
PHP 数组底层实现原理
数组在 PHP 中非常强大、灵活的一种数据类型,和 Java、C 等静态语言不同,我们在初始化 PHP 数组的时候不必指定大小和存储数据的类型,在赋值的时候可以通过数字索引,也可以通过字符串索引的方式:

基于 PHP 数组的强大特性,我们可以轻易实现更加复杂的数据结构,比如栈、队列、列表、集合、字典等。PHP 数组功能之所以如此强大,得益于底层基于散列表实现。
PHP数组底层数据结构
PHP 数组底层依赖的散列表数据结构定义如下(位于 Zend/zend_types.h):
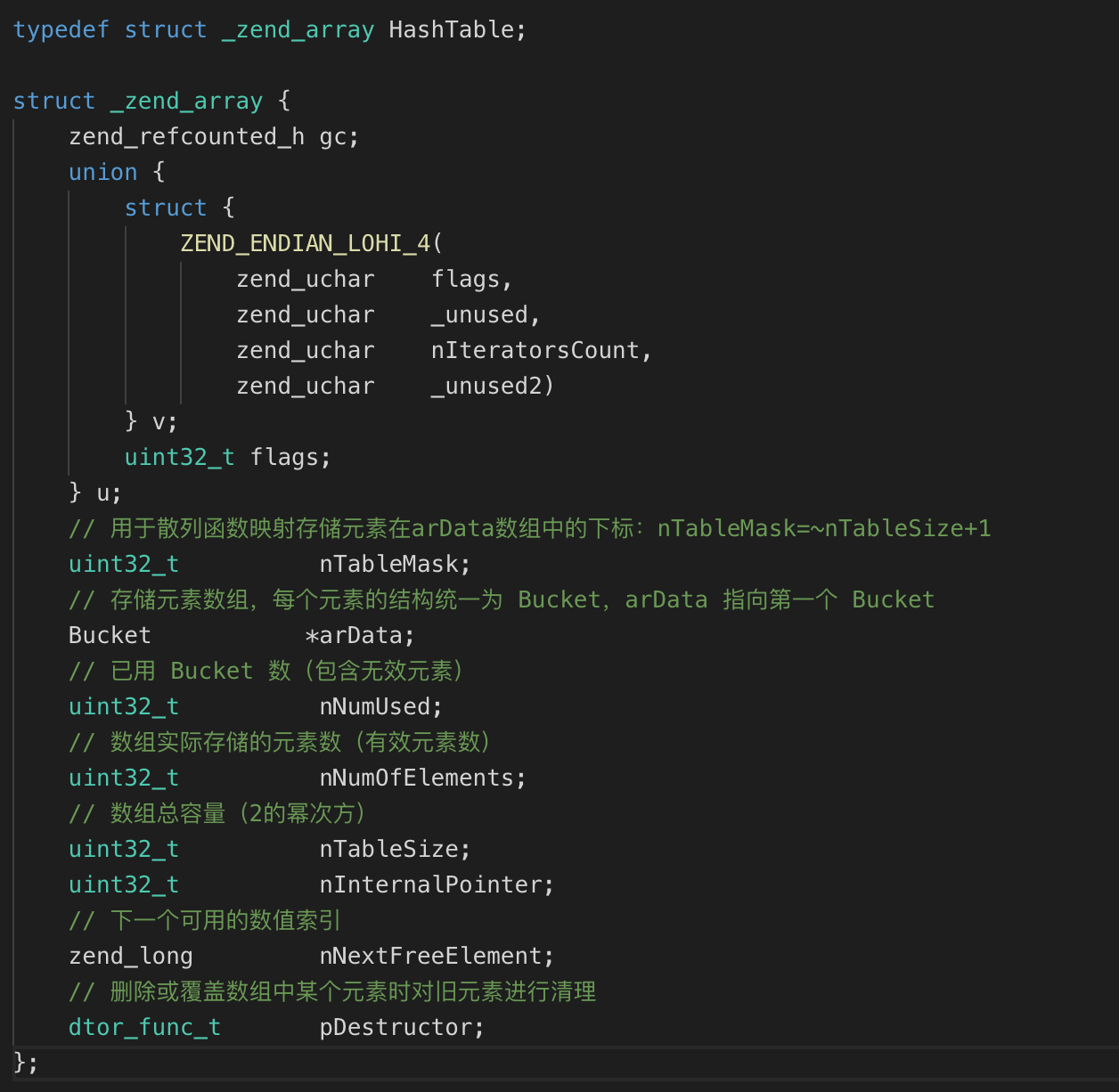
这个散列表中有很多成员,我们挑几个比较重要的来讲讲:
- arData:散列表中保存存储元素的数组,其内存是连续的,arData指向数组的起始位置;
- nTableSize:数组的总容量,即可以容纳的元素数,arData 的内存大小就是根据这个值确定的,它的大小的是2的幂次方,最小为8,然后按照 8、16、32...依次递增;
- nTableMask:这个值在散列函数根据 key 的哈希值映射元素的时候用到,它的值实际就是 nTableSize 的负数,即 nTableMask = -nTableSize,用位运算来表示就是 nTableMask = ~nTableSize+1;
