【近取 key】技术规格说明书
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 2021春季计算机学院软件工程(罗杰 任健) |
| 这个作业的要求在哪里 | 技术规格说明书 |
| 我在这个课程的目标是 | 进一步提升工程化开发能力,积累团队协作经验,熟悉全栈开发流程 |
| 这个作业在哪个具体方面帮助我实现目标 | 介绍项目整体规格和技术基础,并进行简要分析 |
我们团队提出的『近取 key』网页端背单词软件为自选题目,不存在前人的任何架构以供继承,全部内容都将由本团队从零开始实现。该项目的具体功能设计可参见项目功能说明书,这里不再赘述。
一、项目技术栈
项目整体基于网页 web 端实现,目标适配 PC、平板等大屏用户端。项目整体将统一部署到服务器云端,云端开发部署环境为 ubuntu 18.04,目前已在阿里云上购买相应服务器,服务器基本配置如下:
- 2 核 4G,40G ESSD 云盘存储,5Mbps 公网带宽
前后端开发所涉及的具体技术栈如下:
- 前端:前端所用的程序设计语言为
css+html+js全家桶,采用vue+Axios框架开发,利用postman软件进行后端模拟测试;- 低版本浏览器适配:使用 Babel 编译器,实现ES6语法的前向兼容
- 后端:后端所用的程序设计语言为
python+sql,采用Django+MySQL框架,可自行进行单元测试等操作;其中 python 版本为 3.8,MySQL 版本为 5.7,后续可能会视具体兼容情况决定是否做相应调整。
二、功能设计
软件整体功能设计图如下:
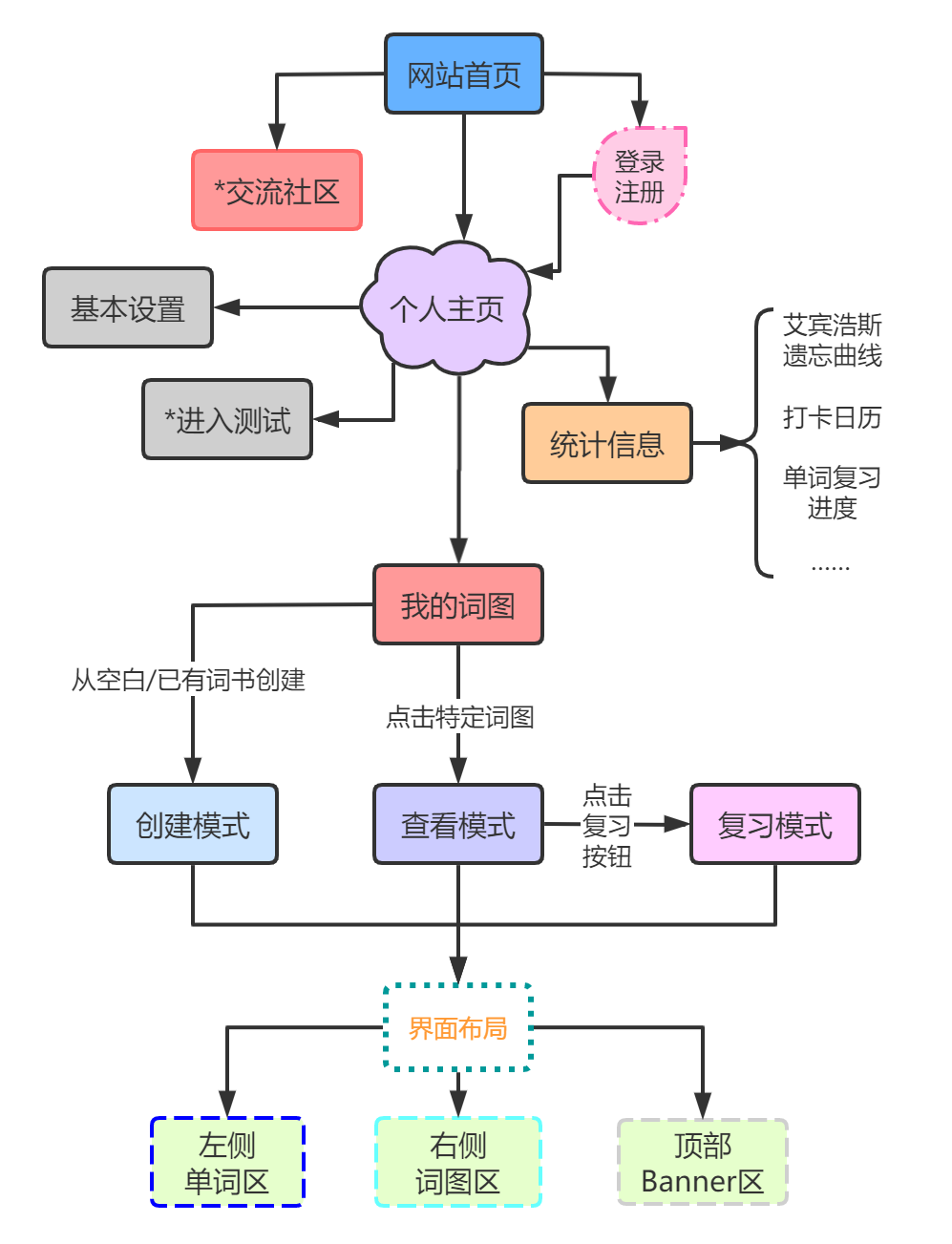
三、软件架构
软件的整体架构如下图所示:
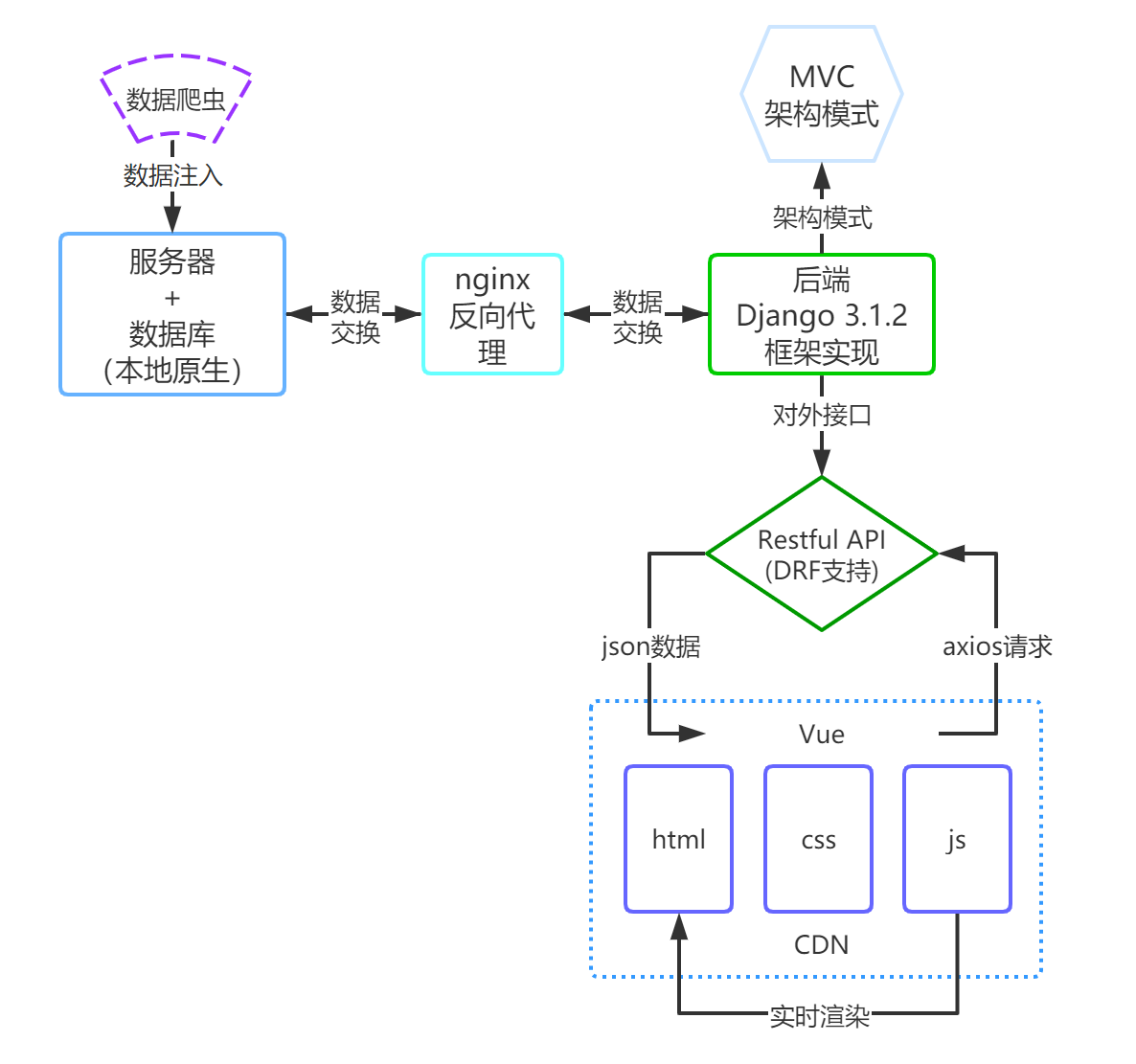
下面对其中的主要模块所承担的功能任务进行简要介绍。
数据爬虫
主要进行单词及其相关数据的爬取与预处理工作,批量对单词相关数据进行处理,并将其预先写入数据库中。
