CPU的缓存L1、L2、L3与缓存行填充
https://juejin.im/post/6844904071166427143
L1,L2,L3 指的都是CPU的缓存,他们比内存快,但是很昂贵,所以用作缓存,CPU查找数据的时候首先在L1,然后看L2,如果还没有,就到内存查找一些服务器还有L3 Cache,目的也是提高速度。
高速缓冲存储器Cache是位于CPU与内存之间的临时存储器,它的容量比内存小但交换速度快。在Cache中的数据是内存中的一小部分,但这一小部分是短时间内CPU即将访问的,当CPU调用大量数据时,就可避开内存直接从Cache中调用,从而加快读取速度。由此可见,在CPU中加入Cache是一种高效的解决方案,这样整个内存储器(Cache+内存)就变成了既有Cache的高速度,又有内存的大容量的存储系统了。Cache对CPU的性能影响很大,主要是因为CPU的数据交换顺序和CPU与Cache间的带宽引起的。

高速缓存的工作原理
1. 读取顺序
CPU要读取一个数据时,首先从Cache中查找,如果找到就立即读取并送给CPU处理;如果没有找到,就用相对慢的速度从内存中读取并送给CPU处理,同时把这个数据所在的数据块调入Cache中,可以使得以后对整块数据的读取都从Cache中进行,不必再调用内存。
正是这样的读取机制使CPU读取Cache的命中率非常高(大多数CPU可达90%左右),也就是说CPU下一次要读取的数据90%都在Cache中,只有大约10%需要从内存读取。这大大节省了CPU直接读取内存的时间,也使CPU读取数据时基本无需等待。总的来说,CPU读取数据的顺序是先Cache后内存。
2. 缓存分类
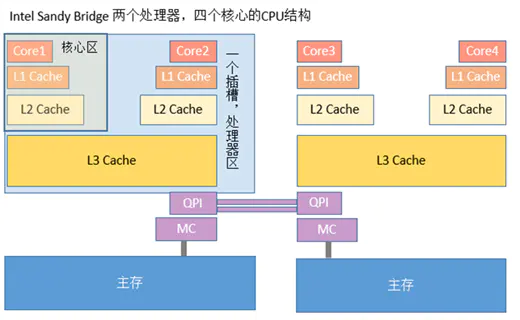
前面是把Cache作为一个整体来考虑的,现在要分类分析了。Intel从Pentium开始将Cache分开,通常分为一级高速缓存L1和二级高速缓存L2。
在以往的观念中,L1 Cache是集成在CPU中的,被称为片内Cache。在L1中还分数据Cache(I-Cache)和指令Cache(D-Cache)。它们分别用来存放数据和执行这些数据的指令,而且两个Cache可以同时被CPU访问,减少了争用Cache所造成的冲突,提高了处理器效能。
在P4处理器中使用了一种先进的一级指令Cache——动态跟踪缓存。它直接和执行单元及动态跟踪引擎相连,通过动态跟踪引擎可以很快地找到所执行的指令,并且将指令的顺序存储在追踪缓存里,这样就减少了主执行循环的解码周期,提高了处理器的运算效率。
以前的L2 Cache没集成在CPU中,而在主板上或与CPU集成在同一块电路板上,因此也被称为片外Cache。但从PⅢ开始,由于工艺的提高L2 Cache被集成在CPU内核中,以相同于主频的速度工作,结束了L2 Cache与CPU大差距分频的历史,使L2 Cache与L1 Cache在性能上平等,得到更高的传输速度。L2Cache只存储数据,因此不分数据Cache和指令Cache。在CPU核心不变化的情况下,增加L2 Cache的容量能使性能提升,同一核心的CPU高低端之分往往也是在L2 Cache上做手脚,可见L2 Cache的重要性。现在CPU的L1 Cache与L2 Cache惟一区别在于读取顺序。