- nNumUsed、nNumOfElements:nNumUsed 是指数组当前使用的 Bucket 数,但不是数组有效元素个数,因为某个数组元素被删除后并没有立即从数组中删除,而是将其标记为 IS_UNDEF,只有在数组需要扩容时才会真正删除,nNumOfElements 则表示数组中有效的元素数量,即调用 count 函数返回值,如果没有扩容,nNumUsed 一直递增,无论是否删除元素;
- nNextFreeElement:这个是给自动确定数值索引使用的,默认从 0 开始,比如 $arr[] = 200,这个时候 nNextFreeElement 值会自动加 1;
- pDestructor:当删除或覆盖数组中的某个元素时,如果提供了这个函数句柄,则在删除或覆盖时调用此函数,对旧元素进行清理;
- u:这个联合体结构主要用于一些辅助作用
Bucket 的结构比较简单,主要用来保存元素的 key 和 value,以及一个整型的 h(散列值,或者叫哈希值):如果元素是数值索引,则其值就是数值索引的值;如果是字符串索引,那么其值就是 key 通过 Time33 算法计算得到的散列值,h 的值用来最终映射元素的存储位置。Bucket 的数据结构如下:

PHP 数组的基本实现
散列表主要由两部分组成:存储元素数组、散列函数。散列表的基本实现前面已经探讨过,PHP 中的数组除了具备散列表的基本特点之外,还有一个特别的地方,那就是它是有序的(与Java中的HashMap的无序有所不同):数组中各元素的顺序和插入顺序一致。这个是怎么实现的呢?
为了实现 PHP 数组的有序性,PHP 底层的散列表在散列函数与元素数组之间加了一层映射表,这个映射表也是一个数组,大小和存储元素的数组相同,存储元素的类型为整型,用于保存元素在实际存储的有序数组中的下标 —— 元素按照先后顺序依次插入实际存储数组,然后将其数组下标按照散列函数散列出来的位置存储在新加的映射表中:
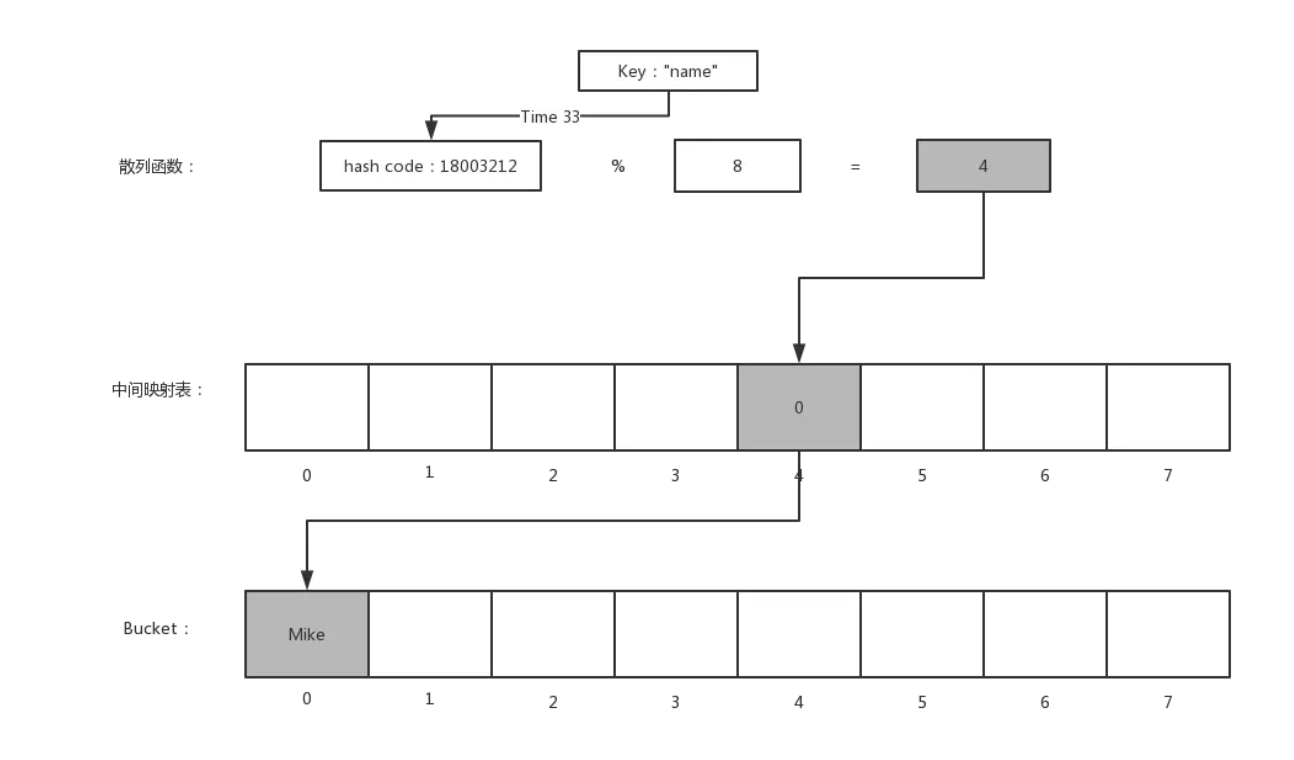
这样,就可以完成最终存储数据的有序性了。
PHP 数组底层结构中并没有显式标识这个中间映射表,而是与 arData 放到了一起,在数组初始化的时候并不仅仅分配用于存储 Bucket 的内存,还会分配相同数量的 uint32_t 大小的空间,这两块空间是一起分配的,然后将 arData 偏移到存储元素数组的位置,而这个中间映射表就可以通过 arData 向前访问到。
