
MySQL优化/面试,看这一篇就够了
概述
为什么要优化
- 系统的吞吐量瓶颈往往出现在数据库的访问速度上
- 随着应用程序的运行,数据库的中的数据会越来越多,处理时间会相应变慢
- 数据是存放在磁盘上的,读写速度无法和内存相比
如何优化
- 设计数据库时:数据库表、字段的设计,存储引擎
- 利用好MySQL自身提供的功能,如索引等
- 横向扩展:MySQL集群、负载均衡、读写分离
- SQL语句的优化(收效甚微)
字段设计
- 字段类型的选择,设计规范,范式,常见设计案例
原则:尽量使用整型表示字符串
存储IP
INET_ATON(str),address to number INET_ATON('192.168.1.1') //3232235777
INET_NTOA(number),number to address INET_NTOA('3232235777') //192.168.1.1
MySQL内部的枚举类型(单选)和集合(多选)类型
但是因为维护成本较高因此不常使用,使用关联表的方式来替代enum
原则:定长和非定长数据类型的选择
decimal不会损失精度,存储空间会随数据的增大而增大。
double 占用固定空间,较大数的存储会损失精度。非定长的还有varchar、text
金额
对数据的精度要求较高,小数的运算和存储存在精度问题(不能将所有小数转换成二进制)
定点数decimal
price decimal(8,2)有2位小数的定点数,定点数支持很大的数(甚至是超过int,bigint存储范围的数)
小单位大数额避免出现小数 : 元->分
字符串存储
定长char,非定长varchar、text(上限65535,其中varchar还会消耗1-3字节记录长度,而text使用额外空间记录长度)
原则:尽可能选择小的数据类型和指定短的长度
原则:尽可能使用 not null
非null字段的处理要比null字段的处理高效些!且不需要判断是否为null。 null在MySQL中,不好处理,存储需要额外空间,运算也需要特殊的运算符。
如select null = null和select null <> null(<>为不等号)有着同样的结果,只能通过is null和is not null来判断字段是否为null。 如何存储?
MySQL中每条记录都需要额外的存储空间,表示每个字段是否为null。因此通常使用特殊的数据进行占位,比如int not null default 0、string not null default ‘’
原则:字段注释要完整,见名知意
原则:单表字段不宜过多 : 二三十个就极限了
原则:可以预留字段
在使用以上原则之前首先要满足业务需求
关联表的设计
外键foreign key只能实现一对一或一对多的映射
一对多:使用外键
多对多:单独新建一张表将多对多拆分成两个一对多
一对一
如商品的基本信息(item)和商品的详细信息(item_intro),通常使用相同的主键或者增加一个外键字段(item_id)
范式 Normal Format
数据表的设计规范,一套越来越严格的规范体系(如果需要满足N范式,首先要满足N-1范式)。
第一范式1NF:字段原子性
字段原子性,字段不可再分割。
关系型数据库,默认满足第一范式。
注意:
注意比较容易出错的一点,在一对多的设计中使用逗号分隔多个外键,这种方法虽然存储方便,但不利于维护和索引(比如查找带标签java的文章)
第二范式:消除对主键的部分依赖
即在表中加上一个与业务逻辑无关的字段作为主键
主键:可以唯一标识记录的字段或者字段集合。
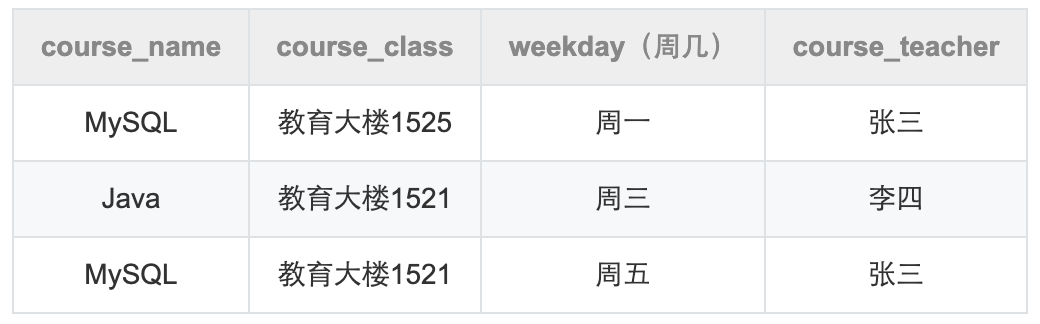
依赖:A字段可以确定B字段,则B字段依赖A字段。比如知道了下一节课是数学课,就能确定任课老师是谁。于是周几和下一节课和就能构成复合主键,能够确定去哪个教室上课,任课老师是谁等。但我们常常增加一个id作为主键,而消除对主键的部分依赖。
对主键的部分依赖:某个字段依赖复合主键中的一部分。
解决方案:新增一个独立字段作为主键。
第三范式:消除对主键的传递依赖
传递依赖:B字段依赖于A,C字段又依赖于B。比如上例中,任课老师是谁取决于是什么课,是什么课又取决于主键id。因此需要将此表拆分为两张表日程表和课程表(独立数据独立建表)

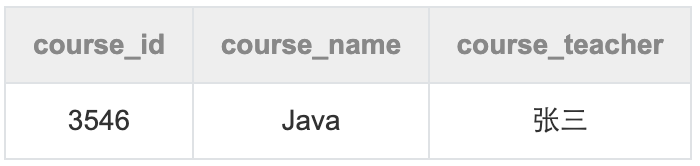
这样就减少了数据的冗余(即使周一至周日每天都有Java课,也只是course_id:3546出现了7次)
存储引擎选择
早期问题:如何选择MyISAM和Innodb?
现在不存在这个问题了,Innodb不断完善,从各个方面赶超MyISAM,也是MySQL默认使用的。
5.5之前默认引擎是MyISAM,5.5以后默认引擎是Innodb
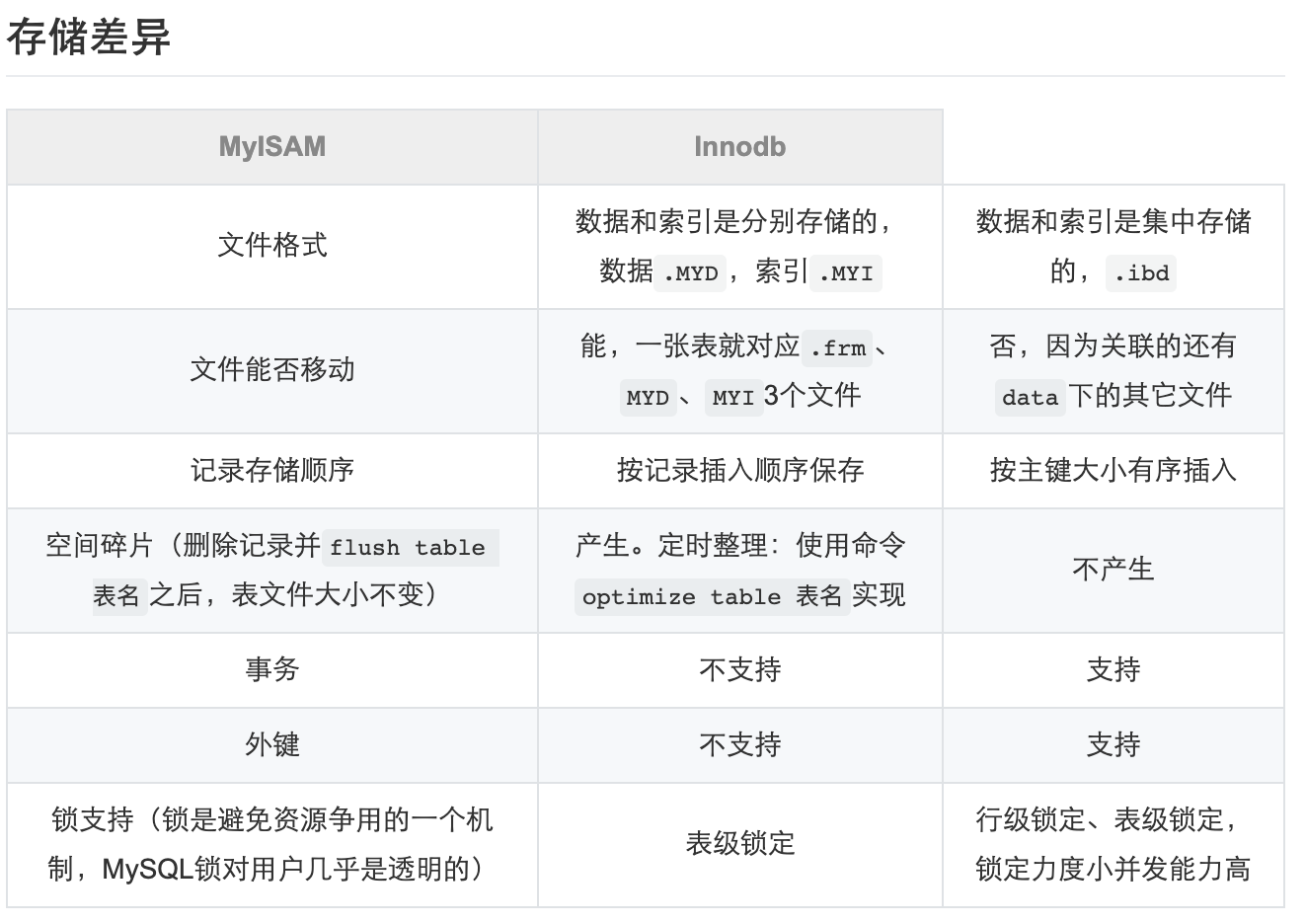
功能差异
show engines
见另外一篇文章
锁扩展 表级锁(table-level lock):lock tables <table_name1>,<table_name2>... read/write,unlock tables <table_name1>,<table_name2>...。
read是共享锁,一旦锁定任何客户端都不可读;
write是独占/写锁,只有加锁的客户端可读可写,其他客户端既不可读也不可写。
锁定的是一张表或几张表。 行级锁(row-level lock):锁定的是一行或几行记录。
共享锁:select * from <table_name> where <条件> LOCK IN SHARE MODE;对查询的记录增加共享锁;
排他锁:select * from <table_name> where <条件> FOR UPDATE;对查询的记录增加排他锁。
注意 :innodb的行锁,其实是一个子范围锁,依据条件锁定部分范围,而不是就映射到具体的行上,因此还有一个学名:间隙锁。
比如select * from stu where id < 20 LOCK IN SHARE MODE会锁定id在20左右以下的范围,你可能无法插入id为18或22的一条新纪录。
选择依据
如果没有特别的需求,使用默认的Innodb即可。
MyISAM:以读写插入为主的应用程序,比如博客系统、新闻门户网站。
Innodb:更新(删除)操作频率也高,或者要保证数据的完整性;并发量高,支持事务和外键保证数据完整性。比如OA自动化办公系统。
索引
关键字与数据的映射关系称为索引(==包含关键字和对应的记录在磁盘中的地址==)。关键字是从数据当中提取的用于标识、检索数据的特定内容。
索引检索为什么快?
