一路青春,感谢有你——『近取Key』 - Beta 项目展示
项目与团队亮点
一、团队成员与分工简介
成员组成与分工
本团队由 6 名成员组成,其中有 3 名 PM,2 名后端开发人员与 4 名前端开发人员,由于组内成员数量有限,因此所有 PM 均需同时兼领开发任务。
团队整体采用前后端分离的开发模式,双方主要基于 API 文档进行交互与协作;PM 则需要对项目整体进度、核心功能实现、开发流程规范等方面进行把控,确保项目能够有条不紊地顺利进行。
管理模式
由于今年课程组统一要求基于 Gitlab 进行敏捷开发,因此本项目在 beta 阶段继续沿用石墨文档 + GitLab issues 的方式进行共同管理。二者可以做到相辅相成,优劣互补,从而尽可能实现科学且富有人性化的管理模式。
在石墨文档上,团队会将下一阶段需要完成的各类任务进行统一的梳理,并将相应的结果记录到文档中,同时计算生成相应的、具有特色的燃尽图。具体特色分析请见第二部分:项目与团队总结。
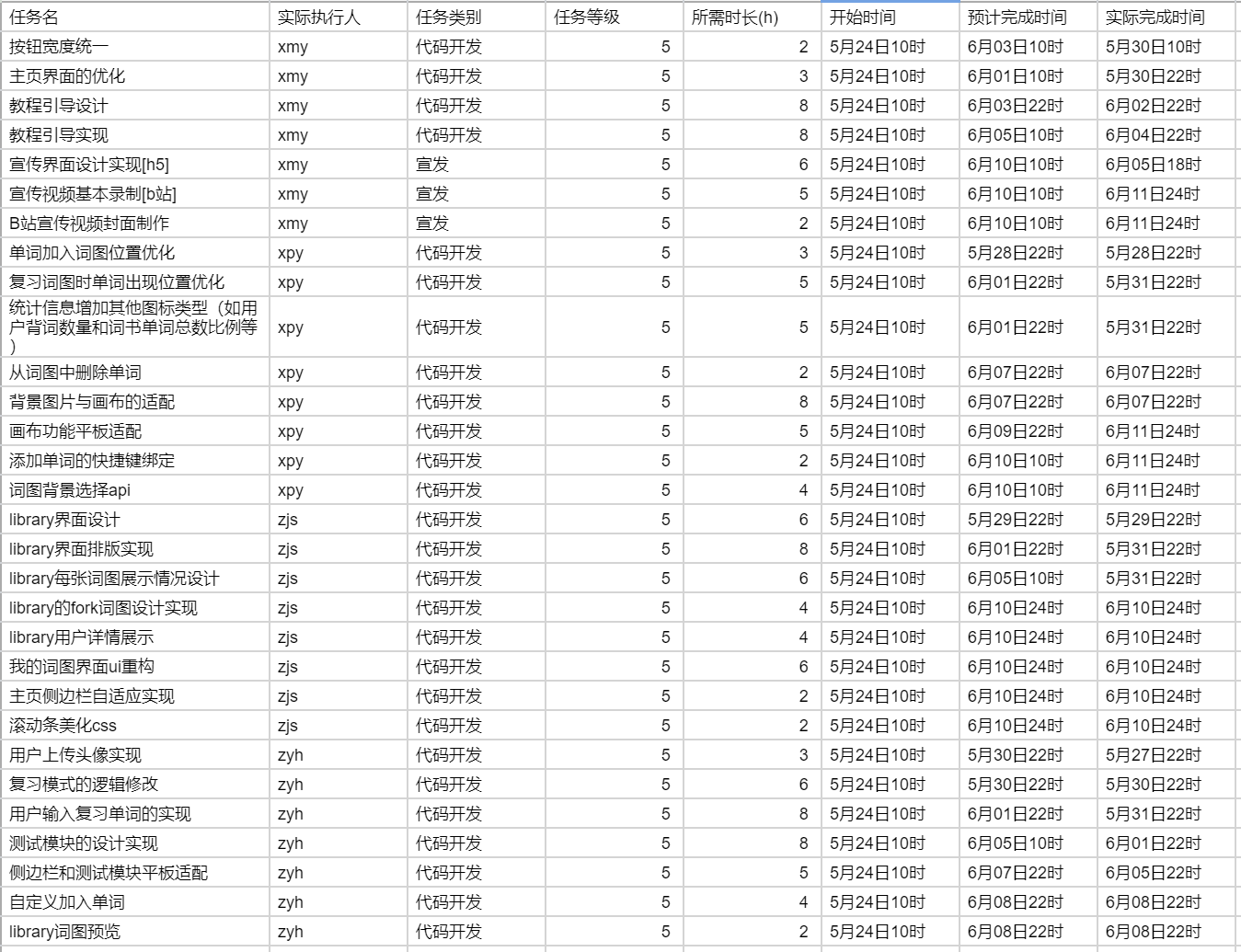 |
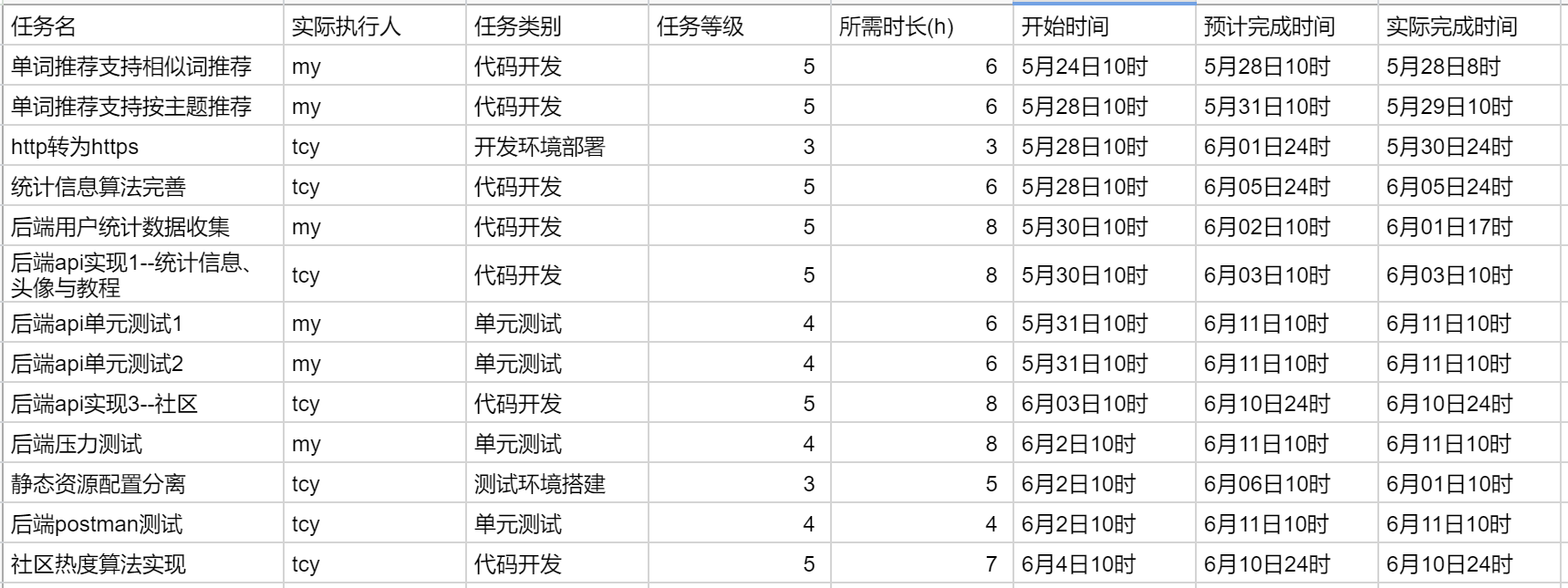 |
在 GitLab 上,团队会基于石墨文档中的任务内容,将其中与代码编写相关的任务以 issue 的形式予以发布,便于团队成员在开发过程中进行及时查看。在开发的不同阶段,团队也设置了相应的 milestone,从而将 issue 进行归类整理。
在项目开发过程中,我们实施完全的前后端分离策略,下图分别为前后端的 issue 截图。
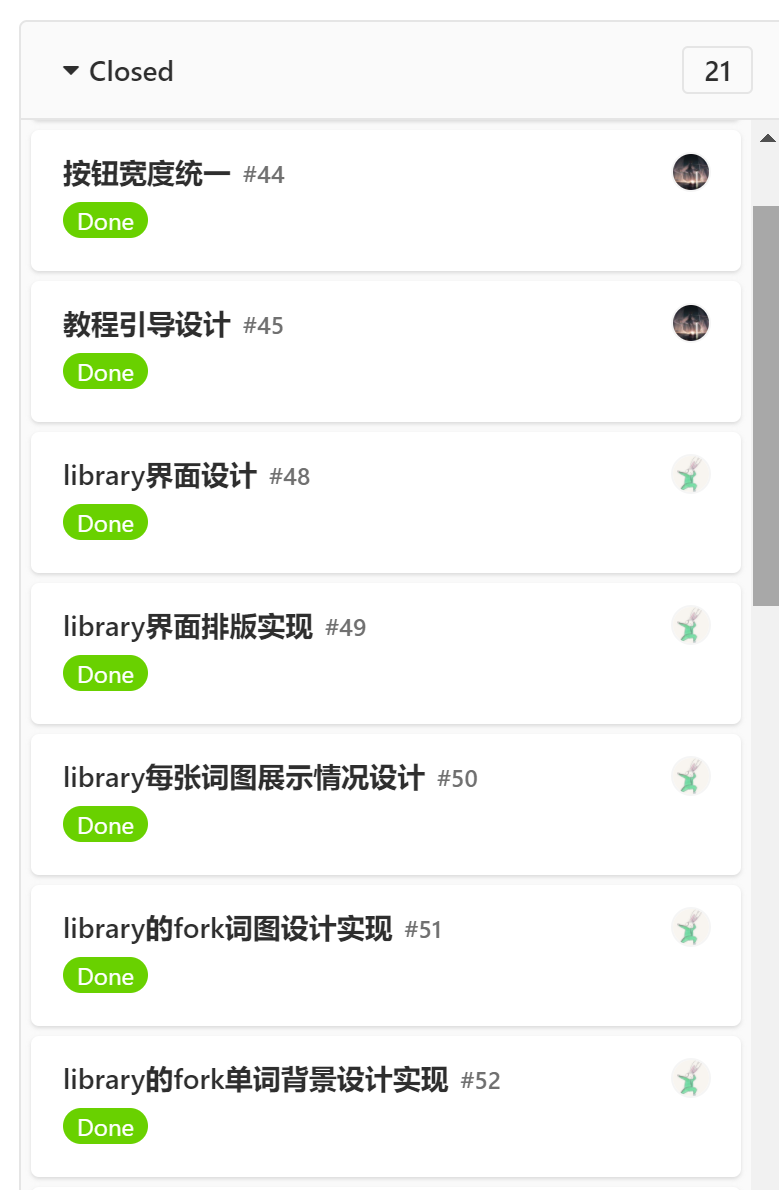 |
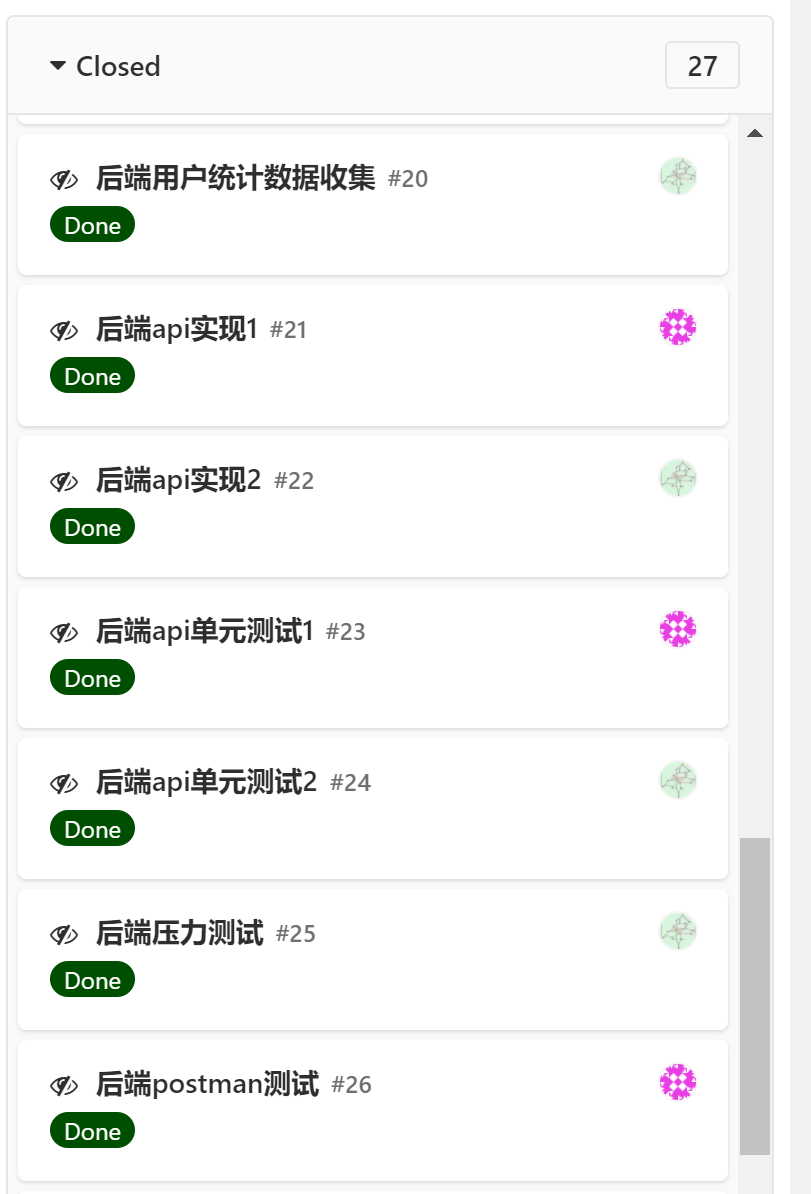 |
beta阶段改进
在alpha阶段中,为了查看的方便,本团队通过 wiki 的形式进行 api 文档的发布与共享;但是 wiki 并不支持查看每次更新的日志记录。因此,为了及时掌握各 api 在开发过程中的更新变动情况,同时也为了将文档与代码部分彻底解耦合,在 beta 阶段本团队在前后端分离的基础上,进一步将文档(documentation)也作为一个单独的 project 进行管理,从而保证各部分的独立性与灵活性。
沟通对接
在整个开发过程中,本团队同样继续贯彻线下讨论为主,线上交流为辅的沟通策略,具体表现为本团队的每次 Scrum Meeting 均为线下进行,总计共进行了 10 次线下讨论/集体开发会议,其中有明确会议记录的有 7 次。
事实证明,与线上讨论相比,线下集体交流无疑要更为高效,成员之间也更易达成一致,形成默契,培养友谊。
特别地,由于现场讨论主要是在教室进行,因此,在最后冲刺阶段的 Scrum Meeting 中,我们依然继续保留 alpha 阶段的特色——“kanban法”,充分因地制宜,直接在黑板上列举当前需要解决的主要 issue,从而充分发挥线下开发的优势,使得团队的每一个人都能对当前的任务进度一目了然。

beta阶段改进
但同时,与 alpha 阶段相比,beta阶段在强调团队协作之外,对于个人的开发也给予了充分的自由度和发挥空间,这主要基于以下原因:
- beta 阶段与一些课程的烤漆重合,且不同同学选课内容不同,因此同步协作难度有所上升;
- beta 阶段的新增功能相互之间较为独立,各成员分工明确,无需像 alpha 那样对核心难点进行集体攻关;
- 各成员在 alpha 阶段的开发后,对于软件已有了一个全面的了解,同时对于自己负责的任务也具备了高度的责任感和创新灵感,需要给予他们更多的自由空间。
二、典型用户场景
本部分重点针对 Beta 阶段的预期目标以及开发过程中新增功能的实现情况分别进行分析:
预期目标
| 预期目标 | 功能描述 | 预期用户场景 |
|---|---|---|
| 引导性教程设计 | 实现用户初次登录的步骤化教程引导,便于用户上手 | 初次使用本软件的用户 |
| 视频及H5宣发 | 制作宣传用视频及H5,在众多社交平台进行宣传 | 对A4纸背单词法不太了解的用户,初次接触本软件的用户 |
| 分享社区实现 | 设计并实现用户社区,以便分享词图 | 多个用户想要协同背单词,或者某用户想要获取现成词图 |
| 加词、单词出现的位置优化 | 将加词的默认位置分散。在复习时词图以过渡动画形式移动。 | 某些用户倾向于使用单词自动弹出位置。词图较大、单词位置较分散时需要动画过渡。 |
| 自定义词图背景 | 用户可以选择自己喜欢的带有含义的背景图片作为词图背景 | 意义明确的词图可以帮助用户更充分地发挥空间联想能力。 |
| 单词测试功能 | 在用户复习测试时,通过输入拼写等方式丰富测试模块 | 用户需要检验自己对单词的记忆程度,以及是否能正确拼写。 |