数组的初始化
数组的初始化主要是针对 HashTable 成员的设置,初始化时并不会立即分配 arData 的内存,插入第一个元素之后才会分配 arData 的内存。初始化操作可以通过 zend_hash_init 宏完成,最后由 _zend_hash_init_int 函数处理(该函数定义在 Zend/zend_hash.c 文件中):
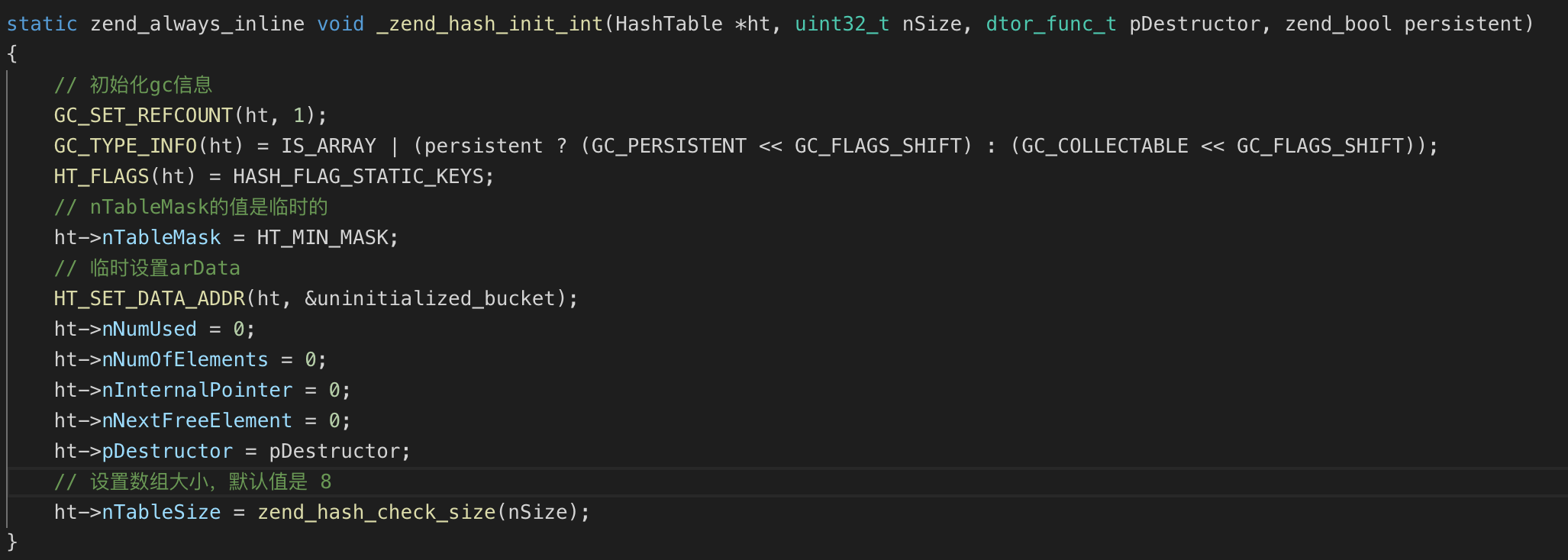
此时的 HashTable 只是设置了散列表的大小及其他成员的初始值,还无法用来存储元素。
插入数据
插入时会检查数组是否已经分配存储空间,因为初始化并没有实际分配 arData 的内存,在第一次插入时才会根据 nTableSize 的大小分配,分配以后会把 HashTable->u.flags 打上 HASH_FLAG_INITIALIZED 掩码,这样,下次插入时发现已经分配了就不会重复操作,这段检查逻辑位于 _zend_hash_add_or_update_i 函数中:
