着A。
Spinlock:
属于busy-waiting类型,用Atomic flag方式实现,可以理解为一个While循环不断的去获取锁,不会产生线程状态切换(用户态->内核态),优点就是省时间,对比Mutex要快很多,如果Mutex延迟17ns的话,Spin也就是1~2ns,缺点就是要一直占用CPU,当出现锁竞争很激烈时,或者执行的代码(临界区)长度过长时会导致很严重性能的问题。而且也不能在代码里进行IO这种系统调用的操作。
所以,一般比较复杂的应用场景还是选择比较灵活Mutex,而选择Spinlock做优化。当然,多线程并行的极致,还是尽量减少锁的使用,实现无锁的并行。在根据用例测试,判断出这少部分的锁应该使用那种方案。
接下来介绍几个厂商分享的解决方案:
DICE的寒霜(Frostbite)引擎 :
2010年前后,EA的DICE工作室分享了他们的寒霜引擎通过EA JobSystem实现的Job-based Parallelism,分割所有的CPU的系统工作,并放入Job(Tasks),每个Job大概是15~200K(行数)大小的C++代码(平均25K),然后按照预设的Job的依赖关系和同步点等,动态的生成Job Graph,然后再按照这个Graph,进行每个阶段的并行计算。这个设计的优点,就是每个阶段的执行,都可以尽量的跑满处理器资源,而且,这样同一类任务一同进行,对Cache
Hit也有帮助。不过这个设计同时要跑在PS3家用机的CELL处理器的SPU上,PPT信息又太少,谁要是更多的资料也希望可以分享下。
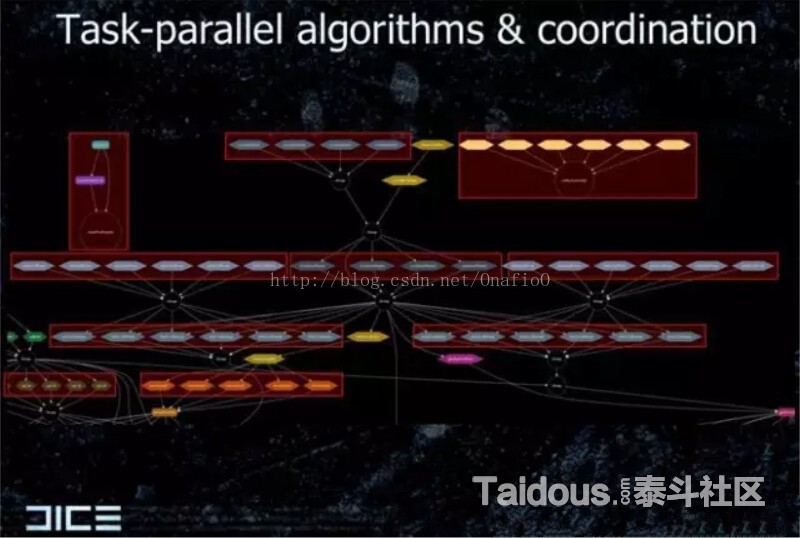
下图就是参考的ppt:Parallel Futures of a Game Engine (v2.0) 和Parallel Graphics in Frostbite –
Current & Future 中的插图 从放大到400%感觉右边的Job Graph应该实现的是Software Occlusion Culling的功能。
 下图是上面右图的一部分放大,每个红框都是可以并行执行的Job。执行顺序在ppt里看吧。
 顽皮狗(Naughty Dog):
2015的GDC上,Naughty Dog分享了他们的Fiber Job System,实现了更灵活的而且没有竞争锁以及线程切换的多线程并行解决方案。这里还是结合PPT的图来做个简单介绍:
