

基于DFA敏感词查询的算法简析
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/
1.背景
项目中需要对敏感词做一个过滤,首先有几个方案可以选择:
a.直接将敏感词组织成String后,利用indexOf方法来查询。
b.传统的敏感词入库后SQL查询。
c.利用Lucene建立分词索引来查询。
d.利用DFA算法来进行。
首先,项目收集到的敏感词有几千条,使用a方案肯定不行。其次,为了方便以后的扩展性尽量减少对数据库的依赖,所以放弃b方案。然后Lucene本身作为本地索引,敏感词增加后需要触发更新索引,并且这里本着轻量原则不想引入更多的库,所以放弃c方案。于是我们选定d方案为研究目标。
2.DFA算法简介
DFA全称为:Deterministic Finite Automaton,即确定有穷自动机。其特征为:有一个有限状态集合和一些从一个状态通向另一个状态的边,每条边上标记有一个符号,其中一个状态是初态,某些状态是终态。但不同于不确定的有限自动机,DFA中不会有从同一状态出发的两条边标志有相同的符号。
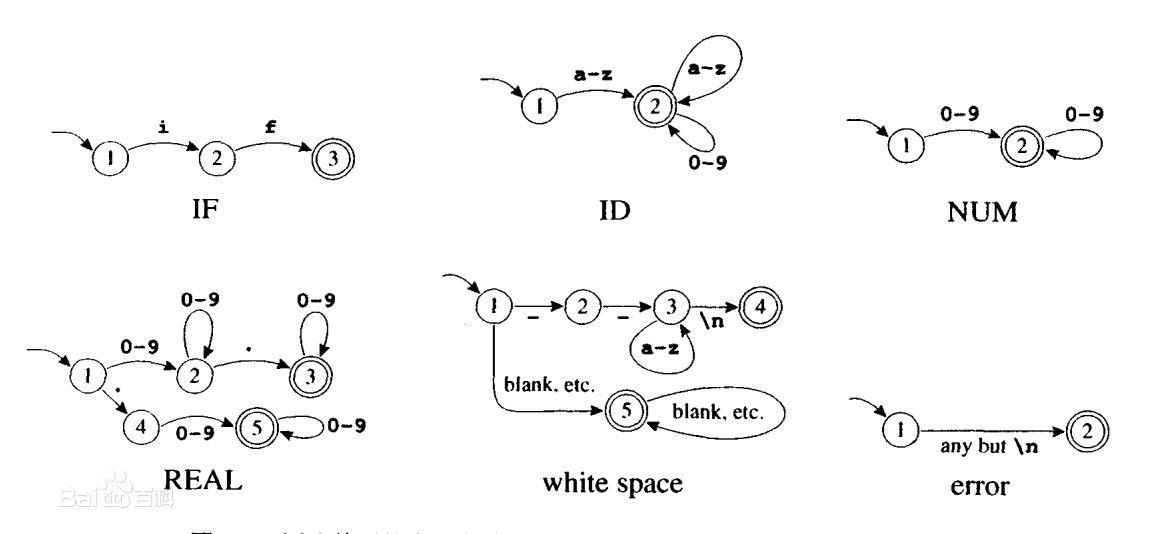
简单点说就是,它是是通过event和当前的state得到下一个state,即event+state=nextstate。理解为系统中有多个节点,通过传递进入的event,来确定走哪个路由至另一个节点,而节点是有限的。
3.敏感词搜寻中的DFA算法
3.1敏感词库构造描述
以王八蛋和王八羔子两个敏感词来进行描述,首先构建敏感词库,该词库名称为SensitiveMap,这两个词的二叉树构造为:
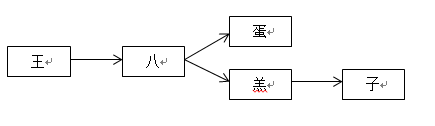
用hash表构造为:

3.2基于敏感词库收索算法的描述
以上面例子构造出来的SensitiveMap为敏感词库进行示意,假设这里输入的关键字为:王八不好,流程图如下:
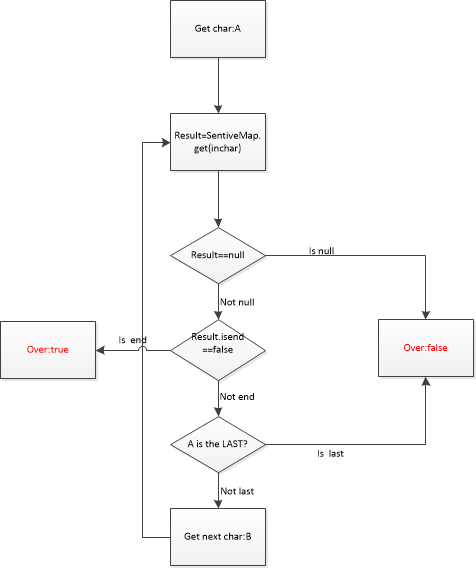
4.代码编写
4.1构造敏感词实现代码

4.2实现敏感词查询代码

5.优化思路
5.1敏感词中间填充无意义字符问题
对于“王*八&&蛋”这样的词,中间填充了无意义的字符来混淆,在我们做敏感词搜索时,同样应该做一个无意义词的过滤,当循环到这类无意义的字符时进行跳过,避免干扰。
5.2敏感词用拼音或部分用拼音代替
两种解决思路:一种是最简单是遇到这类问题,先丰富敏感词库进行快速解决。第二种是判断时将敏感词转换为拼音进行对比判断。
不过目前这两种方案均不能彻底很好的解决该问题,此类问题还需进一步研究。
-----欢迎转载,但保留版权,请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/
如果您觉得本文确实帮助了您,可以微信扫一扫,进行小额的打赏和鼓励,谢谢 ^_^



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
· 上周热点回顾(2.24-3.2)