各种常用排序思想
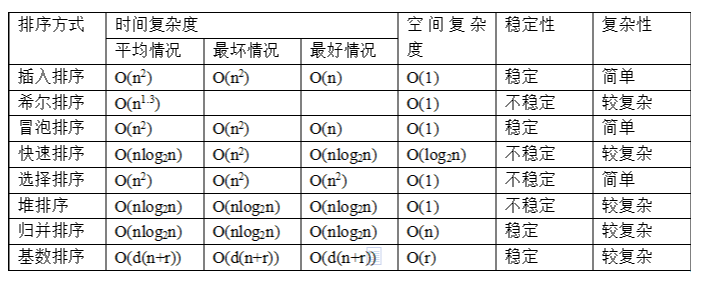
常用的内部排序方法有:交换排序(冒泡排序、快速排序)、选择排序(简单选择排序、堆排序)、插入排序(直接插入排序、希尔排序)、归并排序、基数排序(一关键字、多关键字)。
一、冒泡排序:
1.基本思想:
两两比较待排序数据元素的大小,发现两个数据元素的次序相反时即进行交换,直到没有反序的数据元素为止。
2.排序过程:
设想被排序的数组R[1..N]垂直竖立,将每个数据元素看作有重量的气泡,根据轻气泡不能在重气泡之下的原则,从下往上扫描数组R,凡扫描到违反本原则的轻气泡,就使其向上"漂浮",如此反复进行,直至最后任何两个气泡都是轻者在上,重者在下为止。
【示例】:
49 13 13 13 13 13 13 13
38 49 27 27 27 27 27 27
65 38 49 38 38 38 38 38
97 65 38 49 49 49 49 49
76 97 65 49 49 49 49 49
13 76 97 65 65 65 65 65
27 27 76 97 76 76 76 76
49 49 49 76 97 97 97 97
二、快速排序(Quick Sort)
1.基本思想:
在 当前无序区R[1..H]中任取一个数据元素作为比较的"基准"(不妨记为X),用此基准将当前无序区划分为左右两个较小的无序区:R[1..I-1]和 R[I+1..H],且左边的无序子区中数据元素均小于等于基准元素,右边的无序子区中数据元素均大于等于基准元素,而基准X则位于最终排序的位置上,即 R[1..I-1]≤X.Key≤R[I+1..H](1≤I≤H),当R[1..I-1]和R[I+1..H]均非空时,分别对它们进行上述的划分过 程,直至所有无序子区中的数据元素均已排序为止。
2.排序过程:
【示例】:
初始关键字 [49 38 65 97 76 13 27 49]
第一次交换后 [27 38 65 97 76 13 49 49]
第二次交换后 [27 38 49 97 76 13 65 49]
J向左扫描,位置不变,第三次交换后 [27 38 13 97 76 49 65 49]
I向右扫描,位置不变,第四次交换后 [27 38 13 49 76 97 65 49]
J向左扫描 [27 38 13 49 76 97 65 49]
(一次划分过程)
初始关键字 [49 38 65 97 76 13 27 49]
一趟排序之后 [27 38 13] 49 [76 97 65 49]
二趟排序之后 [13] 27 [38] 49 [49 65]76 [97]
三趟排序之后 13 27 38 49 49 [65]76 97
最后的排序结果 13 27 38 49 49 65 76 97
三、简单选择排序
1.基本思想:
每一趟从待排序的数据元素中选出最小(或最大)的一个元素,顺序放在已排好序的数列的最后,直到全部待排序的数据元素排完。
2.排序过程:
【示例】:
初始关键字 [49 38 65 97 76 13 27 49]
第一趟排序后 13 [38 65 97 76 49 27 49]
第二趟排序后 13 27 [65 97 76 49 38 49]
第三趟排序后 13 27 38 [97 76 49 65 49]
第四趟排序后 13 27 38 49 [49 97 65 76]
第五趟排序后 13 27 38 49 49 [97 97 76]
第六趟排序后 13 27 38 49 49 76 [76 97]
第七趟排序后 13 27 38 49 49 76 76 [ 97]
最后排序结果 13 27 38 49 49 76 76 97
四、堆排序(Heap Sort)
1.基本思想:
堆排序是一树形选择排序,在排序过程中,将R[1..N]看成是一颗完全二叉树的顺序存储结构,利用完全二叉树中双亲结点和孩子结点之间的内在关系来选择最小的元素。
2.堆的定义: N个元素的序列K1,K2,K3,...,Kn.称为堆,当且仅当该序列满足特性:
Ki≤K2i Ki ≤K2i+1(1≤ I≤ [N/2])
堆实质上是满足如下性质的完全二叉树:树中任一非叶子结点的关键字均大于等于其孩子结点的关键字。例如序列10,15,56,25,30,70就是一个 堆,它对应的完全二叉树如上图所示。这种堆中根结点(称为堆顶)的关键字最小,我们把它称为小根堆。反之,若完全二叉树中任一非叶子结点的关键字均大于等 于其孩子的关键字,则称之为大根堆。
