[转]limit查询慢的原因及优化方法
原文出处,删除与知识无关的作者个人经历和感想部分
叶不闻《写在教师节:分页场景(limit,offset)为什么会慢》
链接:https://juejin.im/post/5c4db295e51d4503834d9c43
逻辑算子部分引用了
叁金《SQL优化器执行过程之逻辑算子》
链接:http://www.imooc.com/article/278660
问题分析
select * from table where status = xx limit 10 offset 100000;
在分页场景下,即使有索引,limit请求也会非常慢,在数据量只有10万的情况下,单机大概2-3秒
索引
我们知道MySQL的索引是b+树。如果是一个二叉树,因为无法知道前100个数在树上的分布情况,所以无法利用二分查找的特性。在b+树中,可以通过叶子结点组成的链表,以O(n)的复杂度查找到第100大的数,但即使是O(n),也不至于这么慢,是否还有其他原因
(补充一点,如果查询条件中无limit,在已确定的数据页上就可以使用二分查找查找需要的值)

通过查阅资料得知,InnoDB的索引分为两种
- 聚簇索引:包含主键索引和对应的实际数据,索引的叶子节点就是数据节点,找到索引也就找到了数据
- 辅助索引:可以理解为二级节点,其叶子节点还是索引节点,包含了主键id,还需要查询一遍数据
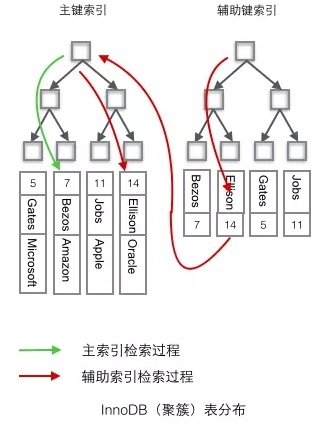
由于MySQL的分层的原因,即使前100000个会扔掉,MySQL也会通过二级索引上的主键id,去聚簇索引上查一遍数据,这可是100000次随机IO,自然慢成哈士奇
分层
了解这个之前需要先了解一个概念,逻辑算子。简单的介绍一下查询计划中的一些逻辑算子
- DataSource:数据源,也就是我们SQL语句中的表。
select name from table1中的table1 - Join:连接,如
select * from table1 table2 where table1.name = table2.name就是把两个表做Join。连接条件是最简单的等值连接,当然还有其他我们熟知的inner join,left join,right join等等 - Selection:选择,如
select name from table1 where id = 1中的where后的过滤条件 - Aggregation:分组,如
select sum(score) from table1 group by name中的group by。按照某些列进行分组,分组后可以进行一些聚合操作,比如Max、Min、Sum、Count、Average等等 - Projection:投影,指搜索的列,如
select name from table1 where id = 1中的列name - Sort:排序,如
select * from table1 order by id里面的order by。无序的数据通过这个算子处理后,输出有序的数据 - Apply:子查询,如
select * from (select id,name from table1) as t中的(select id,name from table1) as t。可以进行嵌套查询。
选择、投影、连接就是最基本的算子,其中 Join 有内连接,左外右外连接等多种连接方式
select b from t1, t2 where t1.c = t2.c and t1.a > 5
变成逻辑查询计划之后
- t1 t2 对应的 DataSource,负责将数据捞上来
- 上面接个 Join 算子,将两个表的结果按 t1.c = t2.c连接
- 再按 t1.a > 5 做一个 Selection 过滤
- 最后将 b 列投影
下图是未经优化的表示,所以说不是mysql不想把limit传递给引擎层,而是因为划分了逻辑算子,所以导致无法直到具体算子包含了多少符合条件的数据

ps:SELECT执行顺序
| 关键字书写顺序 | MySQL引擎顺序 | |
|---|---|---|
| 1 | select distinct | from |
| 2 | from | on |
| 3 | join | join |
| 4 | on | where |
| 5 | where | group by |
| 6 | group by | having+聚合函数 |
| 7 | having | select distinct |
| 8 | union | union |
| 9 | order by | order by |
| 10 | limit | limit |
解决方法
解决方法有2种
- 根据业务实际需求,看能否替换为下一页,上一页的功能,特别在移动端。把limit替换成
>id的方式。该id再调用时,需要返回给前端。但是这种有些业务场景不适用
select * from table where status = xx id > 100000 limit 10;
- 【推荐】嵌套子查询,先查找数据的主键值,因为主键在辅助索引上就有,所以不用回归到聚簇索引的磁盘去拉取。再通过这些已经被limit出来的10个主键id,去查询聚簇索引。这样只会十次随机IO。在业务确实需要用分页的情况下,使用该方案可以大幅度提高性能。通常能满足性能要求
select xxx from in (select id from table where status = xx limit 10 offset 100000);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号