PPT名 Parallelizing the Naughty Dogengine using fibers ,篇幅有限我尽量少摘录几张图:
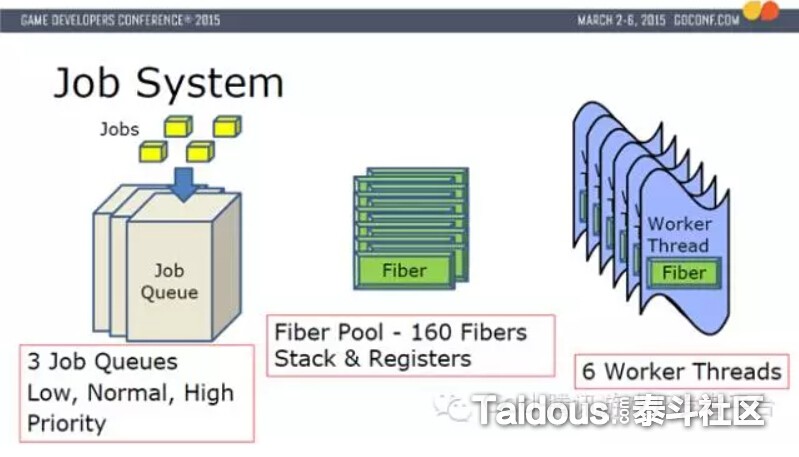 Naughty Dog的Job System对应的是X86的PS4家用机平台,硬件上和传统PC和移动终端更接近了。
有6个工作线程(Worker Threads),每个工作线程都锁定在一个CPU的核上。每个工作线程都是一个执行单元。
Fiber是作为很小上下文(Context)执行在实际的工作线程上,只包含fiber的State,Stack Pointer,Registers的信息,Fiber切换时,并没有线程上下文切换。使得开销最小化。
Job在Fiber的Context中执行,而且Job在执行中,它可以yield到其他Job返回结果再继续执行(类似Unity的协程)。然后Job放入到不同优先级的Job Queue里。
游戏几乎所以的处理都是一个Job,物体对象的更新,动画的更新,命令缓冲生成等等,除了前面提到的I/O操作。
PS4重制版的【最后的生还者(The Last of Us)】中,每帧大概有800~1000个Job。
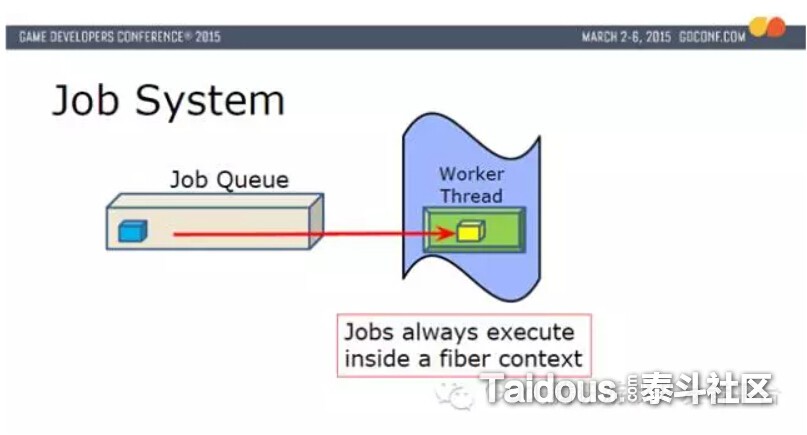 实际执行时,根据优先级,从Job Queue选择黄色Job放入到Fiber的上下文中,然后Fiber在Worker Thread上执行。
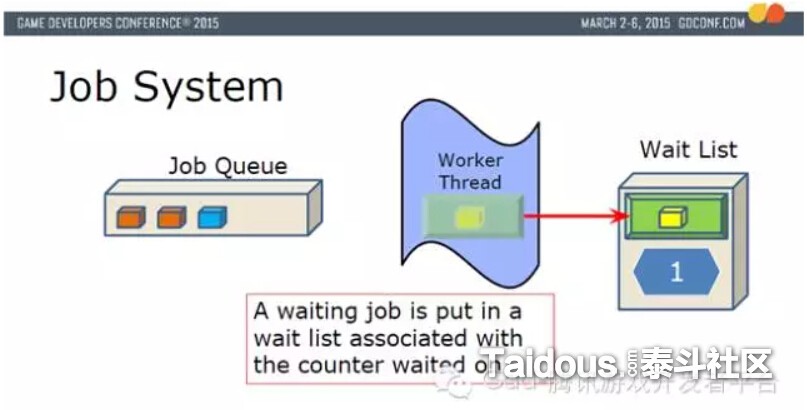 黄色Job,可以添加更多Job(橙色),这时如果在黄色Job里调用RunJob(...)来运行蓝色Job,并WaitForCounter(...),这时,就会把有黄色Job的Fiber,Counter存入Wait List
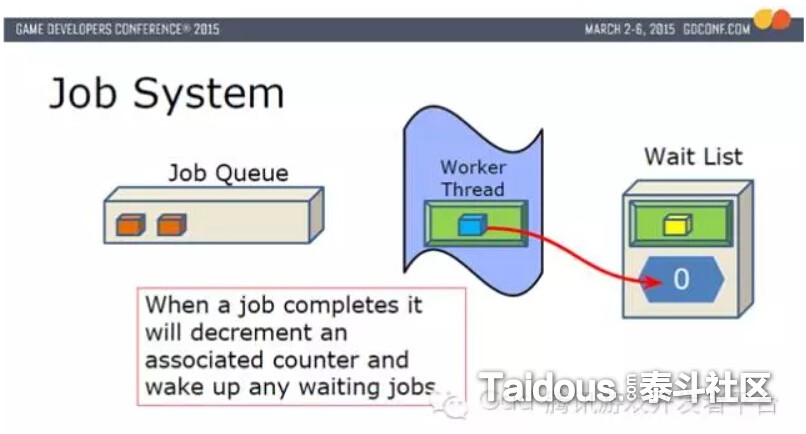 然后,从Fiber Pool取出一个新的Fiber放入到Work Thread,并让蓝色Job在这个新的Fiber上执行。当蓝色执行完成后,把Wait List里对应的Counter -1,并唤醒黄色Job,然后把蓝色Job使用的Fiber释放回Fiber Pool。
