
武Sir博客拿的面试题,答案都是自己写的,多有不足,请多多指教。更新中。。。。。。
1.为什么学习Python?
a.写起来快,看起来明白。作为通用性的语言,除了一些对性能要求很高的场合,几乎什么都能干,常见领域:web服务器、计算科学、程序脚本、系统管理
2.通过什么途径学Python?
看各种教学视频,看博客。
3.Python和Java、PHP、C、C#、C++等其他语言的对比?
Python是一门面向对象的解释性语言,Python通过缩进来确定作用域,Python代码简洁易读。 Python拥有很多功能强大的模块可供使用。但是Python相比较于其他语言,运行效率低,不适合对运行效率要求搞的程序。
4.简述解释型和编译型编程语言?
计算机不能直接的理解高级语言,只能直接理解机器语言,所以必须要把高级语言翻译成机器语言,计算机才能执行高级语言的编写的程序。翻译的方式有两种,一个是编译,一个是解释。两种方式只是翻译的时间不同。
解释性语言的程序不需要编译,解释性语言在程序运行的时候才需要翻译,可移植性好,只需要有解释环境,可在不同平台运行。缺点就是必须要有解释环境才能运行,需要占用更多的资源,代码效率低,解释器本身也需要占用资源,程序严重依赖于平台。
编译型就是直接把程序编译成机器可以执行的文件,编译和执行是分开的,但不能跨平台,编译型语言的程序执行效率高,编译后程序不可修改,保密性好。缺点代码需要经过编译方可运行,可移植性差,只能在兼容的操作系统上运行。
5.Python解释器种类以及特点?
CPython
使用C语言开发,使用最广泛的解释器。
IPython
基于CPython上的一个交互式解释器,IPython在交互方式上有所增强,但执行Python代码的功能和CPython是完全一样。
PyPy
PyPy采用JIT技术,对Python代码进行动态编译,可以显著提高Python代码的执行速度。
JPython
Jython是运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行。
IronPython
IronPython和Jython类似,只不过IronPython是运行在微软.Net平台上的Python解释器,可以直接把Python代码编译成.Net的字节码。
6.位和字节的关系?
8位(bit) = 1字节(Byte)
7.b、B、KB、MB、GB 的关系?
1024b(Byet) = 1KB
1024KB(Byet) = 1MB
1024MB(Byet) = 1GB
1024GB(Byet) = 1TB
8.请至少列举5个 PEP8 规范(越多越好)
a.不要在行尾加分好,也不要用分号将两条命令放在同一行。
b.每行不超过80个字符(长的导入模块语句和注释里的URL除外)
c.不要使用反斜杠连接行。Python会将圆括号,中括号和花括号中的行隐式连接。
d.用四个空格来缩进代码,不要用tab,也不要tab和空格混用。对于行连接的情况,你应该要么垂直对齐换行的元素,或者使用四空格的悬挂式缩进。
e.顶级定义之间空两行,方法定义之间空一行。如函数或者类的定义空两行,方法定义与第一个方法之间,空一行。
f.不要在冒号,逗号,分号前面加空格,但应该在他们后面加。
9.通过代码实现如下转换:(未写)
二进制转换成十进制:v = “0b1111011”
十进制转换成二进制:v = 18
八进制转换成十进制:v = “011”
十进制转换成八进制:v = 30
十六进制转换成十进制:v = “0x12”
十进制转换成十六进制:v = 87
10.请编写一个函数实现将IP地址转换成一个整数。(未写)
如 10.3.9.12 转换规则为:
10 00001010
3 00000011
9 00001001
12 00001100
再将以上二进制拼接起来计算十进制结果:00001010 00000011 00001001 00001100 = ?
11.python递归的最大层数?