| 用户头像上传 | 支持用户自定义头像 | 默认头像好丑,使用用户心仪的头像可以提升用户幸福感 |
| 平板适配 | 升级用户在平板端的使用体验,包括排版适配,动作监听等 | 用户想在平板上通过浏览器使用本软件 |
| 统计信息丰富 | 增加更丰富的统计信息,包括词书背诵进度、整体词库记忆状态等 | |
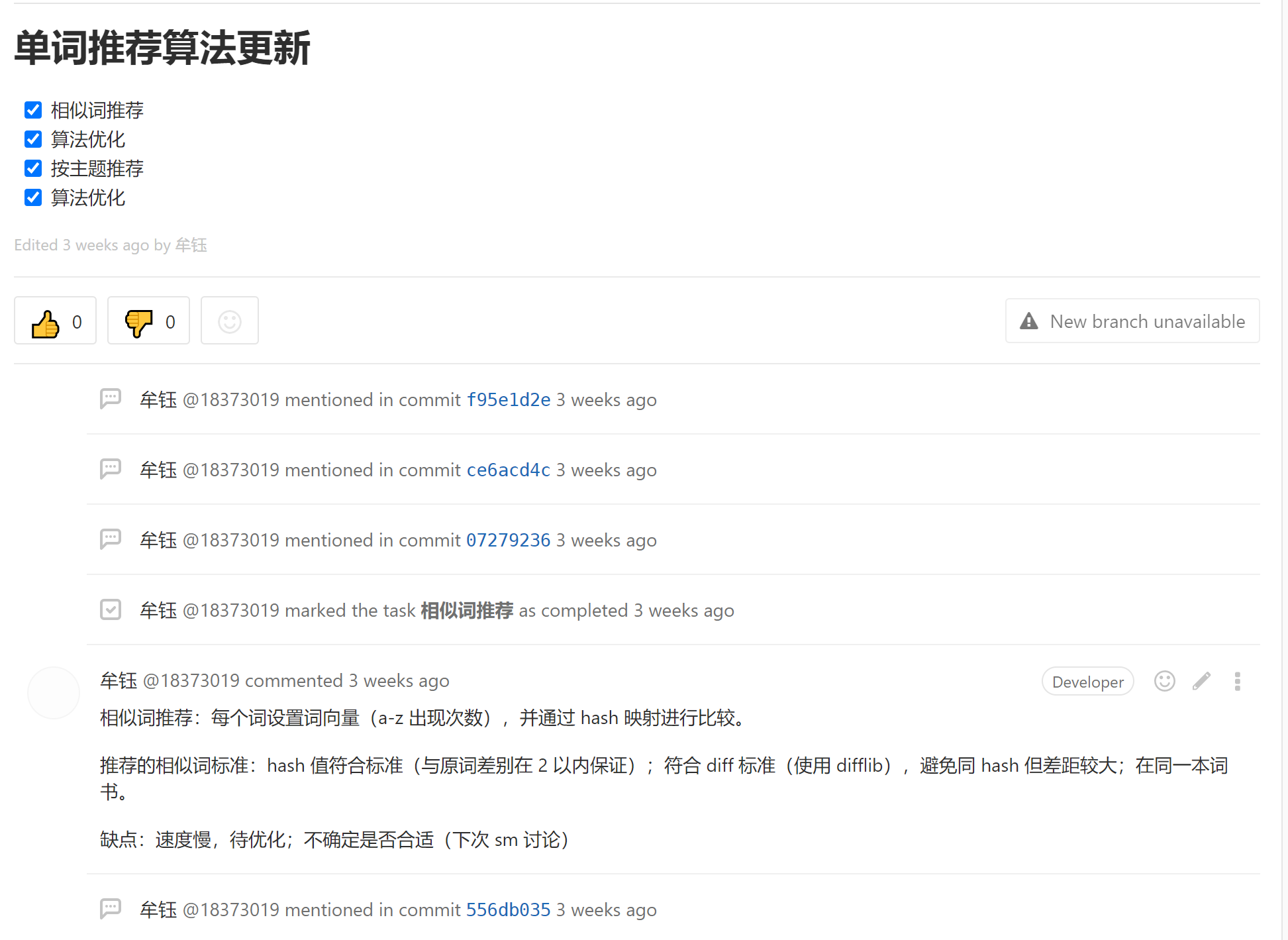
| 单词推荐算法升级 | 增加更多的单词推荐方式 | 不同用户对背诵单词的关联度要求不同。有的倾向于随机,有的倾向于使用词根词缀、近反义词等关联方式 |
新增功能
| 预期目标 | 功能描述 | 预期用户场景 |
|---|---|---|
| 用户默认个人设置 | 在用户设置界面,用户可以设置默认词书、推荐方式、发音类型、单词数量、复习模式等,方便用户后续操作。 | 某用户长期背诵一本次数,每次新建词图重新选择较为不便 |
| Http转Https | 通信通过Https加密,进一步提升安全性 | |
| 字体、主页、我的词图界面美化 | 将全局字体和主页进行ui美化,将我的词图页面进行重构并添加过渡动画。 | 用户使用时,ui的而美观程度将大幅度影响使用感 |
| 社区中用户状态浏览 | 在社区中,不仅可以查看词图,还可以查看分享词图的用户的部分状态信息 | 某用户发现用户A的词图很对自己的口味,于是详细浏览该用户的词图 |
用户场景的满足情况
| 用户 | 用户需求回顾 | 已满足 | Alpha阶段结束后暂未满足 | Beta阶段结束后暂未满足 |
|---|---|---|---|---|
| 田旭尧 | 1. 普及A4纸背单词法的理念 2. 让其明确感受到本软件和其他背词软件的独特之处 3. 让其感受到此单词软件没有缺失作为背单词软件的基本功能 |
1、2、3 | 3(待添加对单词的离散型测试功能) | 无 |
| 田昶舜 | 1. 普及A4纸背单词法的理念 2. 本软件能吸引其注意力,让其背单词时能够集中精神,实现长久记忆 3. 背词形式有趣,能够让用户拥有“换脑子”的体验 4. 支持考研词汇的背诵 5. 和朋友一起协同背单词 |
1、2、3、4 | 5(待添加社区功能) | 无 |
| 田昶禹 | 1. 普及A4纸背单词法的理念 2. 本软件能让其集中精力长时间背单词且少产生疲惫之感 3.本软件能有有效的统计机制,时刻提醒用户进行复习,时刻反应用户对单词的掌握状态,提高用户对已背单词的掌握程度 |
1、2、3 | 3(待添加更丰富的统计信息) | 无 |
| 田永晓 | 1. 拥有海量词库,支持特殊词书要求的背诵 2. 本软件能让其集中精力长时间背单词且少产生疲惫之感 3.本软件能有有效的统计机制,时刻提醒用户进行复习,时刻反应用户对单词的掌握状态,提高用户对已背单词的掌握程度。 4. 本软件具有强大的自定义功能,让用户可以自由组成词图 |
2、3、4 | 1(待添加更多单词推荐选项)、4(待添加用户自定义加入单词的功能) | 无 |
综合来看,本软件已覆盖了用户个人使用时的主要功能,且建立了较完善的用户社区,从而达到 Beta 阶段的功能要求标准。
用户评价
根据收集到的用户反馈,用户普遍认为该软件具有特色,并且使用方式新颖,具备一定的趣味性,达到背单词需求,功能相较于alpha阶段有明显的丰富,尤其是社区功能、单词测试功能的添加比较有亮点。目前的主要问题集中在请求速度(如词图背景api的加载速度)较慢,另外,由于本软件功能较多,初次上手仍存在一定的困难。
用户反馈详见第二部分:项目与团队总结。
三、杀手级功能
Beta 阶段结束后,本项目已经形成了完善的核心系统功能架构:
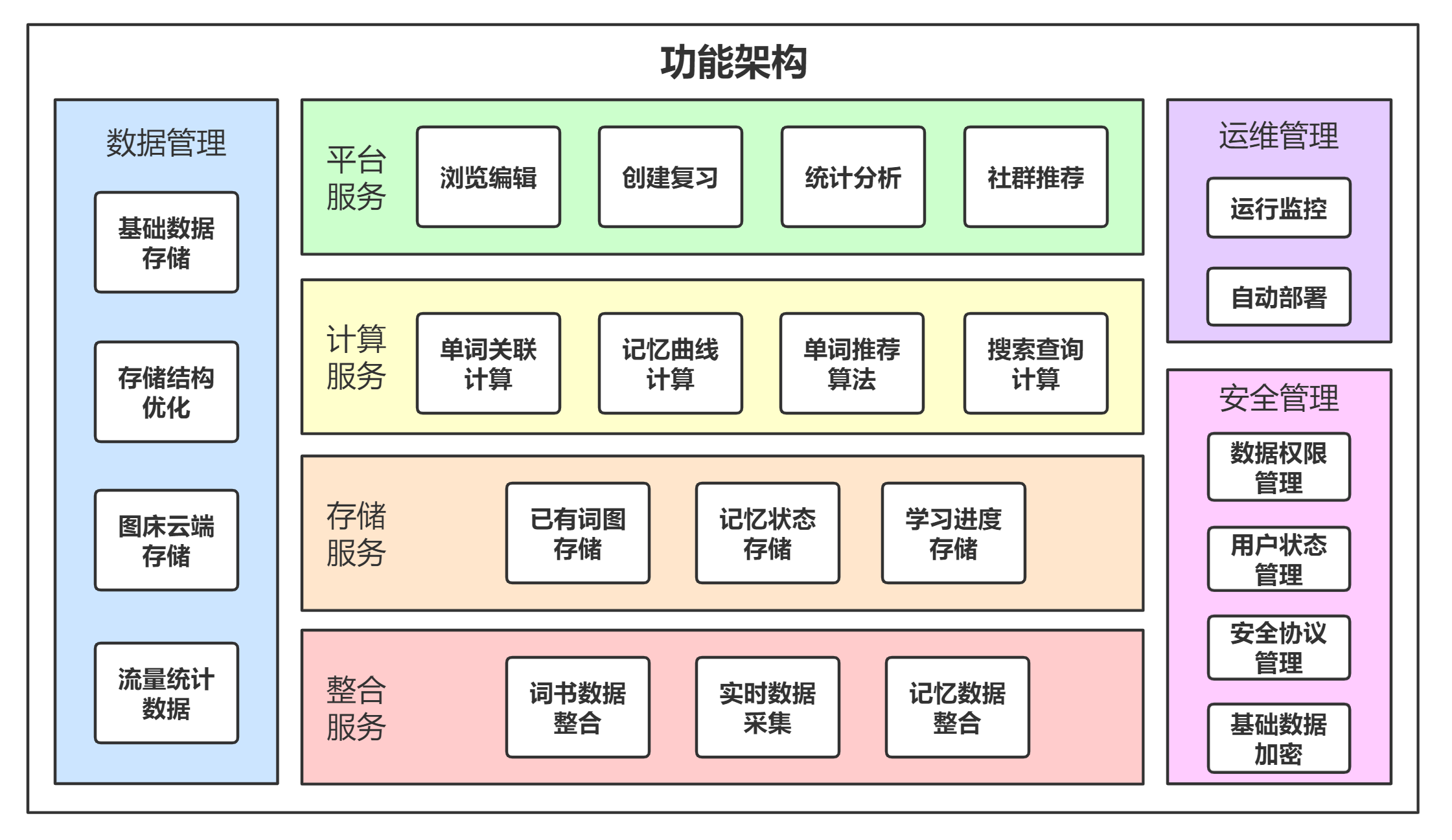
其中,Beta 阶段新增的重要的杀手级功能有:
-
单词键入复习
-
自定义加词

-
自定义背景

-
分享社区
具体功能描述见下文功能介绍部分。
竞品对比
针对 Beta 阶段新增的功能,我们将本软件和当前市场众多背单词app,以及近日在 B 站刚刚崭露头角的A4纸背单词法小程序进行竞品对比。竞品对比图如下:
| 功能 | 百词斩 | 扇贝单词 | 墨墨背单词 | A4纸背词法小程序 | 近取key(Beta) |
|---|---|---|---|---|---|
| 选择词书 | ✅ | ✅ | ✅ | ✅ | ✅ |
| 显示列表背单词 | ✅ | ✅ | ✅ | ⛔ | ✅ |
| 多种单词发音 | ✅ | ✅ | ✅ | ⛔ | ✅ |
| 例句发音 | ✅ | ✅ | ⛔ | ⛔ | ✅ |
| 额外词典 | ⛔ | ✅ | ✅ | ⛔ | ✅ |
| 艾宾浩斯遗忘曲线 | ⛔ | ⛔ | ✅ | ⛔ | ✅ |
| 打卡日历 | ✅ | ✅ | ✅ | ✅ | ✅ |