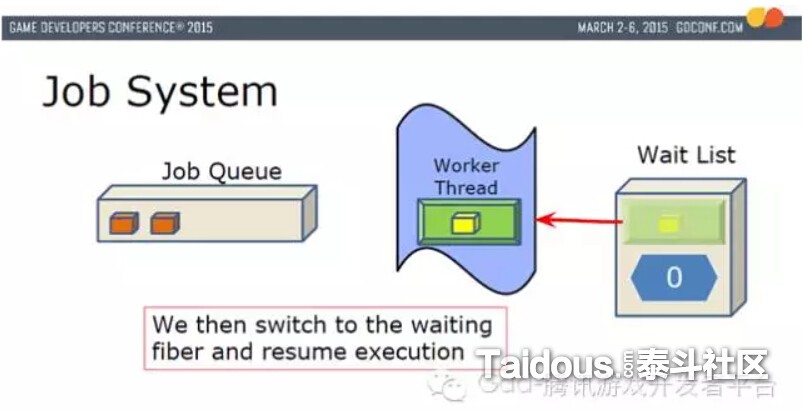 把黄色Job和Fiber放入到Worker Thread里恢复执行。这个图例只是一个Worker Thread的运行,6个Worker Thread时,Fiber会根据空闲情况,执行在不同的Worker Thread上。
 最后的图是对物体对象做动画的事例。RunJobs函数安排所有的Job以及生成JobCounter,然后调用WaitForCounterAndFree,当前Job进入Wait List。
以上就是Naughty Dog的JobSystem的大概运行流程,另外一个内存分配的要点,篇幅缘故就不在介绍,总的来说,Fiber JobSystem有着极为轻量Fiber切换,完全抛弃了Mutex,semaphore, condition variables这种类型的锁,而全部改用Atomic spin locks,速度提高了,我们之前提过的spinlock的缺点也会引发问题。一些需要Mutex的地方,只能用Sleep来替换了Spinlock了。而且,Naughty
Dog的游戏是只限定在PS4上的,Spinlock和Mutex在更复杂环境,以及不同的硬件上的性能表现也有是差别的。
网易的Messiah(弥赛亚)引擎:
Messiah目前还没有太多公开资料,这里也只是一些听说的特性的整理,目前应该还是面向手游开发为主,这里也对Messiah的多线程方案做一下简单的介绍,有了之前几个引擎多线程技术的讲解,理解起来应该不会太困难了:
Messiah沿用了一部分我们已知的技术:
和大部分游戏引擎一样,同样要有CommandRingBuffer,在锁定一个CPU核心来做渲染线程(设备线程)执行绘制指令。
和Naughty Dog的Fiber Job System类似的,把剩余的CPU核心锁定为工作线程(WorkerThread),这样就避免了线程切换的消耗。
同Fiber Job System类似的,也是把引擎的全部工作都分割为Job(Task),Task本身不需要担心锁的问题。
同时也有创新的地方:
在Task无锁并行实现上,DICE的方式是通过设定依赖关系和同步点,生成Job Graph,来确保线程安全和并行效率,而Naughty Dog,则是要在一个Job里调用RunJobs和WaitForCounter,来实现并行,这两种方式,都需要开放人员有一定的多线程并行开发经验,而且要了解引擎运行机制,开发难度比较高。
