

Hive数据仓库
一、数据仓库的概念:
数据仓库,英文名称为Data Warehouse,可简写为DW或DWH。数据仓库的目的是构建面向分析的集成化数据环境,为企业提供决策支持(Decision Support)。它出于分析性报告和决策支持目的而创建。
数据仓库本身并不“生产”任何数据,同时自身也不需要“消费”任何的数据,数据来源于外部,并且开放给外部应用,这也是为什么叫“仓库”,而不叫“工厂”的原因。
二、数据仓库的主要特征:
数据仓库是面向主题的(Subject-Oriented )、集成的(Integrated)、非易失的(Non-Volatile)和时变(一般不会轻易改变)的(Time-Variant )数据集合,用以支持管理决策。
三、数据仓库和数据库的区别:
数据库与数据仓库的区别实际讲的是 OLTP 与 OLAP 的区别。
操作型处理,叫联机事务处理 OLTP(On-Line Transaction Processing,),也可以称面向交易的处理系统,它是针对具体业务在数据库联机的日常操作,通常对少数记录进行查询、修改。用户较为关心操作的响应时间、数据的安全性、完整性和并发支持的用户数等问题。传统的数据库系统作为数据管理的主要手段,主要用于操作型处理。
分析型处理,叫联机分析处理 OLAP(On-Line Analytical Processing)一般针对某些主题的历史数据进行分析,支持管理决策
首先要明白,数据仓库的出现,并不是要取代数据库。
1、数据库是面向事务的设计,数据仓库是面向主题设计的。
2、数据库一般存储业务数据,数据仓库存储的一般是历史数据。
3、数据库设计是尽量避免冗余,一般针对某一业务应用进行设计,比如一张简单的User表,记录用户名、密码等简单数据即可,符合业务应用,但是不符合分析。数据仓库在设计是有意引入冗余,依照分析需求,分析维度、分析指标进行设计。
4、 数据库是为捕获数据而设计,数据仓库是为分析数据而设计。
四、Hive的简介:
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
其本质是将SQL转换为MapReduce的任务进行运算,底层由HDFS来提供数据的存储,说白了hive可以理解为一个将SQL转换为MapReduce的任务的工具,甚至更进一步可以说hive就是一个MapReduce的客户端
五、hive的特点:
- 可扩展
Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。
- 延展性
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
- 容错
良好的容错性,节点出现问题SQL仍可完成执行。
六、hive架构:
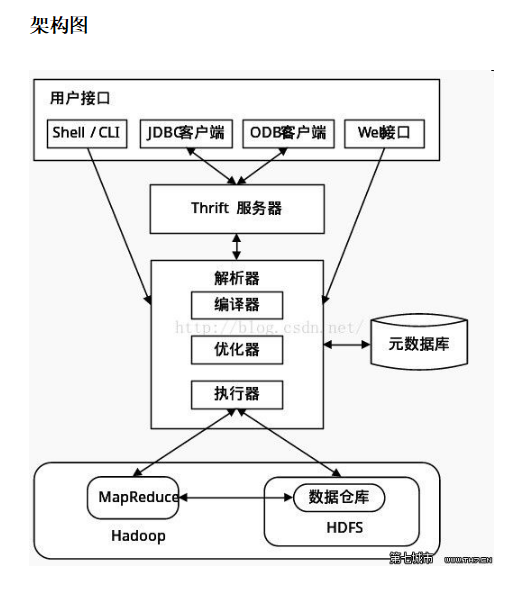
七、hive和hadoop的关系
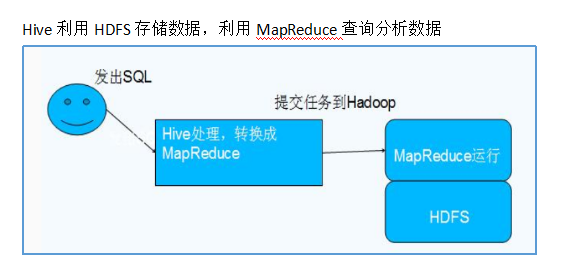
八、hive支持多种存储格式:
1.Text, SequenceFile,ParquetFile,ORC格式RCFILE等
2、只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
3、Hive 中包含以下数据模型:DB、Table,External Table,Partition,Bucket。
db:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
table:在hdfs中表现所属db目录下一个文件夹
external table:与table类似,不过其数据存放位置可以在任意指定路径
partition:在hdfs中表现为table目录下的子目录
bucket:在hdfs中表现为同一个表目录下根据hash散列之后的多个文件
九、hive内嵌derby元数据库,一般不使用。因为如果要使用derby作为hive的元数据库,hive在哪个路径下面起就会在哪个路径下创建元数据库。导致元数据信息不共享。
十、使用mysql用来管理我们的元数据
mysql的安装:(使用yum源进行安装,强烈推荐)
第一步:在线安装mysql相关的软件包
yum install mysql mysql-server mysql-devel
第二步:启动mysql的服务
/etc/init.d/mysqld start
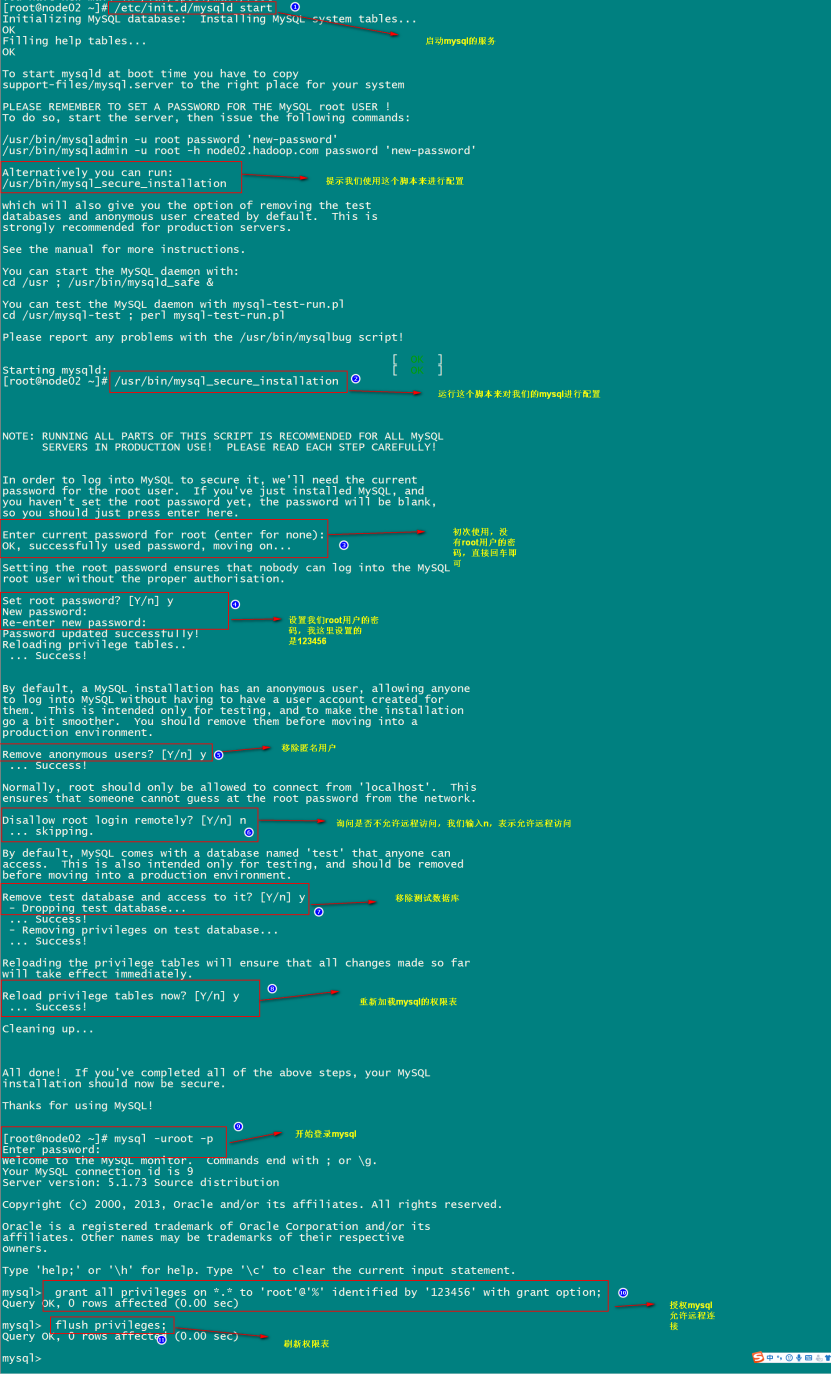
第三步:通过mysql安装自带脚本进行设置
/usr/bin/mysql_secure_installation
第四步:进入mysql的客户端然后进行授权
grant all privileges on *.* to 'root'@'%' identified by '123456' with grant option;
flush privileges;
十一、安装好mysql库之后hive还不会用我们安装的mysql,需要对hive的配置文件进行配置
1、mv hive-env.sh.template hive-env.sh
修改hive-env.sh
添加我们的hadoop的环境变量
cd /export/servers/hive-1.1.0-cdh5.14.0/conf
cp hive-env.sh.template hive-env.sh
vim hive-env.sh

2、修改hive-site.xml(这个文件默认是没有的需要自己创建)
cd /export/servers/hive-1.1.0-cdh5.14.0/conf
vim hive-site.xml
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>#表示我们连接的哪个数据库作为我们的 源数据库
<value>jdbc:mysql://node03.hadoop.com:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node03.hadoop.com</value>
</property>
<!--
<property>
<name>hive.metastore.uris</name>
<value>thrift://node03.hadoop.com:9083</value>
</property>
-->
</configuration>
十二、上传mysql的lib驱动包
将mysql的lib驱动包上传到hive的lib目录下
cd /export/servers/hive-1.1.0-cdh5.14.0/lib
十三、hive的使用待补充:

