BUAA_OS lab1实验报告
一、思考题
思考1.1
也许你会发现我们的readelf程序是不能解析之前生成的内核文件(内核文件是可执行文件)的,而我们之后将要介绍的工具readelf则可以解析,这是为什么呢?(提示:尝试使用readelf -h,观察不同)
使用原有的readelf解析vmlinux文件结果如下:
19377059@stu-112:~/19377059-lab/readelf$ readelf -h ../gxemul/vmlinux
ELF Header:
Magic: 7f 45 4c 46 01 02 01 00 00 00 00 00 00 00 00 00
Class: ELF32
Data: 2's complement, big endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: EXEC (Executable file)
Machine: MIPS R3000
Version: 0x1
Entry point address: 0x80010000
Start of program headers: 52 (bytes into file)
Start of section headers: 37196 (bytes into file)
Flags: 0x1001, noreorder, o32, mips1
Size of this header: 52 (bytes)
Size of program headers: 32 (bytes)
Number of program headers: 2
Size of section headers: 40 (bytes)
Number of section headers: 14
Section header string table index: 11
使用原有readelf解析testELF文件结果如下:
19377059@stu-112:~/19377059-lab/readelf$ readelf -h testELF
ELF Header:
Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00
Class: ELF32
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: EXEC (Executable file)
Machine: Intel 80386
Version: 0x1
Entry point address: 0x8048490
Start of program headers: 52 (bytes into file)
Start of section headers: 4440 (bytes into file)
Flags: 0x0
Size of this header: 52 (bytes)
Size of program headers: 32 (bytes)
Number of program headers: 9
Size of section headers: 40 (bytes)
Number of section headers: 30
Section header string table index: 27
注意到二者的第六个魔数不同,01表示小头编码,02表示大头编码。可以看到vmlinux文件是大头编码,大头编码的文件中存储的所有数据都是大头形式的,而我们的readelf文件目前只能解析小端存储的文件,因此大头的数据传入程序中时会显示数组溢出,无法解析。
思考1.2
内核入口在什么地方?main 函数在什么地方?我们是怎么让内核进入到想要的 main 函数的呢?又是怎么进行跨文件调用函数的呢?
根据mmu.h文件中的信息,内核入口位于0x80000000处,main函数位于0x80010000处。
在内核入口函数中修改跳转指令的地址,之后运用jal可以让内核进入到想要的main函数中。