if (UNEXPECTED(!(HT_FLAGS(ht) & HASH_FLAG_INITIALIZED))) { zend_hash_real_init_mixed(ht); if (!ZSTR_IS_INTERNED(key)) { zend_string_addref(key); HT_FLAGS(ht) &= ~HASH_FLAG_STATIC_KEYS; zend_string_hash_val(key); } goto add_to_hash; }
如果 arData 还没有分配,则最终由 zend_hash_real_init_mixed_ex 完成内存分配:

分配完 arData 的内存后就可以进行插入操作了,插入时先将元素按照顺序插入 arData,然后将其在 arData 数组中的位置存储到根据 key 的散列值与 nTableMask 计算得到的中间映射表中的对应位置:
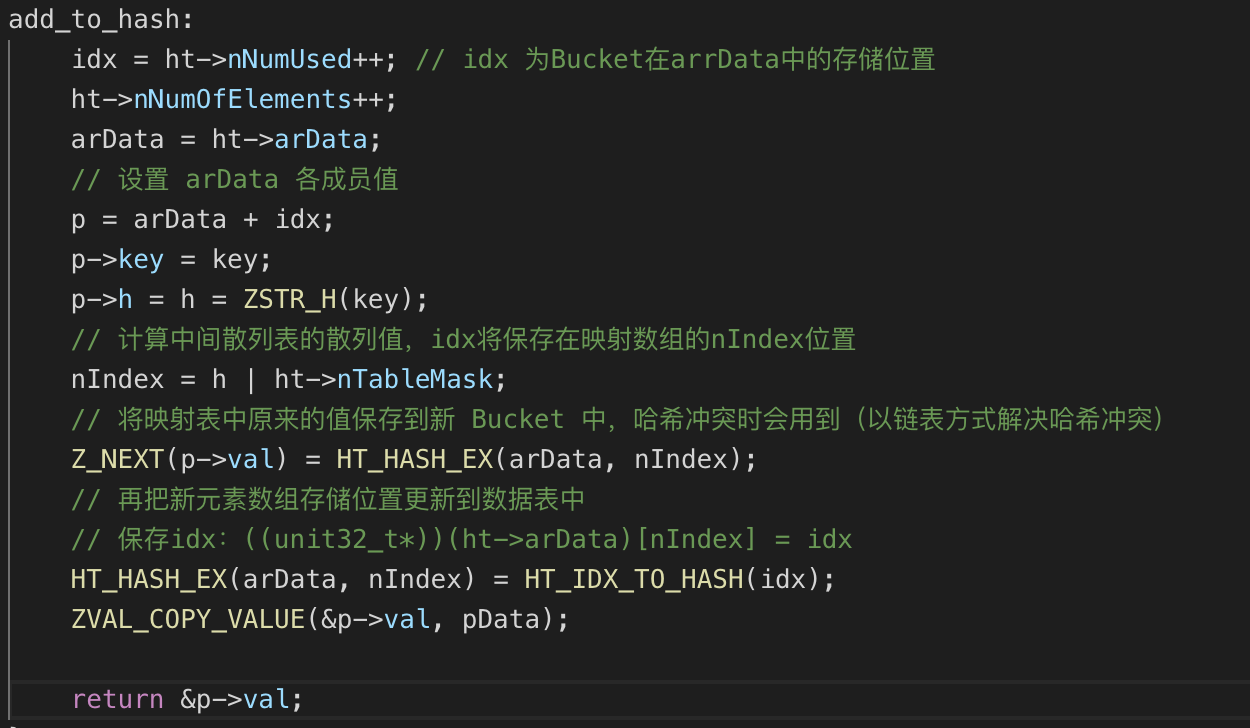
上述只是最基本的插入处理,不涉及已存在数据的覆盖和清理。
哈希冲突
PHP 数组底层的散列表采用链地址法解决哈希冲突,即将冲突的 Bucket 串成链表。