3. 读取命中率
CPU在Cache中找到有用的数据被称为命中,当Cache中没有CPU所需的数据时(这时称为未命中),CPU才访问内存。从理论上讲,在一颗拥有2级Cache的CPU中,读取L1 Cache的命中率为80%。也就是说CPU从L1 Cache中找到的有用数据占数据总量的80%,剩下的20%从L2 Cache读取。由于不能准确预测将要执行的数据,读取L2的命中率也在80%左右(从L2读到有用的数据占总数据的16%)。那么还有的数据就不得不从内存调用,但这已经是一个相当小的比例了。在一些高端领域的CPU(像Intel的Itanium)中,我们常听到L3 Cache,它是为读取L2 Cache后未命中的数据设计的—种Cache,在拥有L3 Cache的CPU中,只有约5%的数据需要从内存中调用,这进一步提高了CPU的效率。
为了保证CPU访问时有较高的命中率,Cache中的内容应该按一定的算法替换。一种较常用的算法是“最近最少使用算法”(LRU算法),它是将最近一段时间内最少被访问过的行淘汰出局。因此需要为每行设置一个计数器,LRU算法是把命中行的计数器清零,其他各行计数器加1。当需要替换时淘汰行计数器计数值最大的数据行出局。这是一种高效、科学的算法,其计数器清零过程可以把一些频繁调用后再不需要的数据淘汰出Cache,提高Cache的利用率。
缓存行填充
CPU访问内存时,并不是逐个字节访问,而是以字长为单位访问。比如32位的CPU,字长为4字节,那么CPU访问内存的单位也是4字节。
这么设计的目的,是减少CPU访问内存的次数,加大CPU访问内存的吞吐量。比如同样读取8个字节的数据,一次读取4个字节那么只需要读取2次。
我们来看看,编写程序时,变量在内存中是否按内存对齐的差异。有2个变量word1、word2:
图如下:
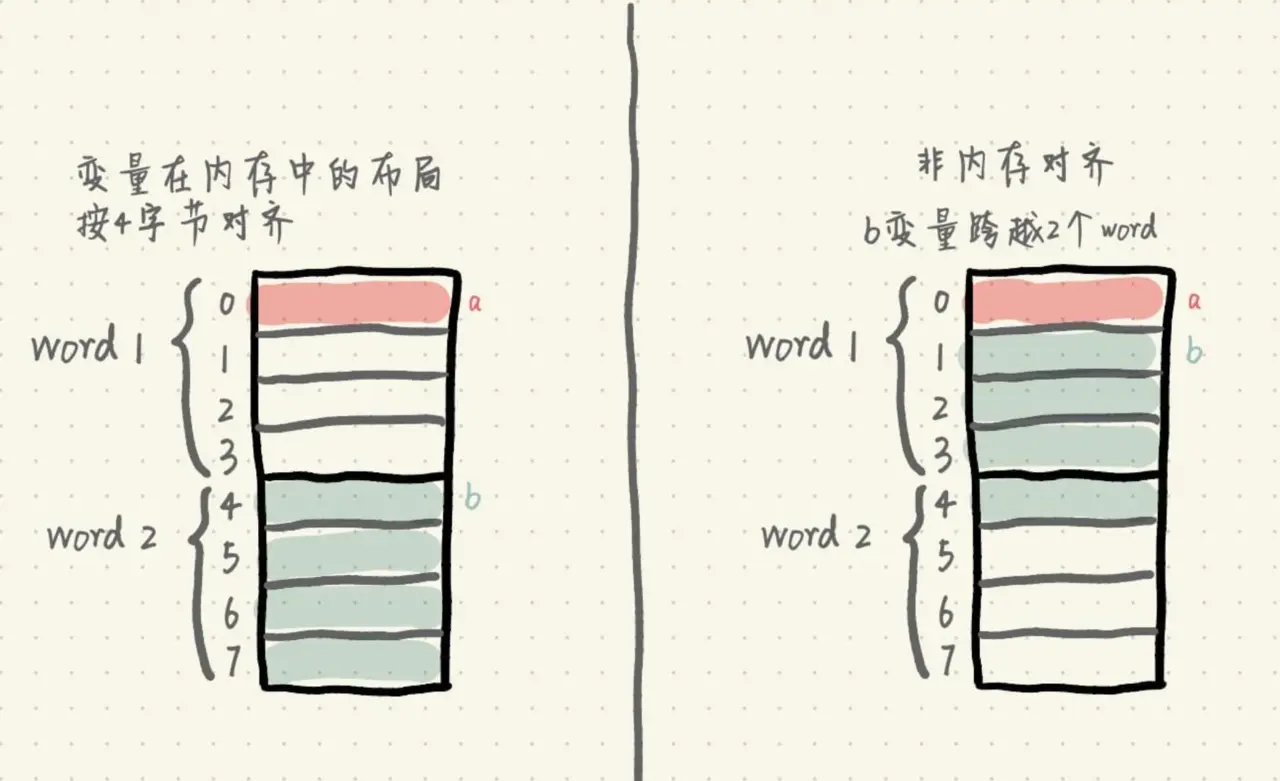
我们假设CPU以4字节为单位读取内存。如果变量在内存中的布局按4字节对齐,那么读取a变量只需要读取一次内存,即word1;读取b变量也只需要读取一次内存,即word2。
而如果变量不做内存对齐,那么读取a变量也只需要读取一次内存,即word1;但是读取b变量时,由于b变量跨越了2个word,所以需要读取两次内存,分别读取word1和word2的值,然后将word1偏移取后3个字节,word2偏移取前1个字节,最后将它们做或操作,拼接得到b变量的值。
显然,内存对齐在某些情况下可以减少读取内存的次数以及一些运算,性能更高。
另外,由于内存对齐保证了读取b变量是单次操作,在多核环境下,原子性更容易保证。
但是内存对齐提升性能的同时,也需要付出相应的代价。由于变量与变量之间增加了填充,并没有存储真实有效的数据,所以占用的内存会更大。这也是一个典型的空间换时间的应用场景。
参考文章
作者:简栈文化
链接:https://juejin.im/post/6844904071166427143
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号