| 各单词掌握情况 | ✅ | ✅ | ⛔ | ⛔ | ✅ |
| 词图相关功能 | ⛔ | ⛔ | ⛔ | ✅(较简陋) | ✅ |
| 分享与社区 | ✅ | ✅ | ✅ | ⛔ | ✅ |
| 更改头像 | ✅ | ✅ | ✅ | ⛔ | ✅ |
| 单词复习 | ✅ | ✅ | ✅ | ⛔ | ✅ |
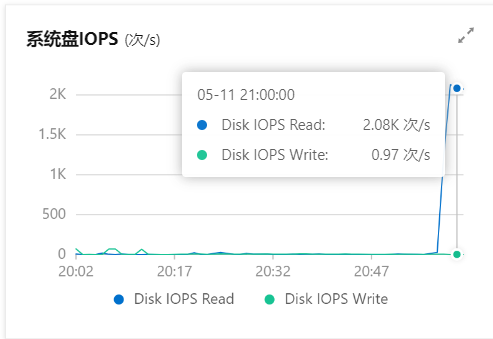
| 单词键入 | ⛔ | ⛔ | ⛔ | ⛔ | ✅ |
竞品主要缺失词图相关、单词键入相关等功能。主要原因为竞品大多基于手机端app实现,而移动端的小屏幕不足以将可编辑词图的优势发挥出来。另外,手机端打字也较为不便。
本产品充分利用了PC端的大屏优势和键盘优势,实现了高自定义度的词图编辑功能和带有键入的词图复习功能,并且基于词图对社区功能、fork等用户间交互操作进行了实现。
四、产品推广与用户数据
目前,团队使用H5宣传册、B站宣传视频等多种宣传方式进行了推介,取得良好的宣传效果。
H5宣传册
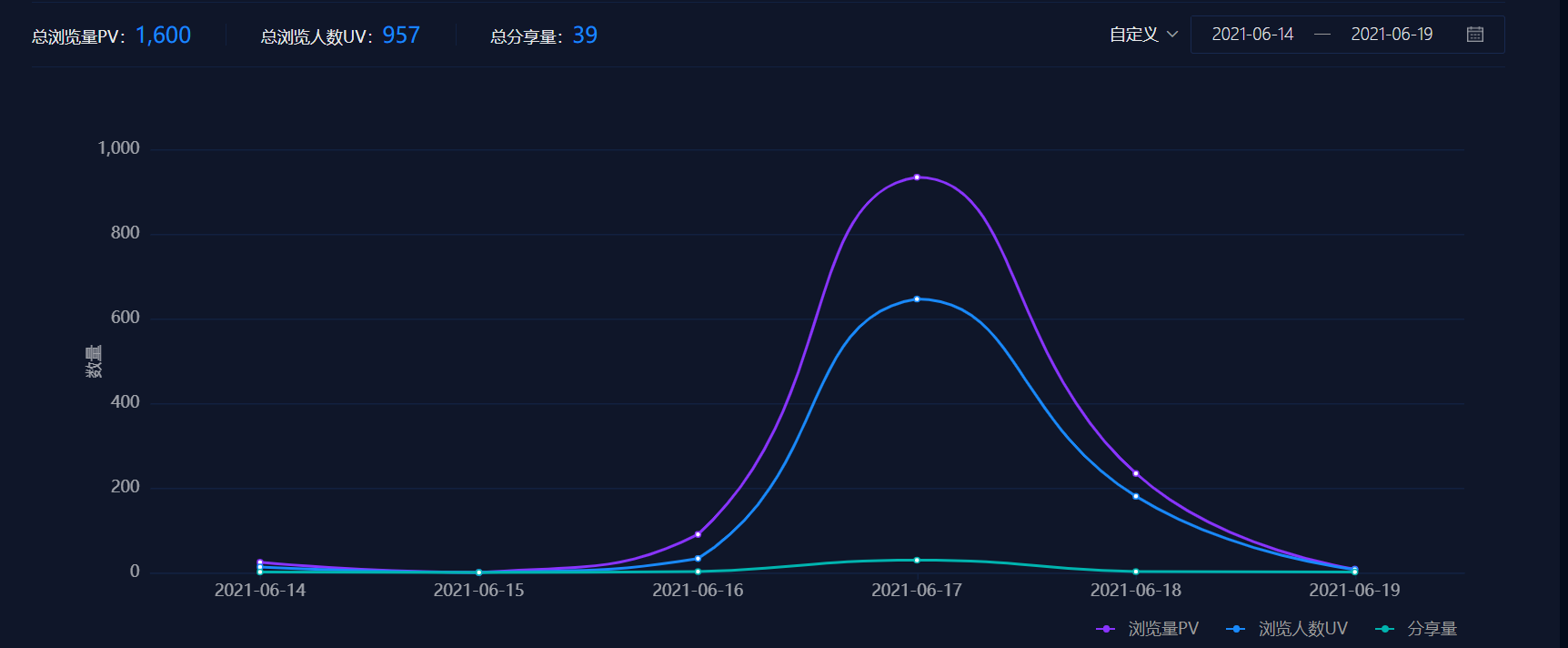
H5宣传册目前累计浏览量为1600次,总浏览人数957人,总分享量39次。详细数据如下:
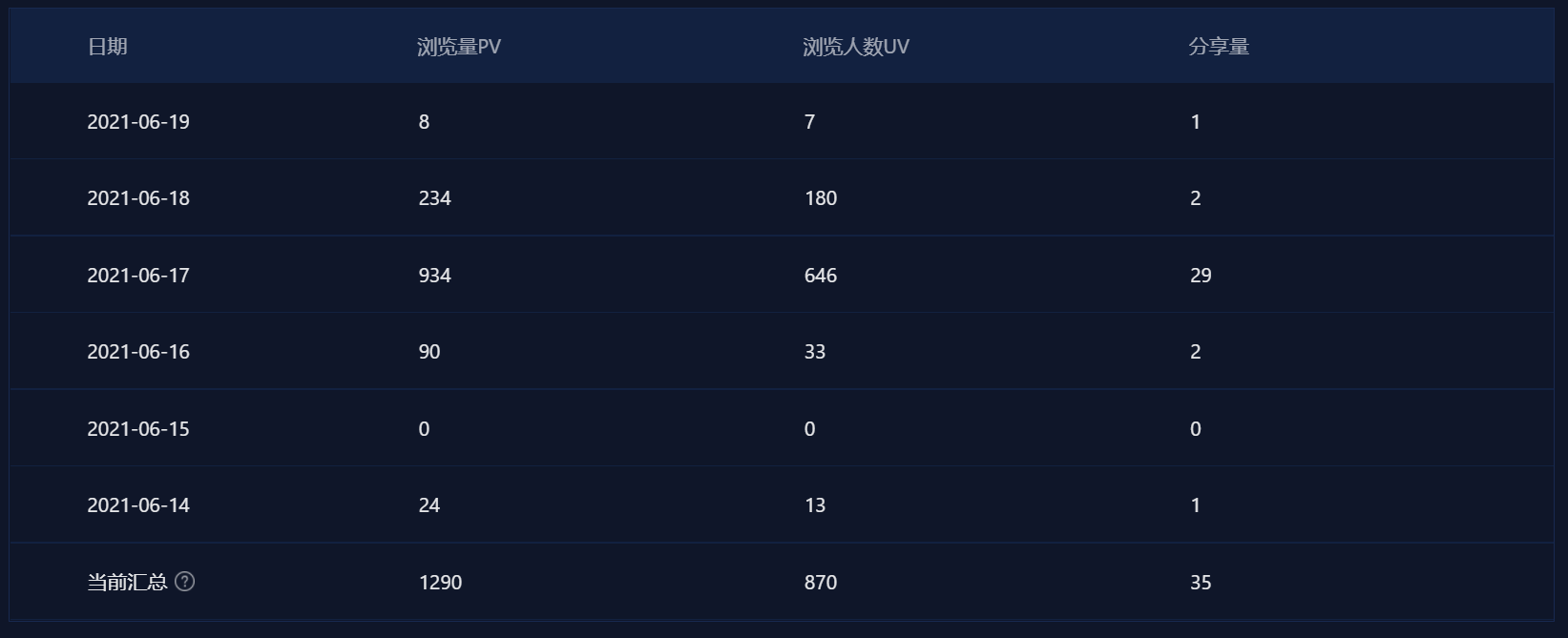
每日具体数据如下:
B站宣传视频
我们于6月17日下午16时在b站发布宣传视频,截至6月19日上午12时,视频播放量已达到996次,达到了良好的宣传效果:
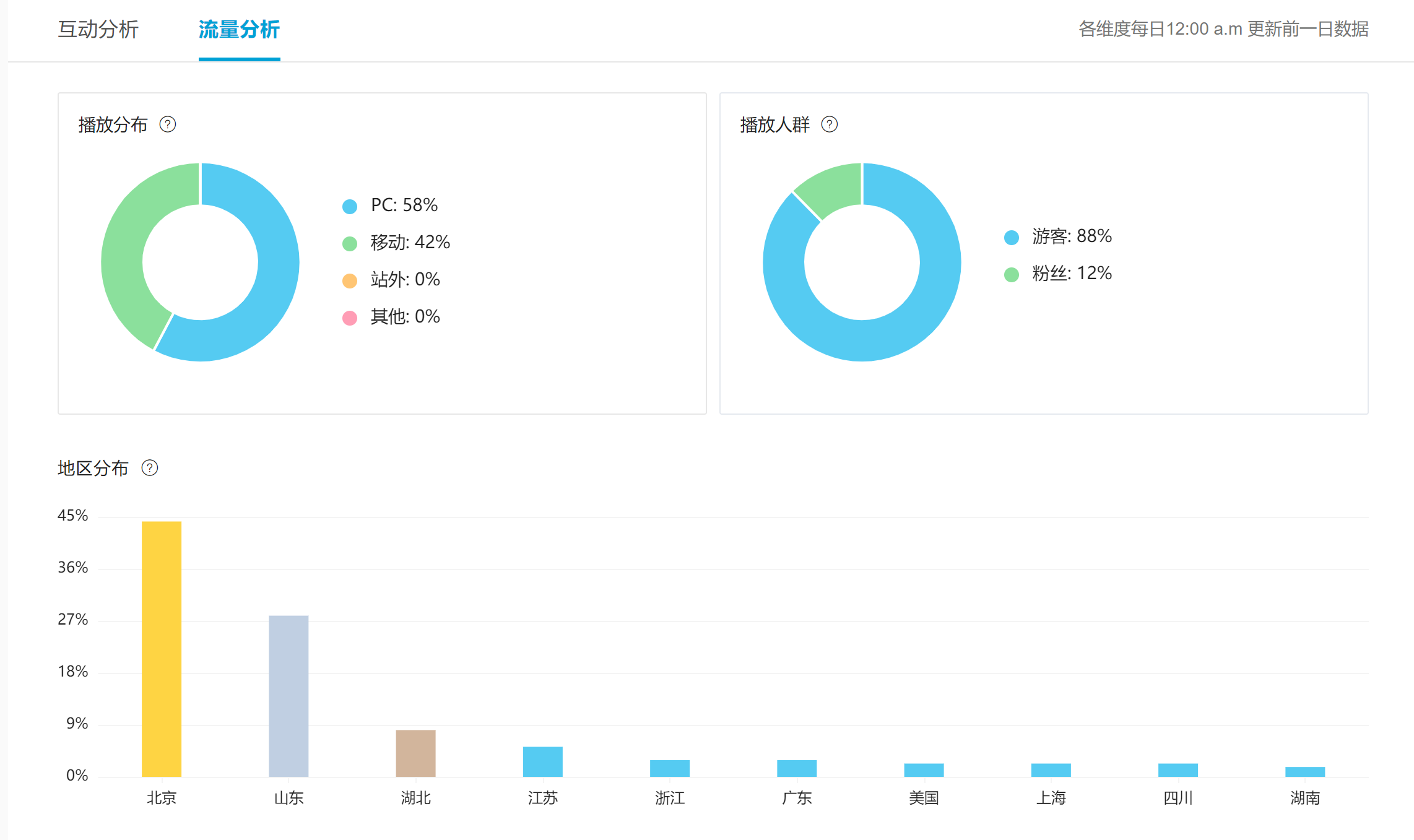
视频流量分析如下图所示:
累积用户
我们以累计注册量为累计用户,在某天查看、修改、新建、复习一次词图才被视为该日的日活用户。目前软件累计用户量已达 253人,较 alpha 阶段增加了约150人,平均日活用户量为 26,具体数据如下:
我们通过线下采访和线上用户反馈模块收集两种方式对用户的反馈进行了收集,详细内容请见第二部分:项目与团队总结。
五、软件工程质量
文档整理
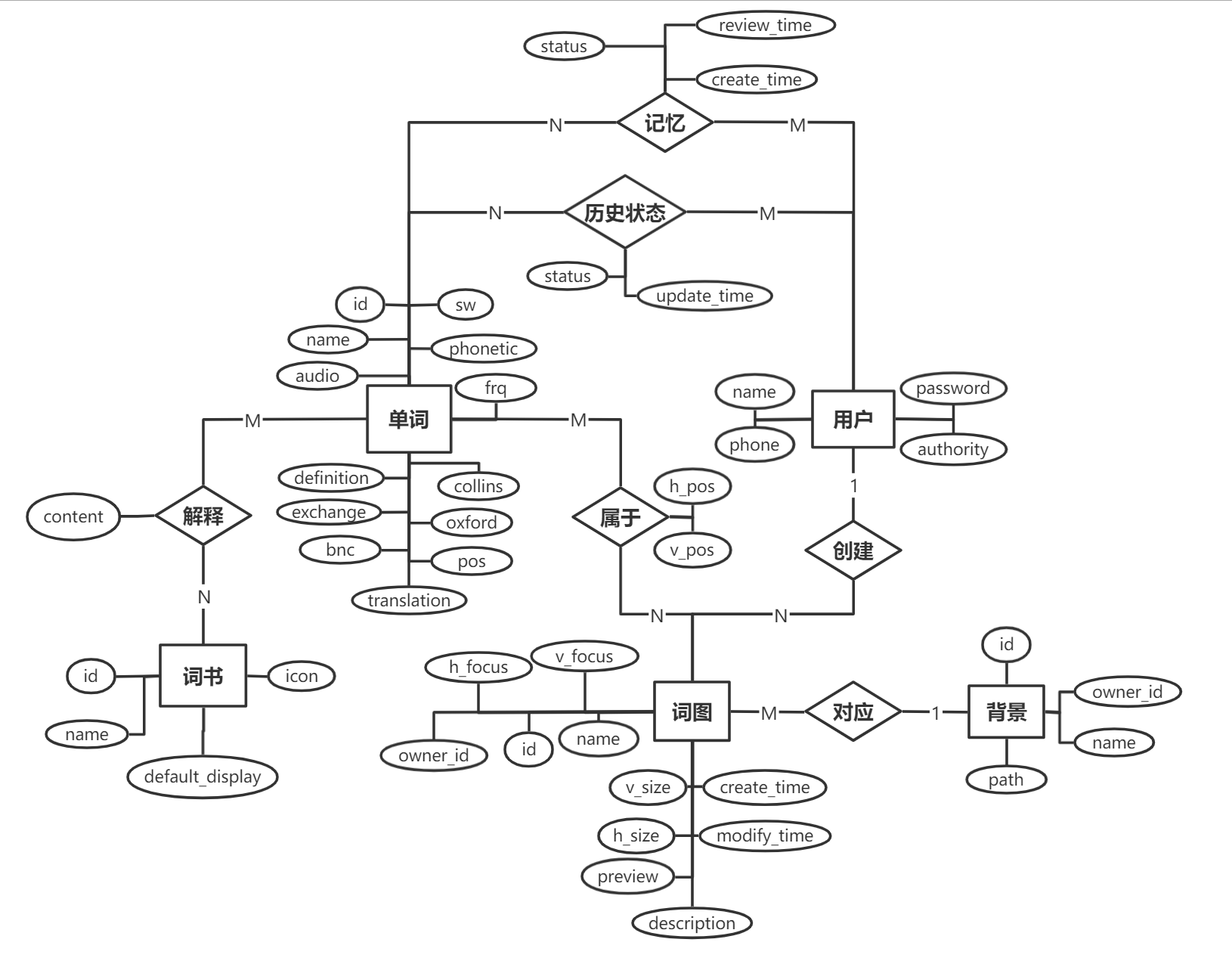
后端根据预期功能进行了较为充分的数据库预设计,通过两个 issue 3 4、以及 ER 图 定下了数据库的基本功能;对于单词基本信息以及其他信息,我们分别使用不同分支进行开发,并对于涉及数据库更新的部分撰写了详细的设计文档。
在 alpha 阶段,本项目使用 Gitlab 的 wiki 对 API 文档进行了完整的书写、实现及整理。另外,前后端人员通过固定的 issue 区对 API 进行改动汇报。
 |
 |
而在 beta 阶段,为了对 api 文档的修改记录实现动态追踪,本项目将文档部分作为一个单独的 project 进行独立出来,并利用 GItLab 的 commits 与 diff 功能了解相关 api 的更新细节,避免了不必要的沟通成本。
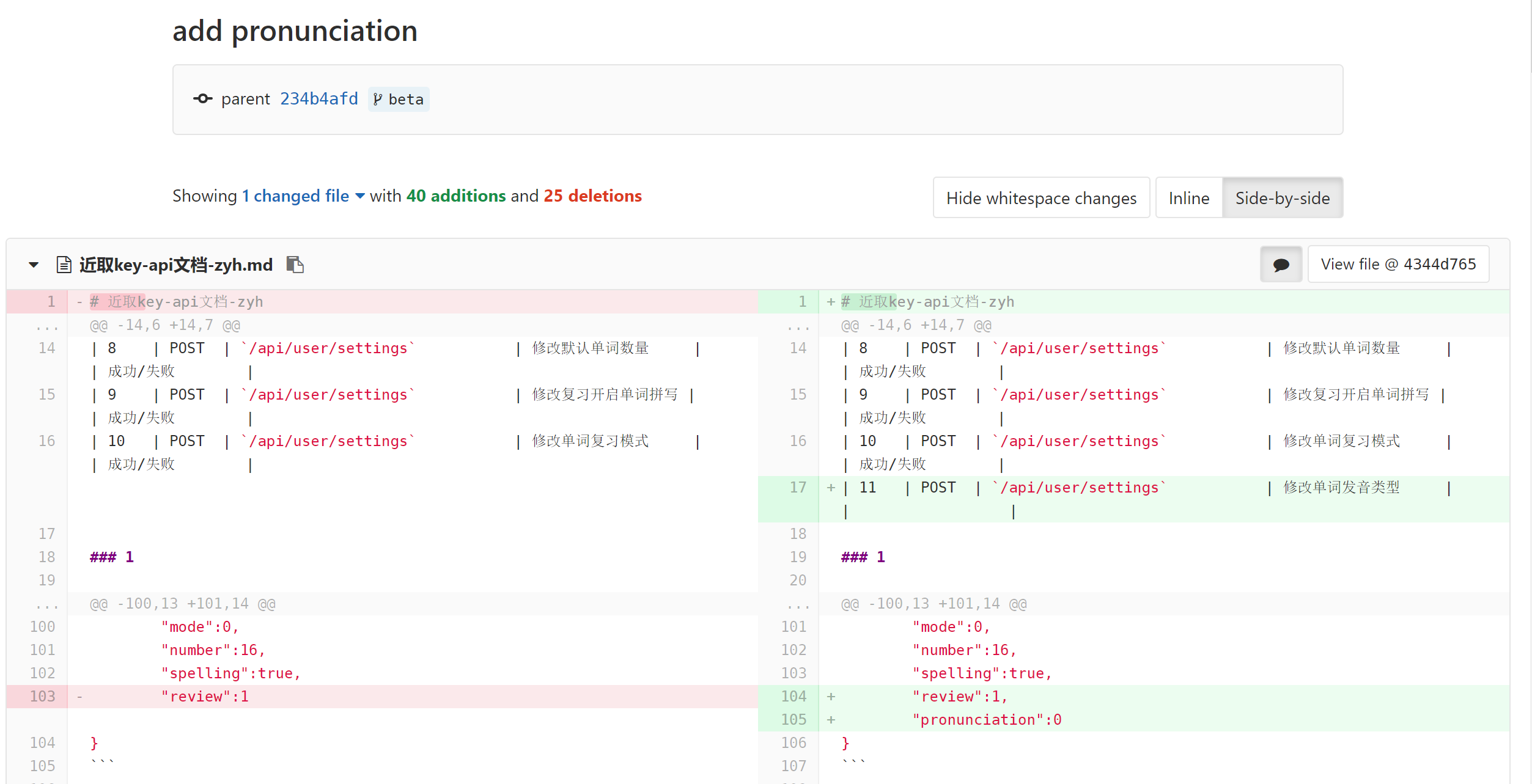
代码规范
前后端均对于代码风格、内容、命名、错误码和返回值进行了规范,详见第二部分。
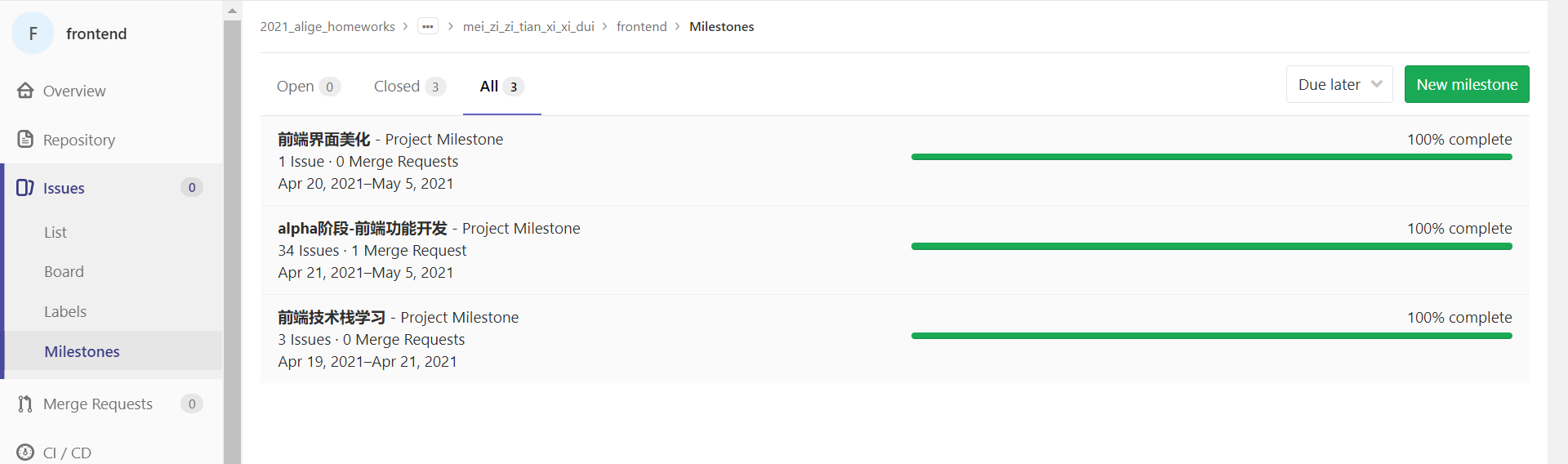
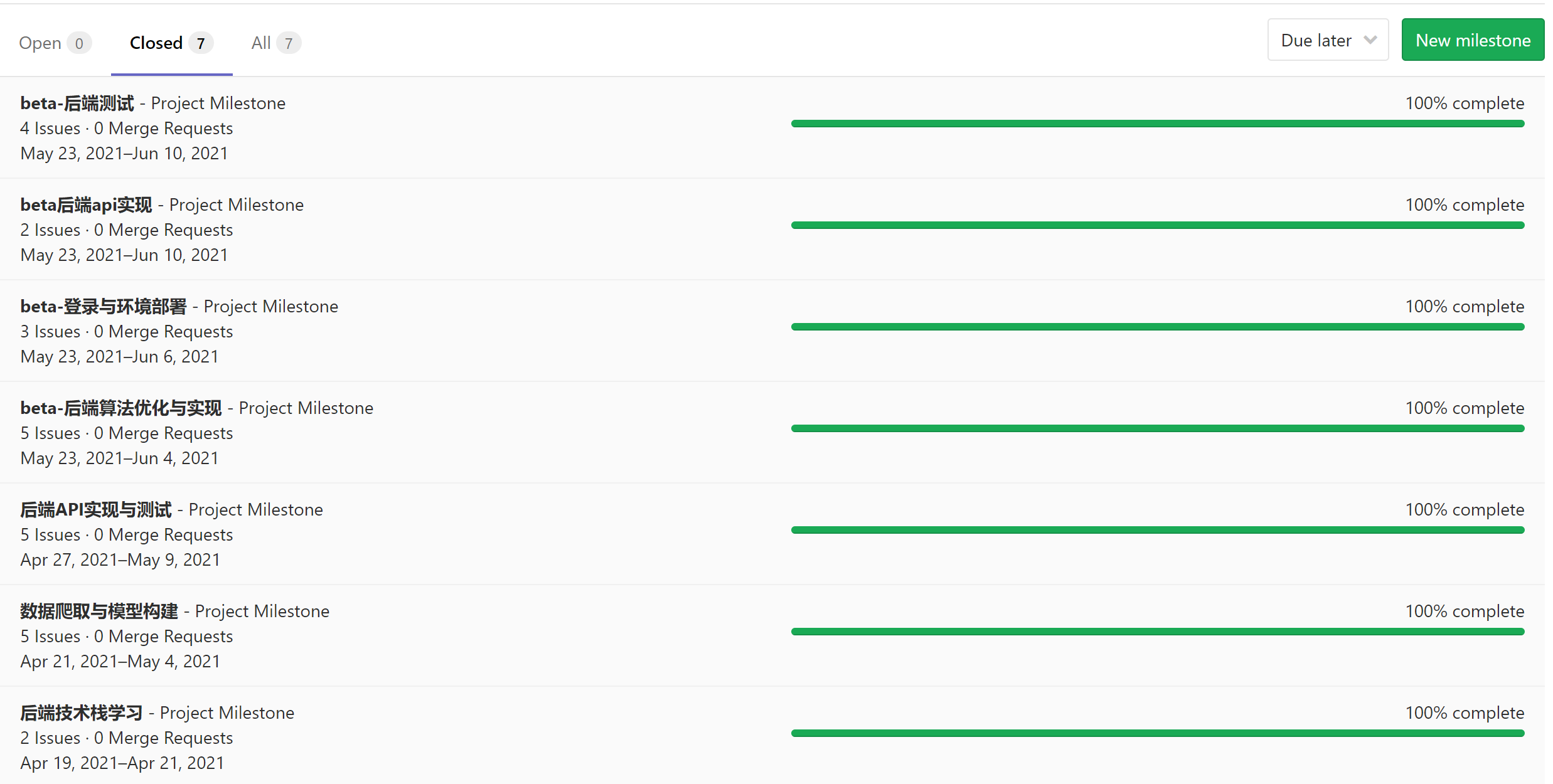
Gitlab 使用
前端和后端在开发过程中都使用 issues 对每位成员的工作任务和进度进行关注,并使用 milestone 对所有 issues 进行归类,展现每一阶段的完成进度。目前 Beta 阶段的全部里程碑均以 100% 完成。
 |
 |
另外,我们通过给 commit 信息添加 issue 链接实现将 commit 与相应的 issue 进行关联,并利用 markdown 自带的 checkbox 对部分重要的 issue 的具体进展情况进行实时追踪,从而更清楚地反应对某一 issue 的完成进度和每一 commit 完成的工作。
测试情况
由于本项目的运行对数据库具有极高的要求,情况较为特殊,正常地测试需要使用自定义的生产数据库进行,单元测试实现较为困难。但我们仍旧通过制作接口、构造数据等方式进行了部分单元测试,覆盖率达到 69%。
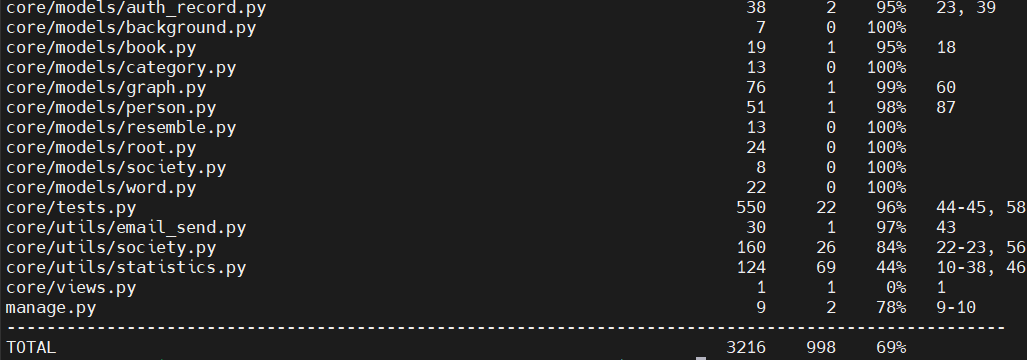
没有达到较高覆盖率的原因有三:
- 使用双重校验,每一个 API 都使用解析 token 和解析用户两步进行,保证了用户隐私的安全性,但同时难以构造测试用例对于能够通过 token 解析但是通不过用户解析的场景,故每一个 API 都无法测试这一点;
- 部分 API 使用与其他 API 类似的结构,仅更改了部分影响内容(如修改字体、修改大小等),对于此类问题由于时间限制等原因没有进行完备的测试;
- 对于登陆和注销有关权限 API,进行了较为完备的场景测试,没有进行单元测试。
