
基于R树索引的点面关系判断以及效率优化统计
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/
1.背景
在之前的博客中,我分别介绍了基于网格的空间索引(http://www.cnblogs.com/naaoveGIS/p/5148185.html)以及四叉树和网格结合的联合索引(http://www.cnblogs.com/naaoveGIS/p/6641449.html),要解决的问题均是判断一个点落在了面图层中的哪个面要素中。单从算法层面上分析,以上两种索引均有一些弊端:
a.网格索引由于对整个空间进行网格划分,如果划分粒度太细容易出现索引冗余,如果划分粒度太大则索引效率又大幅度下降。
b.四叉树索引同样存在一个图元标识被多个区域所关联,相应地存储在多个叶子节点上,这样就存在索引的冗余,与网格索引存在同样的弊端。
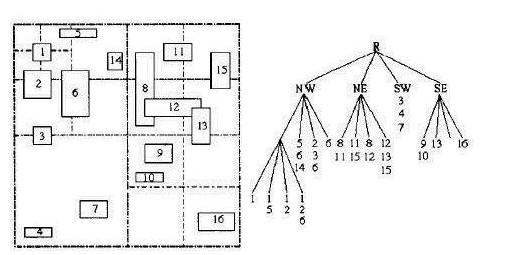
为进一步优化索引,我们决定采用R树来进行优化。
2.R树介绍
R树主要运用空间分割的理念,即采用MBR(Minimal Bounding Rectangle,最小边界矩形)的方法,从叶子结点开始用矩形(rectangle)将空间框起来,结点越往上,框住的空间就越大,以此对空间进行分割:
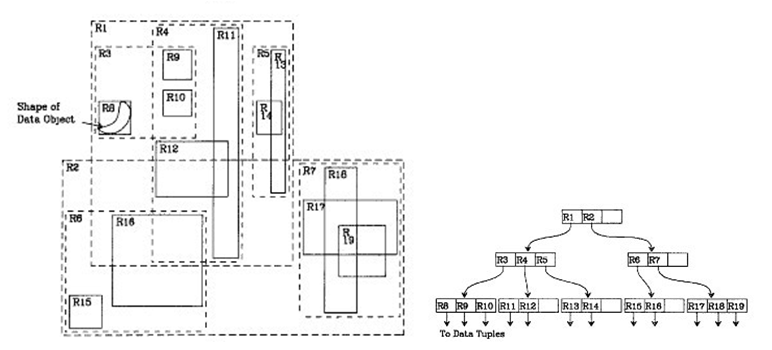
所有的原始空间要素均是叶节点,这样便不会出现如四叉树索引和网格索引中出现的空间要素被多个索引段指引,进而出现大量冗余索引的问题。
3.基于JTS的具体实现
JTS中提供了构建索引的方法,其可以构建四叉树索引、R树索引、KD索引等。这里,我们直接使用JTS来构建R树索引。
JTS的介绍:https://en.wikipedia.org/wiki/JTS_Topology_Suite
JTS的源码下载:https://sourceforge.net/projects/jts-topo-suite/?source=navbar
3.1R树的构建
利用GT读取到本地的SHP,获取到所有的要素集,然后遍历要素将envelope和要素信息一一插入至StrTree中,构建R树:

3.2基于R树的查询
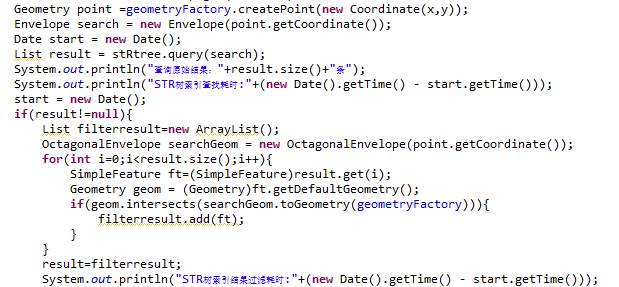
将查询的空间条件构造成一个Envelope在R树中查询,对查询出来的结果再次进行点面关系判断:
4.优化
在我们之前的两种索引方法中,我们均将索引文件保存到了本地,每次调用时去加载索引,如此IO是一个很大的瓶颈。现在我们创建一个容器,将StrTree保存至该容器中。查询时,直接从内存中获取到该树。
5.效率对比
5.1查询效率对比
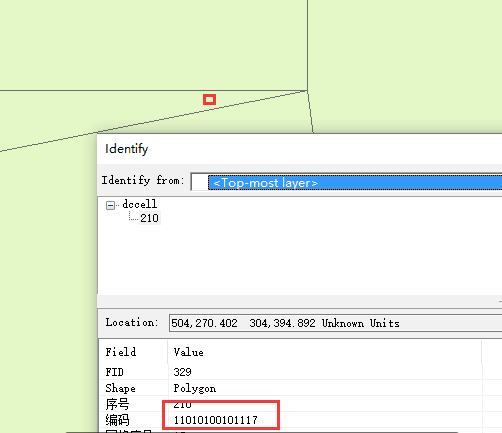
在测试数据中选中一个特殊点(多个多边形的交接处):
分别对使用的三种索引进行了性能对比:
a.本地网格索引:
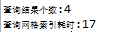
b.本地混合索引(四叉树与网格索引整合):
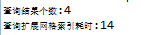
c.内存R树索引:
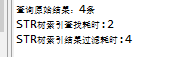
可见查询效率快了一倍左右。
5.2索引构建效率对比
样本数据有2000多个面要素,之前的两种索引均使用本地工具构建,时间大约是1S上下(没有具体统计)。现在使用JTS构建R树索引,效率为:

5.3占用的内存效率
此索引的优化中,我们将数据全部存入了内存。这里必须观察内存的占用量有多大。
一般监控内存有两种方式,通过工具查看或者代码段编写。代码段编写可以通过应用SizeOf.jar实现,工具查看可以通过jvisualvm实现:
原始的本地SHP数据大小为:3.8M。
网格索引大小为:4.4M。
混合索引文件的大小为:8.4M。
而读入内存中的R树索引的大小为:4.3M。
由于我们存储了要素所包含的所有信息,理论上,如果我们将存储信息进一步减少,内存占用会更小。目前来看,SHP数据本身的大小,会跟存入内存的信息大小有直接关系。
6.总结
目前索引方式任然有几点不足:
a.索引构建中的要素获取方式为本地SHP读取,需要扩展成对第三方服务数据的支持。
b.当R数查询命中只有一个要素时,因为最小矩形的范围是大于等于实际要素范围的,所以还要进行一次点面判断。如此,当图层要素个数本身不多时,建立索引不一定可以加速。
-----欢迎转载,但保留版权,请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/
如果您觉得本文确实帮助了您,可以微信扫一扫,进行小额的打赏和鼓励,谢谢 ^_^