Messiah是参考了boost::asio::strand,采用了设计任务调度器(Task Scheduler)的方式,通过Task的派发策略,让并行的Task之间没有共享内存,来保证无锁情况下的线程安全。因为是尽量无锁的,采用Spinlock还是Mutex,会根据具体情况来决定,不会有Fiber Job System那样的限制。调度器要考虑的内容也是很多的,首先,为了保证一定Cache
Hit,同一类Task还是要尽量安排在同一个Worker Thread运行,同时也要考虑到Task的亲缘性,例如一个Task调用另外一个Task,也要尽量和前一个Task在一个Worker Thread。同时它实现了task stealing,当一个Worker Thread空闲时,调度器会安排运行其他的Task,从而实现了task的均衡负载。
调度器另外一个功能,是要保证渲染的Command buffer的执行顺序的正确,Messiah并没有真正意义上的主线程,而是每个Worker Thread都有自己的RenderContext来生成独立的Command buffer,再把它通过CommandRingBuffer推送给渲染线程来执行,虽然大部分的绘制不受调用的先后关系影响,但比如不透明物体和透明物体的绘制顺序,后处理RT等等还是有顺序依赖的,所以调度器也要保证一部分Task执行生成的Command
buffer的前后关系。
Messiah这种调度器方式的目标是,降低并发代码的设计维护成本,尽量由调度器来代劳。但还是无法回避出现Bug时多线程调试困难的现状,同时,像苹果的iOS设备,一般也就是2~3个核心,并行效果和Android4~8核设备比有多大差别,也不是太清楚。
Messiah配套的一些其他的优点,比如基于GPU Bake lightmap以及GPU压缩PVR/ETC,在美术资源的迭代开放测试上也很有帮助。大部分也是听说的,所以最后Messiah的实际情况,还是要看最后发布的游戏和引擎设计人员的技术分享来确定了。
小结
几乎花了大半个篇幅来介绍和Unity无关的多线程技术,主要目的还是希望开发者可以了解到Unity在CPU优化上的一些不足,同时,这也是自研引擎的一大优势,同样的设备,并行效率更好的游戏引擎,可能运行的Draw Call会比Unity更多,更何况还可以针对不同的游戏类型做定制等等。所以我们在用Unity针对竞品游戏做开发时,也要把这部分因素导致的差距考虑进去,在CPU优化上多下一些文章。多线程优化部分,在后面也不会在提及了,这里就稍微多写了一些,还请谅解。
而且,上面阐述的多线程技术,仅仅是纸上谈兵罢了,还是要到实际开放中去体验,测试,才能获取出合适的方案。希望本篇结束时,我也能有一些试验成果分享。如果在多线程并行上很难有图片的话,那么就是接下来要讲的,试图在3D API上做优化。
3D API CALL的优化
对于3D API,特别是移动终端的GLES2.0/3.0这种和D3D9平级的图形API,国内大部分游戏程序员应该都是非常了解的,这里就不多做描述了,具体到后面案例里再针对性的讨论,而最近讨论比较火的“NGAPI(Next-Generation Graphics API)”,由于技术本身还不够成熟,再加上移动终端硬件设备,操作系统版本的限制,要普及可能还需要几年的时间,这里只列出SIGGRAPH2015上的相关链接,有兴趣的可以浏览下:
http://nextgenapis.realtimerendering.com/
比如Nvidia通过次世代图形API,把UE3开发的无主之地2移植到了他们的移动终端,NvidiaShield上。
 回过头来说现在的情况,下图是Unity中显示的渲染状态,只有一些简单的Draw Call数量,CPU和GPU的执行时间(ms),这并不足以作为API Call的性能参考
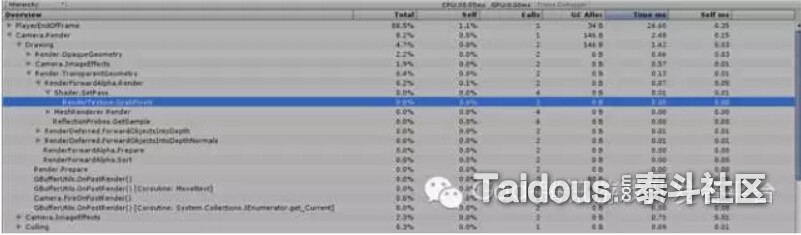
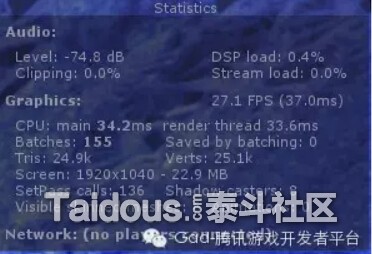 下图是Unity的Profiler,主要也是Unity的API的调用,并看不到实际3D API CALL
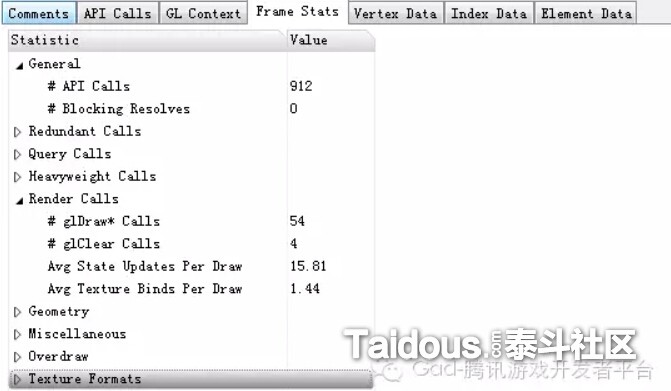
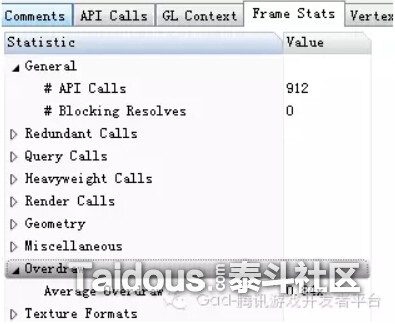
 然后,这里我用高通的Adreno Profile随便截取了应用宝上下载的一款游戏的一帧,针对Adreno Profiler里的一些参数做一些简单介绍:
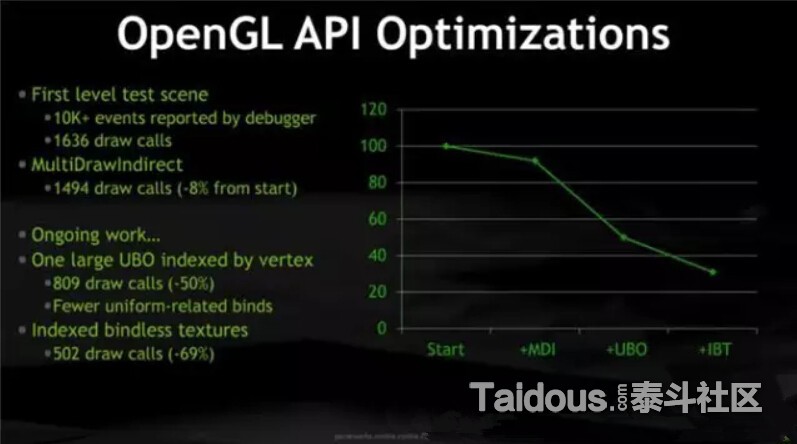
下图是当前帧的一个整体状态,可以看到Draw Call是54,API Call是912