- 关键字相对于数据本身,==数据量小==
- 关键字是==有序==的,二分查找可快速确定位置
图书馆为每本书都加了索引号(类别-楼层-书架)、字典为词语解释按字母顺序编写目录等都用到了索引。
MySQL中索引类型
- 普通索引(
key) - 唯一索引(
unique key) - 主键索引(
primary key) - 全文索引(
fulltext key)
三种索引的索引方式是一样的,只不过对索引的关键字有不同的限制:
- 普通索引:对关键字没有限制
- 唯一索引:要求记录提供的关键字不能重复
- 主键索引:要求关键字唯一且不为null
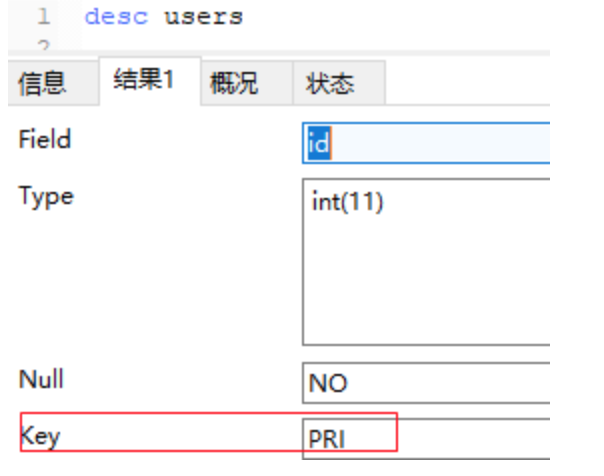
查看索引
show create table 表名
desc 表名
创建索引
创建表之后建立索引
create TABLE user_index( id int auto_increment primary key, first_name varchar(16), last_name VARCHAR(16), id_card VARCHAR(18), information text ); -- 更改表结构 alter table user_index -- 创建一个first_name和last_name的复合索引,并命名为name add key name (first_name,last_name), -- 创建一个id_card的唯一索引,默认以字段名作为索引名 add UNIQUE KEY (id_card), -- 鸡肋,全文索引不支持中文 add FULLTEXT KEY (information);
show create table user_index
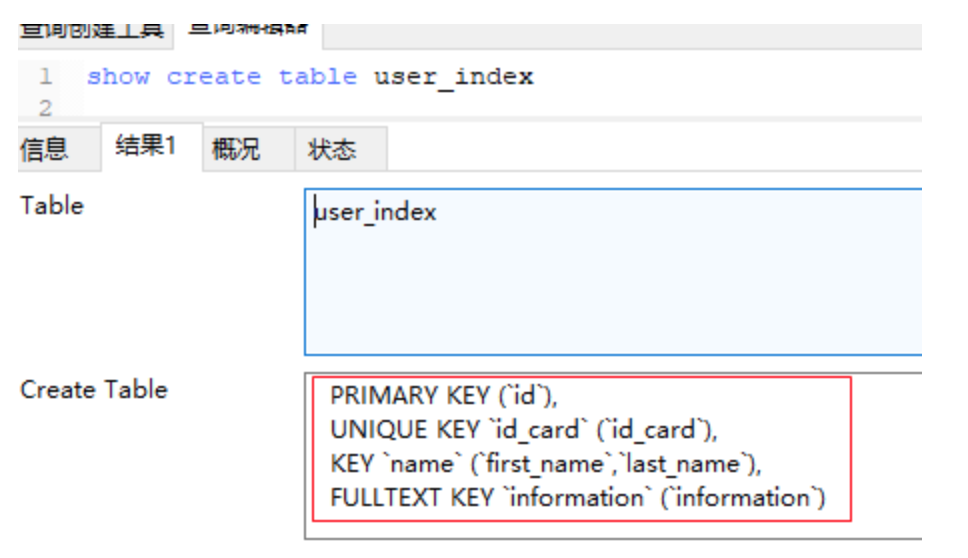
创建表时指定索引
CREATE TABLE user_index2 ( id INT auto_increment PRIMARY KEY, first_name VARCHAR (16), last_name VARCHAR (16), id_card VARCHAR (18), information text, KEY name (first_name, last_name), FULLTEXT KEY (information), UNIQUE KEY (id_card) );
删除索引
根据索引名删除普通索引、唯一索引、全文索引:alter table 表名 drop KEY 索引名
alter table user_index drop KEY name;
alter table user_index drop KEY id_card;
alter table user_index drop KEY information;
删除主键索引:alter table 表名 drop primary key(因为主键只有一个)。
注意:如果主键自增长,那么不能直接执行此操作(自增长依赖于主键索引)
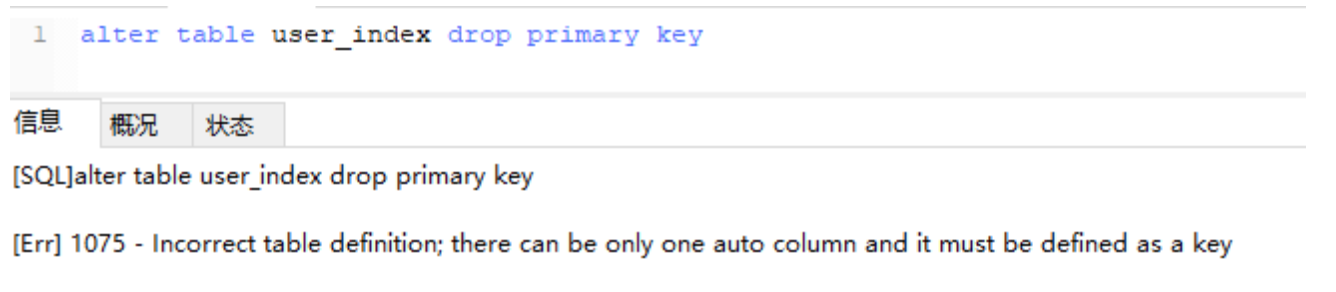
需要取消自增长再行删除:
alter table user_index -- 重新定义字段 MODIFY id int, drop PRIMARY KEY
但通常不会删除主键,因为设计主键一定与业务逻辑无关。
执行计划explain
CREATE TABLE innodb1 ( id INT auto_increment PRIMARY KEY, first_name VARCHAR (16), last_name VARCHAR (16), id_card VARCHAR (18), information text, KEY name (first_name, last_name), FULLTEXT KEY (information), UNIQUE KEY (id_card) ); insert into innodb1 (first_name,last_name,id_card,information) values ('张','三','1001','华山派');
可以通过explain selelct来分析SQL语句执行前的执行计划:
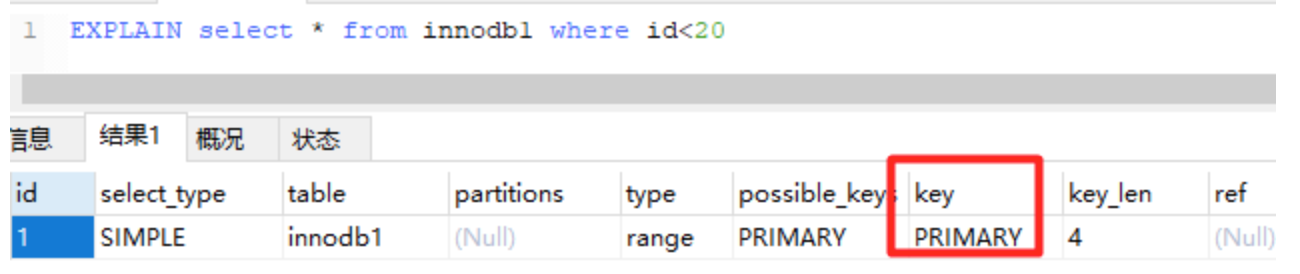
由上图可看出此SQL语句是按照主键索引来检索的。
执行计划是:当执行SQL语句时,首先会分析、优化,形成执行计划,在按照执行计划执行。
索引使用场景(重点)
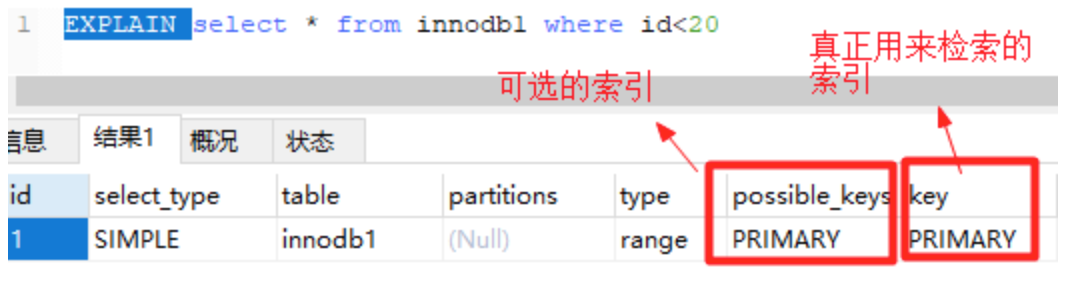
上图中,根据id查询记录,因为id字段仅建立了主键索引,因此此SQL执行可选的索引只有主键索引,如果有多个,最终会选一个较优的作为检索的依据。
-- 增加一个没有建立索引的字段 alter table innodb1 add sex char(1); -- 按sex检索时可选的索引为null EXPLAIN SELECT * from innodb1 where sex='男';
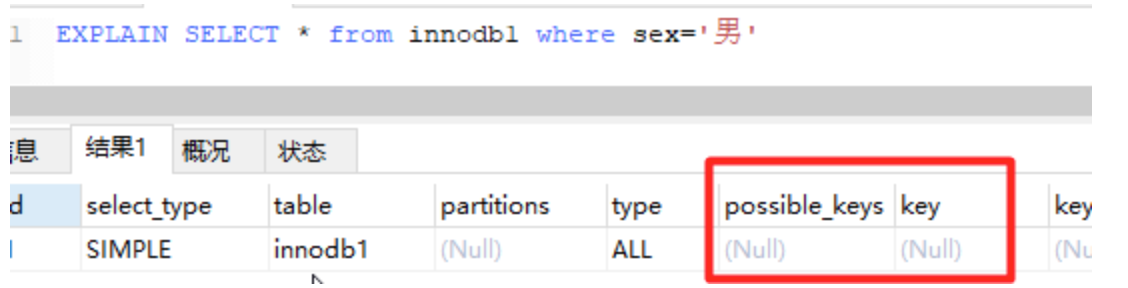
可以尝试在一个字段未建立索引时,根据该字段查询的效率,然后对该字段建立索引(alter table 表名 add index(字段名)),同样的SQL执行的效率,你会发现查询效率会有明显的提升(数据量越大越明显)。
order by
当我们使用order by将查询结果按照某个字段排序时,如果该字段没有建立索引,那么执行计划会将查询出的所有数据使用外部排序(将数据从硬盘分批读取到内存使用内部排序,最后合并排序结果),这个操作是很影响性能的,因为需要将查询涉及到的所有数据从磁盘中读到内存(如果单条数据过大或者数据量过多都会降低效率),更无论读到内存之后的排序了。
但是如果我们对该字段建立索引alter table 表名 add index(字段名),那么由于索引本身是有序的,因此直接按照索引的顺序和映射关系逐条取出数据即可。而且如果分页的,那么只用取出索引表某个范围内的索引对应的数据,而不用像上述那取出所有数据进行排序再返回某个范围内的数据。(从磁盘取数据是最影响性能的)
join
对join语句匹配关系(on)涉及的字段建立索引能够提高效率
索引覆盖
如果要查询的字段都建立过索引,那么引擎会直接在索引表中查询而不会访问原始数据(否则只要有一个字段没有建立索引就会做全表扫描),这叫索引覆盖。因此我们需要尽可能的在select后==只写必要的查询字段==,以增加索引覆盖的几率。
这里值得注意的是不要想着为每个字段建立索引,因为优先使用索引的优势就在于其体积小。
语法细节(要点)
在满足索引使用的场景下(where/order by/join on或索引覆盖),索引也不一定被使用
字段要独立出现
比如下面两条SQL语句在语义上相同,但是第一条会使用主键索引而第二条不会。
select * from user where id = 20-1; select * from user where id+1 = 20;
like查询,不能以通配符开头
比如搜索标题包含mysql的文章:
select * from article where title like '%mysql%';
这种SQL的执行计划用不了索引(like语句匹配表达式以通配符开头),因此只能做全表扫描,效率极低,在实际工程中几乎不被采用。而一般会使用第三方提供的支持中文的全文索引来做。
但是 关键字查询 热搜提醒功能还是可以做的。
比如键入mysql之后提醒mysql 教程、mysql 下载、mysql 安装步骤等。用到的语句是:
select * from article where title like 'mysql%';
这种like是可以利用索引的(当然前提是title字段建立过索引)。
复合索引只对第一个字段有效
建立复合索引:
alter table person add index(first_name,last_name);
其原理就是将索引先按照从first_name中提取的关键字排序,如果无法确定先后再按照从last_name提取的关键字排序,也就是说该索引表只是按照记录的first_name字段值有序。
因此select * from person where first_name = ?是可以利用索引的,而select * from person where last_name = ?无法利用索引。
那么该复合索引的应用场景是什么?==组合查询==
比如对于select * person from first_name = ? and last_name = ?,复合索引就比对first_name和last_name单独建立索引要高效些。
很好理解,复合索引首先二分查找与first_name = ?匹配的记录,再在这些记录中二分查找与last_name匹配的记录,只涉及到一张索引表。
而分别单独建立索引则是在first_name索引表中二分找出与first_name = ?匹配的记录,再在last_name索引表中二分找出与last_name = ?的记录,两者取交集。
or,两边条件都有索引可用
一但有一边无索引可用就会导致整个SQL语句的全表扫描
状态值,不容易使用到索引
如性别、支付状态等状态值字段往往只有极少的几种取值可能,这种字段即使建立索引,也往往利用不上。