每个函数都有自己的地址,在跨文件调用函数时先将原来的变量存入栈中,返回位置同样堆栈,再跳转到调用函数的地址,函数调用结束后从栈中取出返回的位置,返回原函数,相关变量从栈中恢复。
二、实验难点
1.exercise2
值得注意的是,在解析ELF文件前需要判断是否为ELF文件,这在所给代码中已经实现了。
本实验的难点在于如何有条理地使用各个地址或偏移,从而找到相应的存储位置并读取所需信息。
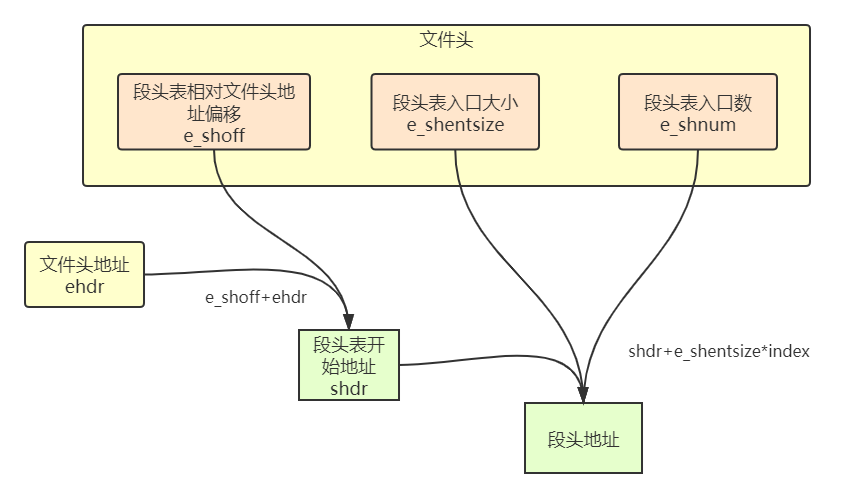
首先从文件头中获得段头表相对文件头地址的偏移,与文件头地址相加获得段头表开始的地址,之后运用从文件头获得的段头表入口大小与段头表入口总数,循环计算每个段头开始的偏移,与段头表开始地址相加即得到段头的真实地址。
2.exercise5
lp_Print函数流程图如下:
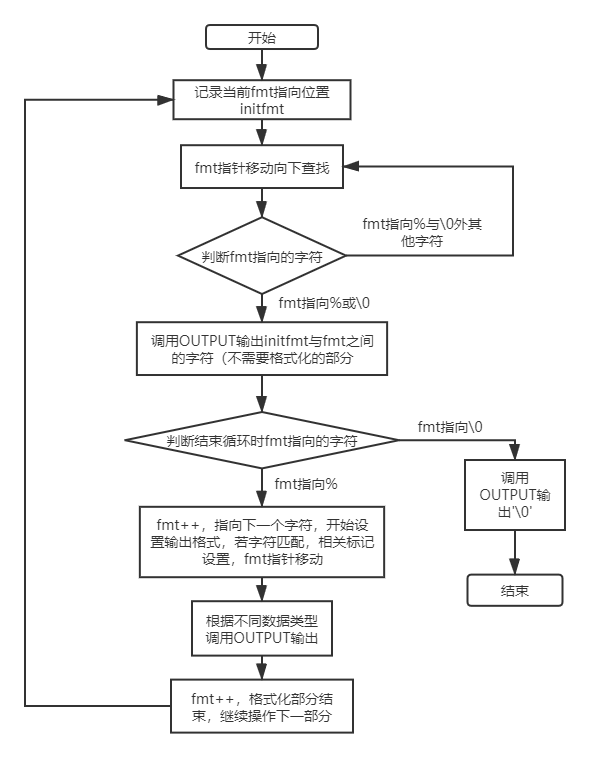
容易产生bug的点在于fmt每次完成匹配后需要自增使其指向下一个待检查的字符。
在输出不需要格式化的部分,我又引入了一个新的指针,用于记录非格式化字符串的起始位置,在fmt指向终止符号后可以整段输出之前的字符,而不需要一个字符一个字符地调用OUTPUT输出。
代码中有些量并没有初始化,比如补全所用的字符padc,即使输出的字符串没有要求使用特定字符补全,也要将其设置为空格,最后应注意每个用于输出的标志都应有值,而不是出于未赋值状态。
在根据不同数据类型输出的部分,%d和%D需要特别关注。需要判断格式化输出的内容是否为负数,若为负数,需要将其变为绝对值,并将negFlag负数标记置1。我是在最后检查代码时发现negFlag没有使用才意识到了这个bug。
三、体会与感想
lab1花费9小时,由于对这个黑色界面仍不太熟悉,补充代码前依旧迟迟不敢开始。在实现printf时需要阅读三个文件的代码,切换起来有些不方便(忘记课程组发过文件夹了),导致浪费了较多时间,对tmux的使用也不够熟悉,想分屏看代码但仍觉得很不顺手。
一直以为Makefile可以实现只要依赖文件发生改动,make就会自动执行,这次作业后才发现原来还是需要在修改代码后手动make。忘记执行make导致我看着printf执行失败的界面不知所措,最后在交流群里找到了问题所在。
目前面对大段代码还是感觉有些吃力,一方面英语水平有些欠缺,会因为某个单词造成理解障碍,另一方面之前过于依赖高亮辅助,导致现在有些“拿不走拐杖”。
给出的代码一般都预先定义好了变量,但由于不能理解变量名称(比如不知道带ptr的变量是指针),我在面对一块待补充的部分时有些茫然,在学习了一些变量命名规范后发现给出的变量名已经暗中提示了相关的操作,甚至提示了变量的数据类型。
四、指导书反馈
printf的格式符众多,指导书中提到可以依据官方文档进行了解,但对于具体实现哪些格式符似乎并没有明确的说明。带着一丝侥幸心理,我目前只实现了指导书表格里列出来的内容,不知道其他字符是否也需要判断。因此,对于这种有很多可以实现的问题,如果可以,希望指导书中可以在每个Exercise中加入明确的说明。
printf格式化的标志顺序是%[flags][width][.precision][length]specifier,检查是否为long int的位置应该靠后,但代码中的提示似乎将其放在了最前面,不知是否有些不妥。
五、残留难点
目前看来本实验的内容都已基本掌握,但还是没有对操作系统实现的功能有一个宏观的概念,简单说甚至还做不到说清内核是什么,内核和main函数的关系,这一部分的不足可能还需要深入理解一下指导书上的讲解或从教材上寻找一些专业的解释。
lab1课上测试结束了,很不幸,我挂掉了第二次。原因似乎是我当时以为ap那个变量(va_list)也可以作为指针。所以当时我的做法是先把ap解析成int*(或long int*),输出一个整数之后ap+=1,然后再把ap解析成char*,同理再输出再自增再解析。但是这种做法似乎只能解析出第一个整数,后面就不行了。这次测试想要考察的点应该是两个char占用4字节的内存,这一点我倒是注意到了,可惜卡在别的地方了。挂了一次也就没机会申优了,但愿以后顺利一点点吧。