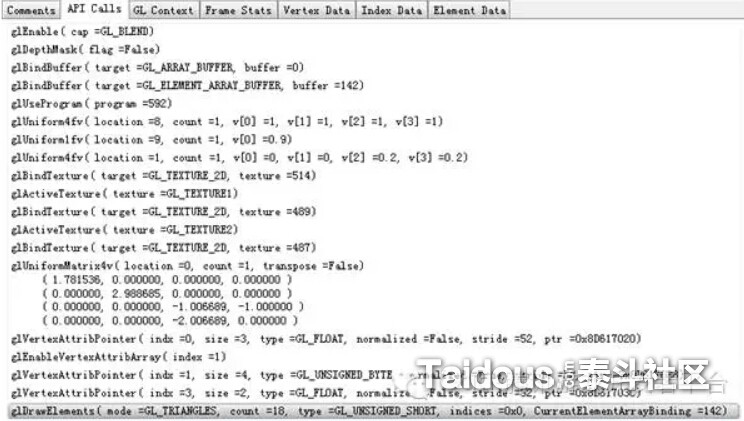
 这张图是具体某一个Draw Call内部的API调用细节,看可以看出,在调用glDrawElements绘制一个元素之前,我们要设置各种绘制状态,生成绑定顶点缓冲,选择使用的Shader Program,设置传入到Shader里的变量,绑定贴图等等完成后,才能把算完成一个Draw Call,所以,我们评估游戏的CPU上的绘制消耗时,并不能仅仅从DC的数量来判断,而是要从每个DC内部实际的API
Call来评估。
 Unity本身也实现一些比较标准的API Call的优化,比如Editor中的Static Batch,以及引擎内部的一些排序策略,状态对比等等,来减少API选择Shader,设置状态,生成绑定缓冲的调用次数。除此之外,如何节省API Call,还是要结合每个API具体消耗CPU的时间,对每个DC做进一步的优化和合并。这些也在后面结合具体的优化案例来做分享。
3)GPU 优化基础
和CPU优化的开头一样,这里再次列出Apple几款iOS设备的性能比较数据,其中的内存带宽(Bandwidth)
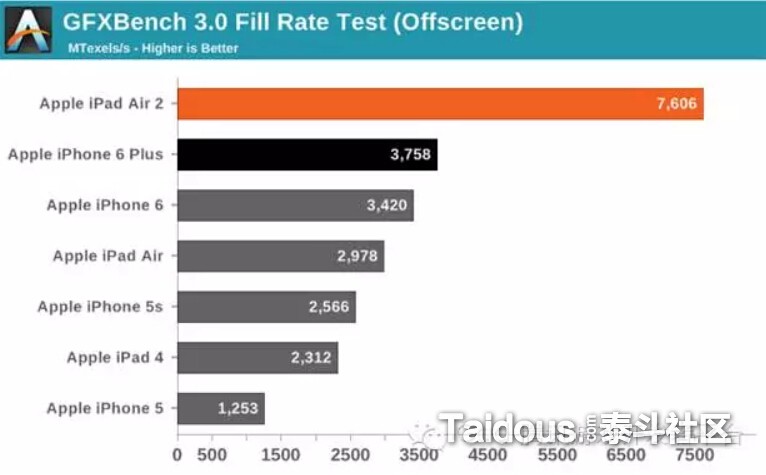
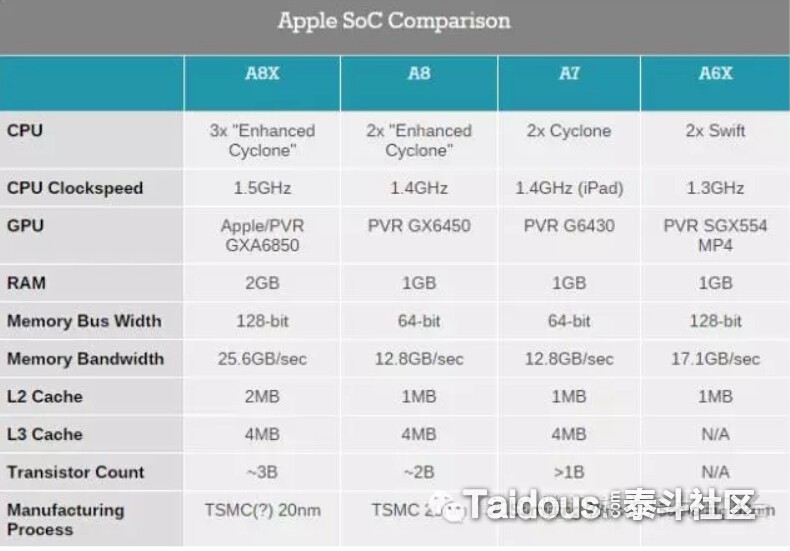 填充率(Fiil Rate)
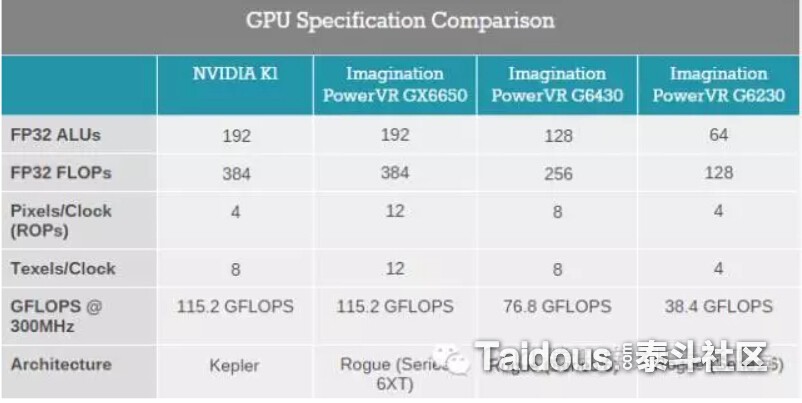
 然后是Shader的浮点计算力
 同样,这里也列出PC上一些主流GPU的参数
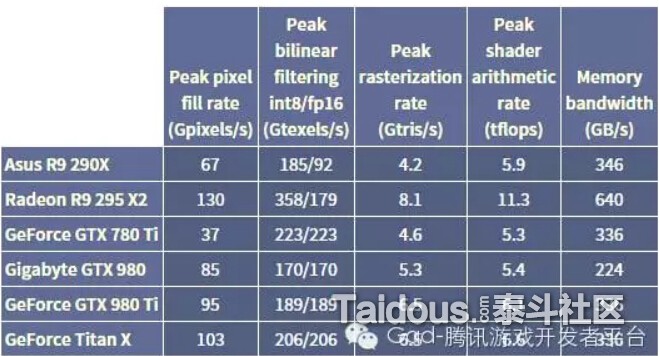 最后也可以确定内存带宽(Bandwidth),填充率(Fill Rate),浮点计算能力(FLOPS),就是GPU的主要性能点,也是我们要进行优化的目标。填充率和带宽方面的一些细节和计算方法,下面的链接里有详细的介绍,这里只简要介绍下
http://www.ping.be/~pin10741/fillbandw.htm
像素/纹素填充率(Fill Rate)
填充率可以理解为每秒像素绘制到屏幕上的数量,向FrameBuffer的输出也一样要占用填充率,单位一般是 MegaPixels/Second(百万像素/秒)或者GigaPixels/Second(十亿像素/秒)。比如ipad air2的填充率是7.6 GigaPixes。