这是因为,一个状态值可能匹配大量的记录,这种情况MySQL会认为利用索引比全表扫描的效率低,从而弃用索引。
索引是随机访问磁盘,而全表扫描是顺序访问磁盘,这就好比有一栋20层楼的写字楼,楼底下的索引牌上写着某个公司对应不相邻的几层楼,你去公司找人,与其按照索引牌的提示去其中一层楼没找到再下来看索引牌再上楼,不如从1楼挨个往上找到顶楼。
如何创建索引
- 建立基础索引:在
where、order by、join字段上建立索引。 - 优化,组合索引:基于业务逻辑
- 如果条件经常性出现在一起,那么可以考虑将多字段索引升级为==复合索引==
- 如果通过增加个别字段的索引,就可以出现==索引覆盖==,那么可以考虑为该字段建立索引
- 查询时,不常用到的索引,应该删除掉
前缀索引
语法:index(field(10)),使用字段值的前10个字符建立索引,默认是使用字段的全部内容建立索引。
前提:前缀的标识度高。比如密码就适合建立前缀索引,因为密码几乎各不相同。
==实操的难度==:在于前缀截取的长度。
可以利用select count(*)/count(distinct left(password,prefixLen));通过调整prefixLen的值(从1自增)查看不同前缀长度的一个平均匹配度,接近1时就可以了(表示一个密码的前prefixLen个字符几乎能确定唯一一条记录)
索引的存储结构
BTree
btree(多路平衡查找树)是一种广泛应用于==磁盘上实现索引功能==的一种数据结构,也是大多数数据库索引表的实现。
以add index(first_name,last_name)为例:
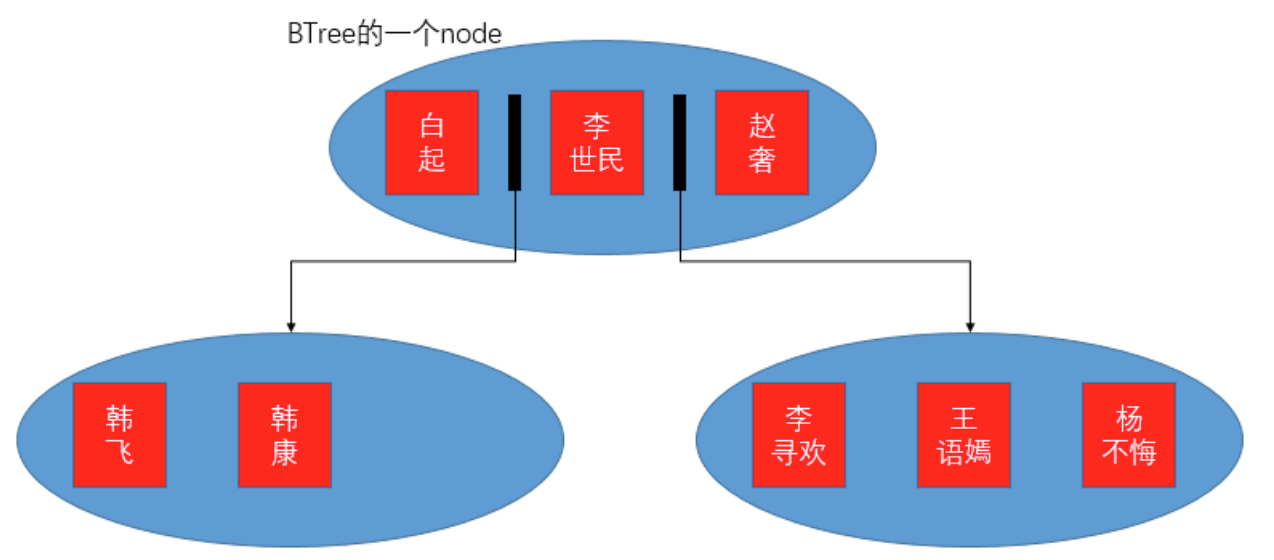
BTree的一个node可以存储多个关键字,node的大小取决于计算机的文件系统,因此可以通过减小索引字段的长度使结点存储更多的关键字。如果node中的关键字已满,那么可以通过每个关键字之间的子节点指针来拓展索引表,但是不能破坏结构的有序性,比如按照first_name第一有序、last_name第二有序的规则,新添加的韩香就可以插到韩康之后。白起 < 韩飞 < 韩康 < 李世民 < 赵奢 < 李寻欢 < 王语嫣 < 杨不悔。这与二叉搜索树的思想是一样的,只不过二叉搜索树的查找效率是log(2,N)(以2为底N的对数),而BTree的查找效率是log(x,N)(其中x为node的关键字数量,可以达到1000以上)。
从log(1000+,N)可以看出,少量的磁盘读取即可做到大量数据的遍历,这也是btree的设计目的。
B+Tree聚簇结构
聚簇结构(也是在BTree上升级改造的)中,关键字和记录是存放在一起的。
在MySQL中,仅仅只有Innodb的==主键索引为聚簇结构==,其它的索引包括Innodb的非主键索引都是典型的BTree结构。
哈希索引
在索引被载入内存时,使用哈希结构来存储。
查询缓存
缓存select语句的查询结果
在配置文件中开启缓存
windows上是my.ini,linux上是my.cnf 在[mysqld]段中配置query_cache_type: 0:OFF 不开启 1:ON 开启,默认缓存所有,需要在SQL语句中增加select sql-no-cache提示来放弃缓存 2:DEMAND 开启,默认都不缓存,需要在SQL语句中增加select sql-cache来主动缓存(==常用==)
更改配置后需要重启以使配置生效,重启后可通过show variables like ‘query_cache_type’;来查看:show variables like'query_cache_type';
query_cache_type DEMAND
在客户端设置缓存大小
通过配置项query_cache_size来设置:
show variables like 'query_cache_size';query_cache_size0set global query_cache_size=64*1024*1024;show variables like'query_cache_size';query_cache_size67108864
将查询结果缓存
select sql_cache * from user;
重置缓存
reset query cache;
缓存失效问题(大问题)
当数据表改动时,基于该数据表的任何缓存都会被删除。(表层面的管理,不是记录层面的管理,因此失效率较高)
注意事项
- 应用程序,不应该关心
query cache的使用情况。可以尝试使用,但不能由query cache决定业务逻辑,因为query cache由DBA来管理。 - 缓存是以SQL语句为key存储的,因此即使SQL语句功能相同,但如果多了一个空格或者大小写有差异都会导致匹配不到缓存。
分区
一般情况下我们创建的表对应一组存储文件,使用MyISAM存储引擎时是一个.MYI和.MYD文件,使用Innodb存储引擎时是一个.ibd和.frm(表结构)文件。
当数据量较大时(一般千万条记录级别以上),MySQL的性能就会开始下降,这时我们就需要将数据分散到多组存储文件,==保证其单个文件的执行效率==。
最常见的分区方案是按id分区,如下将id的哈希值对10取模将数据均匀分散到10个.ibd存储文件中:
create table article( id int auto_increment PRIMARY KEY, title varchar(64), content text )PARTITION by HASH(id) PARTITIONS 10; //相同的输入得到相同的输出 对10取模进行分区
查看data目录:
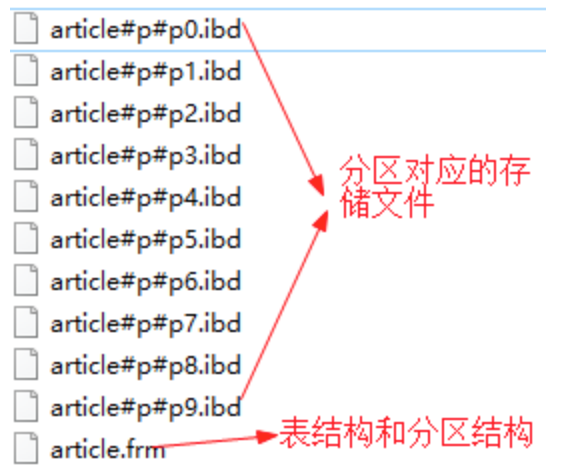
==服务端的表分区对于客户端是透明的==,客户端还是照常插入数据,但服务端会按照分区算法分散存储数据。
MySQL提供的分区算法
==分区依据的字段必须是主键的一部分==,分区是为了快速定位数据,因此该字段的搜索频次较高应作为强检索字段,否则依照该字段分区毫无意义
hash(field)
相同的输入得到相同的输出。输出的结果跟输入是否具有规律无关。==仅适用于整型字段==
key(field)
和hash(field)的性质一样,只不过key是==处理字符串==的,比hash()多了一步从字符串中计算出一个整型在做取模操作。
create table article_key( id int auto_increment, title varchar(64), content text, PRIMARY KEY (id,title) -- 要求分区依据字段必须是主键的一部分 )PARTITION by KEY(title) PARTITIONS 10;
range算法
是一种==条件分区==算法,按照数据大小范围分区(将数据使用某种条件,分散到不同的分区中)。
如下,按文章的发布时间将数据按照2018年8月、9月、10月分区存放:
create table article_range( id int auto_increment, title varchar(64), content text, created_time int, -- 发布时间到1970-1-1的毫秒数 PRIMARY KEY (id,created_time) -- 要求分区依据字段必须是主键的一部分 )charset=utf8 PARTITION BY RANGE(created_time)( PARTITION p201808 VALUES less than (1535731199), -- select UNIX_TIMESTAMP('2018-8-31 23:59:59') PARTITION p201809 VALUES less than (1538323199), -- 2018-9-30 23:59:59 PARTITION p201810 VALUES less than (1541001599) -- 2018-10-31 23:59:59 );
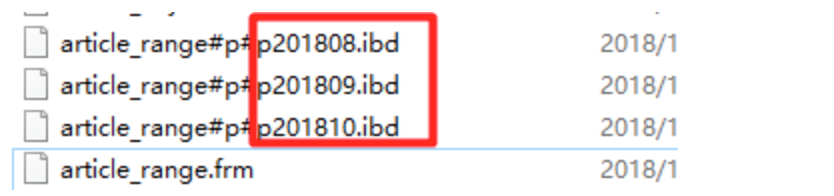
注意:条件运算符只能使用==less than==,这意味着较小的范围要放在前面,比如上述p201808,p201819,p201810分区的定义顺序依照created_time数值范围从小到大,不能颠倒。
insert into article_range values(null,'MySQL优化','内容示例',1535731180); flush tables; -- 使操作立即刷新到磁盘文件
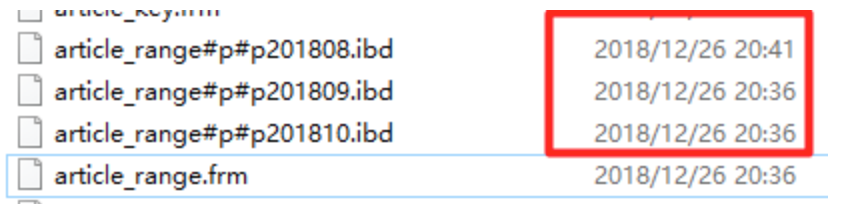
由于插入的文章的发布时间1535731180小于1535731199(2018-8-31 23:59:59),因此被存储到p201808分区中,这种算法的存储到哪个分区取决于数据状况。
list算法
也是一种条件分区,按照列表值分区(in (值列表))。