HashTable 中的 Bucket 会记录与它冲突的元素在 arData 数组中的位置,这也是一个链表,冲突元素的保存位置不在 Bucket 结构中,而是保存在了存储元素 zval 的 u2 结构中,即 Bucket.val.u2.next,所以插入时分为以下两步:
// 将映射表中原来的值保存到新 Bucket 中,哈希冲突时会用到(以链表方式解决哈希冲突) Z_NEXT(p->val) = HT_HASH_EX(arData, nIndex); // 再把新元素数组存储位置更新到数据表中 // 保存idx:((unit32_t*))(ht->arData)[nIndex] = idx HT_HASH_EX(arData, nIndex) = HT_IDX_TO_HASH(idx);
数组查找
清楚了 HashTable 的实现和哈希冲突的解决方式之后,查找的过程就比较简单了:首先根据 key 计算出的散列值与 nTableMask 计算得到最终散列值 nIndex,然后根据散列值从中间映射表中得到存储元素在有序存储数组中的位置 idx,接着根据 idx 从有序存储数组(即 arData)中取出 Bucket,遍历该 Bucket,判断 Bucket 的 key 是否是要查找的 key,如果是则终止遍历,否则继续根据 zval.u2.next 遍历比较。
对应的底层源码如下:
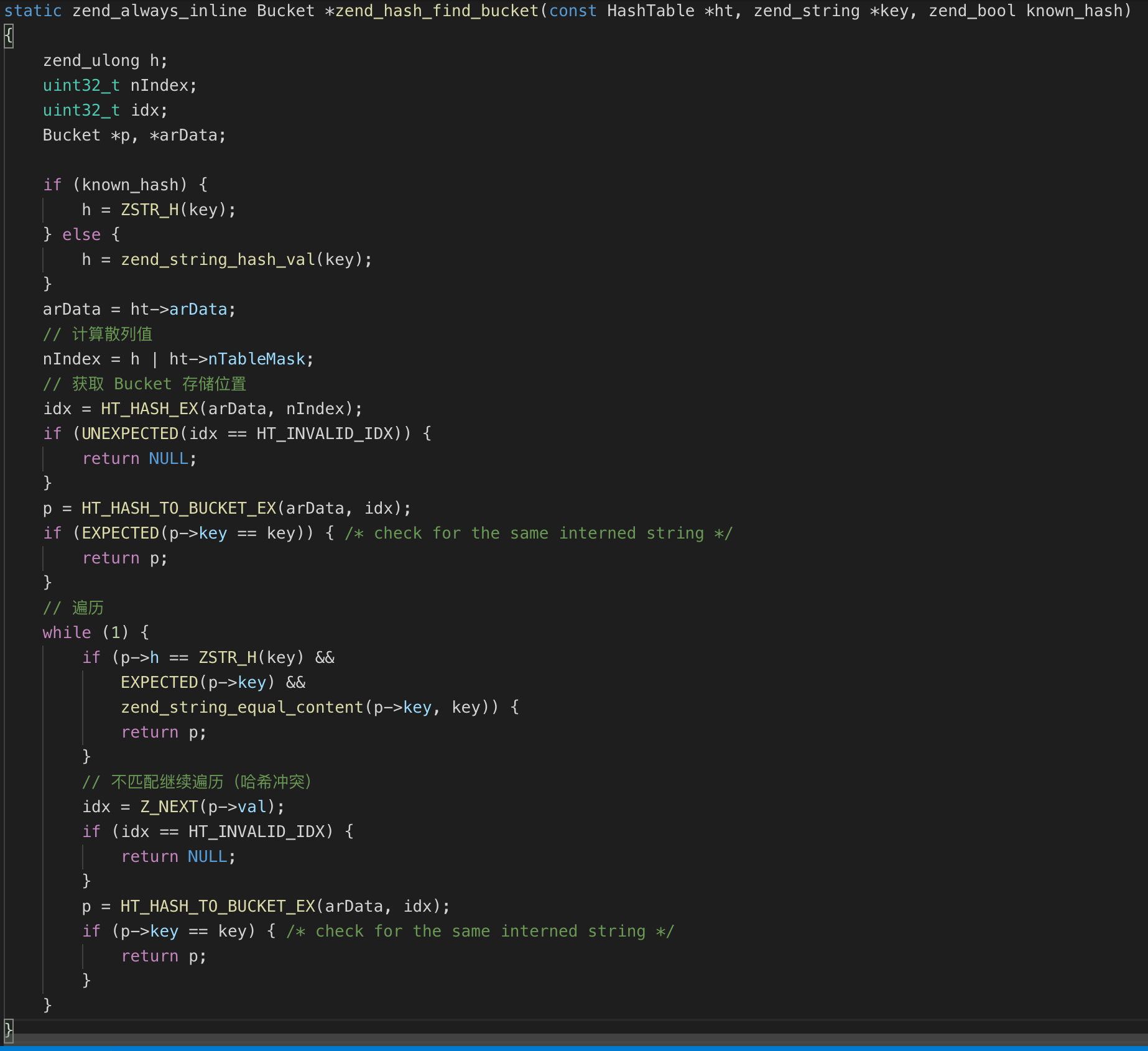
删除数据
关于数组数据删除前面我们在介绍散列表中的 nNumUsed 和 nNumOfElements 字段时已经提及过,从数组中删除元素时,并没有真正移除,并重新 rehash,而是当 arData 满了之后,才会移除无用的数据,从而提高性能。即数组在需要扩容的情况下才会真正删除元素:首先检查数组中已删除元素所占比例,如果比例达到阈值则触发重新构建索引的操作,这个过程会把已删除的 Bucket 移除,然后把后面的 Bucket 往前移动补上空位,如果还没有达到阈值则会分配一个原数组大小 2 倍的新数组,然后把原数组的元素复制到新数组上,最后重建索引,重建索引会将已删除的 Bucket 移除。
对应底层代码如下:
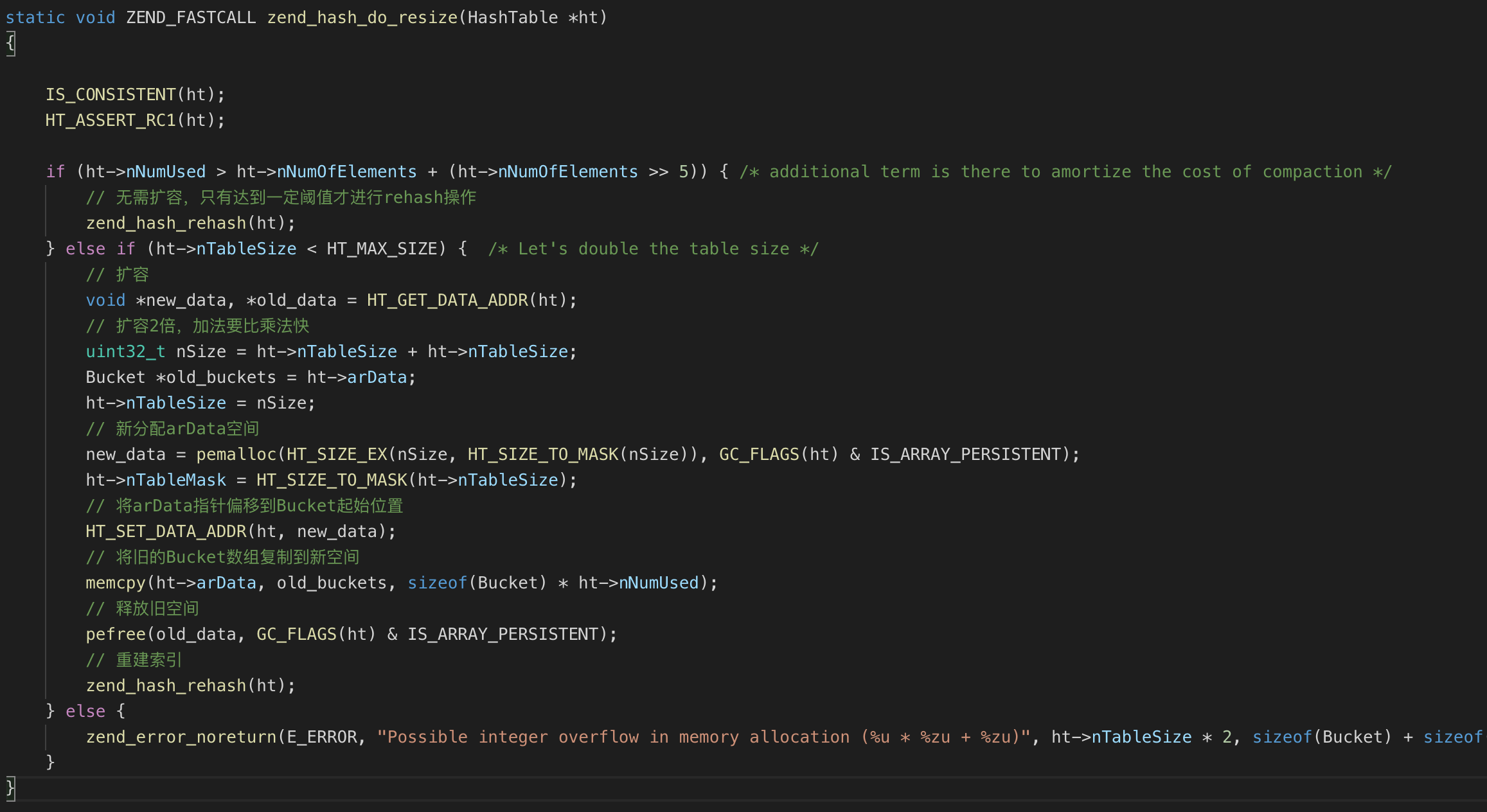
除此之外,数组还有很多其他操作,比如复制、合并、销毁、重置等,这些操作对应的代码都位于 zend_hash.c 中,感兴趣的同学可以去看看。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号