本项目在前端和后端都对 CI/CD 环境进行了配置并且成功运行。由于后端单元测试直接部署在服务端,CI/CD 需配置 django 和 mysql 等一系列软件、故最终没有采用,但在本地提交时会自动进行单元测试;前端实现了 CI/CD 自动部署。主要用途为对项目进行持续集成,并持续测试能否成功打包,为后期向服务器的部署提供了方便。
除了单元测试和 CI/CD,本项目还使用其他方法进行了测试:
- 手动构造测试:进行了大量的模拟用户操作的构造测试。
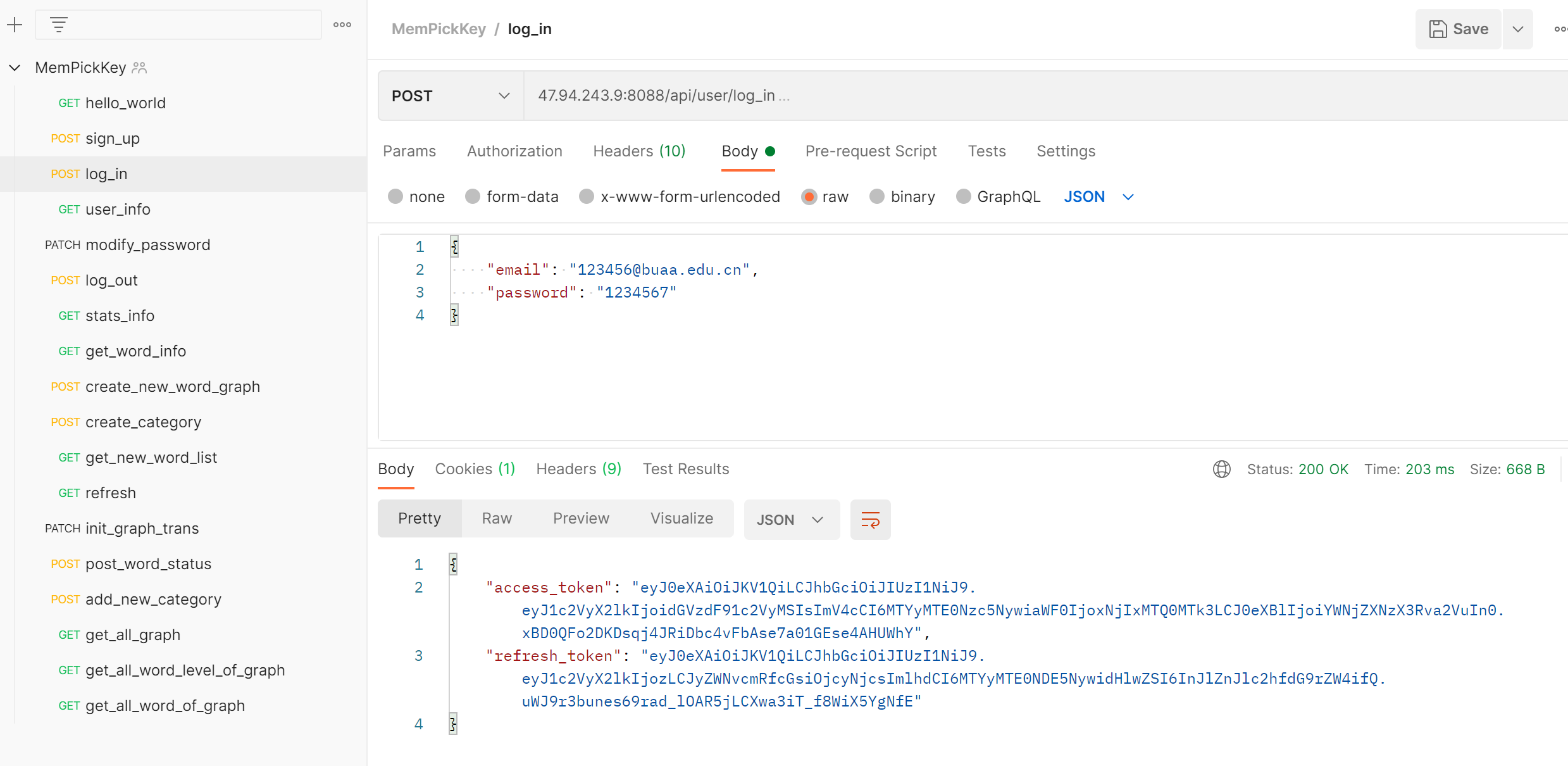
- 压力测试:对于服务器的各项负载能力进行了全面的分析和压力测试。
 |
 |
 |
具体测试细节和结果详见测试报告。
项目与团队总结
一、项目管理
沟通对接、分工协作的展示部分见项目与团队亮点一。
成员简介与个人博客地址
成员简介和个人博客地址可见本团队的团队介绍博客。
团队分工
本部分内容基本与 alpha 阶段一致,并在其基础上加入 beta 阶段的具体任务说明。
详细的分工及工作内容如下所示:
| 岗位 | 成员 | 具体工作 |
|---|---|---|
| PM | tcy, my, zyh | 1. 组织开展例会,明确任务分工 2. 把控整体进度,完成博客撰写 |
| 前端开发测试 | zyh, xpy, zjs, xmy | 1. 完善项目主页、词图管理、统计信息等主要页面 2. 实现用户社区、单词测试等功能 3. 完成前端 API 文档 4. 实现前端页面与组件之间跳转逻辑 5. 前端生产环境部署 |
| 后端开发测试 | tcy, my | 1. 提升系统安全性、响应速度 2. 完善后端数据库 ORM 模型 3. 完善并增加前端所需要的各 API,包括词图等社区推荐算法、统计信息计算、词图克隆等 4. 覆盖进行后端压力测试、单元测试 |
管理模式
本项目采用 石墨文档 + Gitlab issues 的方式进行共同管理。
与 Gitlab 相比,石墨的优势主要表现为以下几点:
- 可以为每个任务的实际工作量进行定量评估,而不是仅仅基于该任务的完成时间进行测算,这在客观上可以更好地衡量开发人员实际投入的时间与精力。
- 由于 Gitlab 本身不支持直接生成燃尽图,或者生成的燃尽图并不足够真实准确,因此基于石墨文档有助于更方便地生成实际任务量对应的燃尽图。
- 考虑到开发人员在开发过程中还存在其他的课业压力,以及某些任务在制定初期可能比较粗糙,不够明确,因此需要在开发过程中对任务的分配进行进一步的细化调整,这一点也使得石墨文档更具优势。
项目分支
在项目开发过程中,我们实施完全的前后端分离策略,即前端与后端分别创建自己的 project,彼此之间仅通过协商好的 API 接口进行交互。这表现在项目开发上,即为前后端的提交无需再进行额外的 merge,从而保证了代码与环境的相互独立。
由于词图与单词详细信息数据体量较大,考虑到目前的系统负载能力,我们选择牺牲组件之间的耦合度,来减少和后端之间的通讯次数,从而最大程度为系统减负。
另一方面,对于后端而言,由于其总体工作大致可分为数据解析爬取与 Django 框架搭建部署两部分,因此我们分别对其创建了相应分支,从而保证生产环境下代码的干净整洁。
燃尽图
通过石墨文档计算得出的整个开发周期的燃尽图如下所示:
注意到,与其他组的燃尽图相比,本组的燃尽图具有以下特点:
- 剩余任务量/预计任务量的单位并非为 issue 个数,而是对任务进行了更细致的难度评定,从而更科学地对其进行量化
- 项目预计进度并非一条直线,而是充分考虑到实际情况,不同任务给出了不同的预计完成时间
- 基于 iFrame 框架实现,可交互,便于实时查看和更新当前最新进度
团队贡献分分配
本团队在贡献分分配上,充分考虑了不同成员领取的任务量与任务难度差异,并对其进行了系统的量化。此外,本团队还引入了互评机制与奖励机制,从而最大程度激发每一位团队成员的积极性,力求客观全面公正。
最终计算得到的各成员贡献分如下表所示:
| 成员 | 实际任务量 | 任务贡献分 | 团队互评得分 | 签到得分 | 贡献奖励分 | 最终得分 | beta 具体贡献 |
|---|---|---|---|---|---|---|---|
| tcy | 201 | 32 | 9.5 | 9 | 3 | 53 | 撰写博客文档,负责大部分 API 以及社区统计推荐算法,词图克隆等功能后端实现,组织开展多次线下集体开发会议 |
| zyh | 187 | 31 | 9.5 | 9 | 2 | 51 | 撰写博客文档,负责前端统筹开发,单词复习测试功能实现,参与组织多次线下集体开发会议 |
| my | 189 | 31 | 9.17 | 7.5 | 1 | 49 | 撰写博客文档,负责后端单元测试等任务,完善部分API接口与单词推荐算法 |