3.排序过程:
堆排序正是利用小根堆(或大根堆)来选取当前无序区中关键字小(或最大)的记录实现排序的。我们不妨利用大根堆来排序。每一趟排序的基本操作是:将当前无 序区调整为一个大根堆,选取关键字最大的堆顶记录,将它和无序区中的最后一个记录交换。这样,正好和直接选择排序相反,有序区是在原记录区的尾部形成并逐 步向前扩大到整个记录区。
【示例】:对关键字序列42,13,91,23,24,16,05,88建堆
五、直接插入排序(Insertion Sort)
1. 基本思想:
每次将一个待排序的数据元素,插入到前面已经排好序的数列中的适当位置,使数列依然有序;直到待排序数据元素全部插入完为止。
2. 排序过程:
【示例】:
[初始关键字] [49] 38 65 97 76 13 27 49
J=2(38) [38 49] 65 97 76 13 27 49
J=3(65) [38 49 65] 97 76 13 27 49
J=4(97) [38 49 65 97] 76 13 27 49
J=5(76) [38 49 65 76 97] 13 27 49
J=6(13) [13 38 49 65 76 97] 27 49
J=7(27) [13 27 38 49 65 76 97] 49
J=8(49) [13 27 38 49 49 65 76 97]
六、希尔排序
1.排序思想:
先 取一个小于n的证书d1作为第一个增量,把文件的全部记录分成d1组。所有距离为d1的倍数的记录放在同一组中。先在各组内进行直接插入排序,然后取第二 个增量d2<d1重复上述的分组和排序,直到所取的增量dt=1,即所有记录放在同一组中进行直接插入排序为止。该方法实际上是一种分组插入方法。
2.排序过程:
[初始关键字] 72 28 51 17 96 62 87 33 45 24
d1=n/2=5 62 28 33 17 24 72 87 51 45 96
d2=d1/2=3 17 24 33 62 28 45 87 51 72 96
d3=d2/2=1 17 24 28 33 45 51 62 72 87 96
七、归并排序
1.排序思想:
设两个有序的子文件(相当于输入堆)放在同一向量中相邻的位置上:R[low..m],R[m+1..high],先将它们合并到一个局部的暂存向量R1(相当于输出堆)中,待合并完成后将R1复制回R[low..high]中。
2.排序过程:
【示例】:
初始关键字 [46][38][56][30][88][80][38]
第一趟归并后[38 46][30 56][80 88][38]
第二趟归并后[30 38 46 56][38 80 88]
最终归并结果[30 38 38 46 56 80 88]
八、基数排序
1.排序思想:
(1)根据数据项个位上的值,把所有的数据项分为10组;
(2)然后对这10组数据重新排列:把所有以0结尾的数据排在最前面,然后是结尾是1的数据项,照此顺序直到以9结尾的数据,这个步骤称为第一趟子排序;
(3)在第二趟子排序中,再次把所有的数据项分为10组,但是这一次是根据数据项十位上的值来分组的。这次分组不能改变先前的排序顺序。也就是说,第二趟排序之后,从每一组数据项的内部来看,数据项的顺序保持不变;
(4)然后再把10组数据项重新合并,排在最前面的是十位上为0的数据项,然后是10位为1的数据项,如此排序直到十位上为9的数据项。
(5)对剩余位重复这个过程,如果某些数据项的位数少于其他数据项,那么认为它们的高位为0。
2.排序过程
【示例】
初始关键字 421 240 035 532 305 430 124
第一趟排序后[240 430] [421] [532] [124] [035 305]
第二趟排序后(305) (421 124) (430 532 035) (240)
最后排序结果(035) (124) (240) (305) (421 430) (532)
出处:https://www.cnblogs.com/angelye/p/7508292.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