后端 Django 框架
基于 MVC 架构实现,利用 Django 提供的对象关系映射机制 (ORM)、路由管理、用户系统组件可显著降低开发成本,提升整体开发效率。同时,Django 提供的 Django-rest-framework(DRF) 插件也可方便地定义前后端交互 API,并通过 uwsgi 进行代理,从而快速迭代实现前端所需的各类接口。
前端 Vue.js + Axios
前端采用 Vue.js 框架实现,利用其“单文件组件”的组织结构,使得页面、样式和脚本代码被集成到了同一个.vue文件中,并可以通过组件这一形式实现前端开发的面向对象化,从而做到信息的封装与隐藏。
Nginx & CDN
此二者主要用于应对潜在的高并发情况,即当出现大量用户请求时,Nginx 可通过反向代理从服务器集群中选择一个当前负载较小的服务器进行分派,从而实现静态资源负载均衡;CDN 则可通过缓存加速机制使用户就近取得所需内容,解决 Internet 网络拥挤的状况,从而提高用户访问网站的相应速度。
四、开发目标
目前暂只考虑alpha阶段的相关开发目标。
4.1 代码编写与设计
后端
- 完成数据爬虫和预处理的相关代码实现
- 设计 ER 图,利用 Django 搭建并初始化数据库,导入相关数据
- 基于 API 文档,实现相关的所有 API 对应的 Controller 单元
- 实现基于艾宾浩斯记忆曲线的复习推荐的相关算法
- 若时间尚有剩余,可对高并发场景进行针对性优化和设计
前端
- 设计功能设计图中各主要页面的基本布局与事件相应及处理逻辑
- 完成主要页面相关代码的撰写与实现
4.2 测试
后端
- 完成数据爬虫与各 API 的功能性测试(单元测试 90% 以上覆盖)
- 若时间尚有剩余,则考虑高并发场景,进行压力测试
- 压力指标:基于服务器实际负载上限与 Alpha 阶段预期用户数综合确定
前端
- 利用 postman 对各 API 接口进行真实测试
- 测试细节:对于各 get、post 等方法,由 postman 发出相应数据,前端捕捉后进行响应,检查基本逻辑是否正确无误