| xpy | 171 | 28 | 9.17 | 9 | 2 | 48 | 负责词图中画布相关功能与统计信息页面的完善。适配与字体美化等 |
| zjs | 191 | 31 | 9.5 | 9 | 2 | 52 | 负责词图管理页面UI重构、用户社区等版块设计与实现 |
| xmy | 171 | 28 | 8.67 | 8.5 | 2 | 47 | 负责主页、教程引导实现,制作H5与宣传视频 |
二、用户场景
典型用户
| 用户信息 | 用户情况 |
|---|---|
| 姓名 | 田旭尧 |
| 身份 | 某校非英语专业大二学生 |
| 使用动机 | 英语不太好,想多背一些单词冲刺四六级,但是没有什么动力 |
| 典型场景1 | 在宿舍突然想背单词,打开 APP 使用一些背词功能 |
| 典型场景2 | 在食堂,饭太烫闲着无聊没事干,背几个单词 |
| 用户偏好 | 几乎不背单词,或偶尔零碎地背单词(非受众) |
| 用户痛点 | 不知道怎么复习/背单词,想要短时高收入 |
| 预期目标 | 由于非主要受众,因此对此类用户的预期目标为:1. 普及A4纸背单词法的理念 2. 让其明确感受到本软件和其他背词软件的独特之处 3. 让其感受到此单词软件没有缺失作为背单词软件的基本功能 |
| 用户信息 | 用户情况 |
|---|---|
| 姓名 | 田昶舜 |
| 身份 | 某校考研党,英语单词量不高,需要大量提升 |
| 使用动机 | 想要在半年里把考研单词记熟,每天抽出一定时间专门背单词 |
| 典型场景1 | 复习数一数二腻了,背背单词学学英语换换脑子 |
| 典型场景2 | 突然被某篇鸡汤激励到,立誓背完考研单词,然后背了五分钟 |
| 用户偏好 | 偶尔会专门背记单词,主要时间不会用太多,但会用系统化的时间专门记忆单词 |
| 用户痛点 | 单词量较大,碎片化背单词过于低效,且容易注意力不集中、记忆不长久 |
| 预期目标 | 1. 普及A4纸背单词法的理念 2. 本软件能吸引其注意力,让其背单词时能够集中精神,实现长久记忆 3. 背词形式有趣,能够让用户拥有“换脑子”的体验 4. 支持考研词汇的背诵 |
| 用户信息 | 用户情况 |
|---|---|
| 姓名 | 田昶禹 |
| 身份 | 可怜高中生,高考近在眼前 |
| 使用动机 | 高考英语单词必须得全部背过呀 |
| 典型场景 | 每周末在家抽出3~4h专门背单词 |
| 用户偏好 | 使用整块的时间系统化背单词,且对每个单词的掌握程度要求高 |
| 用户痛点 | 碎片化的背单词法不适用于一直坐着学习的高考党 |
| 预期目标 | 1. 普及A4纸背单词法的理念 2. 本软件能让其集中精力长时间背单词且少产生疲惫之感 3. 本软件能有有效的统计机制,时刻提醒用户进行复习,时刻反应用户对单词的掌握状态,提高用户对已背单词的掌握程度 |
| 用户信息 | 用户情况 |
|---|---|
| 姓名 | 田永晓 |
| 身份 | 某校英语专业或出锅留学生 |
| 使用动机 | 有大量背单词的需求,常啃红宝书等词书,普通的碎片化记忆模式 APP 不适合了 |
| 典型场景1 | 某一天要背好多单词,不想背着一大摞书去图书馆,硬啃,普通的背单词软件过于碎片化,满足不了需求 |
| 典型场景2 | 看了个英文电影,想把电影里整理出来的单词加入候选背单词列表中 |
| 用户偏好 | 系统化背单词,即专门抽出时间阅读书籍、影视并记忆有关单词 |
| 用户痛点 | 纸质书籍重且较不方便、没有交互;大量学习中产生的零散单词除了手写记录难以集中背诵,且无法自定义位置;希望能提供基于词根词缀、近反义词的推荐背诵词 |
| 预期目标 | 1. 拥有海量词库,支持特殊词书要求的背诵 2. 本软件能让其集中精力长时间背单词且少产生疲惫之感 3.本软件能有有效的统计机制,时刻提醒用户进行复习,时刻反应用户对单词的掌握状态,提高用户对已背单词的掌握程度 4. 本软件具有强大的自定义功能,让用户可以自由组成词图 |
项目发布功能
对于Beta 阶段已发布的功能,仅拷贝发布文档的重要功能概述,其余具体功能实现情况及展示详见发布文档。
新功能介绍
『UI界面更新』
首先,前端对软件字体进行了美化设置,同级字体采用一致的美观字体。
另外,前端针对我的词图界面进行了着重ui优化,包括修改整体布局、过度动画,新增极简模式适应用户的不同需求。
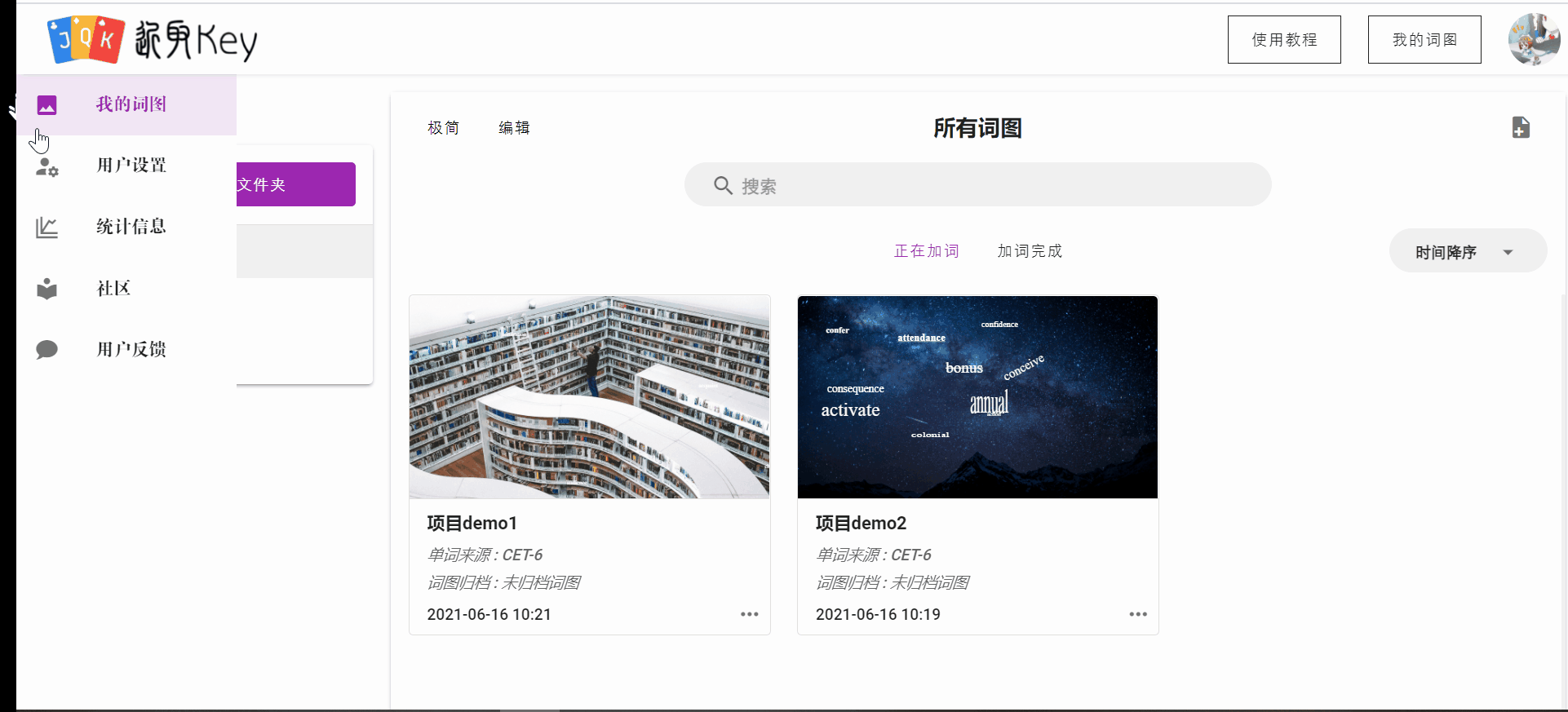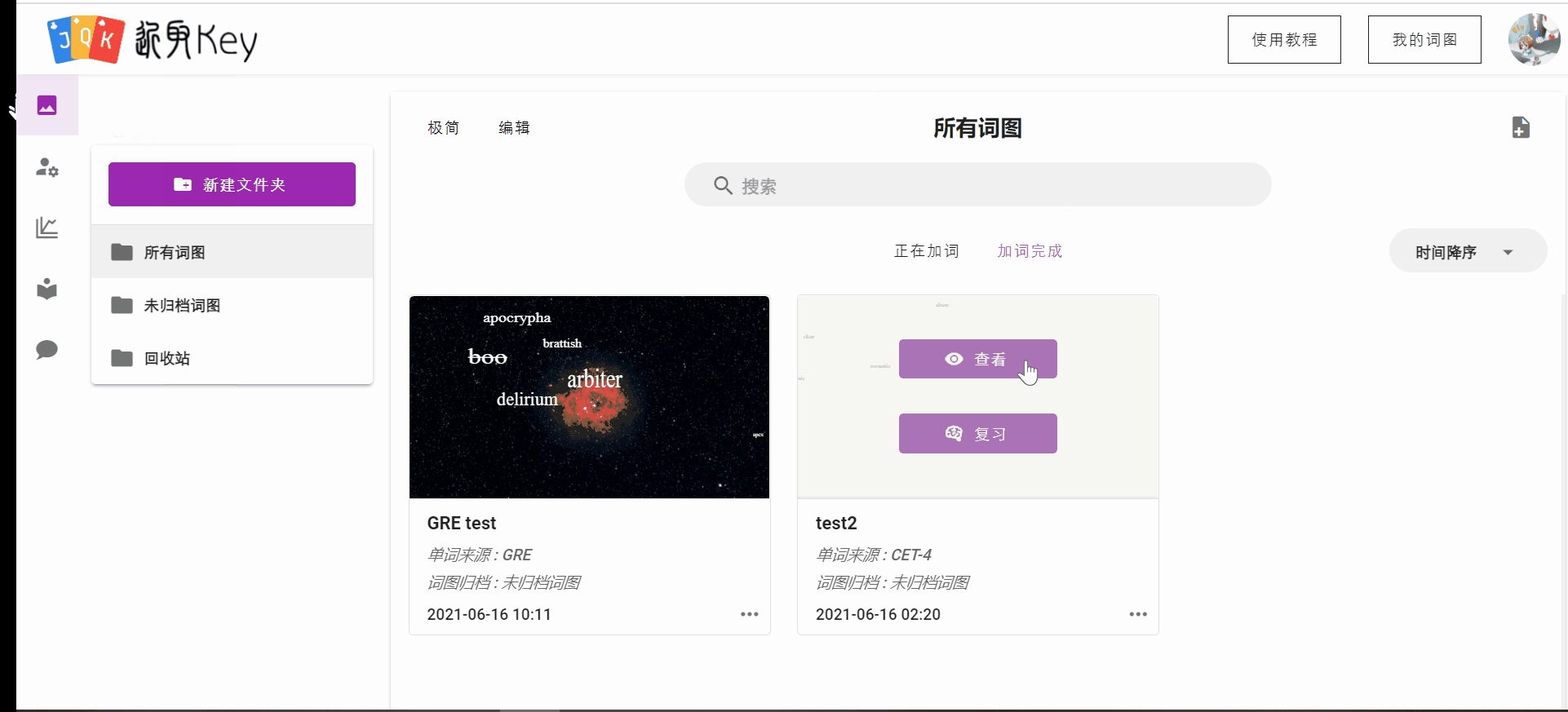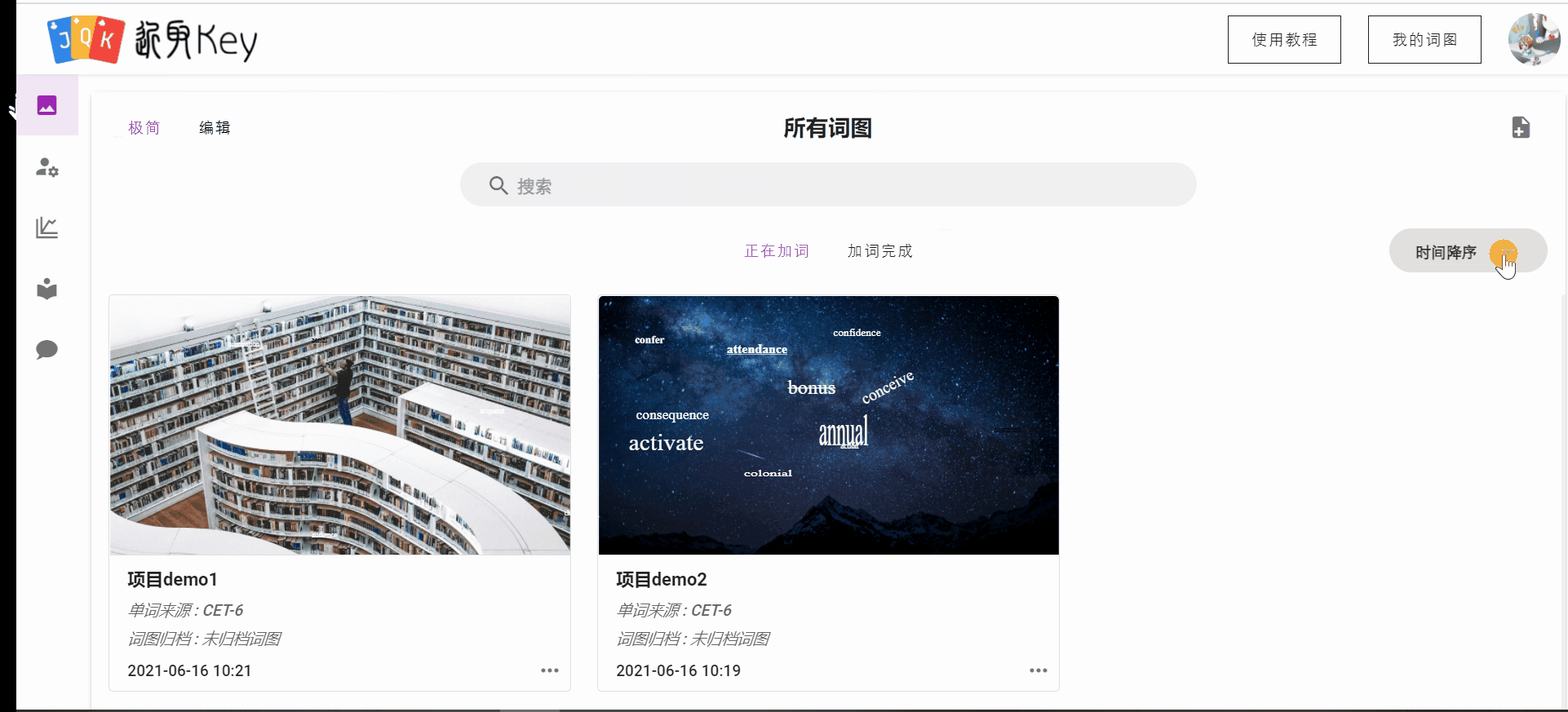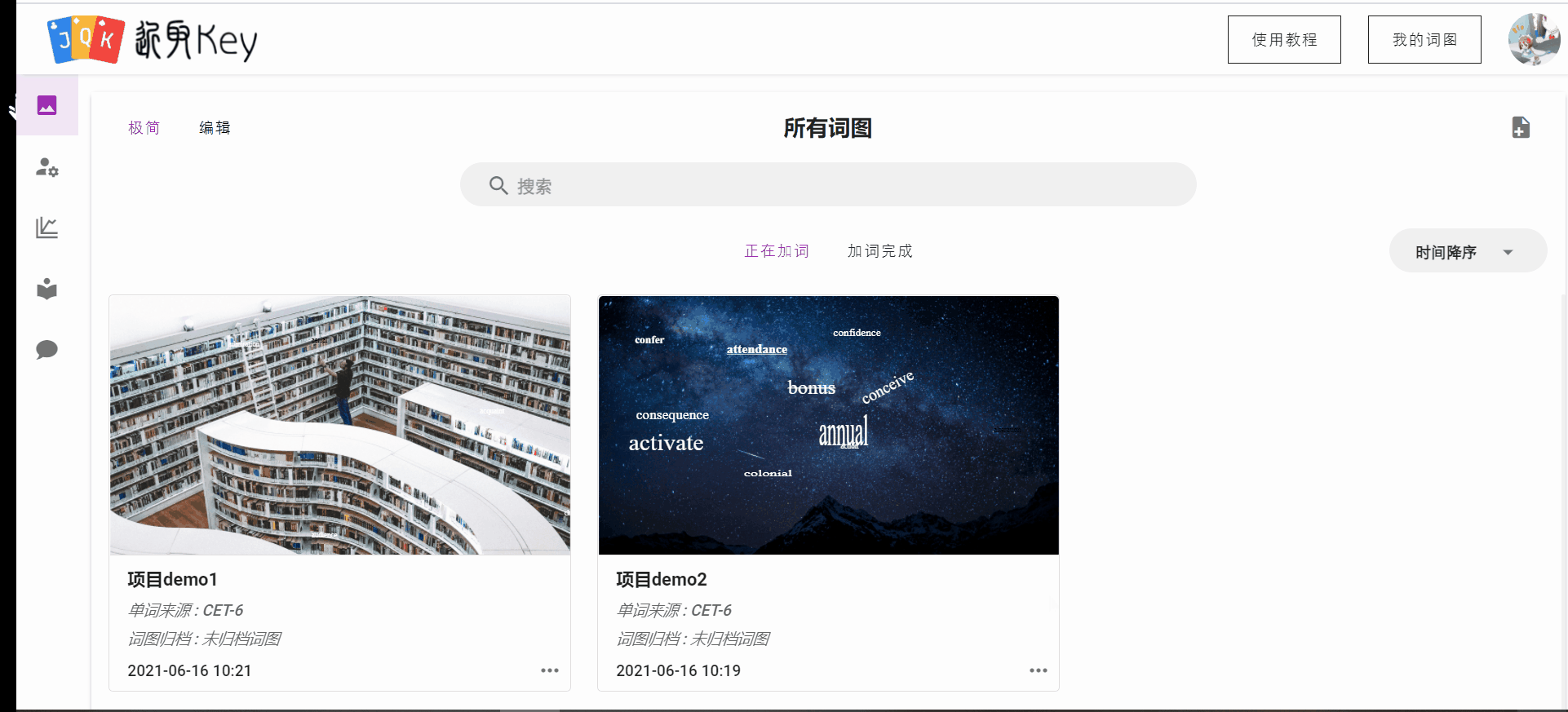
教程引导