create table article_list( id int auto_increment, title varchar(64), content text, status TINYINT(1), -- 文章状态:0-草稿,1-完成但未发布,2-已发布 PRIMARY KEY (id,status) -- 要求分区依据字段必须是主键的一部分 )charset=utf8 PARTITION BY list(status)( PARTITION writing values in(0,1), -- 未发布的放在一个分区 PARTITION published values in (2) -- 已发布的放在一个分区 );
insert into article_list values(null,'mysql优化','内容示例',0); flush tables;
分区管理语法
range/list
增加分区
前文中我们尝试使用range对文章按照月份归档,随着时间的增加,我们需要增加一个月份:
alter table article_range add partition( partition p201811 values less than (1543593599) -- select UNIX_TIMESTAMP('2018-11-30 23:59:59') -- more );
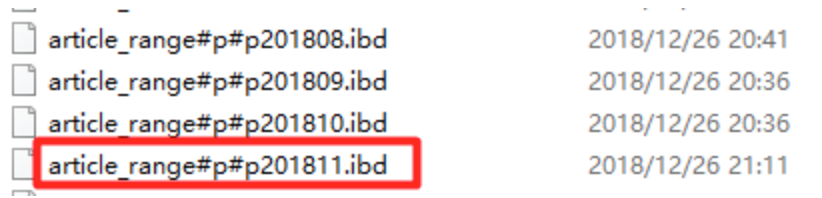
删除分区
alter table article_range drop PARTITION p201808
注意:==删除分区后,分区中原有的数据也会随之删除!==
key/hash
新增分区
alter table article_key add partition partitions 4
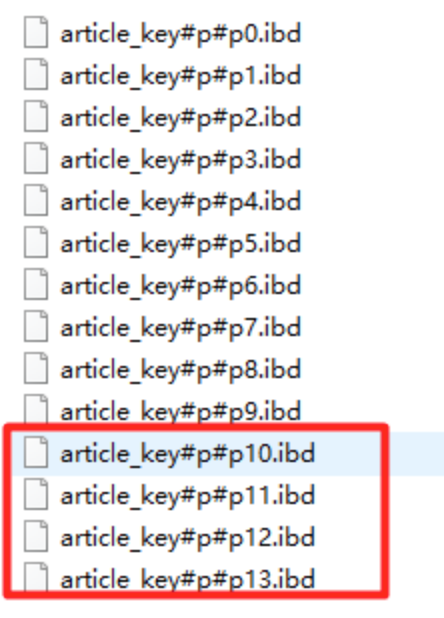
销毁分区
alter table article_key coalesce partition 6
key/hash分区的管理不会删除数据,但是每一次调整(新增或销毁分区)都会将所有的数据重写分配到新的分区上。==效率极低==,最好在设计阶段就考虑好分区策略。
分区的使用
当数据表中的数据量很大时,分区带来的效率提升才会显现出来。
只有检索字段为分区字段时,分区带来的效率提升才会比较明显。
因此,==分区字段的选择很重要==,并且==业务逻辑要尽可能地根据分区字段做相应调整==(尽量使用分区字段作为查询条件)。
水平分割和垂直分割
水平分割:通过建立结构相同的几张表分别存储数据
垂直分割:将经常一起使用的字段放在一个单独的表中,分割后的表记录之间是一一对应关系。
分表原因
- 为数据库减压
- 分区算法局限
- 数据库支持不完善(
5.1之后mysql才支持分区操作)
id重复的解决方案
- 借用第三方应用如
memcache、redis的id自增器 - 单独建一张只包含
id一个字段的表,每次自增该字段作为数据记录的id
集群
横向扩展:从根本上(单机的硬件处理能力有限)提升数据库性能 。由此而生的相关技术:==读写分离、负载均衡==
安装和配置主从复制
环境
Red Hat Enterprise Linux Server release 7.0 (Maipo)(虚拟机)mysql5.7
安装和配置
解压到对外提供的服务的目录(我自己专门创建了一个/export/server来存放)
tar xzvf mysql-5.7.23-linux-glibc2.12-x86_64.tar.gz -C /export/server cd /export/server mv mysql-5.7.23-linux-glibc2.12-x86_64 mysql
添加mysql目录的所属组和所属者:
groupadd mysql useradd -r -g mysql mysql cd /export/server chown -R mysql:mysql mysql/ chmod -R 755 mysql/
创建mysql数据存放目录(其中/export/data是我创建专门用来为各种服务存放数据的目录)
mkdir /export/data/mysql
初始化mysql服务
cd /export/server/mysql ./bin/mysqld --basedir=/export/server/mysql --datadir=/export/data/mysql --user=mysql --pid-file=/export/data/mysql/mysql.pid --initialize
如果成功会显示mysql的root账户的初始密码,记下来以备后续登录。如果报错缺少依赖,则使用yum instally依次安装即可
vim /etc/my.cnf [mysqld] basedir=/export/server/mysql datadir=/export/data/mysql socket=/tmp/mysql.sock user=mysql server-id=10 # 服务id,在集群时必须唯一,建议设置为IP的第四段 port=3306 # Disabling symbolic-links is recommended to prevent assorted security risks symbolic-links=0 # Settings user and group are ignored when systemd is used. # If you need to run mysqld under a different user or group, # customize your systemd unit file for mariadb according to the # instructions in http://fedoraproject.org/wiki/Systemd [mysqld_safe] log-error=/export/data/mysql/error.log pid-file=/export/data/mysql/mysql.pid # # include all files from the config directory # !includedir /etc/my.cnf.d
cp /export/server/mysql/support-files/mysql.server /etc/init.d/mysqld //将服务添加到开机自动启动
service mysqld start //启动服务
配置环境变量,在/etc/profile中添加如下内容
# mysql env MYSQL_HOME=/export/server/mysql MYSQL_PATH=$MYSQL_HOME/bin PATH=$PATH:$MYSQL_PATH export PATH
source /etc/profile //使配置即可生效
mysql -uroot -p //使用root登录
# 这里填写之前初始化服务时提供的密码
登录上去之后,更改root账户密码(我为了方便将密码改为root),否则操作数据库会报错
set password=password('root'); flush privileges;这样就可以在宿主机使用navicat远程连接虚拟机linux上的mysql了
配置主从节点
配置master
以linux(192.168.10.10)上的mysql为master,宿主机(192.168.10.1)上的mysql为slave配置主从复制。
修改master的my.cnf如下
[mysqld] basedir=/export/server/mysql datadir=/export/data/mysql socket=/tmp/mysql.sock user=mysql server-id=10 port=3306 # Disabling symbolic-links is recommended to prevent assorted security risks symbolic-links=0 # Settings user and group are ignored when systemd is used. # If you need to run mysqld under a different user or group, # customize your systemd unit file for mariadb according to the # instructions in http://fedoraproject.org/wiki/Systemd log-bin=mysql-bin # 开启二进制日志 expire-logs-days=7 # 设置日志过期时间,避免占满磁盘 binlog-ignore-db=mysql # 不使用主从复制的数据库 binlog-ignore-db=information_schema binlog-ignore-db=performation_schema binlog-ignore-db=sys binlog-do-db=test #使用主从复制的数据库 [mysqld_safe] log-error=/export/data/mysql/error.log pid-file=/export/data/mysql/mysql.pid # # include all files from the config directory # !includedir /etc/my.cnf.d