Python解释器为了避免内存一出和性能影响设置了最大递归深度为998,当调用栈超过998层就会报错。
12.求结果:
v1 = 1 or 3
--------------->v1 = 1
v2 = 1 and 3
-------------->v2 = 3
v3 = 0 and 2 and 1 -------->v3 = 0
v4 = 0 and 2 or 1 --------->v4 = 1
v5 = 0 and 2 or 1 or 4 ---->v5 = 1
v6 = 0 or False and 1 ----->v6 = False
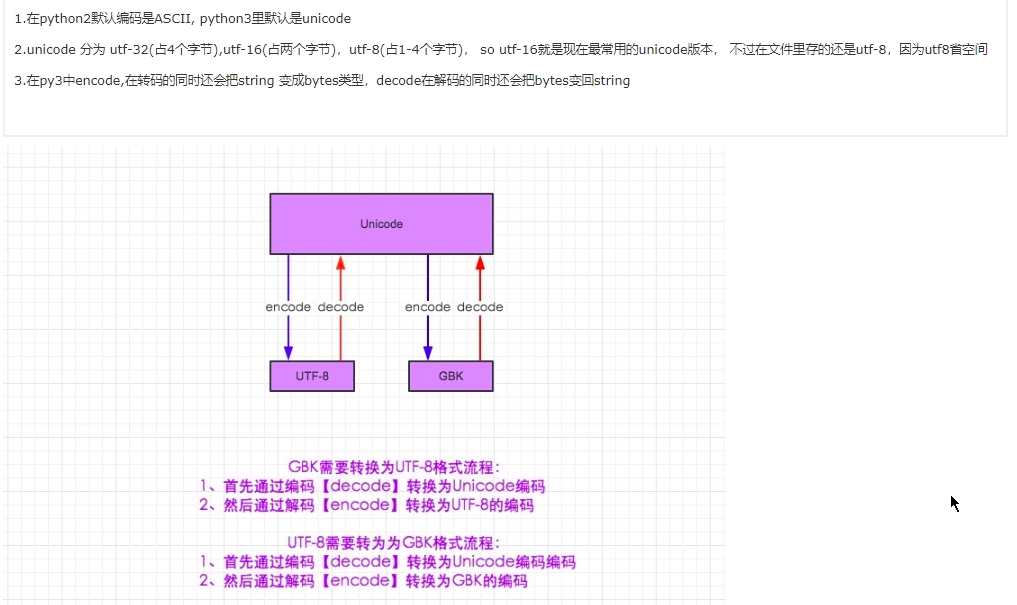
13.ascii、unicode、utf-8、gbk 区别?
ascii:
在计算机内部,所有信息最终都是一个二进制。每一个二进制位(bit),有0和1两种状态,因此,8个二进制位可以组合出256种状态,这被称为字节。上个世纪六十年代,美国定制了一套字符编码,对英文字符与二进制之间做了联系,这个被称为ASCII🐴,一直沿用至今。
ASCII🐴一共规定了128个字符,比如space是32,A是65,这128个符号只占用了一个字节的后面七位,最前面的一位规定为0。
GBK:
GBK编码是对GB2312的扩展,完全兼容GB2312。采用双字节编码方案,剔除xx7F码位共23940个码位,共收录汉字和图形符号21886个,GBK编码方案与1995年12月15日发布。它几乎完美支持汉字,因此经常会遇见GBK与UNICode的转换。
UNICode:
如上文所述,世界上有多种编码方法,同一个二进制数字可以被解释称不同的符号。因此,在打开一个文本文件时候,就必须知道它的编码方式,用错误的编码方式打开,就会出现乱码。假如,有一种编码,将世界上所有的符号都纳入其中,每一种符号都给予独一无二的编码,那么乱码问题就不会存在了。因此,产生了Unicode编码,这是一种所有符号的编码。
Unicode显然是一个巨大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如U+0041表示英语的大写字母A,U+4e25表示汉字严。
在Unicode庞大的字符集的优势下,还存在一个问题,比如一个汉字,“严”的Unicode是十六进制4e25,转成二进制足足有15位,也就是,这个符号需要2个字节,表示其他字符还存在3个字节或者更多。计算机怎么区别三个字节表示的是同一个符号而不是分开表示三个呢?如果Unicode统一规定,每个符号用3个字节表示,但是某些字母显然不需要3个,那么就浪费了空间,文本文件大小超出了很多,这显然是不合理的。直到UTF8字符编码出现了。
UTF-8:
随着互联网的发展,强烈要求出现一种统一的编码方式。UTF8就是在互联网中使用最多的对Unicode的实现方式。还有其他实现,比如UTF16(字符用2个字节或者4个字节表示),UTF32(字符用4个字节表示)。UTF8是Unicode的实现方式之一,也是最为常见的实现方式。UTF8的最大特点是,它是一种变长编码,可以使用1-4个字节表示一个符号,根据不同的符号来变化字节长度。UTF8编码规则只有两条:
1)对于单字节的符号,字节的第一位设为0,后面的7位为这个符号的Unicode码。因此,对于英文字母,UTF8编码和ASCII编码是相同的。
2)对于非单字节(假设字节长度为N)的符号,第一个字节的前N位都设为1,第N+1设为0,后面字节的前两位一律设为10,剩下的没有提及的二进制,全部为这个符号的Unicode码。
14.字节码和机器码的区别?
机器码:CPU能够直接解读的数据,也被称为原生码。
字节码:一种包含执行程序、由一序列操作代码/数据组成的二进制文件。它是一种中间代码,需要转译才能被CPU所解读。
15.三元运算规则以及应用场景?
例如:
h = "变量1" if a>b else "变量2"
三元运算也可用于生成列表和字典:
1-10的数字,打印出其中的偶数:
ss = [i for i in range(1,11) if i%2==0 ]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号