字符串的提取与拼接应用
需求:从在线文件夹下载最新版本的文件
存在问题:该文件夹内存在历史版本,而且还有其它文件,增加了下载难度。
特点:文件顺序按照更新时间从上到下排序
实现思路:①将网页数据写入文本;②从文本中提取需要下载的文件版本号;③拼接成需要下载的文件,进行下载
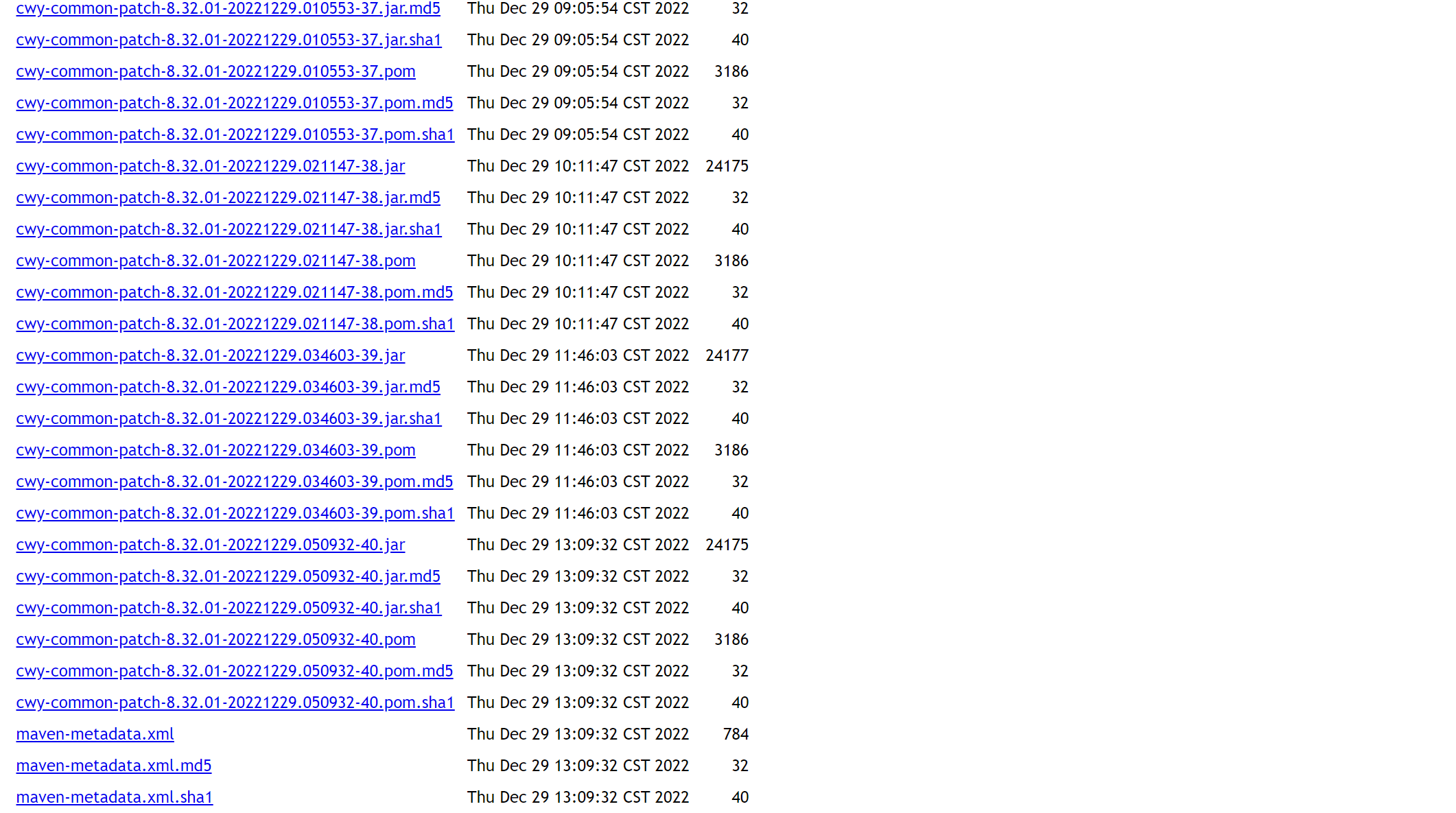
实现如下:
1. 将在线文件夹内数据写入html文件
curl http://maven.xxx -o common.html
2. 从common.html文件中提取最后一个带有“cwy-common-patch-8.32.01-”的最后一行记录
[root@cwcsb-gxcwy832-xnce-2 mm]# ps x|grep cwy-common-patch-8.32.01- common.html|awk '{print $2}'|sed -n '$p' href="http://maven.xxx/cwy-common-patch-8.32.01-20221229.050932-40.pom.sha1">cwy-common-patch-8.32.01-20221229.050932-40.pom.sha1</a></td>
3.通过切片方式,将目标取出
common_jar='href="http://maven.xxx/cwy-common-patch-8.32.01-20221229.050932-40.pom.sha1">cwy-common-patch-8.32.01-20221229.050932-40.pom.sha1</a></td>'
echo ${common_jar:6:61}
http://maven.xxx/cwy-common-patch-8.32.01-20221229.050932-40.
整体如下:
Jarfile_path="/opt/cwy8.32/product/module/A/CWY/patch" check() { if [ $? -eq 0 ];then echo "下载完成" else echo "下载失败请检查" fi } #下载网页数据 cd $Jarfile_path curl http://maven.xxx -o common.html -o common.html #提取数据 common_jar=`ps x|grep cwy-common-patch-8.32.01- common.html|awk '{print $2}'|sed -n '$p'` #下载文件 wget -c ${common_jar:6:61}jar -P $Jarfile_path check
本文来自博客园,作者:查拉图斯特拉面条,转载请注明原文链接:https://www.cnblogs.com/n00dle/p/17012780.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号