对于首次使用本软件的用户,我们提供了引导性教程,一步一步指导用户完成第一张词图的建立。教程引导覆盖:
- 新建词图
- 编辑词图(加词,工具栏)
- 测试词图
 |
 |
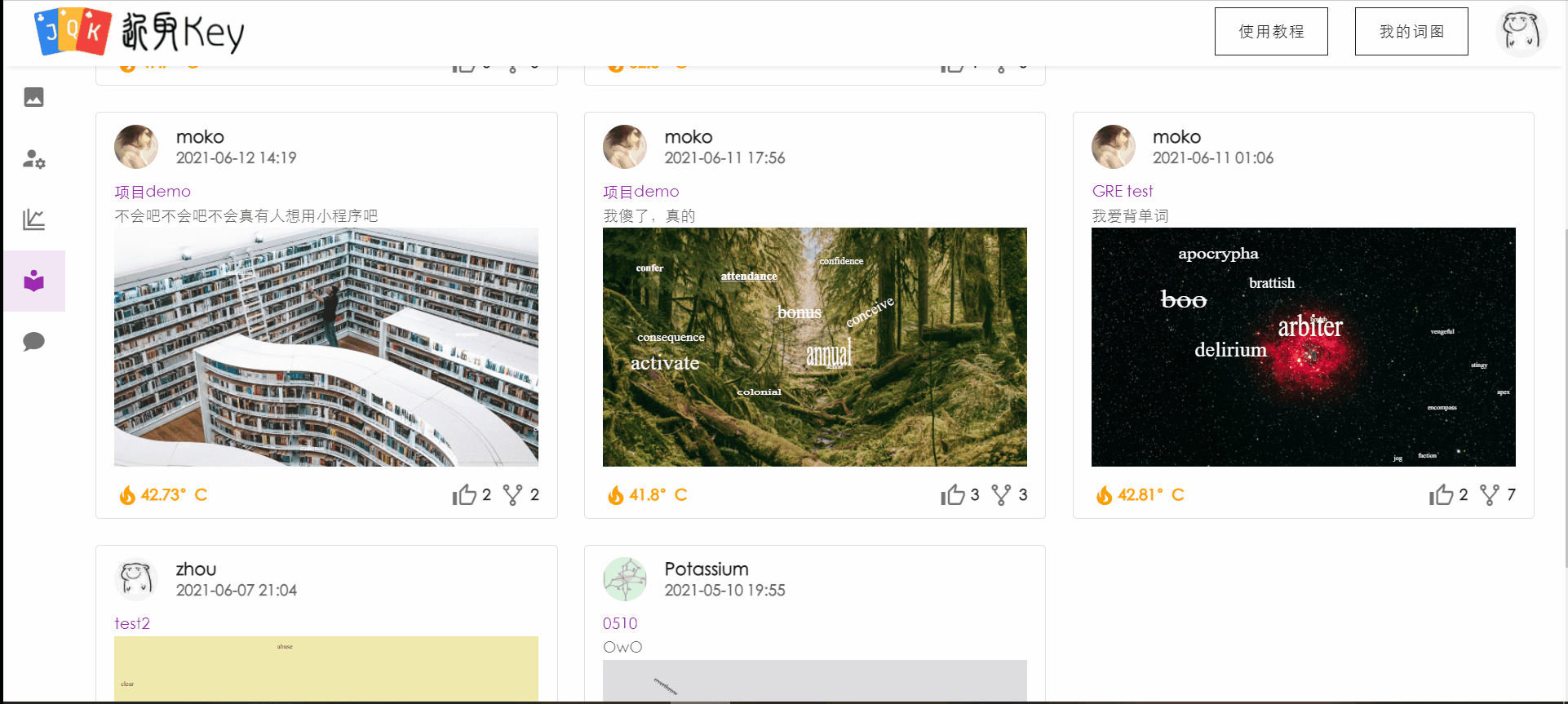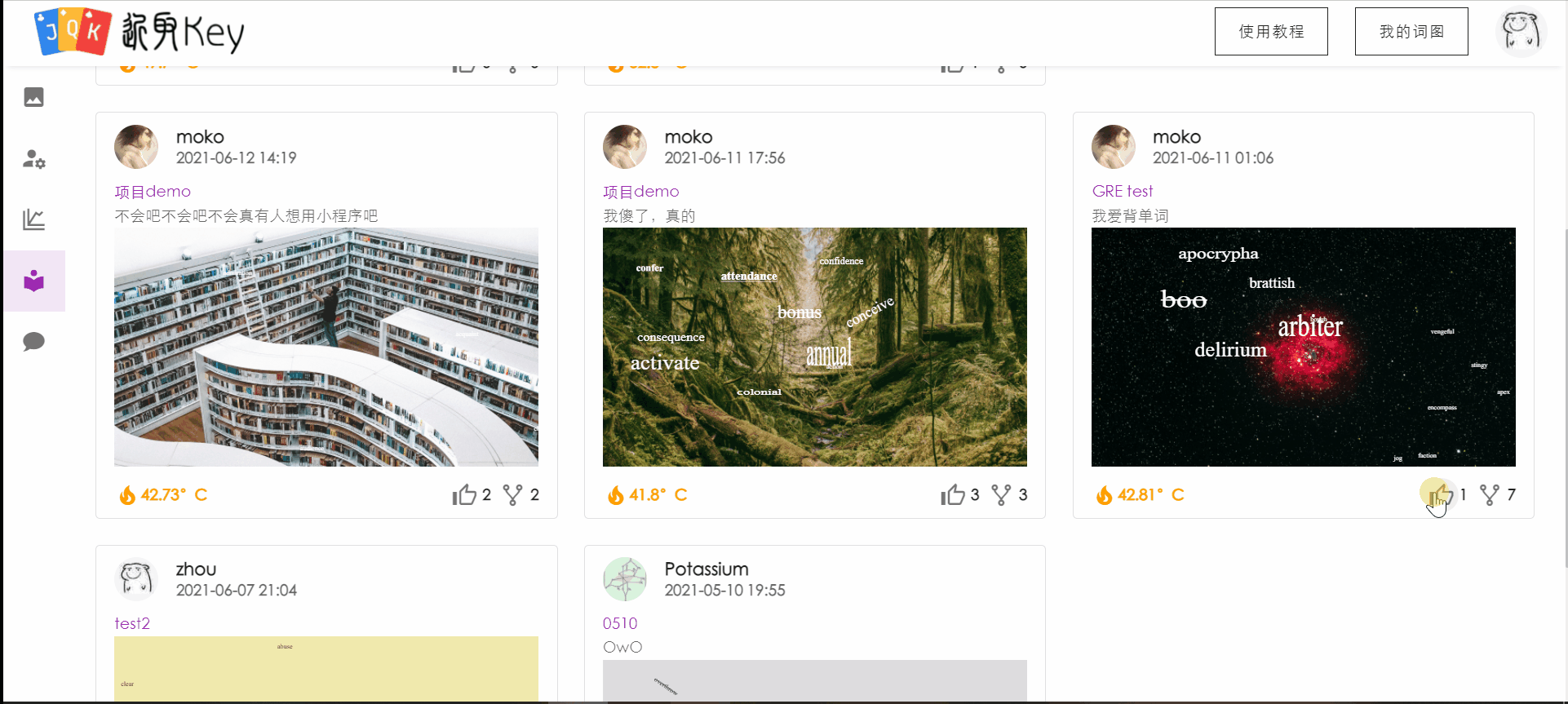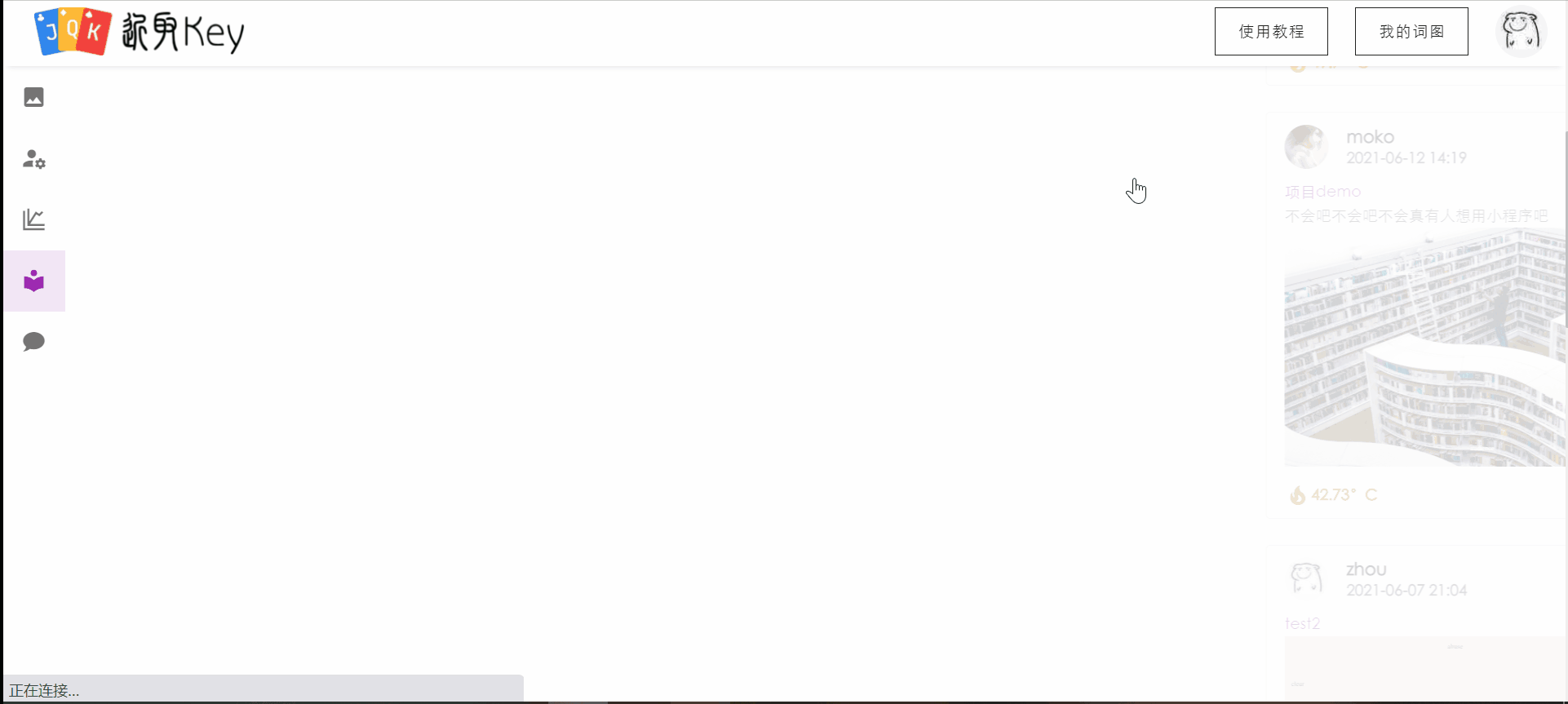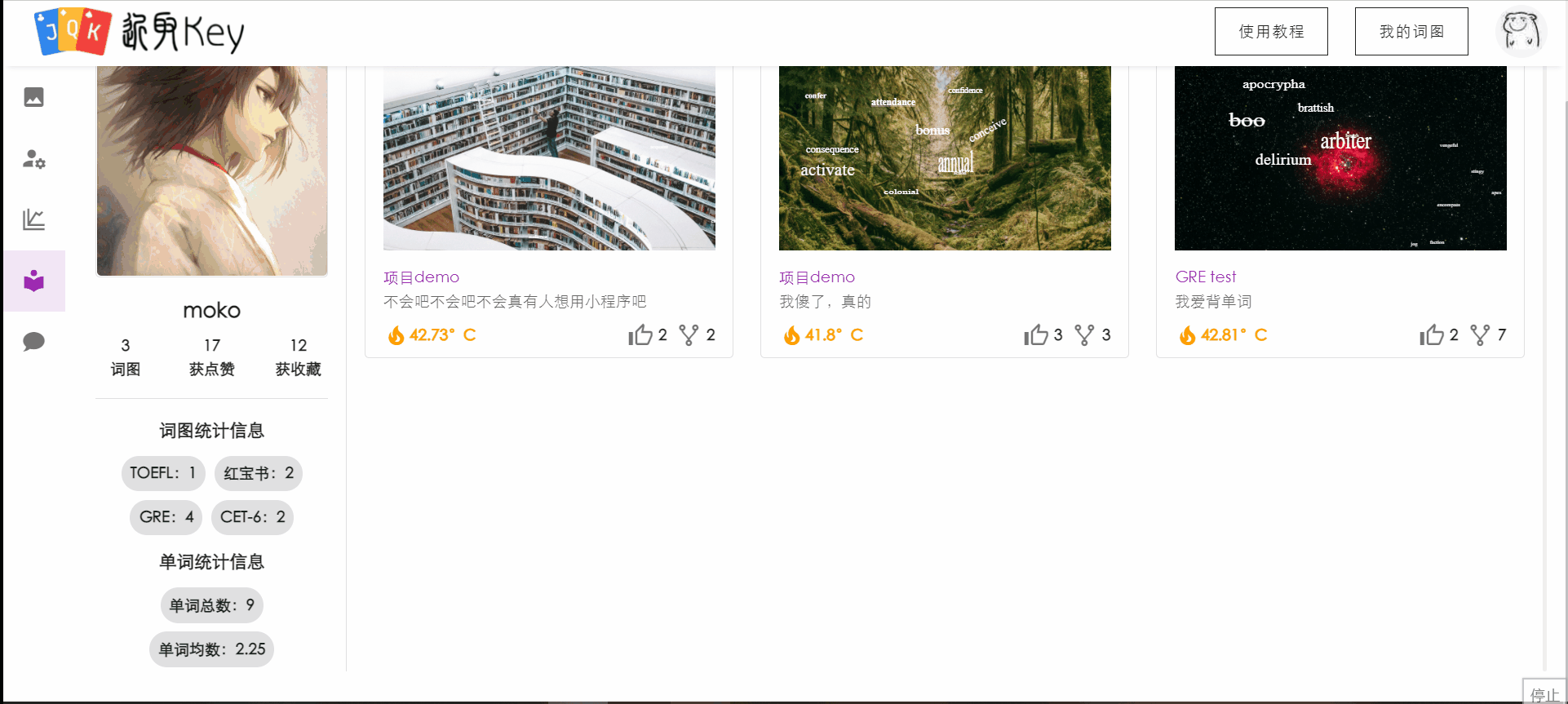
社区
功能特性详述
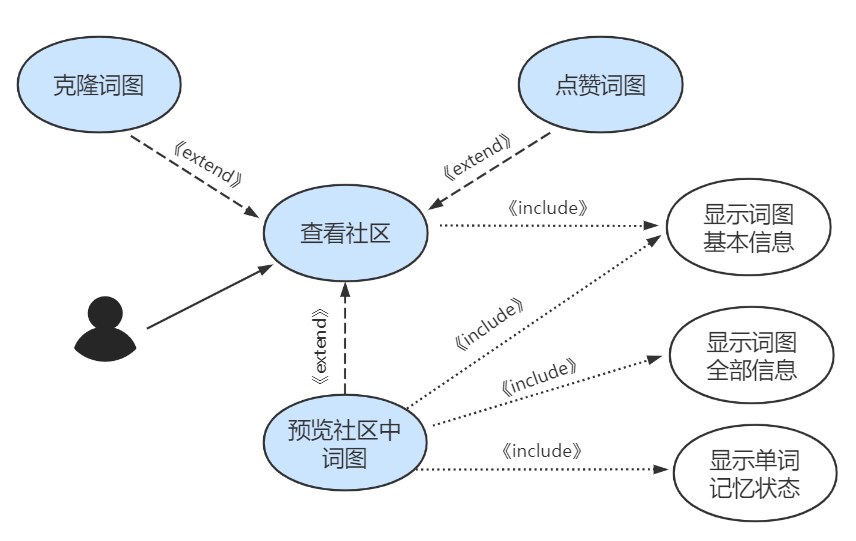
新增社区功能。用户可以在社区中查看其他用户公开的已完成词图,查看某用户的详细信息(包括点赞数量、宏观背词状态等)。
针对感兴趣的词图,用户可以进入预览,查看词图的全貌和自己对该词图中单词的掌握状态。
对于喜欢的词图,用户可以将其克隆到自己的词图中,并且对齐进行加词或编辑。
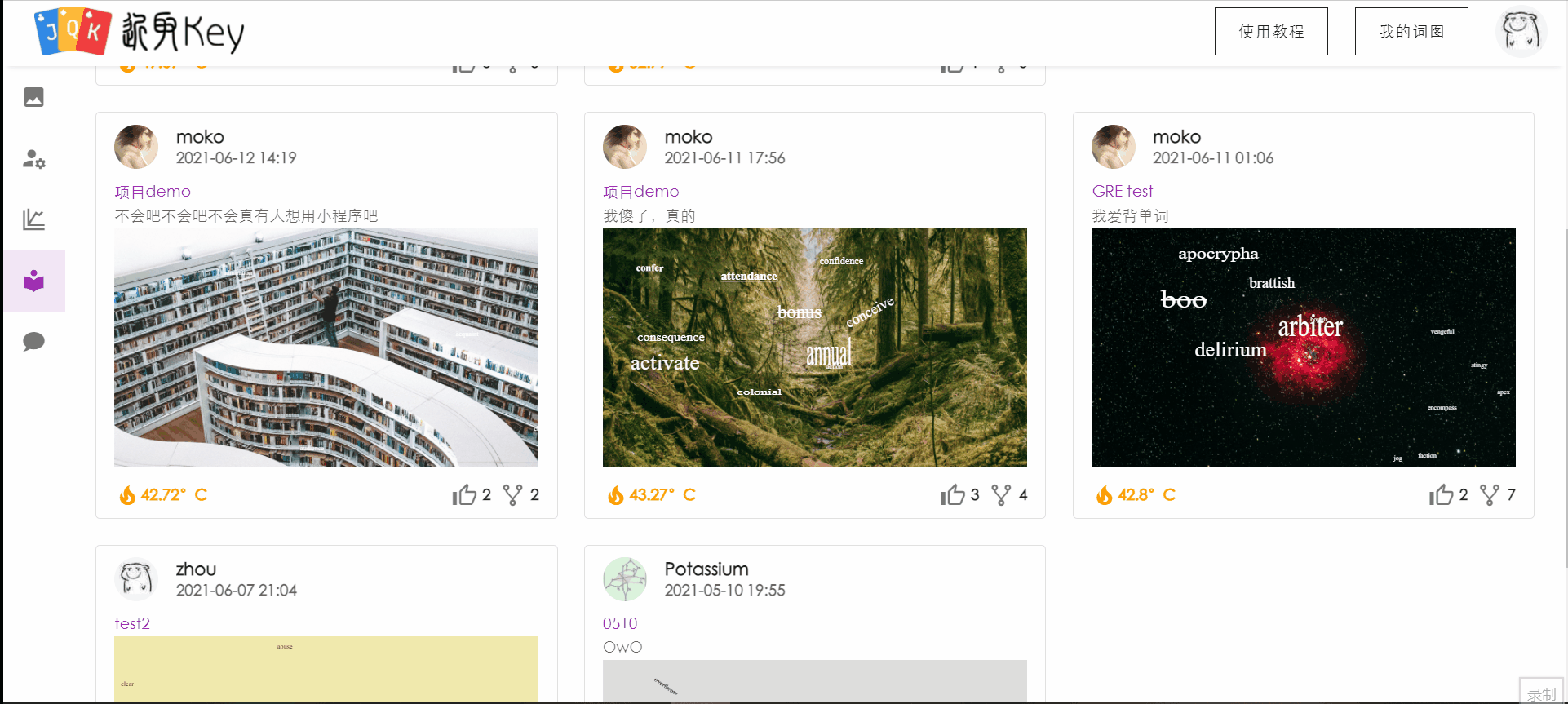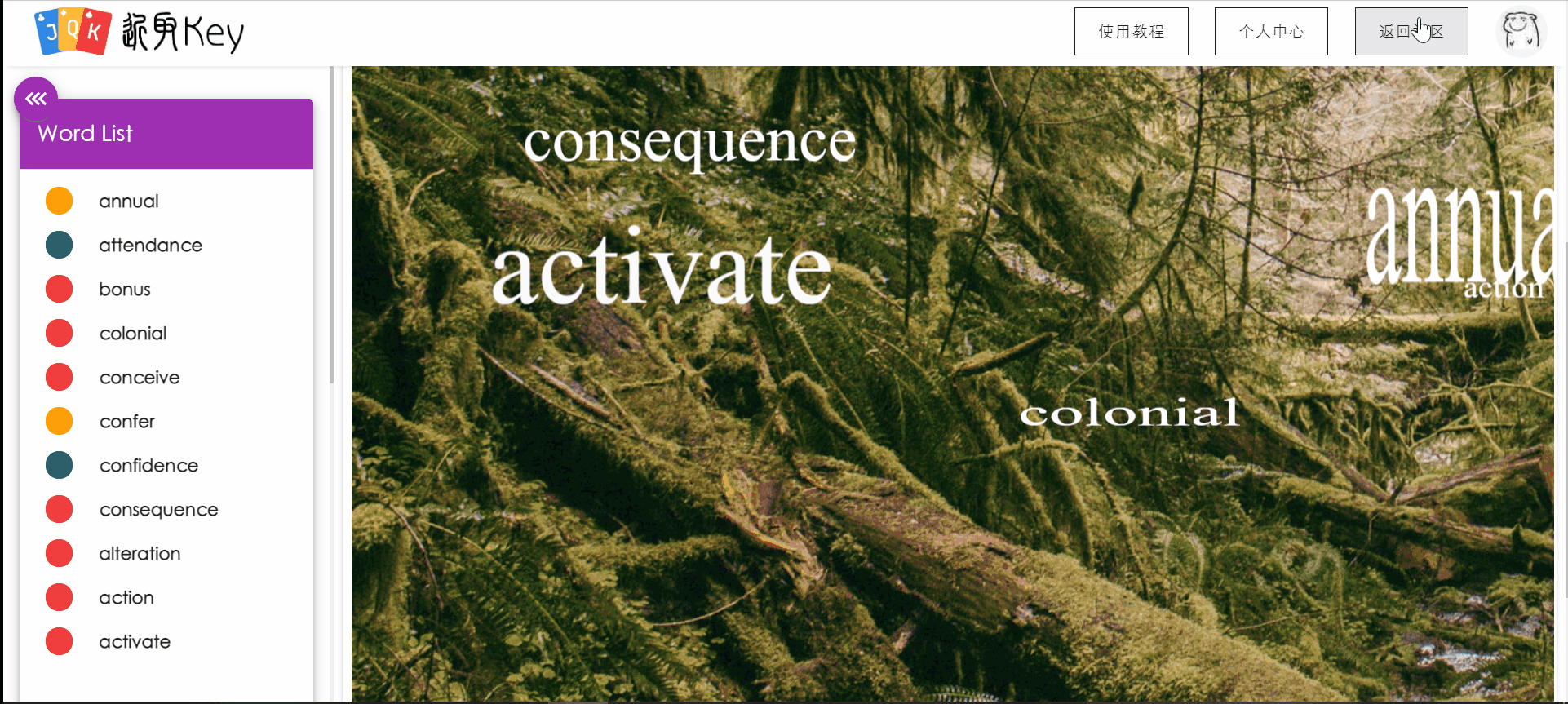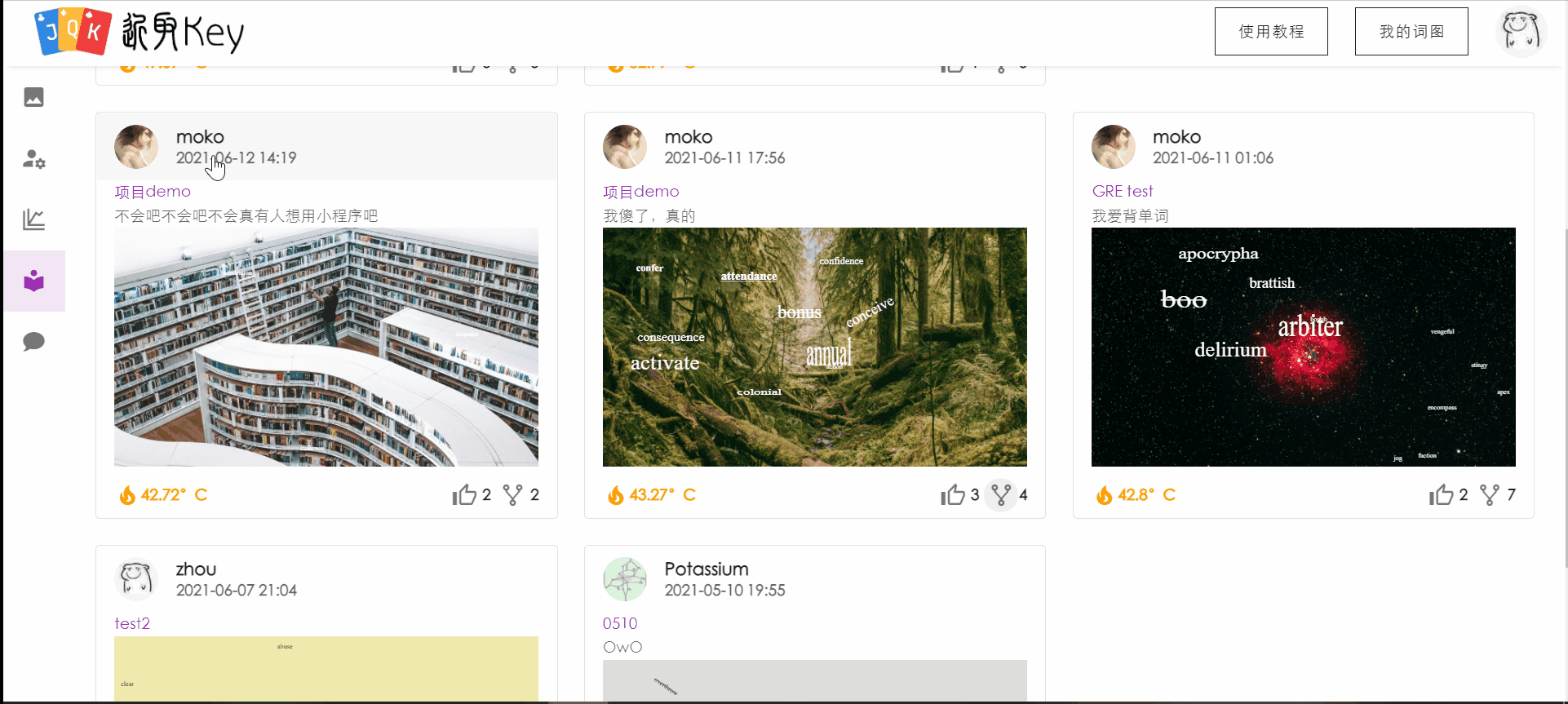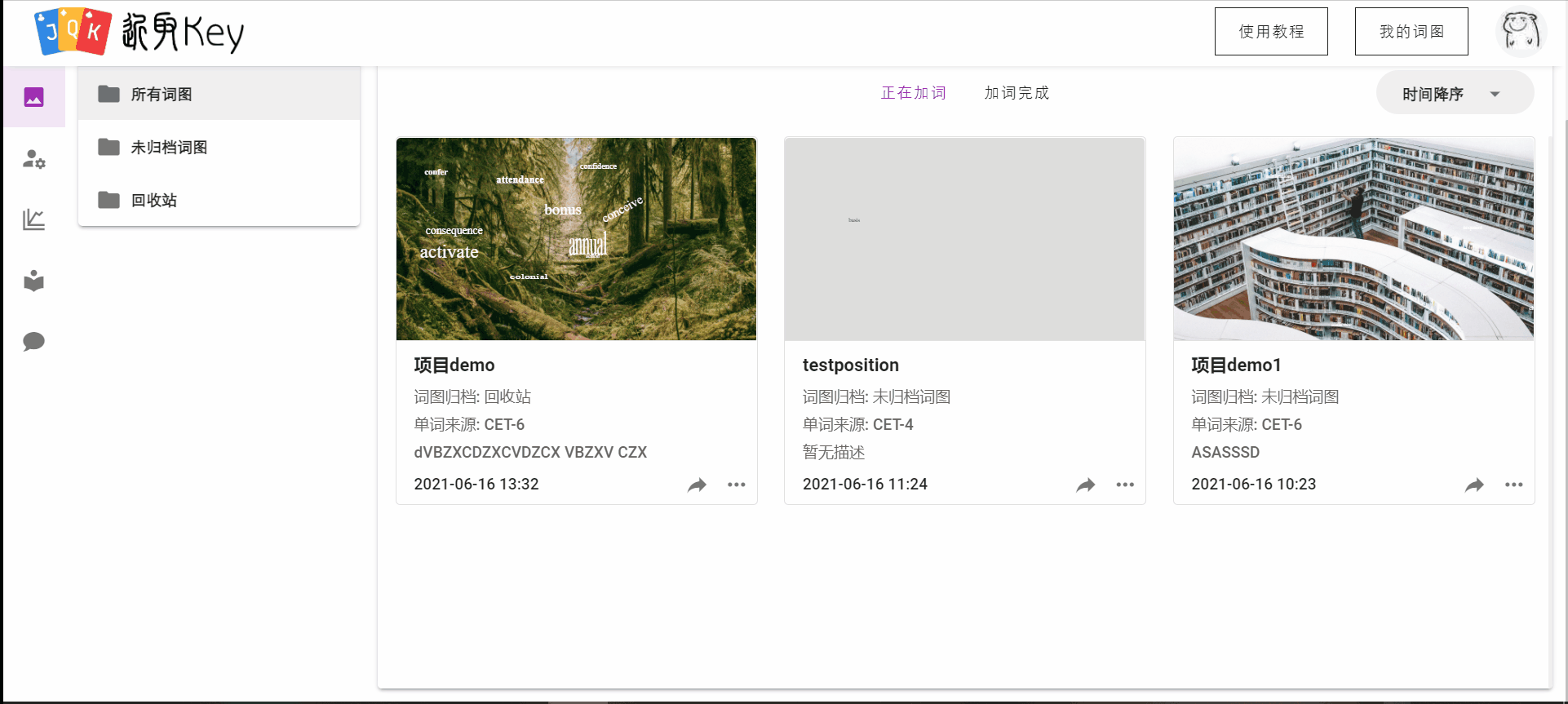
用户在社区中的操作用例图如下:
个人设置
在个人设置中,用户可以上传大小不超过100KB的头像,并可以对新建词图、测试词图模块的默认设置进行设定。
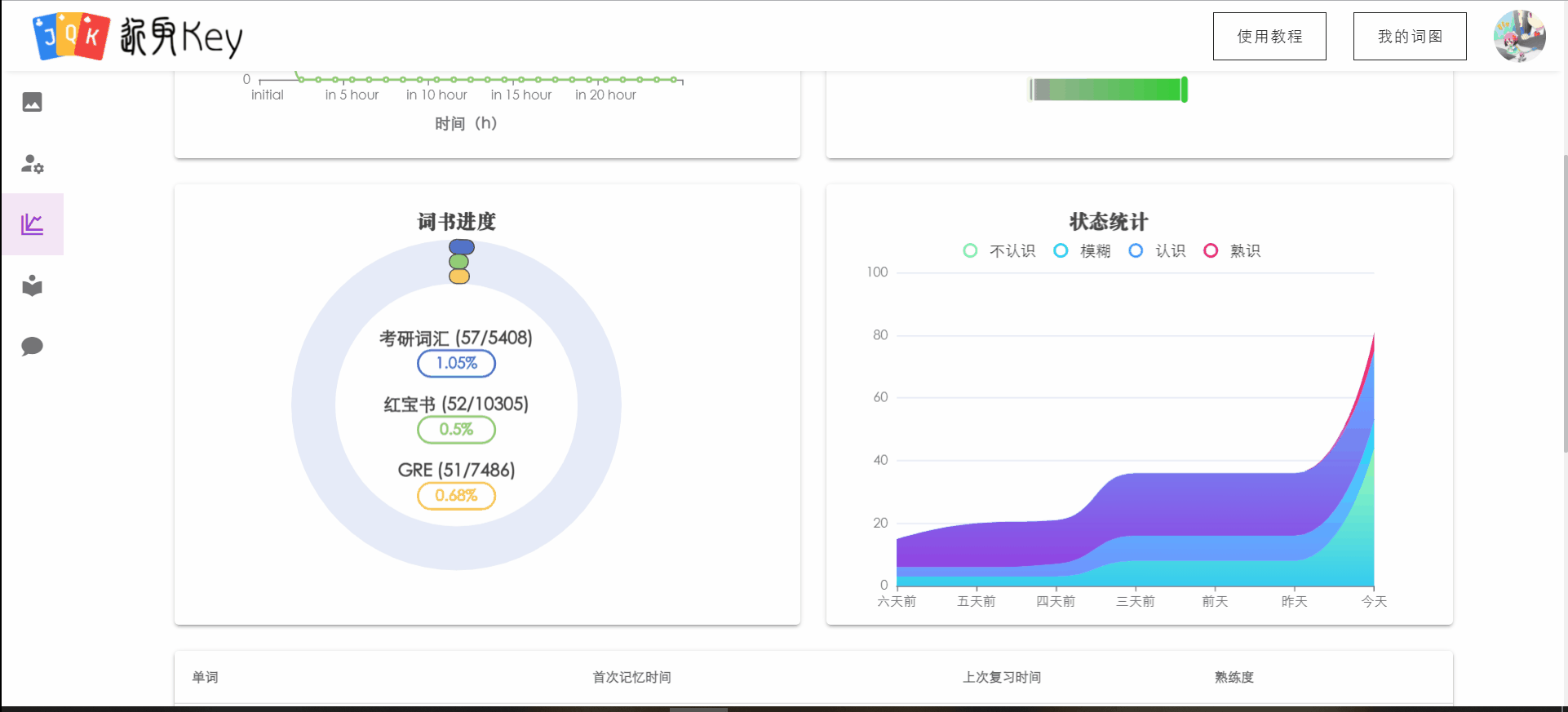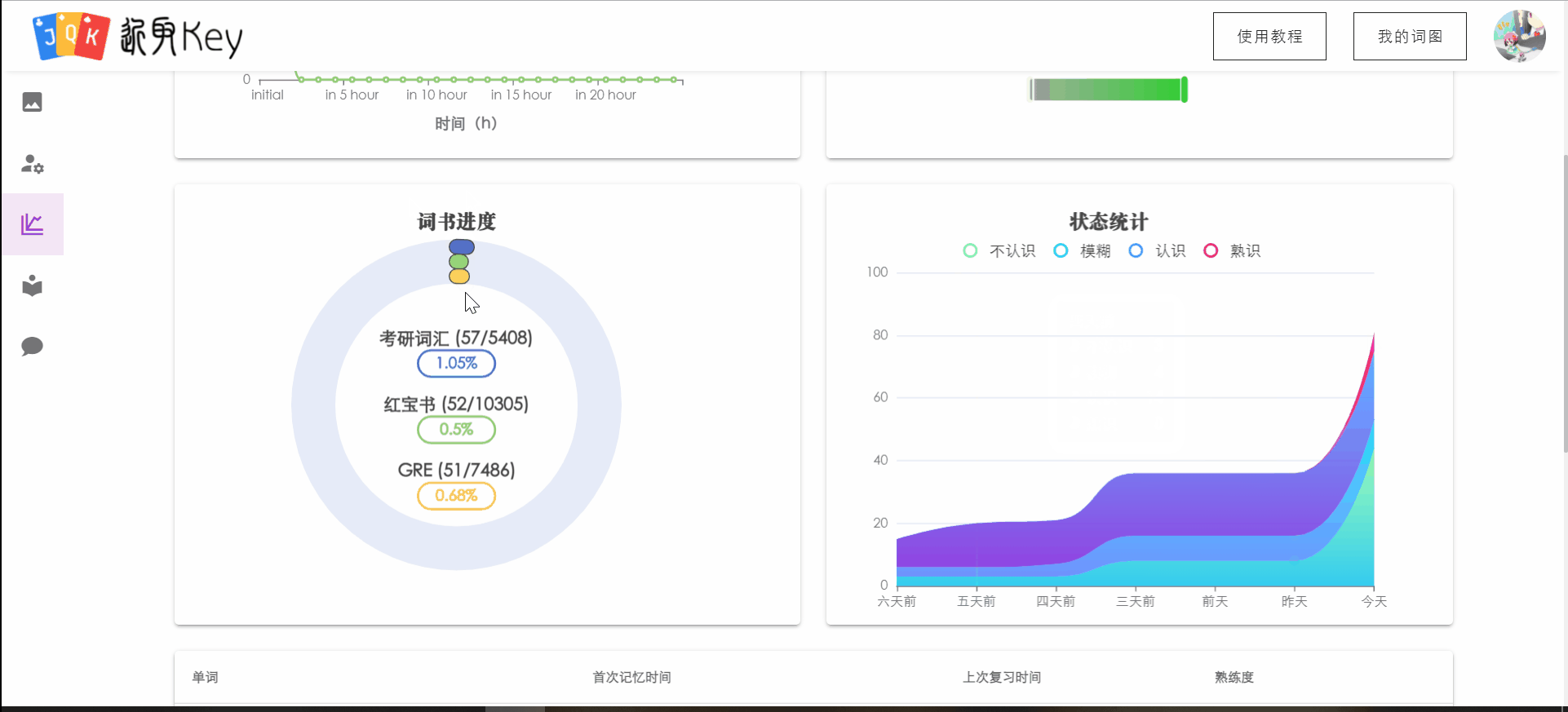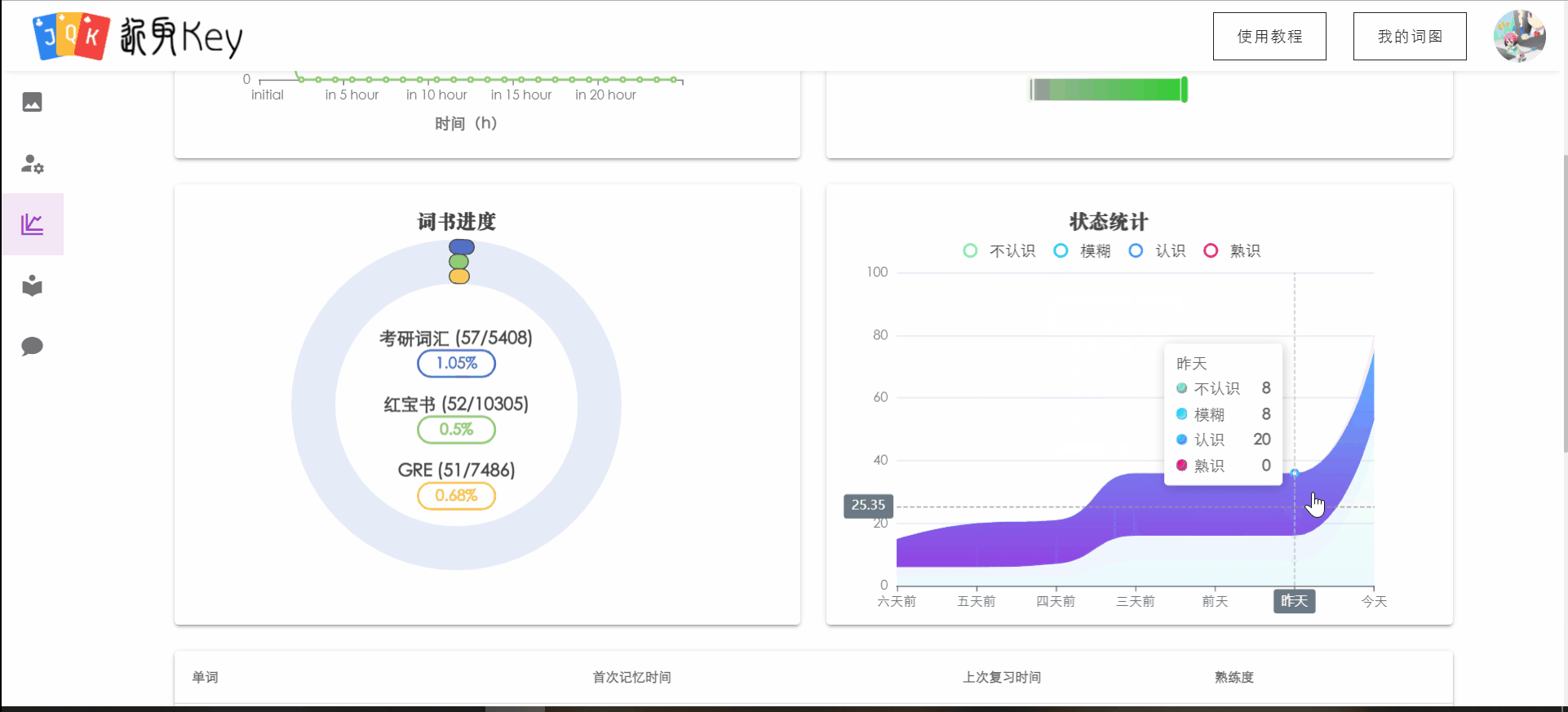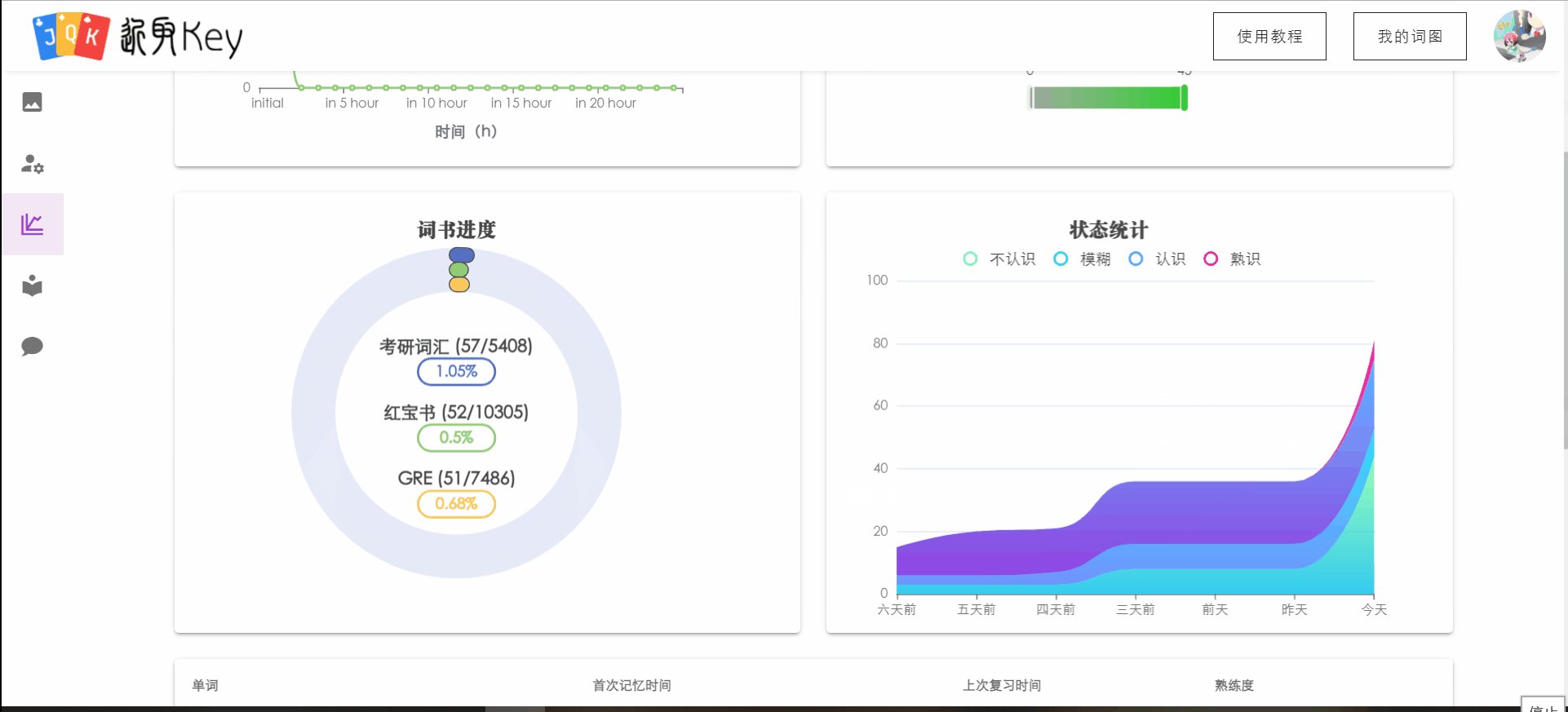
统计信息
统计信息界面新增了用户背诵的当前词书的背词进度(比例),以及用户对已经背诵的单词的总体状态。
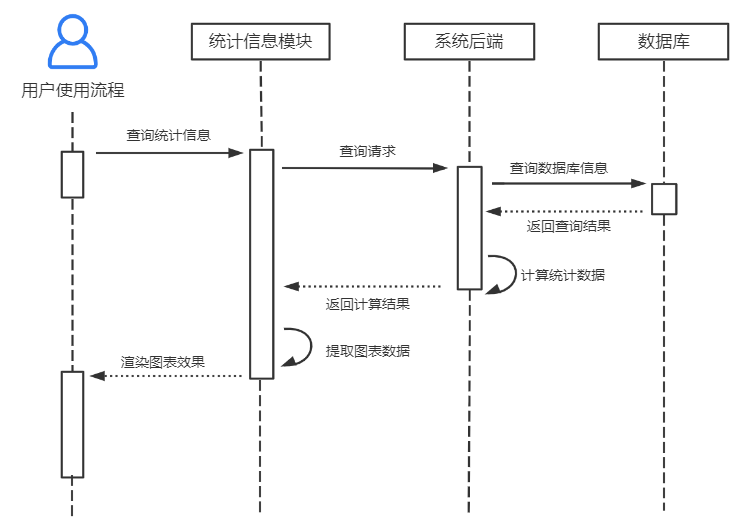
用户访问统计信息时的时序图如下:
自定义搜索加词
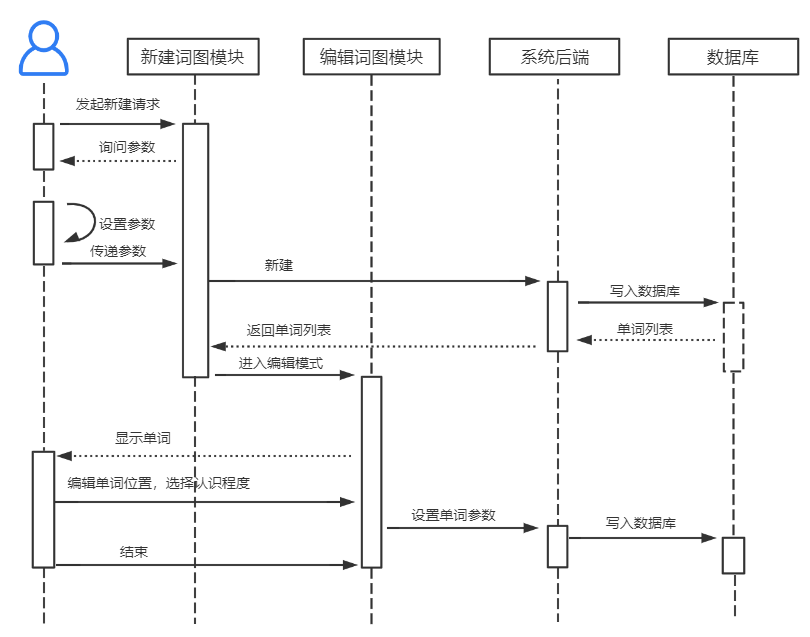
在编辑词图时,用户可以通过搜索加入自己想要自定义加入的单词。被选中的单词讲自动添加到待背诵列表的首位。
用户在新建、编辑词图时的时序图如下:
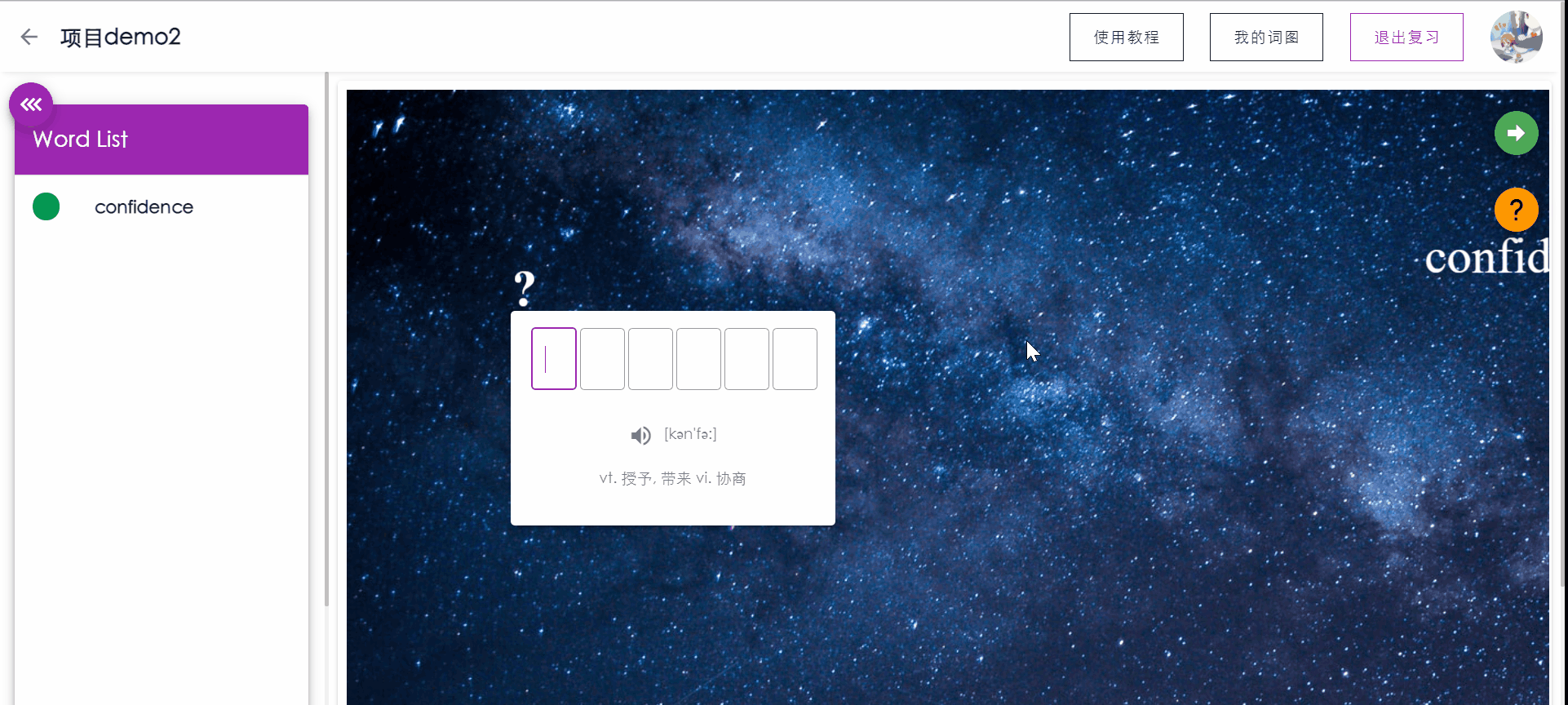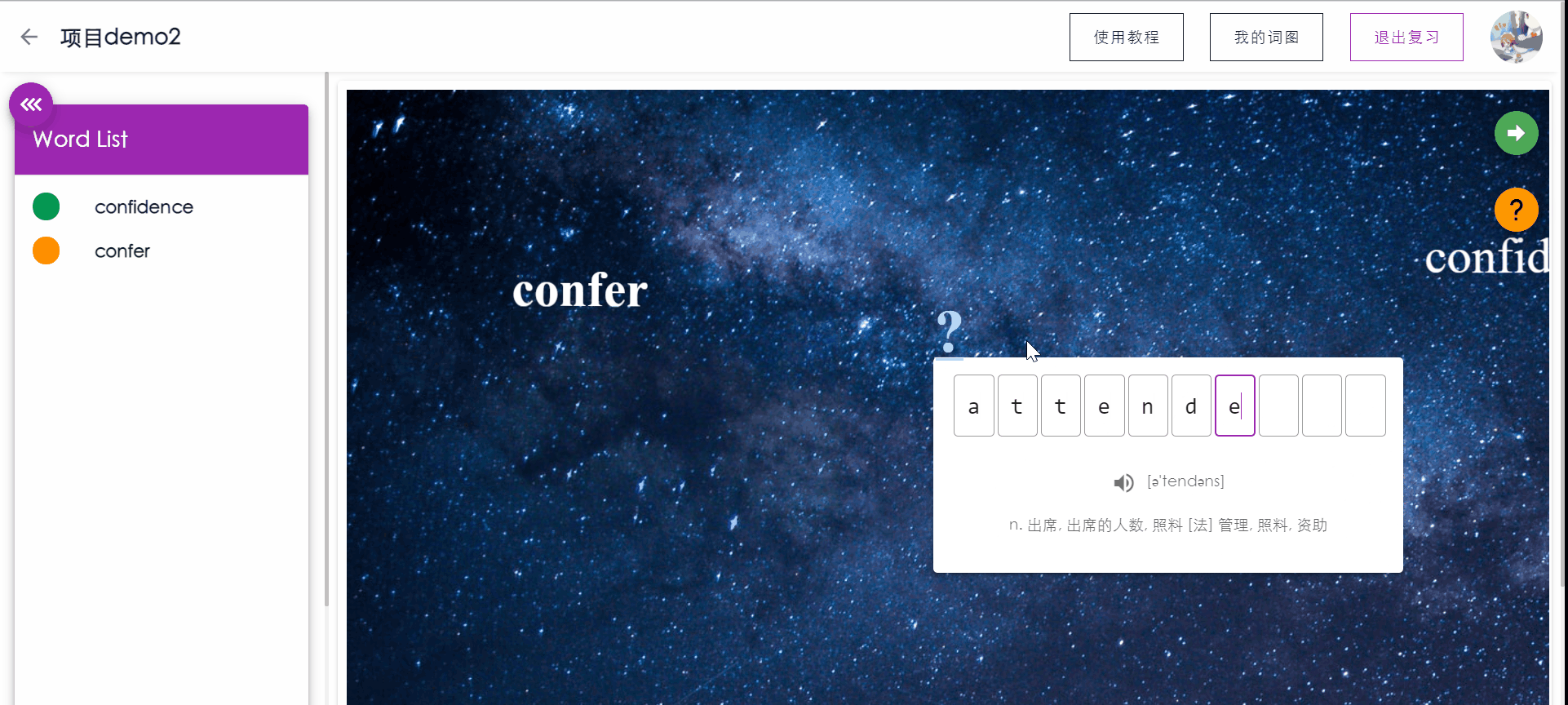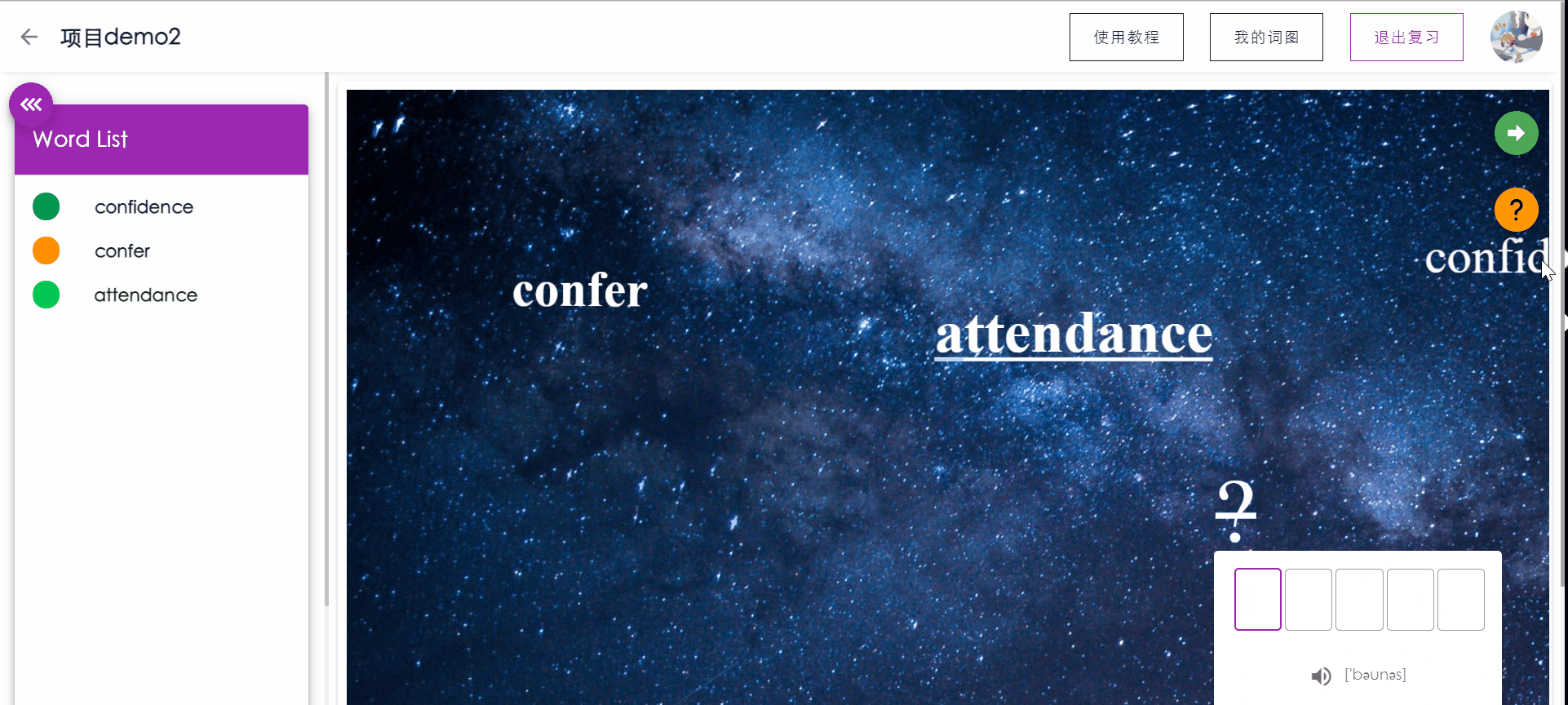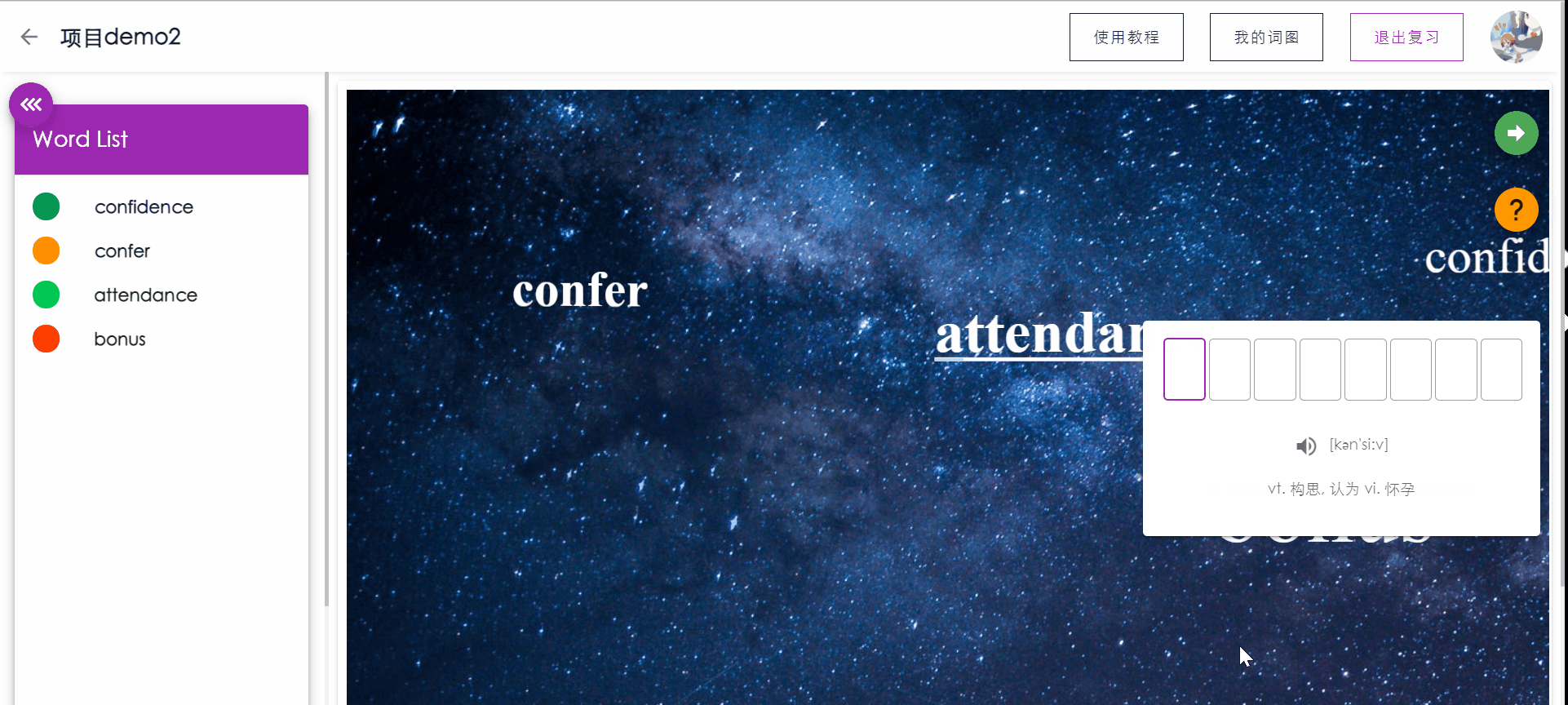
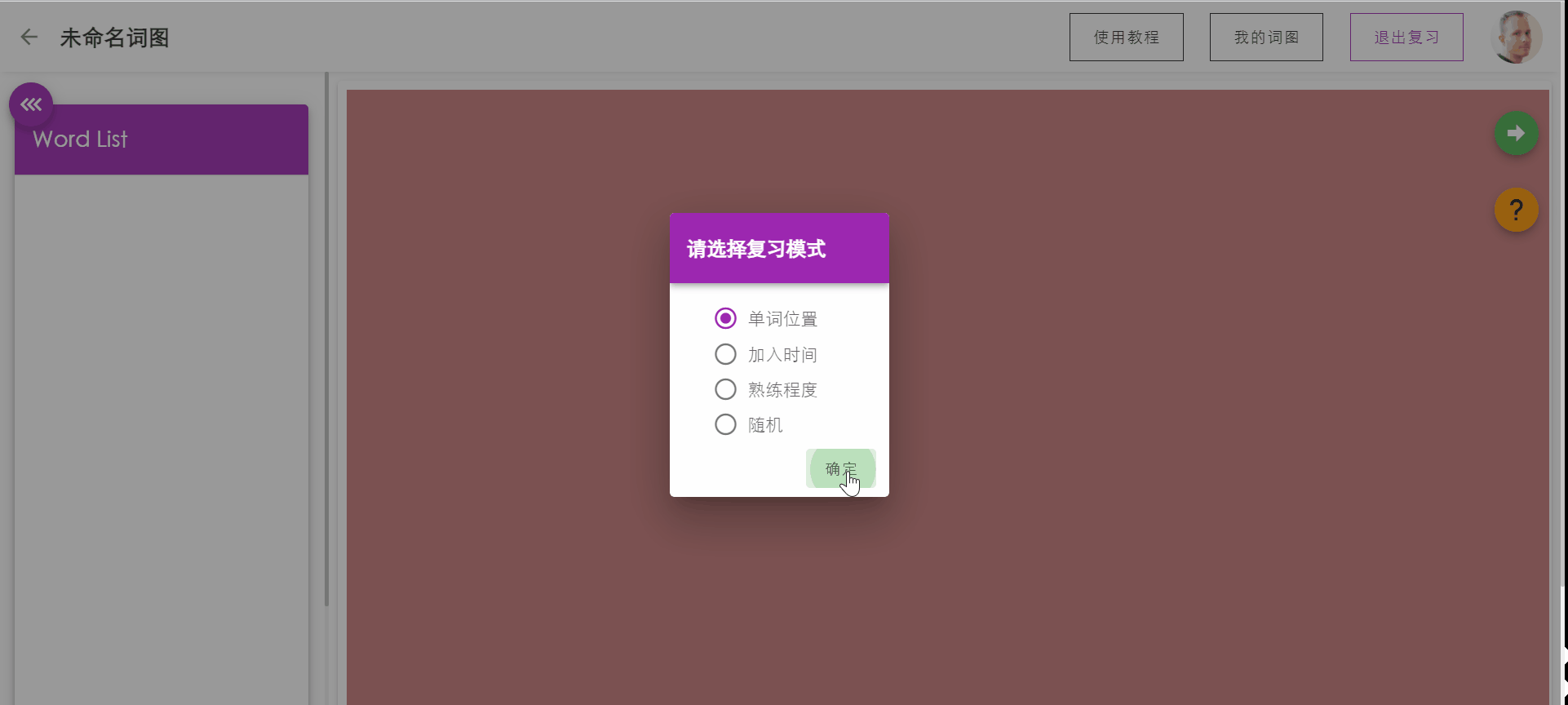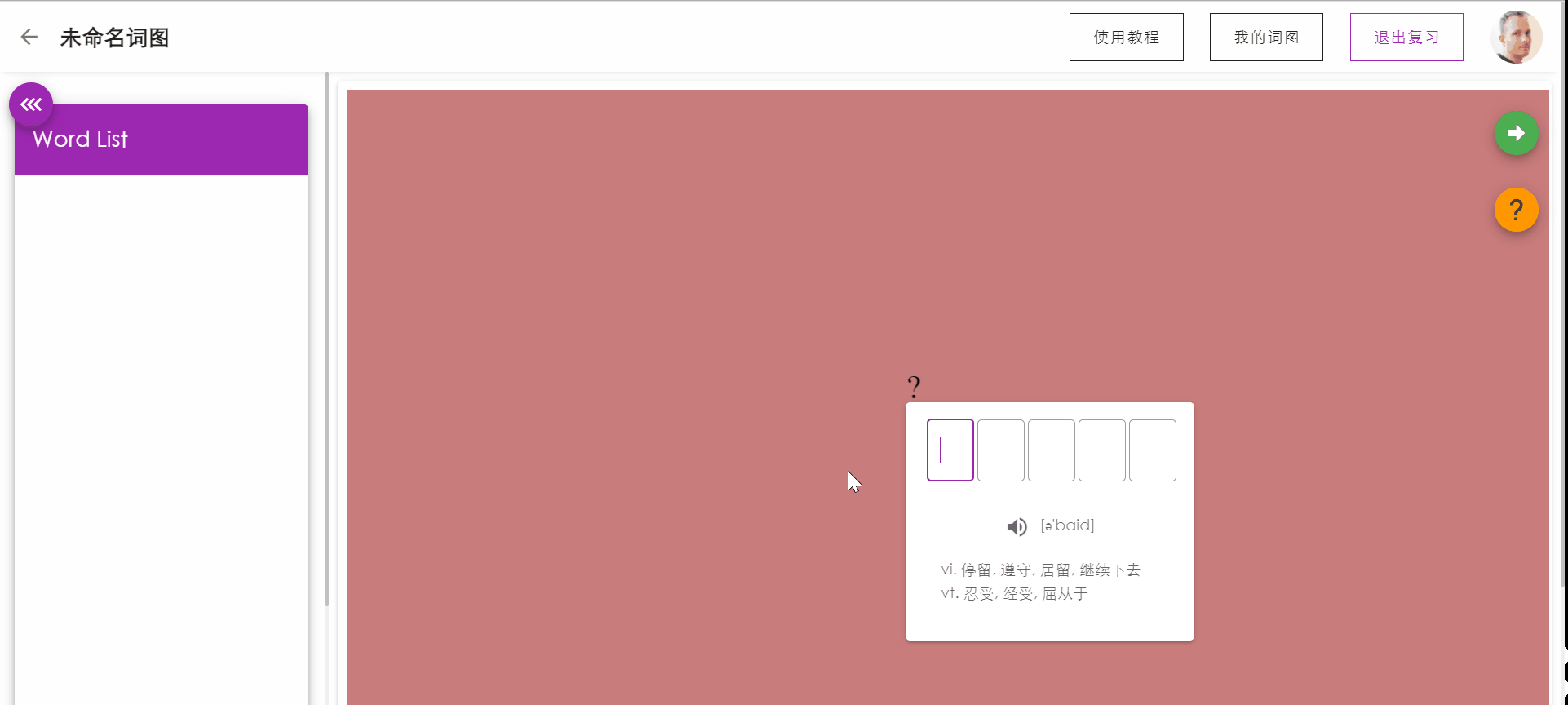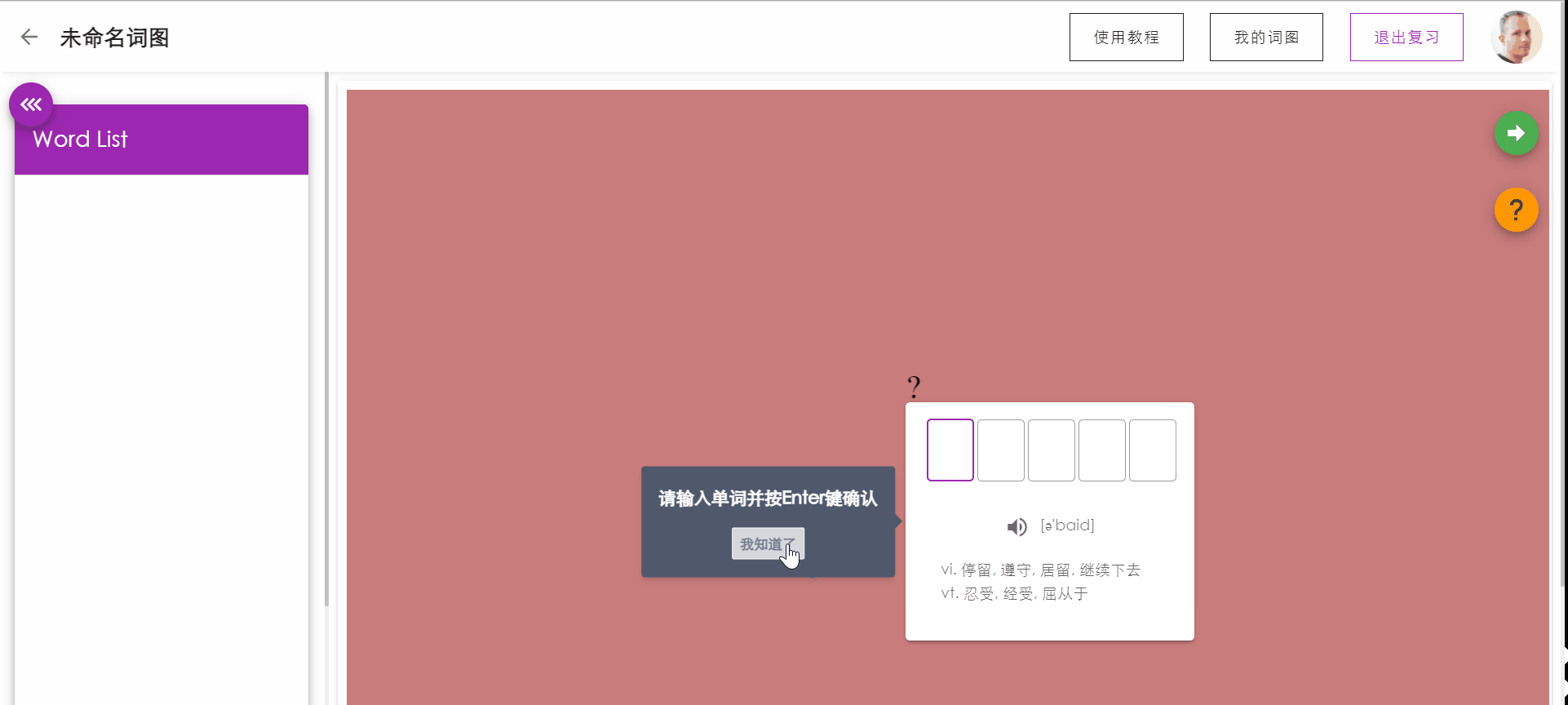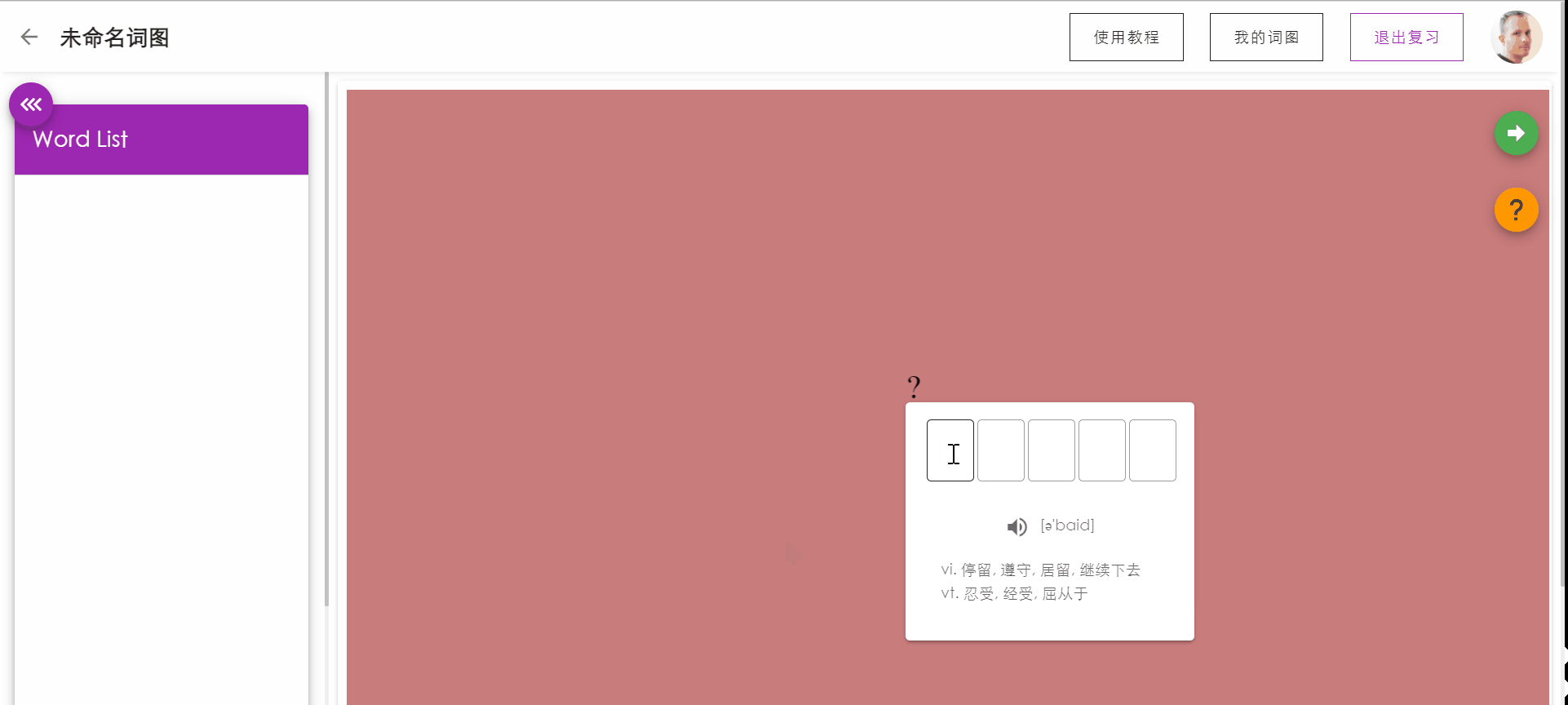
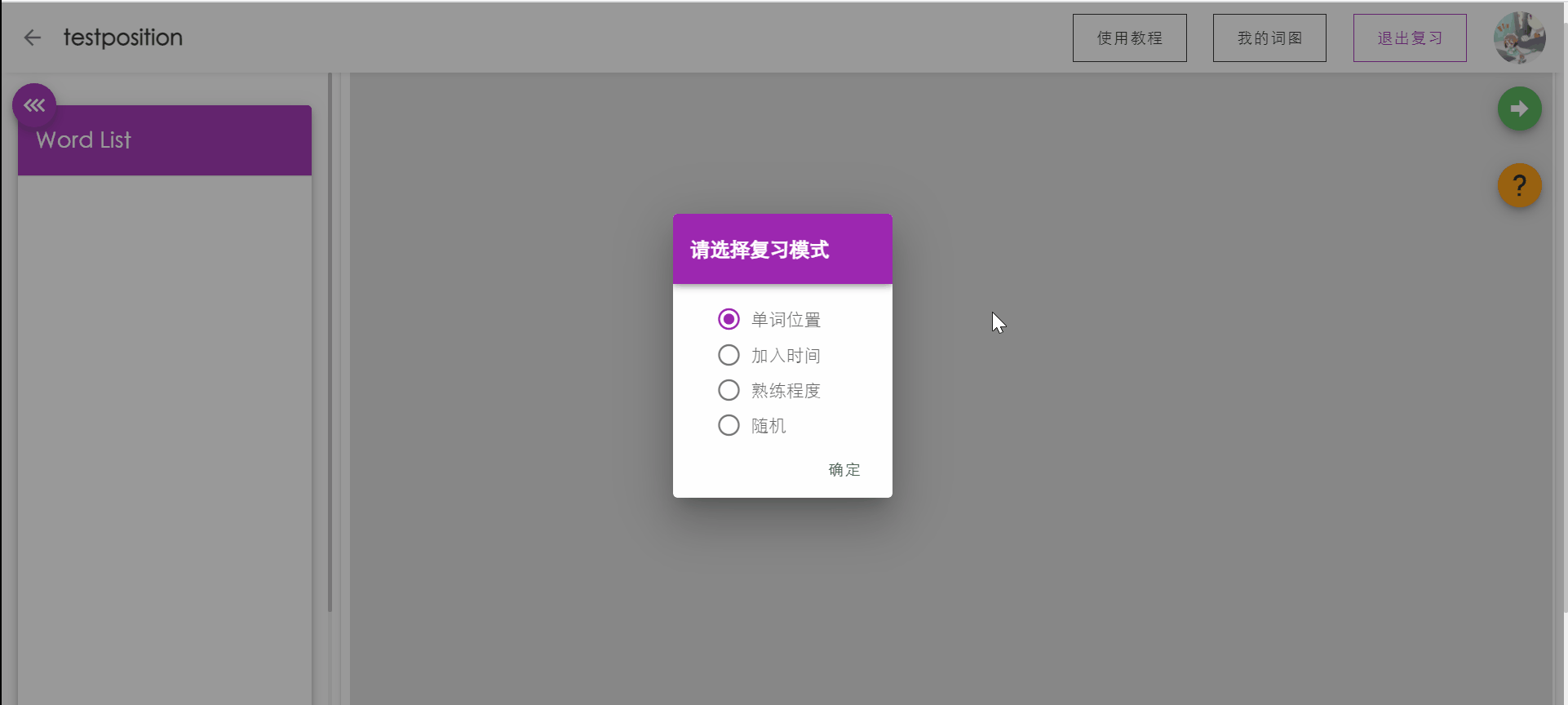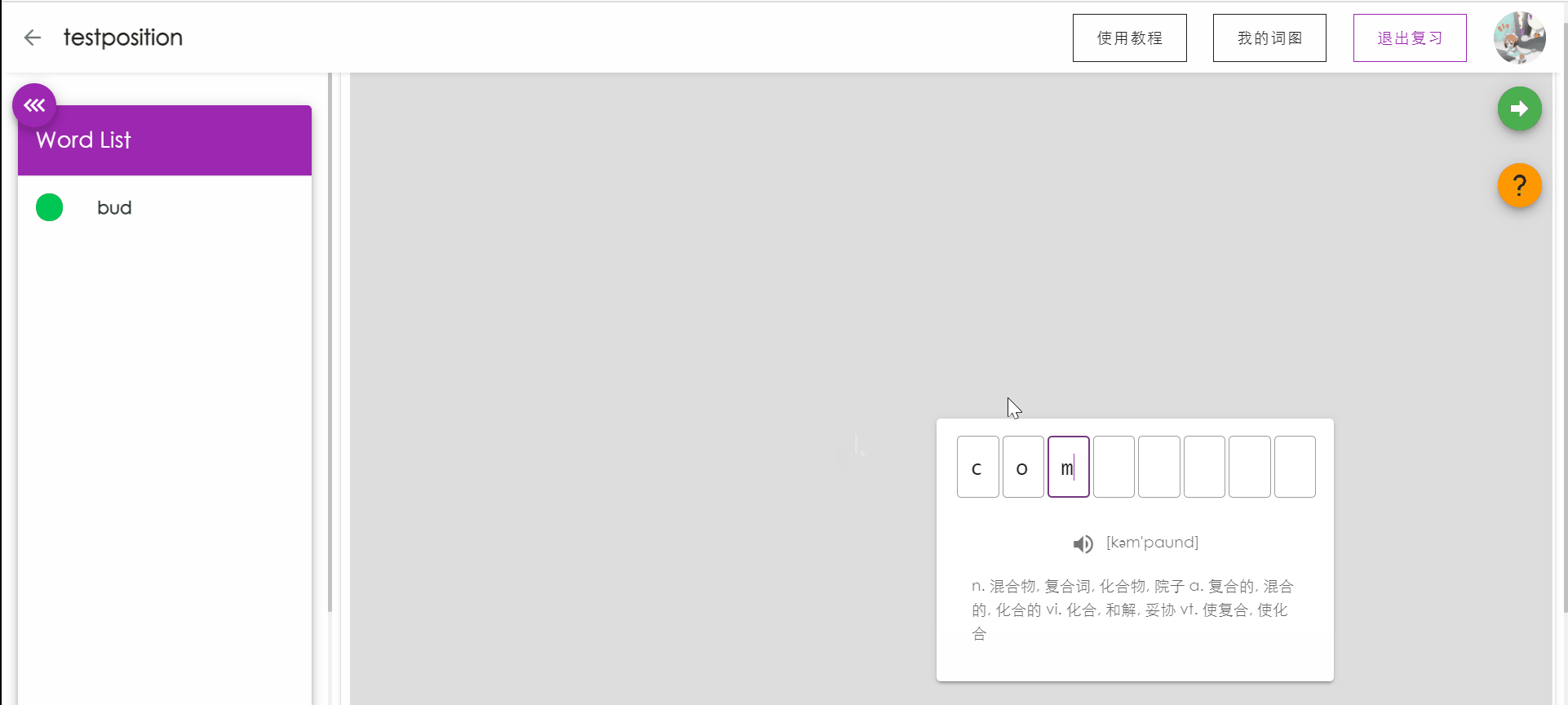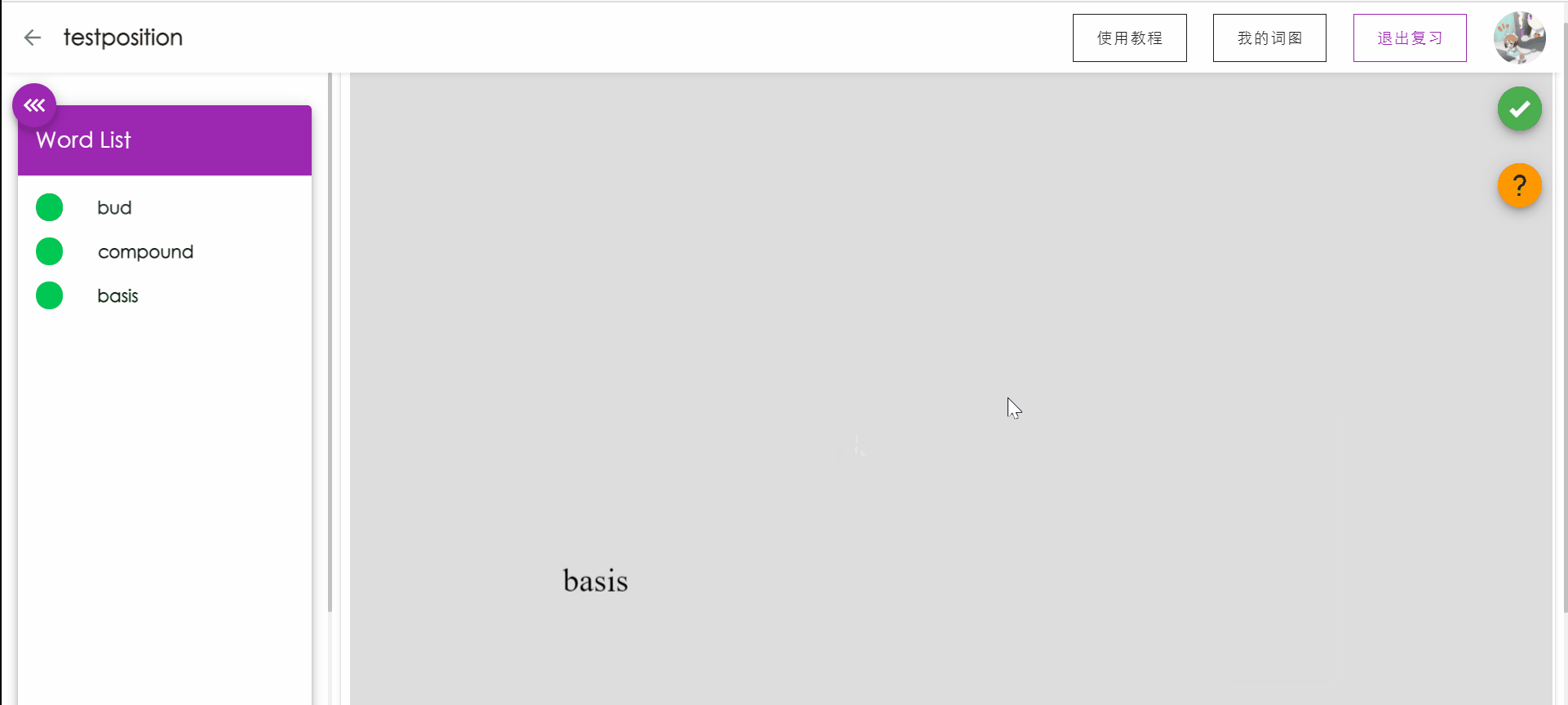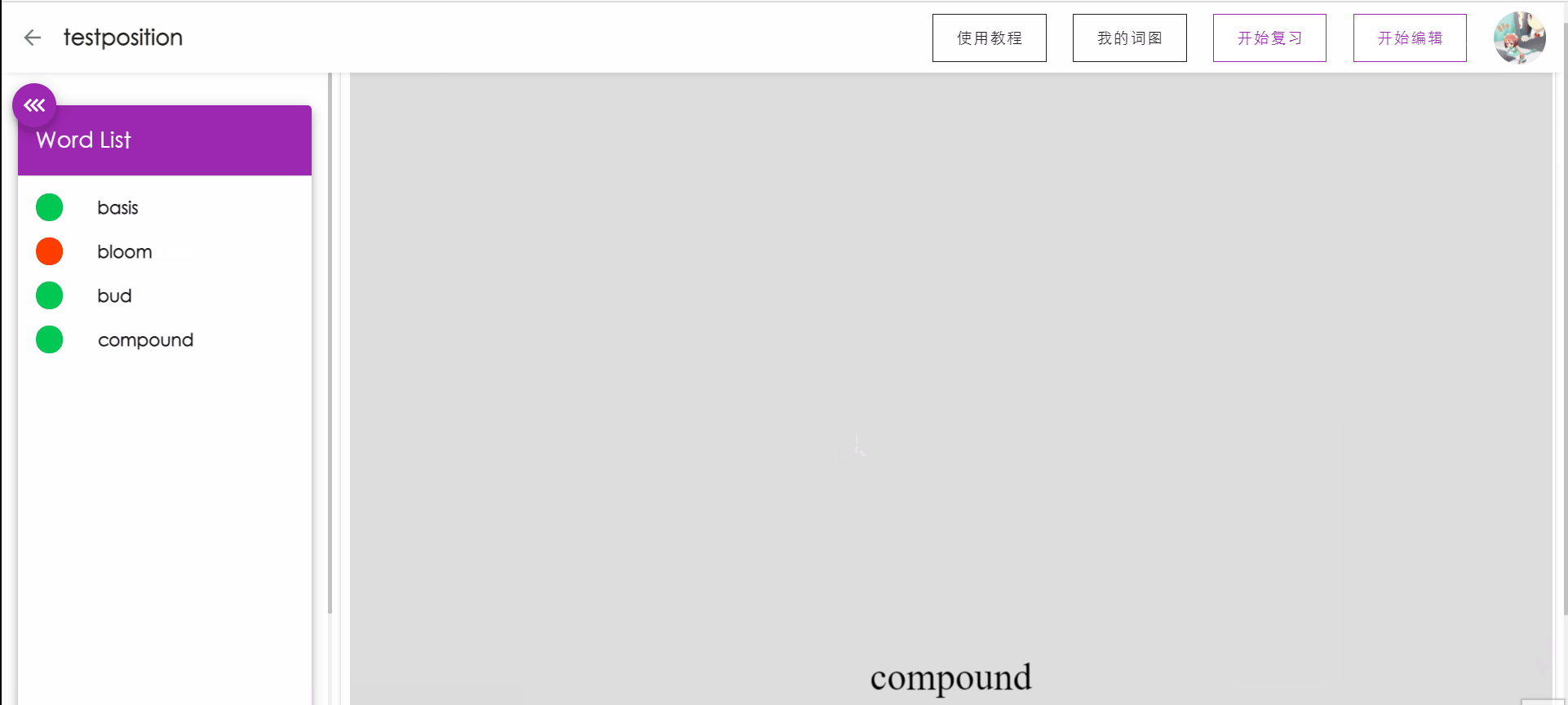
复习单词测试
PC端拥有键盘的优越性,让用户可以通过敲入要复习的单词来强化记忆,同时系统会根据用户的敲入状态更新用户对本单词的记忆状态。
如果敲入单词正确,按下回车后将显示单词的含义,再次按下回车将自动跳转到下一个单词。
如果敲入错误,按下回车后系统将对错误的字母进行提示(方框标红),用户可以通过backspace进行顺滑的删除修改。如果用户忘记单词的拼写,可以点击提示,将展示单词的。
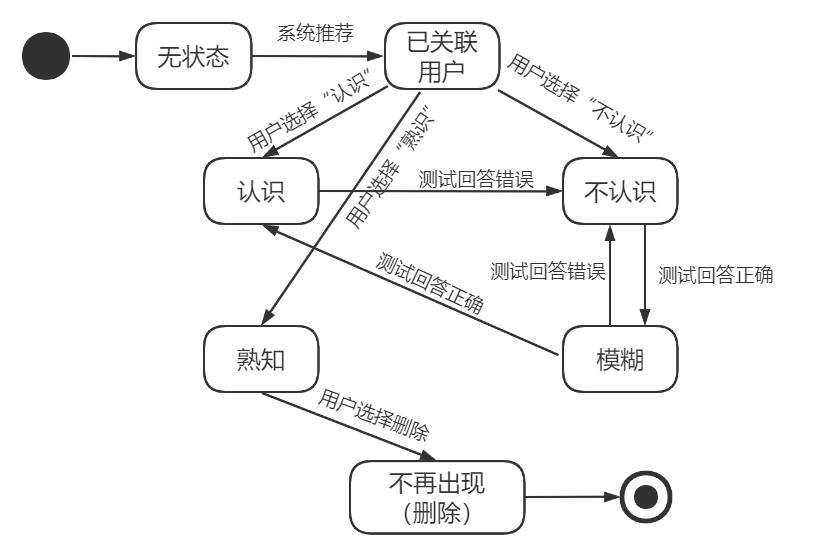
侧边栏将实时显示已复习单词的记忆状态。
用户对某一单词的记忆状态机如下:
词图背景图及复位
新增词图设置背景图片功能。用户可以通过工具栏选择心仪的背景图片,并在此之上完成词图的构建。每次重新进入编辑页面,背景图库将更新。
对于由于zoom和拖拽导致的词图位置偏移,用户可以点击工具栏的复位按钮回归默认视觉中心位置。
删除单词
用户可以选中词图中已有的单词,点击工具栏中的删除按钮移除单词。
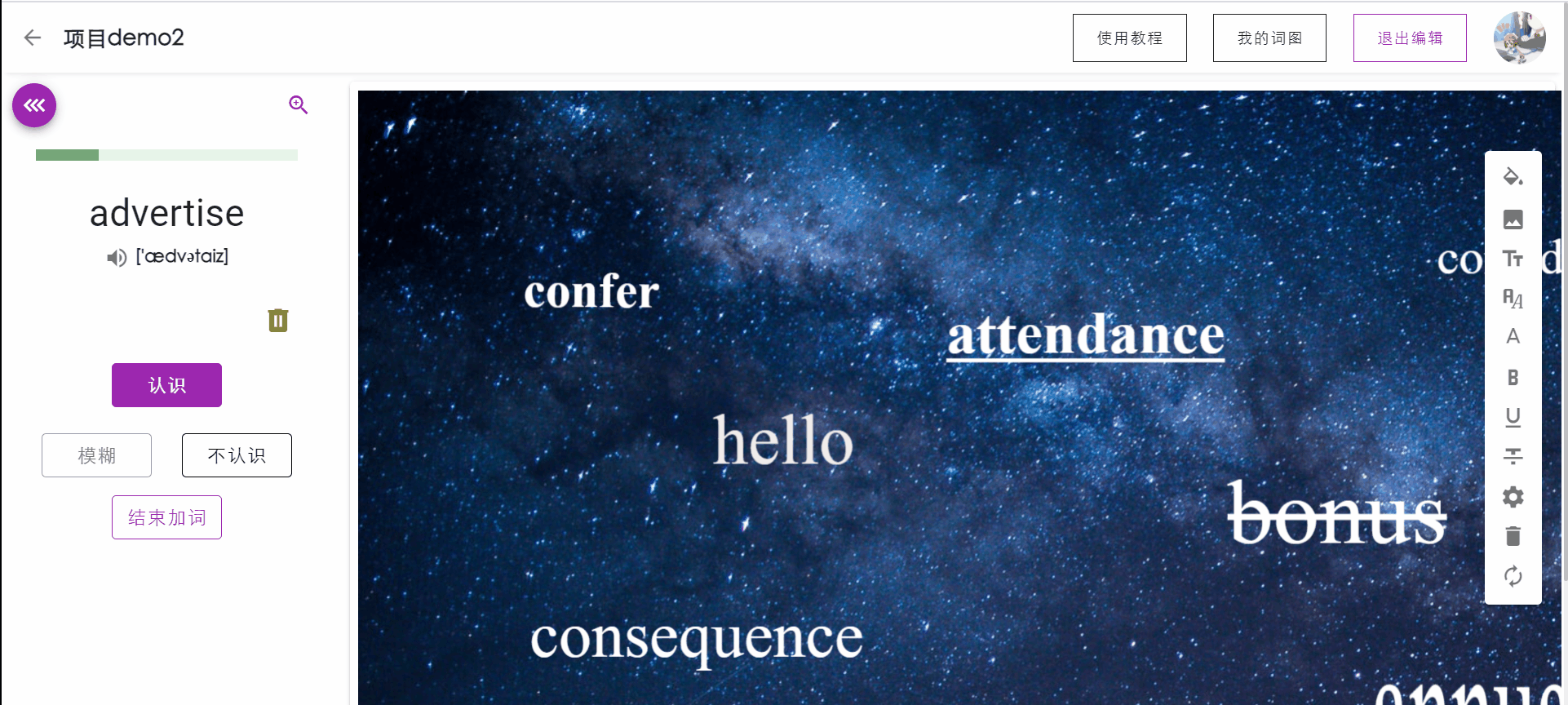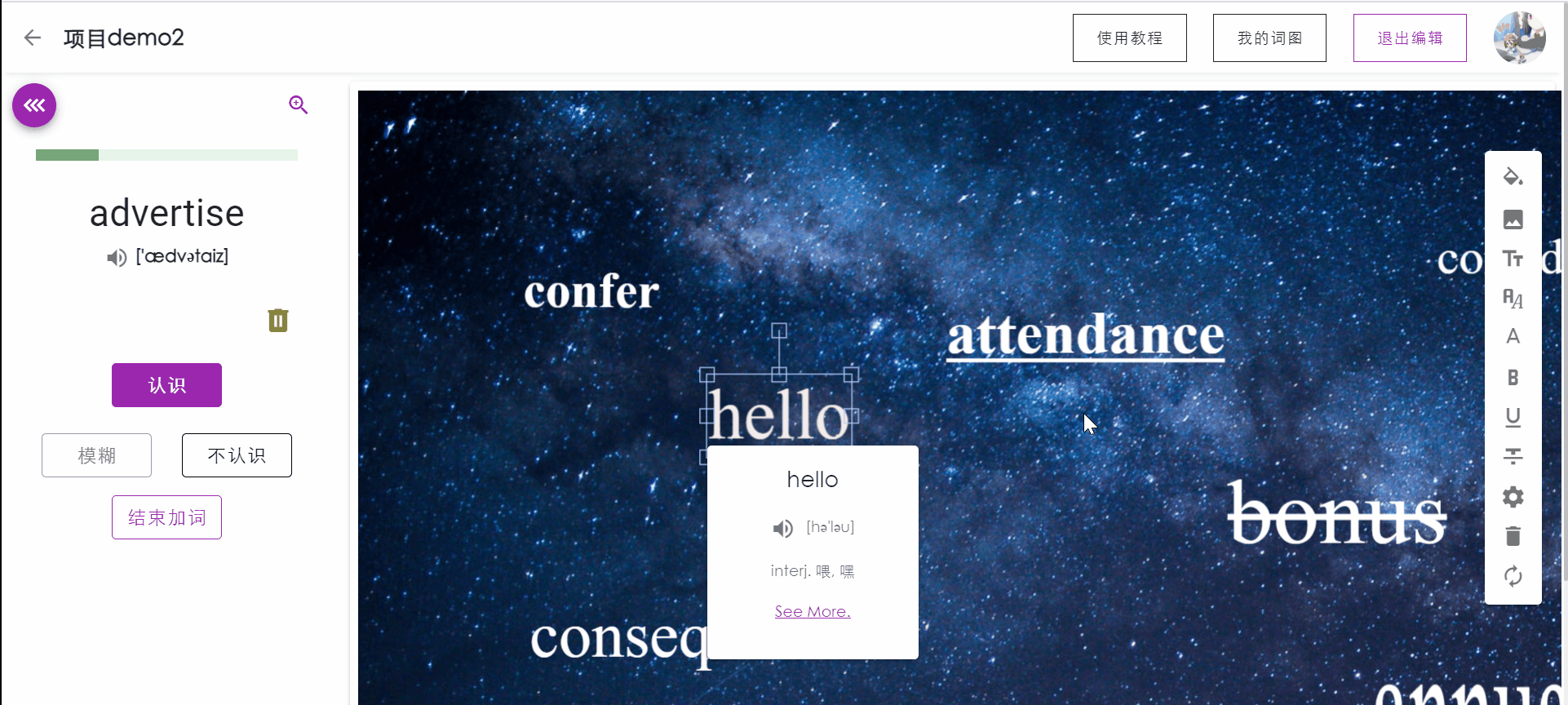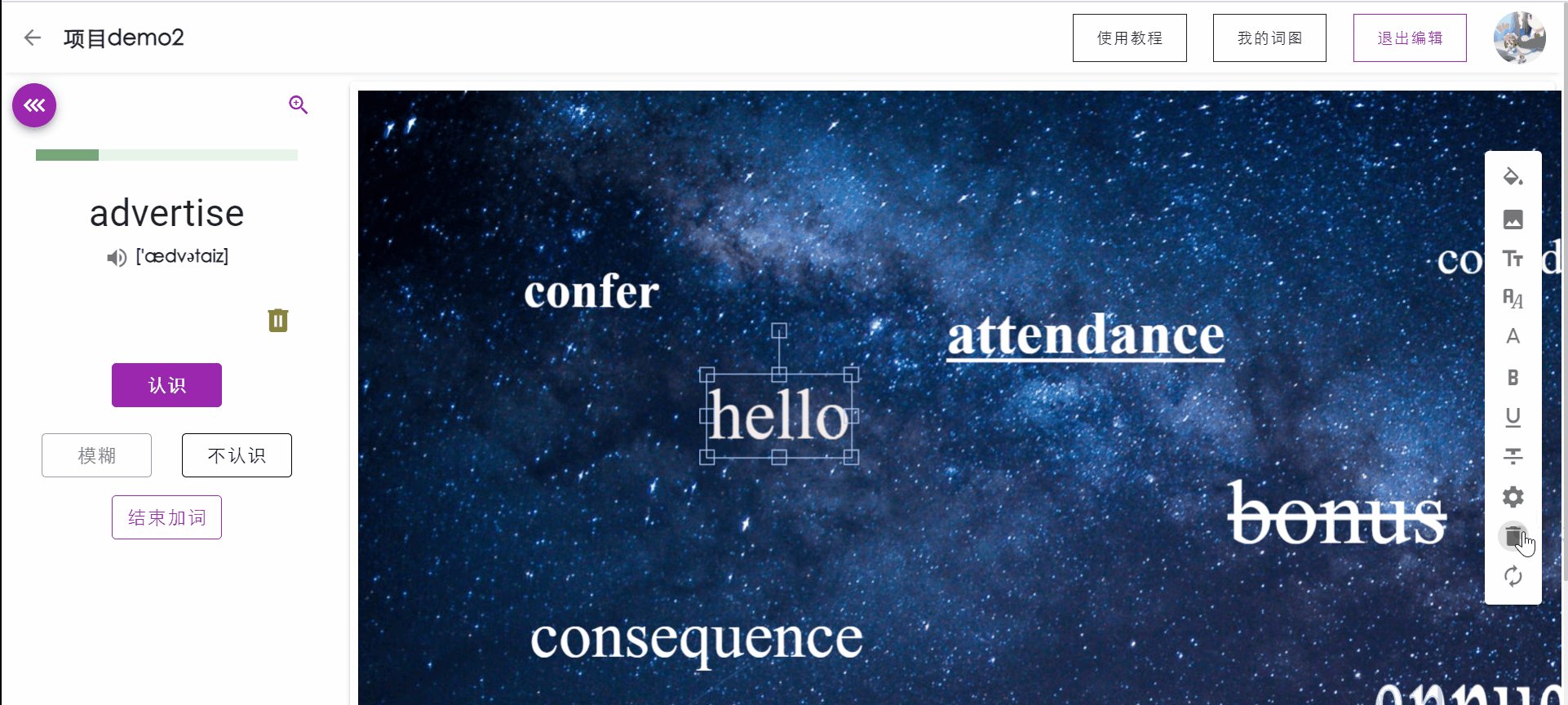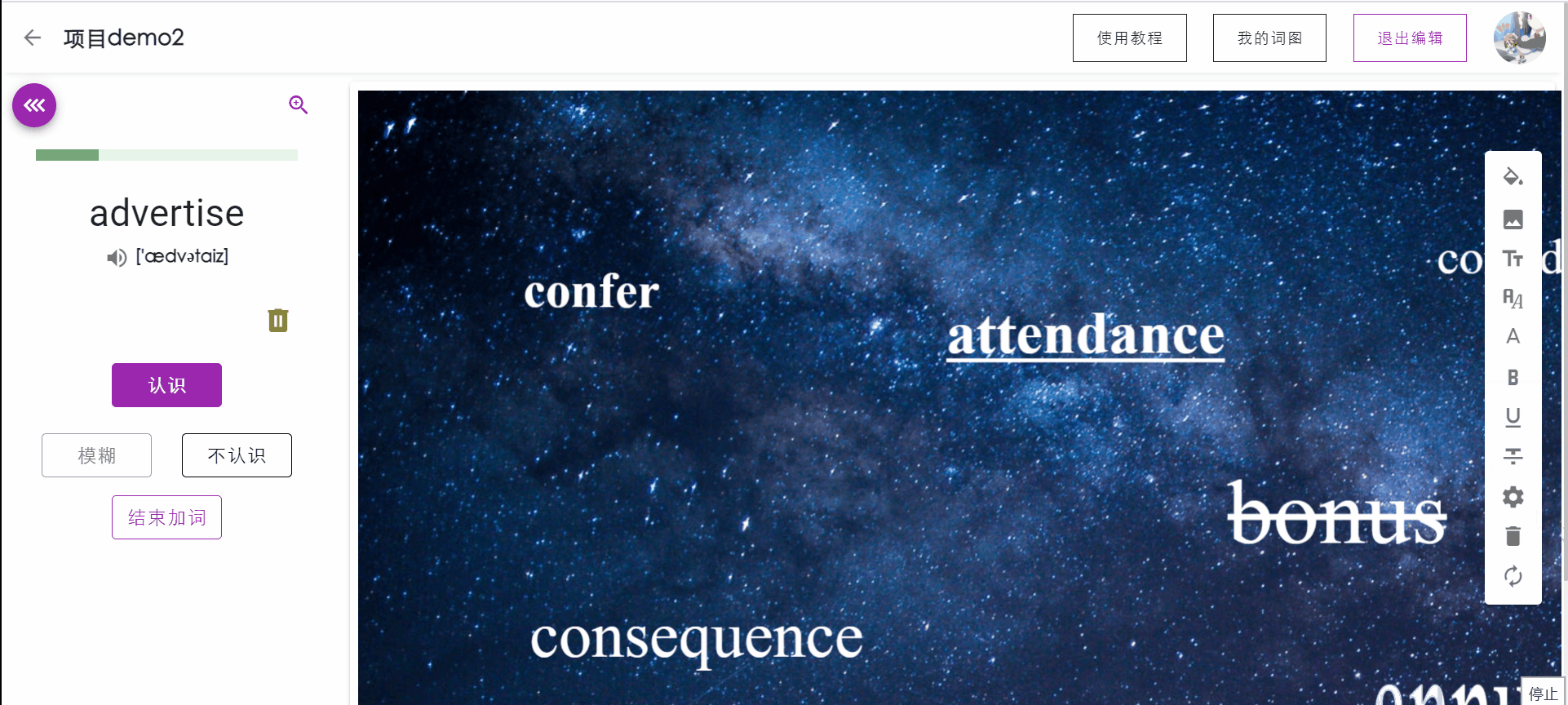