- 采用单元测试、组件测试与端到端(E2E)测试相结合的方式,联合使用 Jest 与 Vue-test-utils 单元测试工具,并利用 Nightwatch.js 实现 E2E 测试
集成
- 前后端部署后,进行集成模拟测试,即模拟用户在真实场景下的可能操作,前后端统一进行检错。
4.3 文档
文档编写方面,出于时间紧、任务重的综合考虑,我们团队决定采取非必要不编写的基本原则。即除必要的前后端交互所需的 API 文档外,其余说明文档视时间允许与任务需要决定是否撰写。
另外,虽然我们不强制要求说明文档的撰写,但我们非常鼓励在代码中添加必要的注释,从而保证代码的可读性,为后续的迭代工作做好预备,这方面的内容已被纳入本团队的贡献分考核指标中。基于此,我们或许可以借助相关工具从注释直接导出相应的说明文档。
五、基本分析
5.1 封装与抽象
底层实现抽象(基于 Django):
- 将 SQL 语句抽象为 OOP 的相应函数式操作,便于实现复杂语句的增删改查
- 将数据模型抽象为 python 中的类对象,便于定义属性及其相应约束
- 将结构变动信息抽象为 migrations 中的迁移记录,便于审核与检查
物理数据抽象:
- 将单词实体抽象为包含单词文本、释义、例句、音标音频等信息的映射关系,从而可降低其内部耦合度,自由添加额外信息
- 将词图抽象为单词与其位置的一一对应映射,从而可便于存储和复现
- 将词书抽象为视图,从而降低底层数据冗余
- 将前端页面的复杂逻辑抽象为一个个组件,便于相互调用
- 基于 MVVM 模型的思想,采用 Vue 框架,模块化编写单文件组件,将 View 的状态和行为抽象化,让视图UI和业务逻辑分开
用户视图抽象:
- 基于『词图』,在单词和词书之间额外增加了一层有丰富语义信息的数据抽象层次,从而帮助用户记忆
- 利用统计信息,获得每日打卡情况的整体统计数据,帮助了解评估整体学习效果
RESTful API:
- 将前后端完全分离,前端只能通过调用相应 API 实现对后端数据的访问,后端的其余数据无法被前端捕获,从而实现信息的封装与隐藏