填充率的计算公式可以简化为:
fill_rate = resolution * depth_complexity * frame_rate
resolution 就是设备的屏幕分辨率,像移动终端的2K屏幕的分辨率就是2560*1440
depth_complexity 深度复杂度,就是在一帧里对像素的绘制次数,比如我们从后向前绘制场景,画了物体对象A后,然后B绘制并覆盖掉A的一部分,那么被覆盖的这部分像素的深度复杂度就是2,而被深度检测剔除的部分则不会增加深度复杂度。
frame_rate,帧率,也是我们常说的FPS
那么,对是1024x768分辨率,深度复杂度为3,帧率为60fs的应用来讲,它的填充率就是:
(1024 x 768) * 3 * 60 = 141.6 Mpixel/sec
在Unity和一些分析工具中也提供了的OverDraw的预览和平均值:
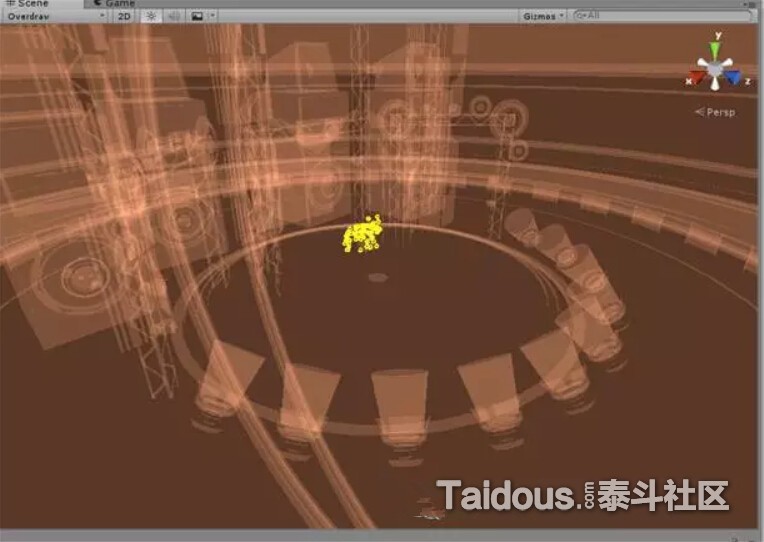  内存带宽(Bandwidth)
内存带宽的使用范围就更广泛一些了,比如Framebuffer的读写,Shader中根据不同采样设置读取Texture,以及ZBuffer的读写。它的单位是GB/sec(千兆字节/秒)。
不同操作使用的内存带宽的计算公式可以简化为:
Frame_buffer_bandwidth = resolution * depth_complexity * Frame Buffer Color Depth *frame_rate * z-buffer_pass_rate
Texture_memory_bandwidth = resolution * depth_complexity * 2.5 * Texel Color Depth *frame_rate
Z_buffer_bandwidth = resolution * depth_complexity * frame_rate * 1.5 * z_buffer_size
大部分参数和在计算填充率时是一样的,Color Depth是指Texture和FameBffer的格式,比如32bit的RGBA就是4(字节),z-buffer_pass_rate是值当前绘制有多少像素可见,其他的就被Zbuffer Test Pass掉,不会占用内存带宽了。
