典型的高可用架构浅析
高可用是互联网应用一直在追求的指标之一(高性能、易伸缩,易扩展是另外三个),追求100%的高可用是不现实的,通常一个系统能达到99.99%的高可以就可以认为非常不错了。高可用的实现理论基础在于冗余,而对于数据库,Redis这些有状态的中间件,要实现高可用除了冗余外还需要一个核心的功能:复制。下图是一个典型的互联网应用高可用架构,如图:
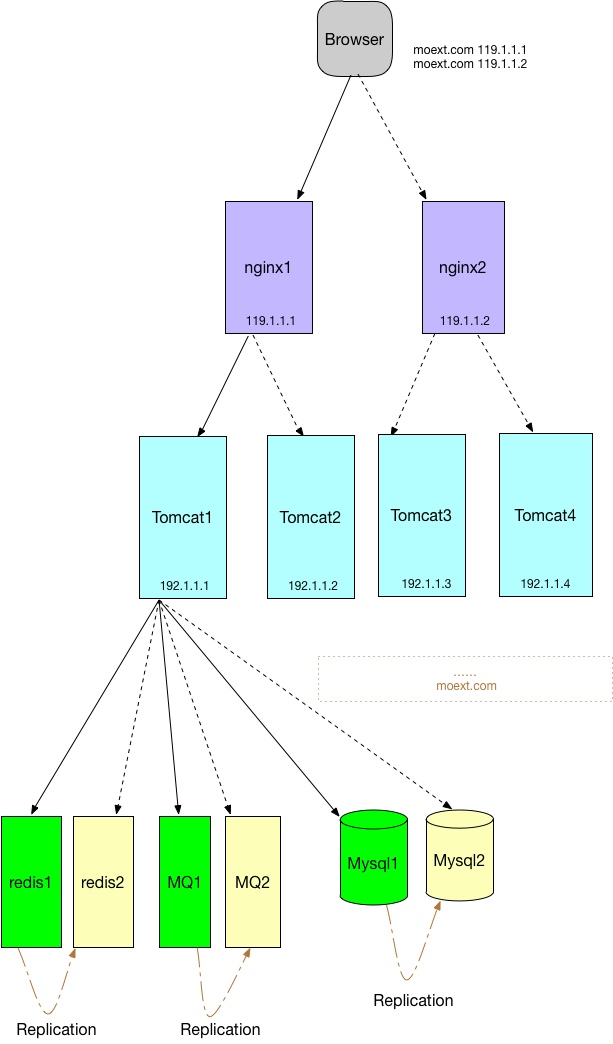
1、Nginx的高可用
两个Nginx,IP分别为119.1.1.1和119.1.1.2,在CNAME配置一个域名对应两个IP如下:
moext.com 119.1.1.1
moext.com 119.1.1.2
通过DNS轮询解析域名返回一个IP
缺点:DNS存在各级Cache,修改CNAME记录后生效时间不可控,当某个nginx挂掉后,不能通过修改CNAME立刻切换IP。但至少能保证另一半用户的正常访问。
2、Tomcat服务的高可用
通过Nginx负载均衡将请求转发给后端Tomcat服务,Nginx常见的负载均衡策略有:轮询、加权轮询、ip_hash等。常见的负载均衡备选的软件方案还有LVS、Haproxy甚至Apache等,而硬件上可选择的方案有F5、Array,F5功能强大,但价格不菲,相比之下Array性价比也不错,适合预算不高的公司使用。每个实现都有其特点,至于具体选用哪种负载均衡实现,请根据项目实际情况,人员配备综合选择。
3、中间件如数据库MySql、消息中间件、Redis的高可用的高可用
中间件高可用的核心仍在于Replication,具体实现时也有些细节的差异。通常有几类选择:
- 高可用完全在后端实现,对使用方来说完全透明。
这其中最常见的代表是通过Keepalived实现VIP切换,比如VIP为:192.168.1.11, redis1为:192.168.1.12, redis2为:192.168.1.13,当前VIP=192.168.1.11的真实IP为192.168.1.12,(脚本检测发现)redis1挂掉后,将VIP漂移到192.168.1.13。即VIP=192.168.1.11此时的真实IP为192.168.1.13,从而实现高可用,优点是简单,缺点是一般来说只实现了高可用,没实现负载均衡。 - 高可用完全由调用方编码实现。
如mysql双写,由调用方在写完mysql1后再显式调用写mysql2。当其中一台挂了后,还能保证另一台写成功。 想要负载均衡或只要高可用均可自行实现。优点是相当灵活,缺点是需要自行实现,除非有充分必要的原因,否则不建议自行实现。 - 高可用由独立的第三方client端实现。
即由调用方嵌入实现了负载均衡的客户端实现高可用及负载均衡。这些第三方client端实现,有些已经实现了高可用+负载均衡(有些只实现了高可用)。优点是不需要自行开发,另外比起3.1当某个节点挂掉后,应用能够更快感知到。
3.4、Cluster实现。
无论Mysql、Redis、MQ、Zookeeper通常都有其集群实现方案。通常对开发人员来说,调用集群与单机的实现编码上会有所区别。另外Cluster除了实现高可用和负载均衡外,具备更好的伸缩性,一般情况下如果是新项目建议使用。Cluster实现与3.1类似,只是客户端只需要知道Cluster的地址,而不需要知道具体Node的,开发编码上有所区别,具有负载均衡功能,具备更好伸缩性。
附:
高可用后用户session的保持如何解决呢?通常有如下几种做法:
- 负载均衡层策略,如nginx根据ip_hash,F5根据cookie分发等,将同一用户请求发送给同一个Tomcat服务。 缺点就是服务做成了有状态的,而且某台Tomcat挂掉之后,这台Tomcat上的Session用户全部要重新登陆。
- 各Tomcat之间互配session同步,即每台Tomcat有全量的session。这种方式缺点也很明显,伸缩性很差。
- Session统一在后端存储,如Redis。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号