单词出现位置优化
在用户点击加入词图后,单词在词图中出现的位置将以当前视觉中心为圆心进行扩散,随机分布在画布较合适的位置上。
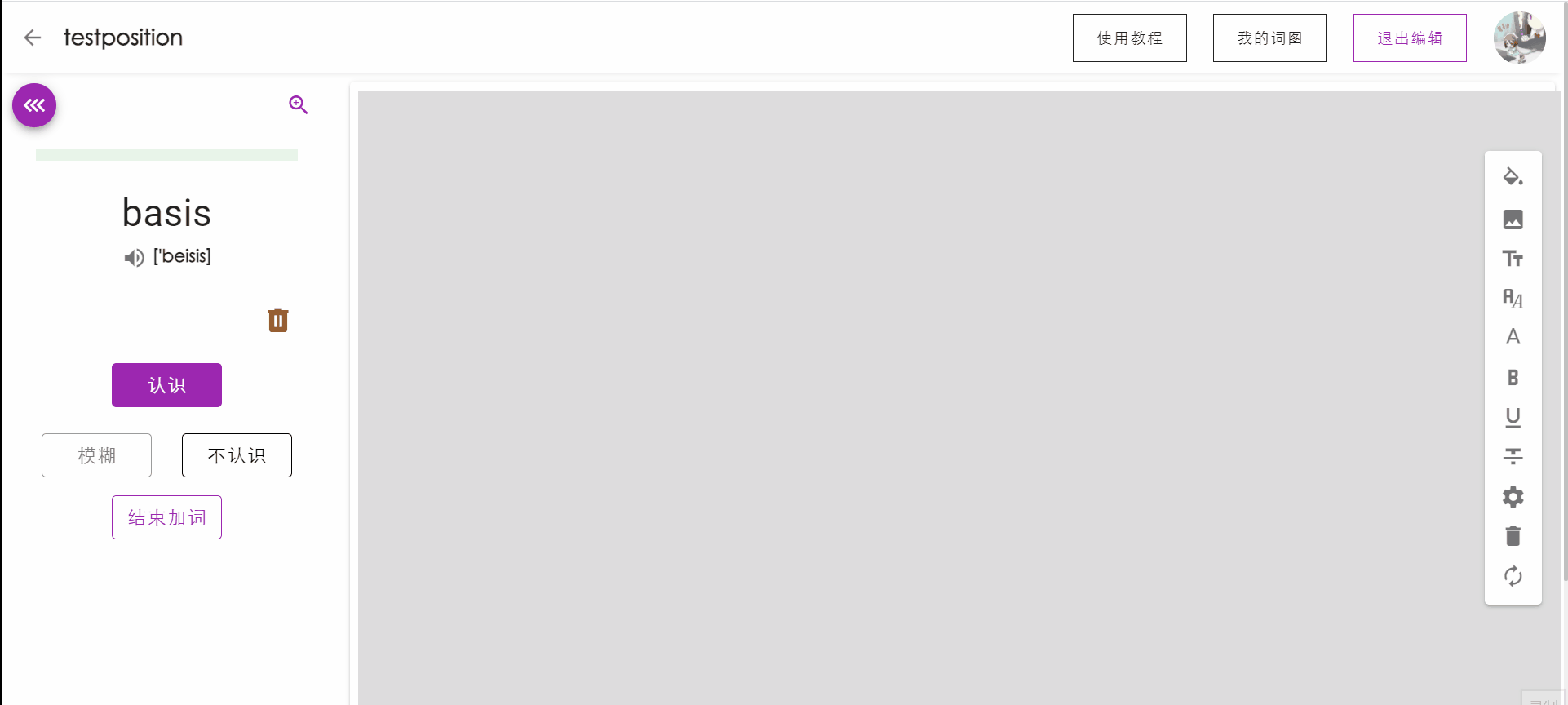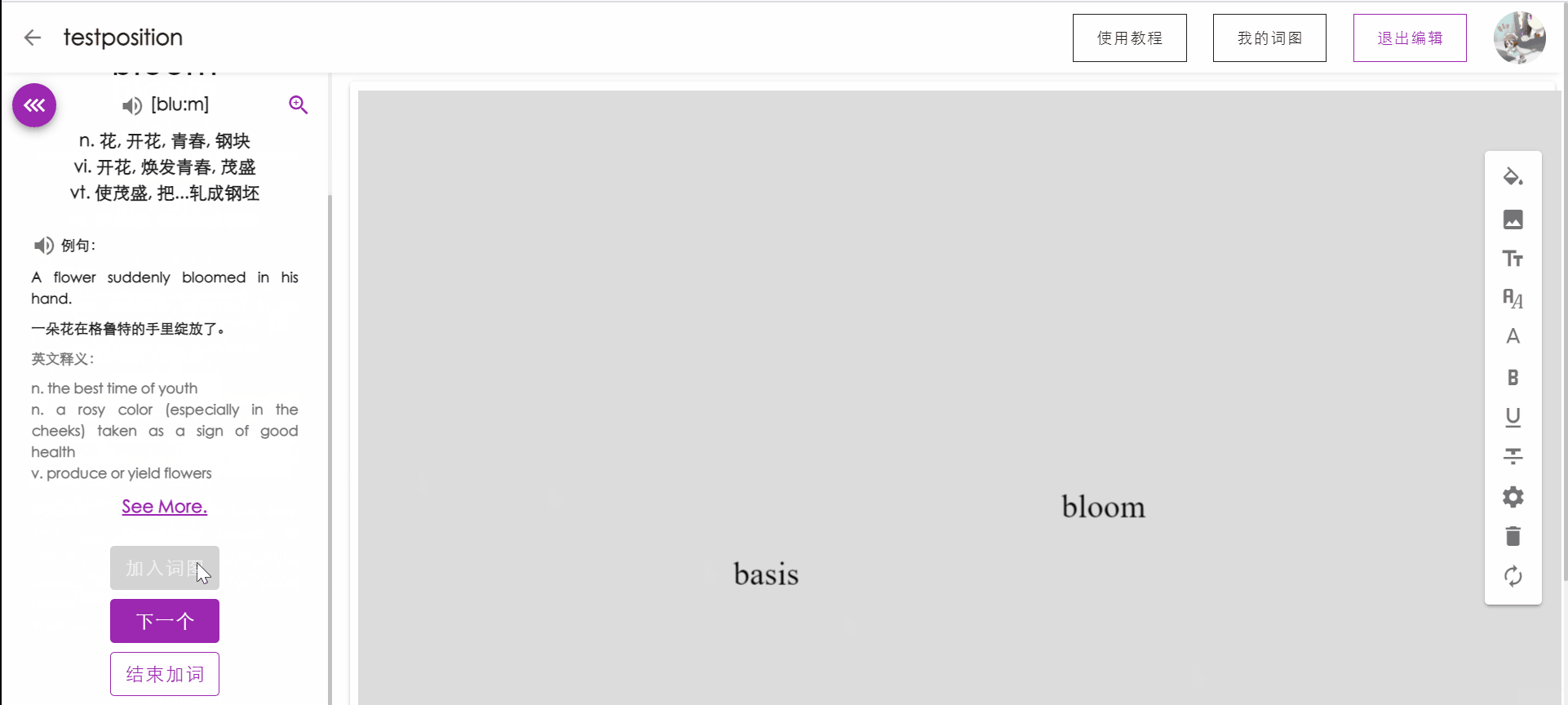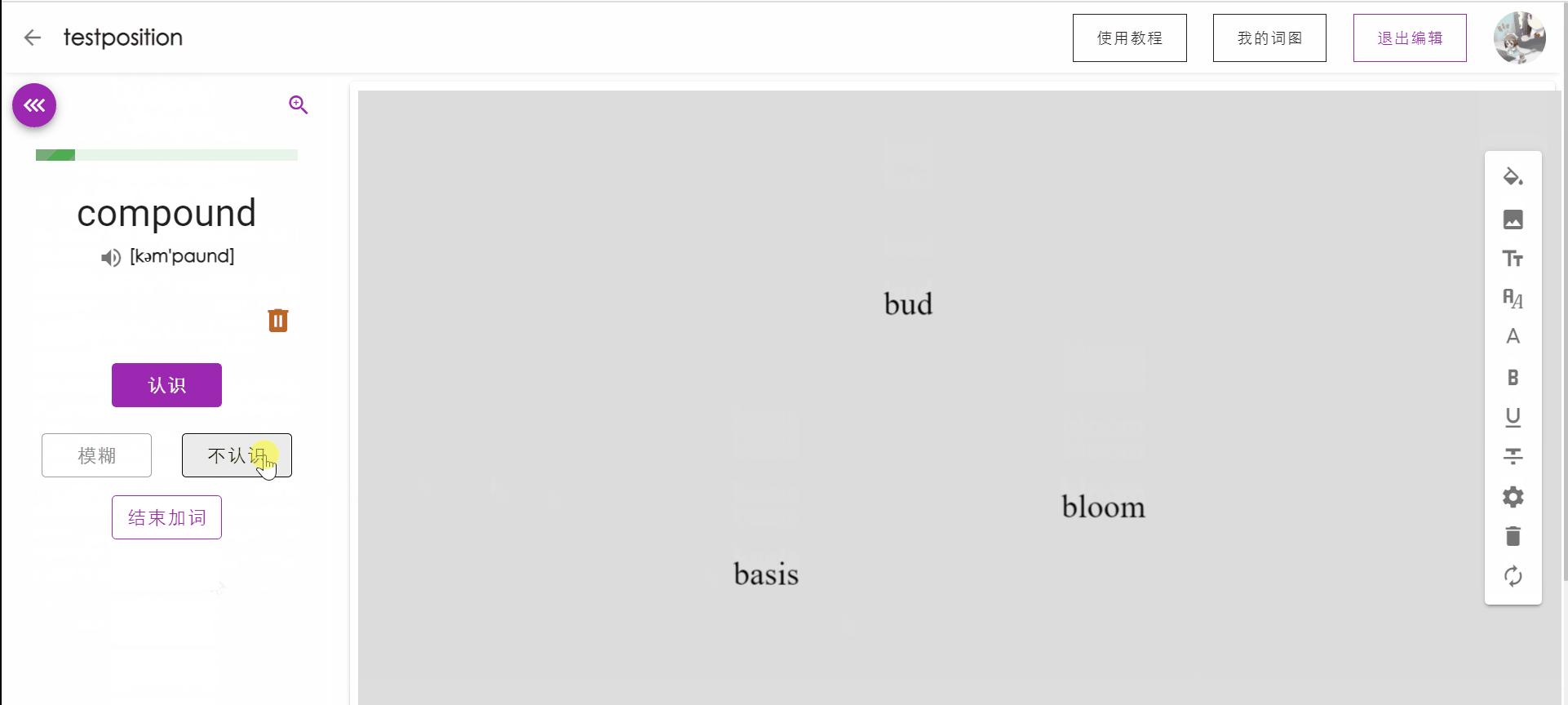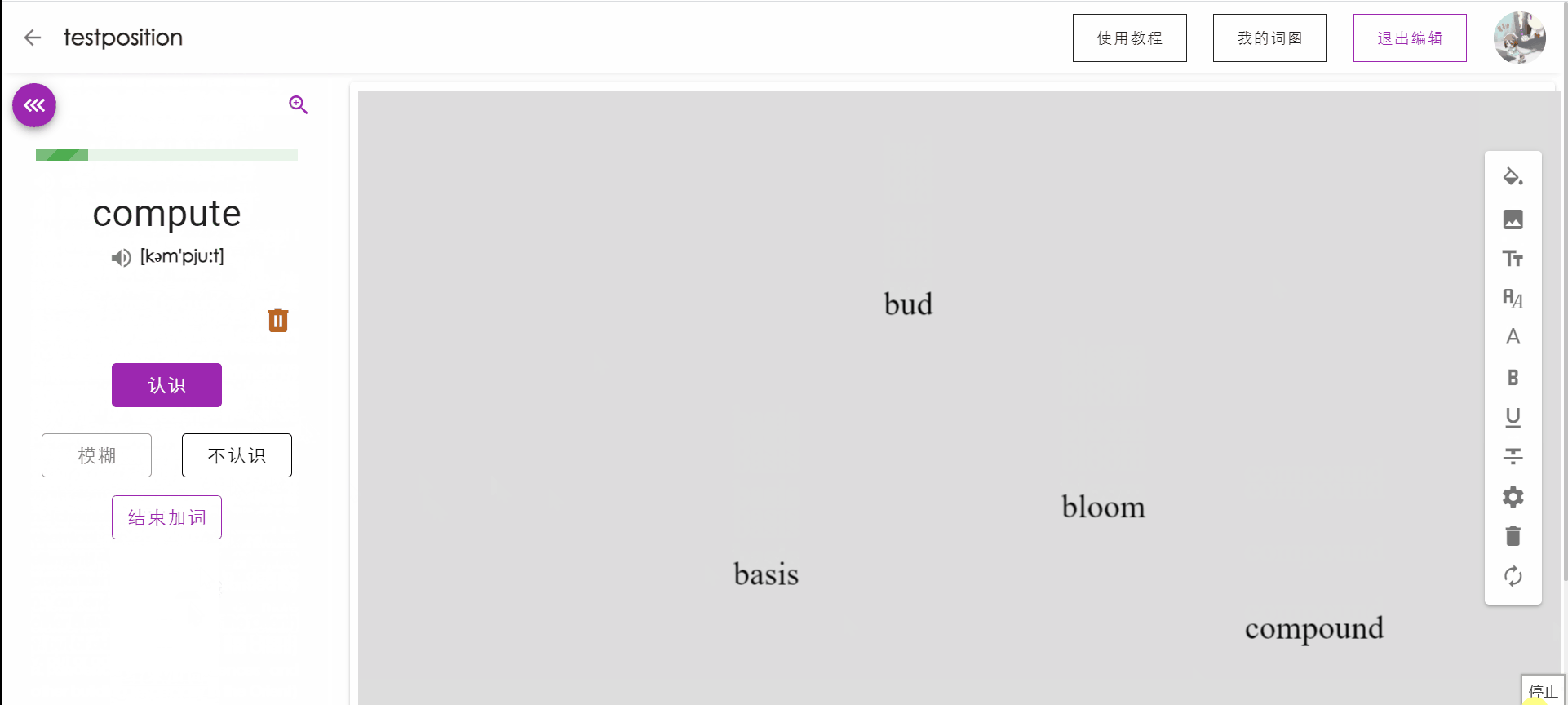
视觉中心移动动画
在复习时,有些单词之间的距离较远,需要进行视觉中心的移动。我们采用速度适中的动画效果进行视觉中心的切换。
发布位置:
目前本软件已支持直接通过域名访问!
域名:jqkey.xyz
另外,本项目同时配备H5宣传手册及宣传视频。
三、用户日活
用户日活数据
见项目与团队亮点四。
用户反馈
我们通过线下采访和线上用户反馈模块收集两种方式对用户的反馈进行了收集。
线下采访部分截图:
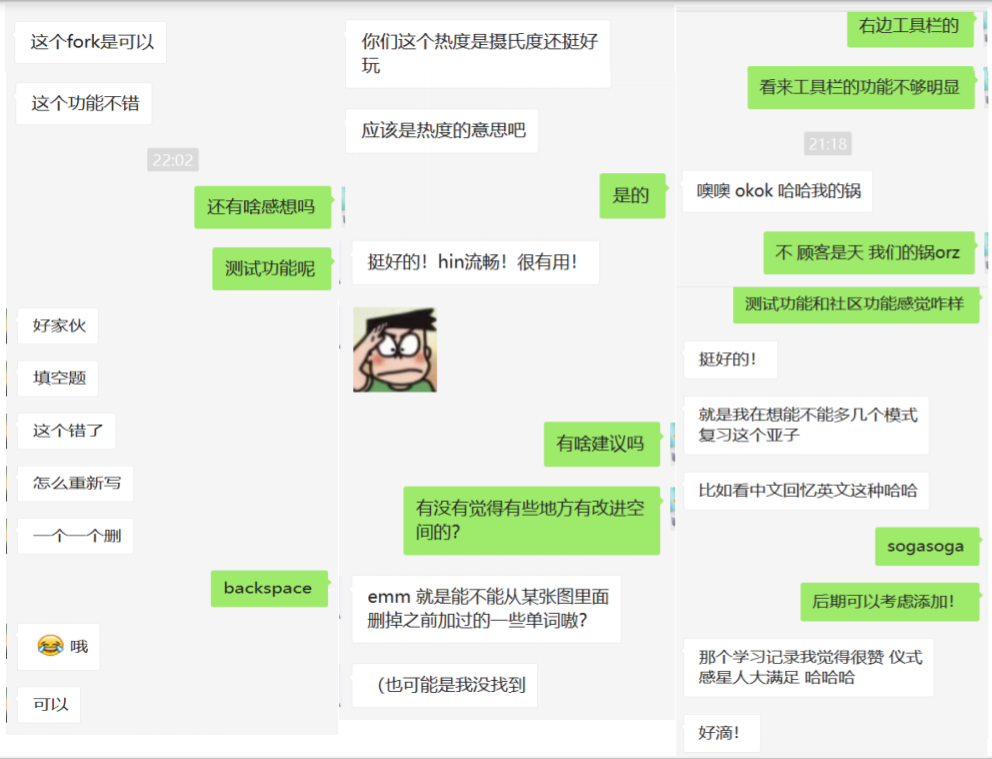
线上收集数据:
由于时间较短,暂时没有收到用户反馈数据。
功能性问题
下面对两种途径获得的功能性建议和 bug 进行汇总。
Alpha 阶段用户反馈
| 用户反馈(功能) | 问题原因 | 是否解决 |
|---|---|---|
| 不认识的词需要点击两边,操作冗余 | 设计时结合扇贝单词的机制有意如此实现,但从用户反馈来看不符合大多数用户的使用习惯。 | 已修正用户对单词掌握程度的逻辑 |
| iPad 平板无法拖拽缩放词图 | 目前 Alpha 版本成品对平板的适应不够完全 | 否 |
| 复习时单词默认在中间出现 | 由于单词有可能出现在画布内,因此暂时将这种出现方式作为默认方式 | 单词随机位置出现,减少重合概率 |
| 不能删除单词 | Alpha 版本暂未实现该功能 | 是 |
| 不能修改头像 | Alpha 版本暂未实现该功能 | 是 |
| 不能自定义背景图片 | Alpha 版本暂未实现该功能 | 是 |
| 新手教程不够友好 | 目前教程作为独立页面存在,但用户希望能和使用界面进行融合,手把手教学 | 实现了更友好的教程 |
| 没有测试模块 | Alpha 版本暂未实现该功能 | 是 |
| 部分 UI 为中文,部分为英文,不够统一 | 在对多模块进行分别设计时没有对 UI 的语言进行规定 | 将前端语言风格进行了统一 |
Beta 阶段用户反馈
| 用户反馈(功能) | 问题原因 | 解决方法 |
|---|---|---|
| 工具栏功能不够明显 | 缺少工具栏的引导 | 暂时考虑用户自行探索,也可添加鼠标移上去显示功能 |
bug 反馈
下面对两种途径获得的 bug 反馈进行汇总:
| 用户反馈(功能) | 问题原因 | 解决办法 |
|---|---|---|
| iPad 平板无法拖拽缩放词图,侧边栏无法显示 | 目前 Alpha 版本成品对平板的适应不够完全 | 争取增加画布对平板分辨率和交互方式的适配性。 |
综合来看,目前用户反馈的 bug 较少,大多集中在前端的效果及多设备的适配方面,没有影响用户正常使用的严重功能性 bug 出现。
四、特色功能
杀手级功能、与竞品的对比见项目与团队亮点三。
预期目标与团队自我评价见项目与团队亮点二。
五、软件工程质量
文档、测试见项目与团队亮点五;经验教训见项目与团队总结六。
分支规范
对于单词基本数据的解析和导入,我们使用了独立分支 parse_mdx 进行开发,使用公开的 ecdict 数据,并在 issue 中进行了阐明。
对于词根词缀、同近义词、词书的解析和导入,我们使用另一个独立分支 parse_wordbook 进行开发,通过 issue 6 13 进行了数据的获取、解析和导入,并针对每一需要更新数据库结构的部分都写了设计文档,如词根词缀、同近义词,其中描述了设计目标、文件格式、数据库设计、实现过程(如手动修改了哪些值,或如何进行实现)、以及 TO-DO 表示可改进之处。
代码规范
后端开发过程对一下几点实现进行了规范:
-
进行了代码的命名规范:不进行简写、使用下划线命名法。
-
进行了代码的内容规范:API 传入时先进行错误处理、异常判断;且对于需要返回的异常情况进行捕获并返回错误码,对于无需返回的异常情况则不进行处理,允许抛出不捕获的异常;等等。
-
对于错误码的类别,进行了规范。
-
对于返回值,成功和失败分别进行了规范。
前端在代码开发前对组件、函数的命名进行了规范:
- Vue 组件命名采用 kebab-case 规范,遵循 W3C 规范中的自定义组件名及 Vue 官方风格指南。