5.2 高内聚低耦合
高内聚:
- 前后端各司其职,只通过api通信、交换数据
低耦合:
- 后端采用 MVC 架构,将数据、控制器与视图分离,降低各模块之间耦合度
- 前端采用 MVVM 架构,利用组件进一步划分功能,降低各页面各模块之间的相互影响
- 对于每一个页面的功能(如单词的拖拽、编辑、查看释义等),单独编写 Vue 组件,便于复用、降低耦合
5.3 错误机制与处理方法
后端:
- 构造异常,对可能的错误进行捕获
- 与前端通信时,若出现错误,则返回相应的 Http 错误码,便于 Debug 时判断具体的错误信息
- 利用 Django,可在 Debug 模式下实时查看前端调用API接口时的具体异常信息,包括错误栈等
前端:
- 使用 Vue 提供的用于捕获异常的 API:errorCaptured、errorHandler,对于不同的错误类型使用 try...catch... 分类进行处理;进一步地,对于不同的错误类型,我们将设置相应的内部错误码,从而明确前后端的通信规范。
5.4 高并发场景的应对方式
考虑到我们预期的用户规模不大,后端逻辑相对简单,因此在开发阶段项目不存在较高的并发需求。对于一般情况,MySQL + Nginx + uwsgi 的部署策略即可满足要求。
假如出现更强烈的高并发需求,可以借助 CDN 分发静态资源(前端 SPA),后端增加响应实例数量,数据库实现读写分离,进行分布式管理,同时添加 redis 等中间件消峰。
5.5 需求灵活变化
由于我们的软件整体设计上呈现扁平化趋势,且团队规模与软件大小均相对轻量,因此当出现新增需求时,我们可以实现“一站式”流水线应对方案。
具体操作流程为:
- 前端设计实现用户操作接口、相应界面与控制逻辑
- 前端判断现有 API 能否满足新需求需要,若不可,则定义新的 API,同时更新 API 文档
- 后端基于 API 文档实现其内部控制逻辑,同时判断现有数据模型能否满足新需求需要
- 若不可,则调整数据模型,进行迁移