service mysqld restart //重启master
登录master查看配置是否生效(ON即为开启,默认为OFF):
mysql> show variables like 'log_bin'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | log_bin | ON | +---------------+-------+
在master的数据库中建立备份账号:backup为用户名,%表示任何远程地址,用户back可以使用密码1234通过任何远程客户端连接master
grant replication slave on *.* to 'backup'@'%' identified by '1234'
查看user表可以看到刚创建的用户:
mysql> use mysql mysql> select user,authentication_string,host from user; +---------------+-------------------------------------------+-----------+ | user | authentication_string | host | +---------------+-------------------------------------------+-----------+ | root | *81F5E21E35407D884A6CD4A731AEBFB6AF209E1B | % | | mysql.session | *THISISNOTAVALIDPASSWORDTHATCANBEUSEDHERE | localhost | | mysql.sys | *THISISNOTAVALIDPASSWORDTHATCANBEUSEDHERE | localhost | | backup | *A4B6157319038724E3560894F7F932C8886EBFCF | % | +---------------+-------------------------------------------+-----------+
新建test数据库,创建一个article表以备后续测试
CREATE TABLE `article` ( `id` int(11) NOT NULL AUTO_INCREMENT, `title` varchar(64) DEFAULT NULL, `content` text, PRIMARY KEY (`id`) ) CHARSET=utf8;
重启服务并刷新数据库状态到存储文件中(with read lock表示在此过程中,客户端只能读数据,以便获得一个一致性的快照)
][root@zhenganwen ~]# service mysqld restart Shutting down MySQL.... SUCCESS! Starting MySQL. SUCCESS! [root@zhenganwen mysql]# mysql -uroot -proot mysql> flush tables with read lock; Query OK, 0 rows affected (0.00 sec)
查看master上当前的二进制日志和偏移量(记一下其中的File和Position)
mysql> show master status \G *************************** 1. row *************************** File: mysql-bin.000002 Position: 154 Binlog_Do_DB: test Binlog_Ignore_DB: mysql,information_schema,performation_schema,sys Executed_Gtid_Set: 1 row in set (0.00 sec)
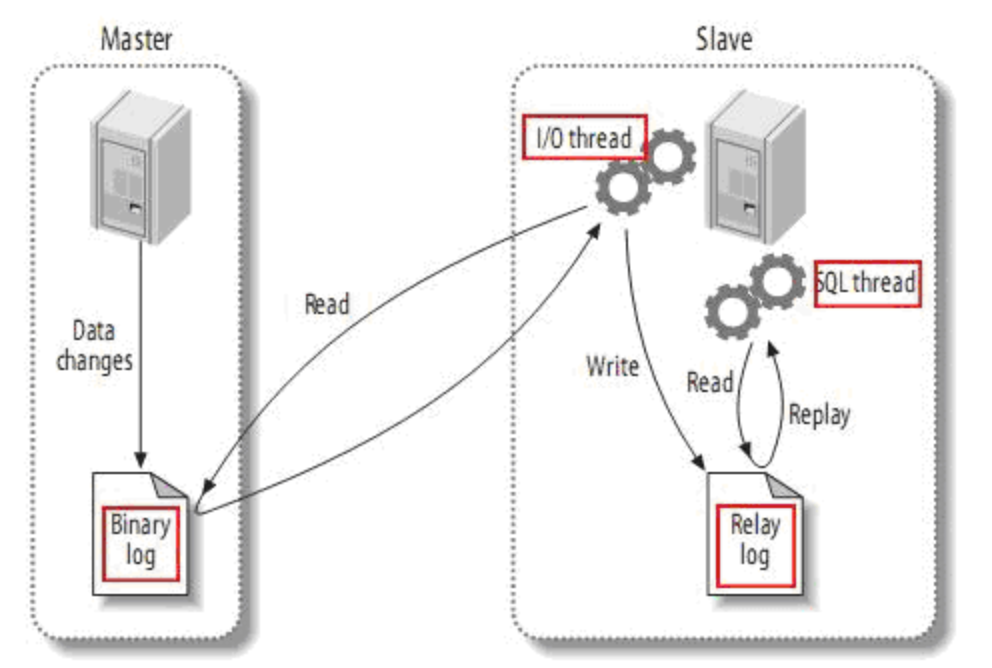
File表示实现复制功能的日志,即上图中的Binary log;Position则表示Binary log日志文件的偏移量之后的都会同步到slave中,那么在偏移量之前的则需要我们手动导入。
主服务器上面的任何修改都会保存在二进制日志Binary log里面,从服务器上面启动一个I/O thread(实际上就是一个主服务器的客户端进程),连接到主服务器上面请求读取二进制日志,然后把读取到的二进制日志写到本地的一个Realy log里面。从服务器上面开启一个SQL thread定时检查Realy log,如果发现有更改立即把更改的内容在本机上面执行一遍。
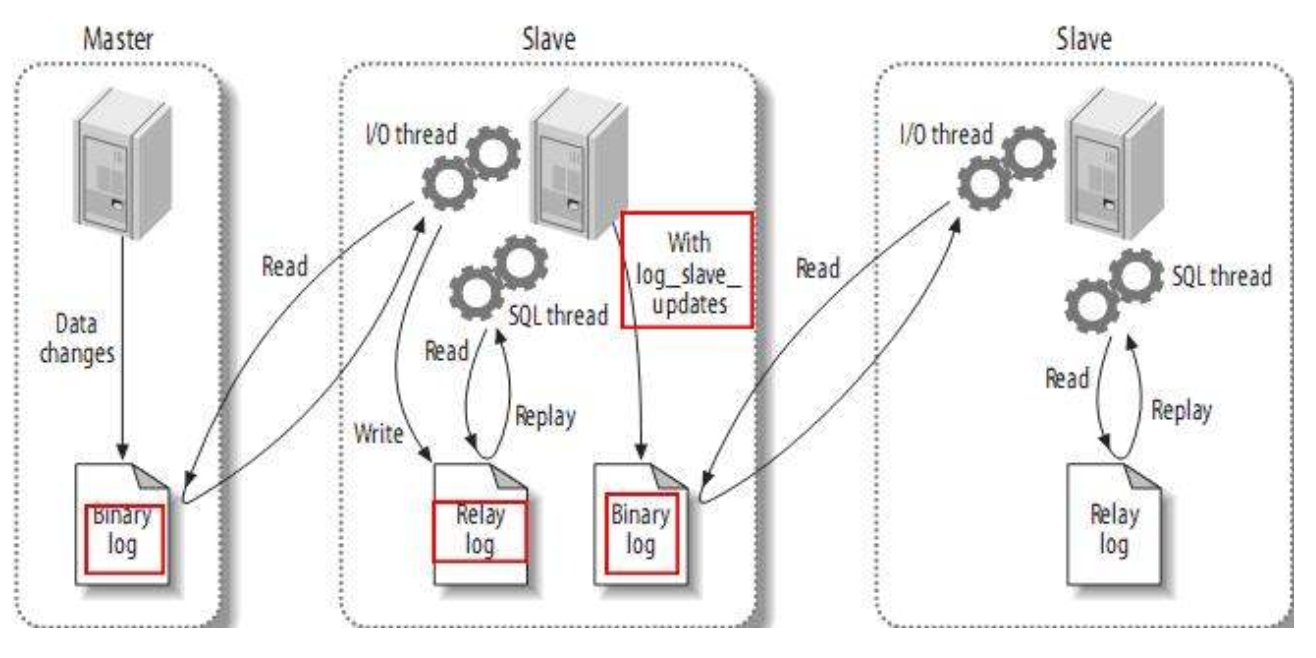
如果一主多从的话,这时主库既要负责写又要负责为几个从库提供二进制日志。此时可以稍做调整,将二进制日志只给某一从,这一从再开启二进制日志并将自己的二进制日志再发给其它从。或者是干脆这个从不记录只负责将二进制日志转发给其它从,这样架构起来性能可能要好得多,而且数据之间的延时应该也稍微要好一些
手动导入,从master中导出数据
mysqldump -u root -p root -h localhost test > /export/data/test.sql
将导出来的sql文件再从服务器导入:(保证有该数据库)
mysql -u root -p root -h localhost test < /export/data/test.sql
配置slave
修改slave的my.ini文件中的[mysqld]部分
log-bin=mysql server-id=1 #192.168.10.1
保存修改后重启slave,WIN+R->services.msc->MySQL5.7->重新启动
登录slave检查log_bin是否已被开启:
mysql> show variables like 'log_bin'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | log_bin | ON | +---------------+-------+
配置与master的同步复制:
stop slave; change master to master_host='192.168.10.10', -- master的IP master_user='backup', -- 之前在master上创建的用户 master_password='1234', master_log_file='mysql-bin.000002', -- master上 show master status \G 提供的信息 master_log_pos=154;
启用slave节点并查看状态
mysql> start slave; mysql> show slave status \G *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event //==重点== Master_Host: 192.168.10.10 Master_User: backup Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000002 Read_Master_Log_Pos: 154 Relay_Log_File: DESKTOP-KUBSPE0-relay-bin.000002 Relay_Log_Pos: 320 Relay_Master_Log_File: mysql-bin.000002 Slave_IO_Running: Yes //==重点== Slave_SQL_Running: Yes //==重点== Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 154 Relay_Log_Space: 537 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0 Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 10 Master_UUID: f68774b7-0b28-11e9-a925-000c290abe05 Master_Info_File: C:\ProgramData\MySQL\MySQL Server 5.7\Data\master.info SQL_Delay: 0 SQL_Remaining_Delay: NULL Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates Master_Retry_Count: 86400 Master_Bind: Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: Executed_Gtid_Set: Auto_Position: 0 Replicate_Rewrite_DB: Channel_Name: Master_TLS_Version: 1 row in set (0.00 sec)
测试
关闭master的读取锁定
