

impala
一、impala基本介绍? 所有的计算都是基于内存来的,官方推荐每台服务器的内存最少128G起
impala是cloudera提供的一款高效率的sql查询工具,提供实时的查询效果,官方测试性能比hive块3到10倍,其sql查询比sparkSQL还要快,号称是当前大数据领域最快的查询sql工具。
impala是参照谷歌的新三篇论文(Caffeine、Pregel、Dremel)当中的Dremel实现而来,其中旧三篇论文分别是(BigTable,GFS,MapReduce)分别对应我们即将学的HBase和已经学过的HDFS以及MapReduce
impala是基于hive并使用内存进行计算,兼顾数据仓库,具有实时,批处理,多并发等优点。
二、impala与hive的关系?
impala是基于hive的大数据分析查询引擎,直接使用hive的元数据库metadata,意味着impala元数据都存储在hive的metadata当中,并且impala兼容hive的绝大多数sql语法。所以需要安装impala的话,必须先安装hive,保证hive安装成功,并且还需要启动hive的metastore服务。
impala支持95%以上的所有的hive的语法,可以无缝的兼容hive的绝大多数的语法
基本上所有的hive的任务都可以无缝迁移到impala上面来
三、impala的优点和缺点?
优点:
1、impala比较快,非常快,特别快,因为所有的计算都可以放入内存当中进行完成,只要你内存足够大。
2、摈弃了MR的计算,改用C++来实现,有针对性的硬件优化。
3、具有数据仓库的特性,对hive的原有数据做数据分析。
4、支持ODBC、JDBC远程访问。
缺点:
1、基于内存计算,对内存依赖性较大。
2、改用C++编写,意味着维护难度增大。
3、基于hive、与hive共存亡、紧耦合。
4、稳定性不如hive,不存在数据丢失的情况。
四、impala的架构以及查询计划?
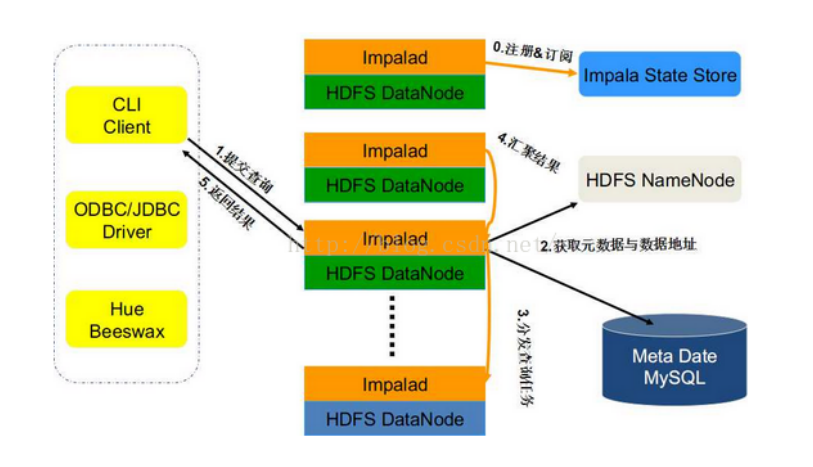
待续................