- 组件内部变量、方法命名采用驼峰命名规范。
注释与运行
前端对页面、组件进行了一一对应的结构组织,代码结构清晰。另外,在与画布相关的复杂组件中,前端使用规格和文字对函数进行了注释。在其余功能单一的组件中缺少部分注释。
前端可以在配置好相关开发环境的新机器上轻松运行,如要与后端进行交互,则只需修改配置文件即可。
npm install
npm run serve
后端主要工作在于对 API 的实现,由于 API 文档的完备性,后端具体实现逻辑简单,故代码中注释较少,API 文档已能够清晰地展现后端代码结构。
在新机器上,后端正常编译是可以通过的;但数据库不会自动导入,这是因为我们使用自己的方式对于数据库进行了分批导入与更新。如要获得完整数据库,需要将 parse_wordbook 分支中 main.py 里的注释逐个解掉并运行,具备可行性,但暂且没有相应文档。
单元测试与CI/CD
前端
在 beta 阶段中,为方便前端项目的实时部署与动态迭代,前端基于 scp 实现了相应的CI/CD功能。
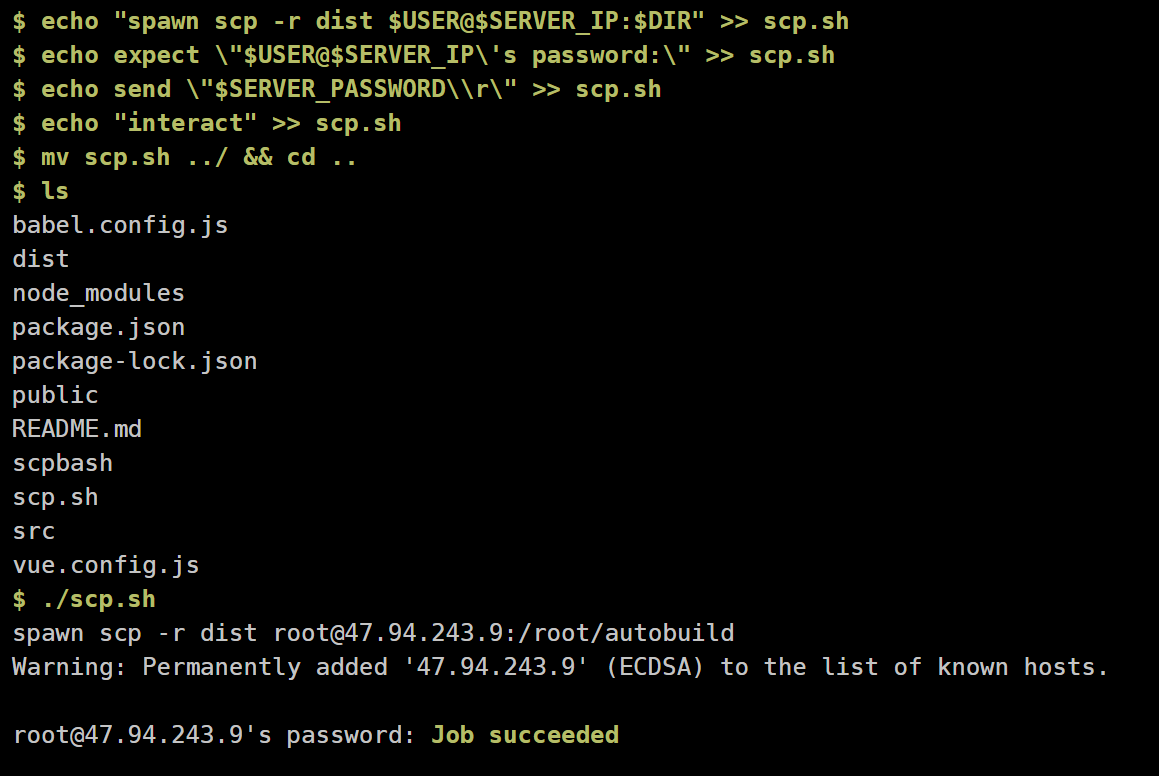
后端
在 beta 阶段中,后端进行了较为完备的单元测试,测试覆盖率达到70%。
而之所以没能达到更高覆盖率,其原因主要有如下三点:
- 出于安全性考虑,每个 api 均使用双重校验,分为解析 token 和解析用户两步进行,从而最大程度保证了用户隐私与后端数据的安全性,但同时难以构造测试用例专门针对能够通过 token 解析但是通不过用户解析的场景,故每一个 API 测试都无法对这双重验证的第二重实现覆盖;
- 部分 API 使用与其他 API 类似的结构,仅更改了部分影响内容(如修改字体、修改大小等),对于此类问题由于时间限制等原因没有进行完备的测试;
- 对于登陆和注销有关权限 API,主要进行了较为完备的场景测试,没有进行单元测试。
六、反思与展望
Beta 反思
伴随着烤漆的钟声与一门门课大作业 ddl 的结束,软工 beta 阶段的开发也就此终于落下帷幕。
如果把 alpha 阶段比作是在一片白茫茫荒漠中摸索出一条大致的路来,那么 beta 阶段就是要努力让这条路变得更宽更广,让更多的人能够走上这条我们开创的路,并能够收获更美丽的风景。
在 beta 阶段的开发中,我们在 alpha 里积累的所有优良传统(比如全线下meeting,kanban法冲刺等)都得到了很好的保留;同时,更令人欣慰的,是团队中的每一个人都最终找到了自己合适的定位,在这样的一个项目里做着自己感兴趣的那部分工作,发挥自己的长处,几乎是不求回报地想要把自己的那份工作做到最好,做到极致。
这一切,作为PM的我(tcy),全程都看在了眼里。我记得,小树不断地将前端的 UI 界面进行反复优化与重构,只求为用户提供最丝滑的使用体验;我记得,Mokoghost为了实现词图中单词移动的动态效果,亲自手写了最底层的动画播放逻辑;我记得,潜行的蚂蚁对于主页、教程的反复打磨,以及在宣发时的不遗余力;我还记得,圆那超强的执行力以及不怕苦不怕累的担当和责任感;还有Potassium对于核心算法的实现与数据的爬取做出的无可替代的贡献……
类似的故事还有很多很多,多到足以让我坚定不移地相信,我们团队里的任何一个人,放到外面的任何一个地方,都能做到独当一面,都能一人撑起一个甚至多个部门,都能成为未来IT行业的超级精英。
回到软件本身上来,可以说,beta 版本的『近取Key』已经几乎实现了我们在 alpha 开发伊始所能设想到的全部的功能,『记忆宫殿』、『A4纸背单词』这些最核心的创意与逻辑均已得到了淋漓尽致地展现,此外还增加了诸如自定义加词、智能推荐等等意料之外的功能。但是,这还不能说它已经足够完美了,只能说这是我们6个人在短短2个月时间内,在无数烤漆裹挟下,在极有限的资源加持下,所能交出的一份最好的答卷。
但是,这绝不是这个软件本身所能达到的最完美的形态。
无论是从软件本身的可维护性、安全性、跨平台兼容性,还是从用户体验视角下使用的流畅性、健壮性、交互友好性,抑或是从商业视角下的盈利能力、宣发能力,我们和它都还有很长很长的一段路要走;甚至也许,这条由我们亲自开辟的路,永远也不会有所谓的尽头。
更远的未来
目前,为了更好地证明我们所做出的这个成果的价值,我们已经为其申请了全国大学生创新创业年会创新训练项目,并已成功入选。

这之后,虽然软工这门课的使命已经结束了,但由这个因所种下的果还将在未来很长的一段时间内持续长久地存在着。这并不是因为它能够给我们带来物质上的什么回报,而是因为在他的背后,承载的是我们整个团队大学三年中最宝贵的一份回忆,以及回忆之中所凝结的青春与汗水。
这才是软工这门课真正的价值,才是大学所应有的意义。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号