mysql> unlock tables; Query OK, 0 rows affected (0.00 sec)
向master中插入一条数据
mysql> use test mysql> insert into article (title,content) values ('mysql master and slave','record the cluster building succeed!:)'); Query OK, 1 row affected (0.00 sec)
查看slave是否自动同步了数据
mysql> insert into article (title,content) values ('mysql master and slave','record the cluster building succeed!:)'); Query OK, 1 row affected (0.00 sec)
至此,主从复制的配置成功!:)
读写分离
读写分离是依赖于主从复制,而主从复制又是为读写分离服务的。因为主从复制要求slave不能写只能读(如果对slave执行写操作,那么show slave status将会呈现Slave_SQL_Running=NO,此时你需要按照前面提到的手动同步一下slave)。
负载均衡
负载均衡算法
- 轮询
轮询算法是最简单的一种负载均衡算法。它的原理是把来自用户的请求轮流分配给内部的服务器:从服务器1开始,直到服务器N,然后重新开始循环。
算法的优点是其简洁性,它无需记录当前所有连接的状态,所以它是一种无状态调度。
轮询算法假设所有服务器的处理性能都相同,不关心每台服务器的当前连接数和响应速度。当请求服务间隔时间变化比较大时,轮询算法容易导致服务器间的负载不平衡。所以此种均衡算法适合于服务器组中的所有服务器都有相同的软硬件配置并且平均服务请求相对均衡的情况。
假设有N台服务器:S = {S1, S2, …, Sn},一个指示变量i表示上一次选择的服务器ID。变量i被初始化为N-1。该算法的伪代码如下:
j = i; do { j = (j + 1) mod n; i = j; return Si; } while (j != i); return NULL;
- 加权轮询:按照处理能力来加权
轮询算法并没有考虑每台服务器的处理能力,实际中可能并不是这种情况。由于每台服务器的配置、安装的业务应用等不同,其处理能力会不一样。
所以,加权轮询算法的原理就是:根据服务器的不同处理能力,给每个服务器分配不同的权值,使其能够接受相应权值数的服务请求。
首先看一个简单的Nginx负载均衡配置。
http { upstream cluster { server a weight=1; server b weight=2; server c weight=4; } ... }
按照上述配置,Nginx每收到7个客户端的请求,会把其中的1个转发给后端a,把其中的2个转发给后端b,把其中的4个转发给后端c。
加权轮询算法的结果,就是要生成一个服务器序列。每当有请求到来时,就依次从该序列中取出下一个服务器用于处理该请求。比如针对上面的例子,加权轮询算法会生成序列{c, c, b, c, a, b, c}。这样,每收到7个客户端的请求,会把其中的1个转发给后端a,把其中的2个转发给后端b,把其中的4个转发给后端c。收到的第8个请求,重新从该序列的头部开始轮询。
总之,加权轮询算法要生成一个服务器序列,该序列中包含n个服务器。n是所有服务器的权重之和。在该序列中,每个服务器的出现的次数,等于其权重值。并且,生成的序列中,服务器的分布应该尽可能的均匀。比如序列{ c, c, c, c, c, a, b}中,前五个请求都会分配给服务器a,这就是一种不均匀的分配方法,更好的序列应该是:{c, c, b, c, a, b, c}。
- 负载分配:依据当前的空闲状态(但是测试每个节点的内存使用率、CPU利用率等,再做比较选出最闲的那个,效率太低)
高可用
在服务器架构时,为了保证服务器7x24不宕机在线状态,需要为每台单点服务器(由一台服务器提供服务的服务器,如写服务器、数据库中间件)提供冗余机。
对于写服务器来说,需要提供一台同样的写-冗余服务器,当写服务器健康时(写-冗余通过心跳检测),写-冗余作为一个从机的角色复制写服务器的内容与其做一个同步;当写服务器宕机时,写-冗余服务器便顶上来作为写服务器继续提供服务。对外界来说这个处理过程是透明的,即外界仅通过一个IP访问服务。
典型SQL
线上DDL
DDL是指数据库表结构的定义(create table)和维护(alter table)的语言。在线上执行DDL,在低于MySQL5.6版本时会导致全表被独占锁定,此时表处于维护、不可操作状态,这会导致该期间对该表的所有访问无法响应。但是在MySQL5.6之后,支持Online DDL,大大缩短了锁定时间。
优化技巧是采用的维护表结构的DDL(比如增加一列,或者增加一个索引),是==copy==策略。
思路:创建一个满足新结构的新表,将旧表数据==逐条==导入(复制)到新表中,以保证==一次性锁定的内容少==(锁定的是正在导入的数据),同时旧表上可以执行其他任务。导入的过程中,将对旧表的所有操作以日志的形式记录下来,导入完毕后,将更新日志在新表上再执行一遍(确保一致性)。最后,新表替换旧表(在应用程序中完成,或者是数据库的rename,视图完成)。
但随着MySQL的升级,这个问题几乎淡化了。
数据库导入语句
在恢复数据时,可能会导入大量的数据。此时为了快速导入,需要掌握一些技巧:
导入时==先禁用索引和约束==:
alter table table-name disable keys
待数据导入完成之后,再开启索引和约束,一次性创建索引
alter table table-name enable keys
- 数据库如果使用的引擎是
Innodb,那么它==默认会给每条写指令加上事务==(这也会消耗一定的时间),因此建议先手动开启事务,再执行一定量的批量导入,最后手动提交事务。 - 如果批量导入的SQL指令格式相同只是数据不同,那么你应该先
prepare==预编译==一下,这样也能节省很多重复编译的时间。
limit offset,rows
尽量保证不要出现大的offset,比如limit 10000,10相当于对已查询出来的行数弃掉前10000行后再取10行,完全可以加一些条件过滤一下(完成筛选),而不应该使用limit跳过已查询到的数据。这是一个==offset做无用功==的问题。对应实际工程中,要避免出现大页码的情况,尽量引导用户做条件过滤。
select * 要少用
即尽量选择自己需要的字段select,但这个影响不是很大,因为网络传输多了几十上百字节也没多少延时,并且现在流行的ORM框架都是用的select *,只是我们在设计表的时候注意将大数据量的字段分离,比如商品详情可以单独抽离出一张商品详情表,这样在查看商品简略页面时的加载速度就不会有影响了。
order by rand()不要用
它的逻辑就是随机排序(为每条数据生成一个随机数,然后根据随机数大小进行排序)。
如select * from student order by rand() limit 5的执行效率就很低,因为它为表中的每条数据都生成随机数并进行排序,而我们只要前5条。
解决思路:在应用程序中,将随机的主键生成好,去数据库中利用主键检索。
单表和多表查询
多表查询:join、子查询都是涉及到多表的查询。
如果你使用explain分析执行计划你会发现多表查询也是一个表一个表的处理,最后合并结果。因此可以说单表查询将计算压力放在了应用程序上,而多表查询将计算压力放在了数据库上。
现在有ORM框架帮我们解决了单表查询带来的对象映射问题(查询单表时,如果发现有外键自动再去查询关联表,是一个表一个表查的)。
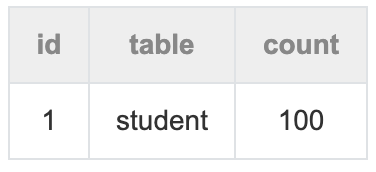
count(*)
在MyISAM存储引擎中,会自动记录表的行数,因此使用count(*)能够快速返回。而Innodb内部没有这样一个计数器,需要我们手动统计记录数量
解决思路就是单独使用一张表:
limit 1
如果可以确定仅仅检索一条,建议加上limit 1,其实ORM框架帮我们做到了这一点(查询单条的操作都会自动加上limit 1)。
慢查询日志
用于记录执行时间超过某个临界值的SQL日志,用于快速定位慢查询,为我们的优化做参考。
开启慢查询日志
配置项:slow_query_log
可以使用show variables like ‘slov_query_log’查看是否开启,如果状态值为OFF,可以使用set GLOBAL slow_query_log = on来开启,它会在datadir下产生一个xxx-slow.log的文件。
设置临界时间
配置项:long_query_time
查看:show VARIABLES like 'long_query_time',单位秒
设置:set long_query_time=0.5
实操时应该从长时间设置到短的时间,即将最慢的SQL优化掉
查看日志
一旦SQL超过了我们设置的临界时间就会被记录到xxx-slow.log中
查询慢查询日志的开启状态和慢查询日志储存的位置
show variables like '%quer%';
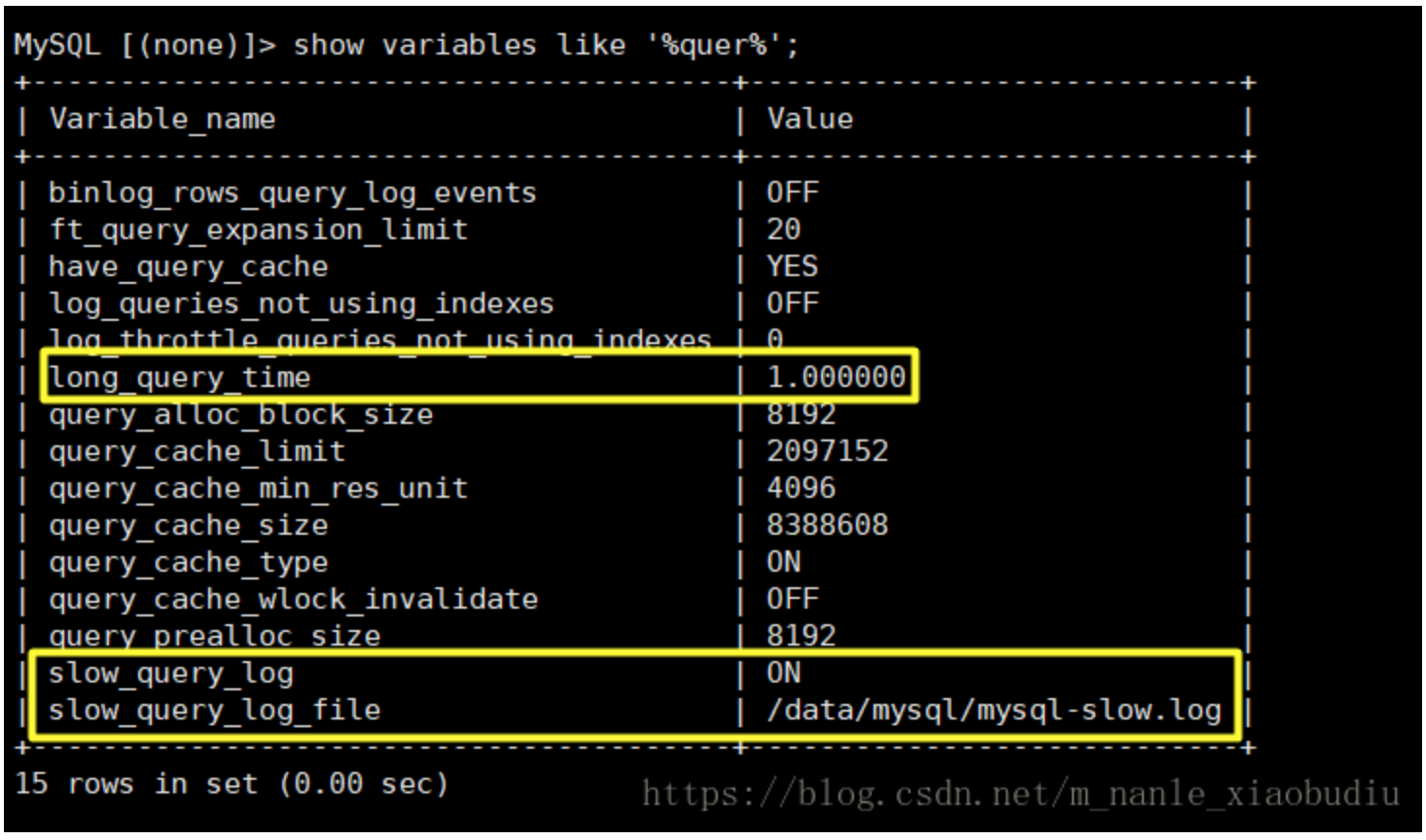