那么假设分辨率是1024x768,60帧,深度复杂度还是3,50%被z-buffer test pass掉,那么Framebuffer的带宽使用是:
Frame_buffer_bandwidth = (1024 * 768) * 3 * 4 * 60 * 0.5 = 0.28 GB/sec。
Texture的带宽使用要复杂一些,一个像素上,不同采样方式的需要的Texel数量不同,不同情况,Texture的Cache Hit的命中也不同,这里假设像素中只会从内存fetch 2.5个texel,其他环境还是一样,那么Texture的总的内存带宽使用是:
Texture_memory_bandwidth = (1024 * 768) * 3 * 2.5 * 4 * 60 = 0.47 GB/sec。
Zbuffer,我们还是假设有50%被pass掉,那么平均读写次数就是1.5:
Z_buffer_bandwidth = 849,346,560 or 0.85 GB/sec
最后,总的内存带宽使用是
Total_memory_bandwidth = Frame_buffer_bandwidth + Texture_memory_bandwidth +Z_buffer_bandwidth = 0.28 + 1.42 + 0.85 = 2.55 GB/sec
Shader的每秒浮点计算力
单位一般是GFLOPS(每秒10亿次浮点计算),相对来说,只要不在Pixel Shader里写循环或者是大量分支判断,一般不会有问题。细节也放到具体优化里吧。
总结
由于时间仓促,很抱歉还是没能把本篇的全部内容在1周内做好,而且上半部分名没有太多Unity内容,有点对应不上标题了,但如果做图形优化,我想上面所列的CPU和GPU知识应该够用了,虽然还是一些比较肤浅和基础的问题。之后的Unity的各种分析和优化方案,就是要把具体的表现,转化成对应不同CPU或GPU上消耗的成本,再进行有目的修改。将来再后面的优化分析案例中,我也还会引用到上半节的基础点,所以这部分不看其实也没有太大影响。对于一些对优化有兴趣又没有太入门的朋友,希望能提供能帮助和参考,同时也希望大神们能多提宝贵意见。在接下来的性能分析和瓶颈判断部分能准备多一些的Test
Case,尽快完成下篇再做分享。
|

 浙公网安备 33010602011771号
浙公网安备 33010602011771号