参数说明:
slow_query_log : 是否已经开启慢查询
slow_query_log_file : 慢查询日志文件路径
long_query_time : 超过多少秒的查询就写入日志
log_queries_not_using_indexes 如果值设置为ON,则会记录所有没有利用索引的查询(性能优化时开启此项,平时不要开启)
使用慢查询日志示例:
cat -n /data/mysql/mysql-slow.log

从慢查询日志中,可以看到每一条查询时间高于1s钟的sql语句,并可以看到执行的时间是多少。
比如上面,就表示 sql语句 select * from comic where comic_id < 1952000; 执行时间为3.902864秒,超出了我们设置的慢查询时间临界点1s,所以被记录下来了。
对慢查询日志进行分析
通过查看慢查询日志可以发现,很乱,数据量大的时候,可能一天会产生几个G的日志,根本没有办法去清晰明了的分析。所以,这里,我们采用工具进行分析。
1、使用mysqldumpslow进行分析
mysqldumpslow -t 10 /data/mysql/mysql-slow.log #显示出慢查询日志中最慢的10条sql
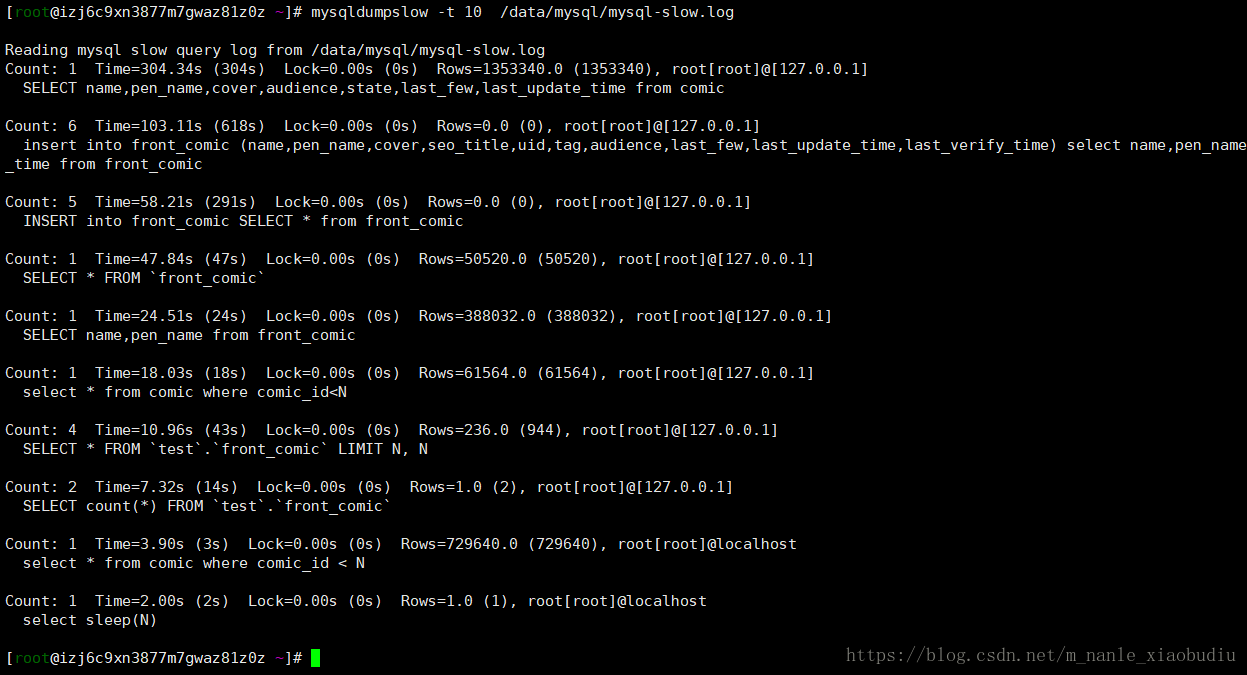
注:mysqldumpslow工具还有其他参数,以提供其他功能
2、使用pt-query-digest工具进行分析
mysqldumpslow是mysql安装后就自带的工具,用于分析慢查询日志,但是pt-query-digest却不是mysql自带的,如果想使用pt-query-digest进行慢查询日志的分析,则需要自己安装pt-query-digest。pt-query-digest工具相较于mysqldumpslow功能多一点。
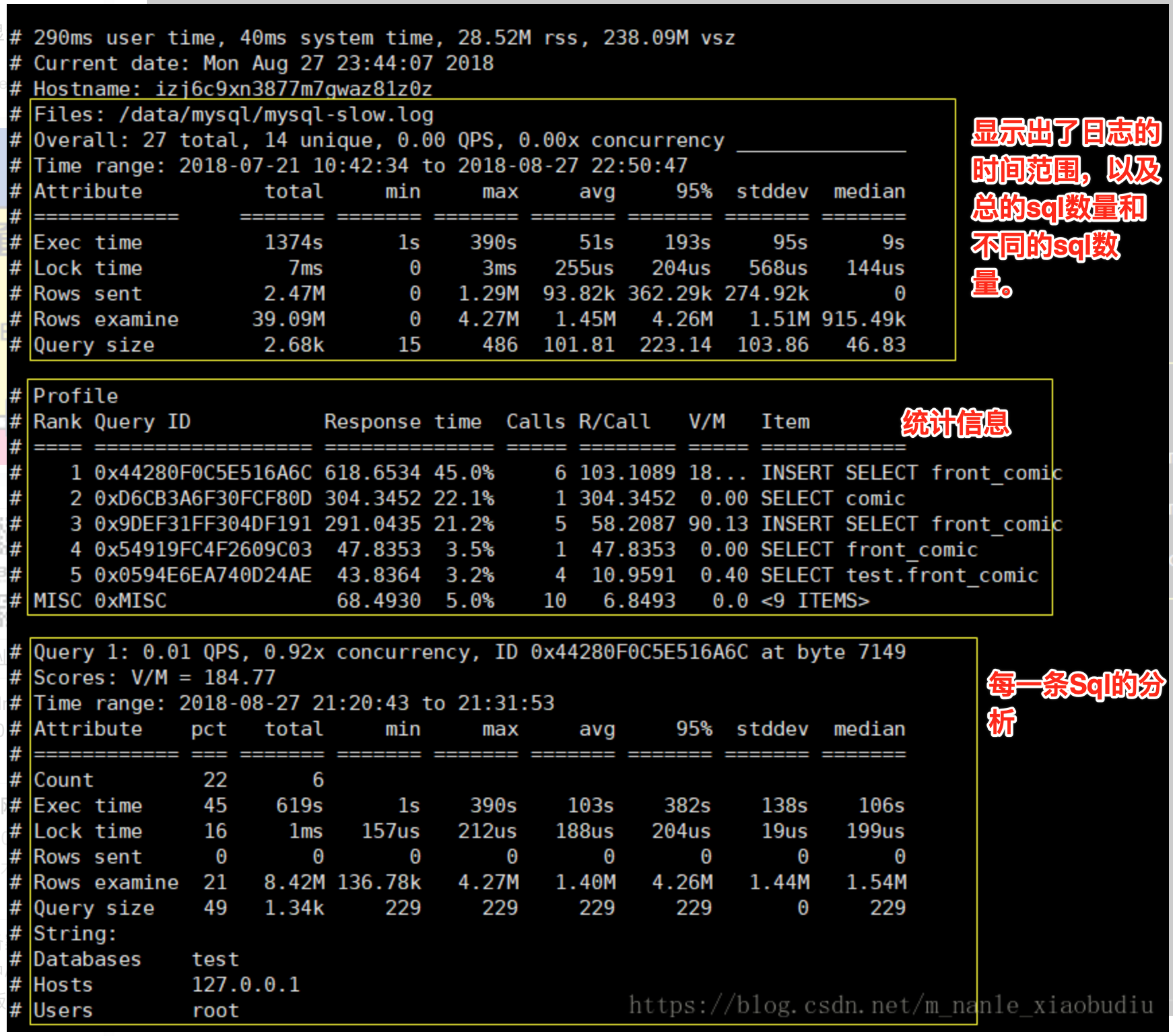
pt-query-digest /data/mysql/mysql-slow.log
查询出来的结果分为三部分
如何通过pt-query-digest 慢查询日志发现有问题的sql
- 查询次数多且每次查询占用时间长的sql : 通常为pt-query-digest分析的前几个查询
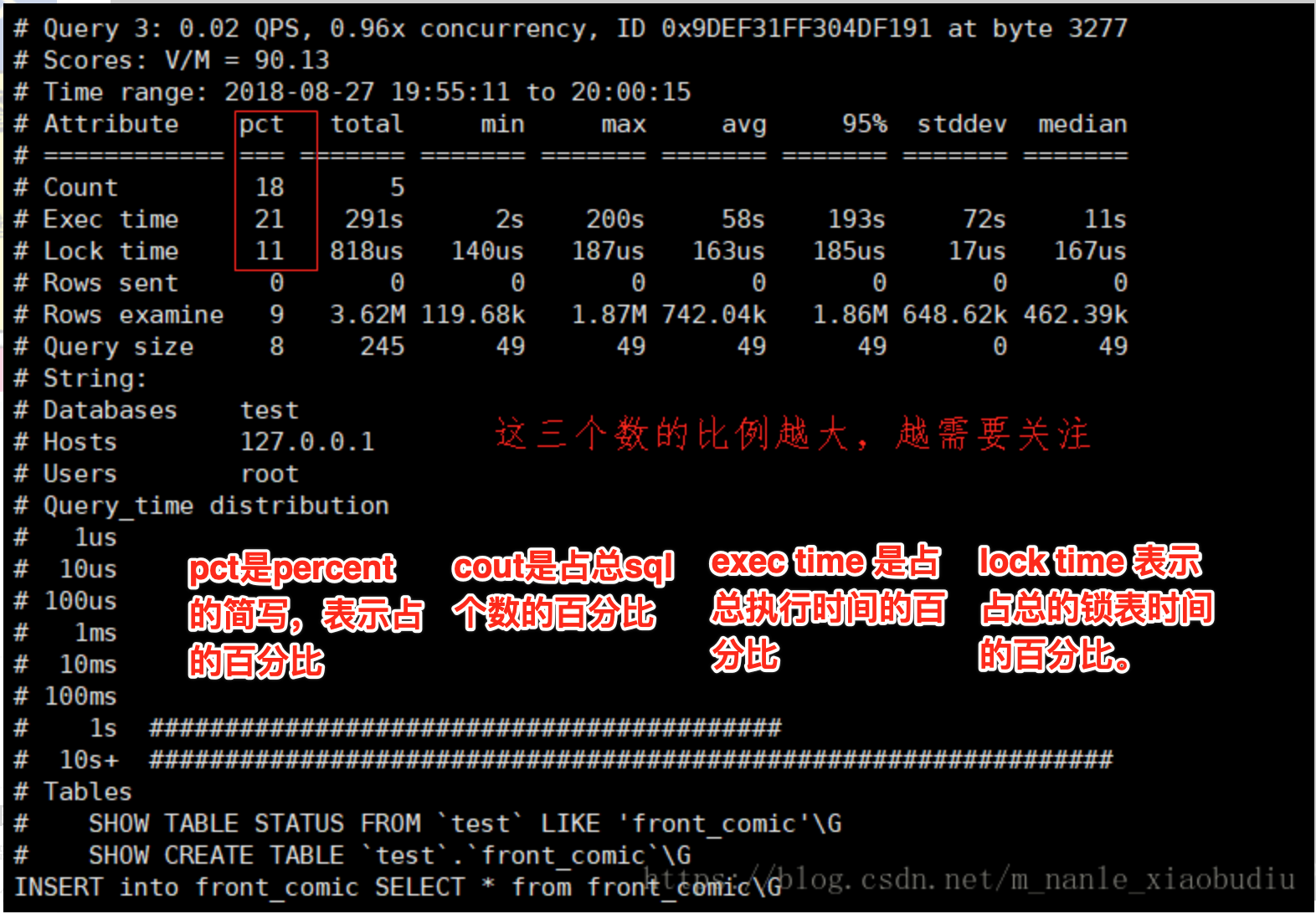
- IO消耗大的sql : 注意pt-query-digest分析中的Rows examine项
- 为命中索引的sql
注意pt-query-digest分析中Rows examine(扫描行数) 和 Rows sent (发送行数)的对比 ,如果扫描行数远远大于发送行数,则说明索引命中率并不高。
profile信息
配置项:profiling
开启profile
set profiling=on //开启后,所有的SQL执行的详细信息都会被自动记录下来
mysql> show variables like 'profiling'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | profiling | OFF | +---------------+-------+ 1 row in set, 1 warning (0.00 sec) mysql> set profiling=on; Query OK, 0 rows affected, 1 warning (0.00 sec)查看profile信息
mysql> show variables like 'profiling'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | profiling | ON | +---------------+-------+ 1 row in set, 1 warning (0.00 sec)mysql> show profiles
+----------+------------+-----------------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+-----------------------------------------------------------------+
| 1 | 0.00427225 | select * from user |
| 2 | 0.00023 | select * from user |
| 3 | 0.00019475 | select * from user |
| 4 | 0.000192 | select * from user |
| 5 | 8.725E-5 | select * from user where id='1' |
| 6 | 0.00028875 | select * from user where id=1 |
| 7 | 7.5E-5 | set profiling=1 |
| 8 | 0.00020075 | select * from user |
+----------+------------+-----------------------------------------------------------------+
8 rows in set
通过执行 “SHOW PROFILE” 命令获取当前系统中保存的多个 Query 的 profile 的概要信息。
通过Query_ID查看某条SQL所有详细步骤的时间
show profile for query Query_ID
语法:Show profile type , block type for query 问题sql数字号码
其中type:
ALL: 显示所有的开销信息
BLOCK IO : 显示块IO相关开销
CONTEXT SWITCHS: 上下文切换相关开销
CPU : 显示cpu 相关开销
IPC: 显示发送和接收相关开销
MEMORY: 显示内存相关开销
PAGE FAULTS:显示页面错误相关开销信息
SOURCE : 显示和Source_function ,Source_file,Source_line 相关的开销信息
SWAPS:显示交换次数相关的开销信息
mysql> show profile cpu,block io for query 8; +----------------------+----------+----------+------------+--------------+---------------+ | Status | Duration | CPU_user | CPU_system | Block_ops_in | Block_ops_out | +----------------------+----------+----------+------------+--------------+---------------+ | starting | 3.1E-5 | 0 | 0 | NULL | NULL | | checking permissions | 6E-6 | 0 | 0 | NULL | NULL | | Opening tables | 1.4E-5 | 0 | 0 | NULL | NULL | | System lock | 6E-6 | 0 | 0 | NULL | NULL | | init | 1.3E-5 | 0 | 0 | NULL | NULL | | optimizing | 3E-6 | 0 | 0 | NULL | NULL | | statistics | 8E-6 | 0 | 0 | NULL | NULL | | preparing | 5E-6 | 0 | 0 | NULL | NULL | | executing | 1E-6 | 0 | 0 | NULL | NULL | | Sending data | 4.6E-5 | 0 | 0 | NULL | NULL | | end | 3E-6 | 0 | 0 | NULL | NULL | | query end | 2E-6 | 0 | 0 | NULL | NULL | | closing tables | 5E-6 | 0 | 0 | NULL | NULL | | freeing items | 5.4E-5 | 0 | 0 | NULL | NULL | | logging slow query | 2E-6 | 0 | 0 | NULL | NULL | | cleaning up | 3E-6 | 0 | 0 | NULL | NULL | +----------------------+----------+----------+------------+--------------+---------------+ 16 rows in set
参数解释:
Status : sql 语句执行的状态
Duration: sql 执行过程中每一个步骤的耗时
CPU_user: 当前用户占有的cpu
CPU_system: 系统占有的cpu
Block_ops_in : I/O 输入
Block_ops_out : I/O 输出
上面的例子中是获取 CPU 和 Block IO 的消耗,非常清晰,对于定位性能瓶颈非常适用。
典型的服务器配置
注意:以下的配置全都取决于实际的运行环境
max_connections,最大客户端连接数mysql> show variables like 'max_connections'; +-----------------+-------+ | Variable_name | Value | +-----------------+-------+ | max_connections | 151 | +-----------------+-------+
table_open_cache,表文件句柄缓存(表数据是存储在磁盘上的,缓存磁盘文件的句柄方便打开文件读取数据)mysql> show variables like 'table_open_cache'; +------------------+-------+ | Variable_name | Value | +------------------+-------+ | table_open_cache | 2000 | +------------------+-------+
key_buffer_size,索引缓存大小(将从磁盘上读取的索引缓存到内存,可以设置大一些,有利于快速检索)mysql> show variables like 'key_buffer_size'; +-----------------+---------+ | Variable_name | Value | +-----------------+---------+ | key_buffer_size | 8388608 | +-----------------+---------+
innodb_buffer_pool_size,Innodb存储引擎缓存池大小(对于Innodb来说最重要的一个配置,如果所有的表用的都是Innodb,那么甚至建议将该值设置到物理内存的80%,Innodb的很多性能提升如索引都是依靠这个)mysql> show variables like 'innodb_buffer_pool_size'; +-------------------------+---------+ | Variable_name | Value | +-------------------------+---------+ | innodb_buffer_pool_size | 8388608 | +-------------------------+---------+
innodb_file_per_table(innodb中,表数据存放在.ibd文件中,如果将该配置项设置为ON,那么一个表对应一个ibd文件,否则所有innodb共享表空间)
压测工具mysqlslap
安装MySQL时附带了一个压力测试工具mysqlslap(位于bin目录下)
自动生成sql测试
C:\Users\zaw>mysqlslap --auto-generate-sql -uroot -proot mysqlslap: [Warning] Using a password on the command line interface can be insecure. Benchmark Average number of seconds to run all queries: 1.219 seconds Minimum number of seconds to run all queries: 1.219 seconds Maximum number of seconds to run all queries: 1.219 seconds Number of clients running queries: 1 Average number of queries per client: 0
并发测试
C:\Users\zaw>mysqlslap --auto-generate-sql --concurrency=100 -uroot -proot mysqlslap: [Warning] Using a password on the command line interface can be insecure. Benchmark Average number of seconds to run all queries: 3.578 seconds Minimum number of seconds to run all queries: 3.578 seconds Maximum number of seconds to run all queries: 3.578 seconds Number of clients running queries: 100 Average number of queries per client: 0 C:\Users\zaw>mysqlslap --auto-generate-sql --concurrency=150 -uroot -proot mysqlslap: [Warning] Using a password on the command line interface can be insecure. Benchmark Average number of seconds to run all queries: 5.718 seconds Minimum number of seconds to run all queries: 5.718 seconds Maximum number of seconds to run all queries: 5.718 seconds Number of clients running queries: 150 Average number of queries per client: 0
多轮测试
C:\Users\zaw>mysqlslap --auto-generate-sql --concurrency=150 --iterations=10 -uroot -proot mysqlslap: [Warning] Using a password on the command line interface can be insecure. Benchmark Average number of seconds to run all queries: 5.398 seconds Minimum number of seconds to run all queries: 4.313 seconds Maximum number of seconds to run all queries: 6.265 seconds Number of clients running queries: 150 Average number of queries per client: 0
存储引擎测试
C:\Users\zaw>mysqlslap --auto-generate-sql --concurrency=150 --iterations=3 --engine=innodb -uroot -proot mysqlslap: [Warning] Using a password on the command line interface can be insecure. Benchmark Running for engine innodb Average number of seconds to run all queries: 5.911 seconds Minimum number of seconds to run all queries: 5.485 seconds Maximum number of seconds to run all queries: 6.703 seconds Number of clients running queries: 150 Average number of queries per client: 0
C:\Users\zaw>mysqlslap --auto-generate-sql --concurrency=150 --iterations=3 --engine=myisam -uroot -proot mysqlslap: [Warning] Using a password on the command line interface can be insecure. Benchmark Running for engine myisam Average number of seconds to run all queries: 53.104 seconds Minimum number of seconds to run all queries: 46.843 seconds Maximum number of seconds to run all queries: 60.781 seconds Number of clients running queries: 150 Average number of queries per client: 0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号