RabbitMQ系列之—初识
一、 消息队列概述
消息队列是指利用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的集成。
通过提供消息传递和消息排队模型,它可以在分布式环境下提供应用解耦、弹性伸缩、冗余存储、流量削峰、异步通信、数据同步 等等功能,其作为 分布式系统架构 中的一个重要组件,有着举足轻重的地位。
二、 消息队列的特点
1、采用异步处理模式
消息发送者可以发送一个消息而无须等待响应。消息发送者将消息发送到一条 虚拟的通道(主题 或 队列)上,消息接收者则订阅或是监听该通道。一条信息可能最终转发给 一个或多个 消息接收者,这些接收者都无需对消息发送者做出同步回应。整个过程都是异步的。
2、应用系统之间解耦合
主要体现在如下两点:
发送者和接受者不必了解对方、只需要确认消息;
发送者和接受者不必同时在线。
比如在线交易系统为了保证数据的最终一致,在支付系统处理完成后会把支付结果放到消息中间件里,通知订单系统修改订单支付状态。两个系统是通过消息中间件解耦的。
三、消息队列的的传输模式
1、点对点模型
点对点模型用于消息生产者和消息消费者之间点到点的通信。消息生产者将消息发送到由某个名字标识的特定消费者。这个名字实际上对于消费服务中的一个 队列(Queue),在消息传递给消费者之前它被存储在这个队列中。队列消息可以放在内存中也可以 持久化,以保证在消息服务出现故障时仍然能够传递消息。传统的点对点消息中间件通常由消息队列服务、消息传递服务、消息队列和消息应用程序接口 API 组成。

2、发布/订阅模型(Pub/Sub)
发布者/订阅者模型支持向一个特定的消息主题生产消息。0 或 多个订阅者可能对接收来自特定消息主题的消息感兴趣。
在这种模型下,发布者和订阅者彼此不知道对方,就好比是匿名公告板。这种模式被概况为:多个消费者可以获得消息,在 发布者 和 订阅者 之间存在 时间依赖性。发布者需要建立一个订阅(subscription),以便能够消费者订阅。订阅者必须保持 持续的活动状态并接收消息。
在这种情况下,在订阅者未连接时,发布的消息将在订阅者重新连接时重新发布,如下图所示:
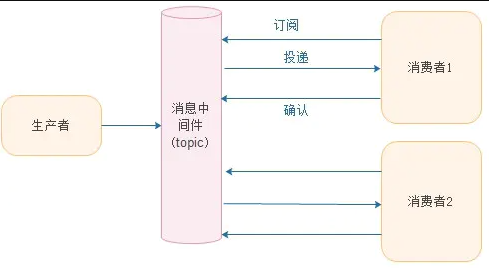
特性:
- 每个消息可以有多个订阅者;
- 客户端只有订阅后才能接收到消息;
- 持久订阅和非持久订阅。
四、消息队列应用场景
当你需要使用消息队列时,首先需要考虑它的必要性。可以使用消息队列的场景有很多,最常用的几种,是做应用程序松耦合、异步处理模式、发布与订阅、最终一致性、错峰流控和日志缓冲 等。反之,如果需要强一致性,关注业务逻辑的处理结果,则使用 RPC 显得更为合适。
1、异步处理
非核心流程异步化,减少系统响应时间,提高吞吐量。例如:短信通知、终端状态推送、App 推送、用户注册 等。
消息队列 一般都内置了高效的通信机制,因此也可以用于单纯的消息通讯,比如实现点对点消息队列或者聊天室等
2、系统解耦
- 系统之间不是强耦合的,消息接受者可以随意增加,而不需要修改消息发送者的代码。消息发送者的成功不依赖 消息接受者(比如:有些银行接口不稳定,但调用方并不需要依赖这些接口)。
- 不强依赖于非本系统的核心流程,对于非核心流程,可以放到消息队列中让 消息消费者 去按需消费,而不影响核心主流程。
3、最终一致性
最终一致性不是消息队列的必备特性,但确实可以依靠消息队列来做最终一致性的事情。
- 先写消息再操作,确保操作完成后再修改消息状态。定时任务补偿机制实现消息可靠发送接收、业务操作的可靠执行,要注意消息重复与幂等设计。
- 所有不保证
100%不丢消息的消息队列,理论上无法实现最终一致性。
像 Kafka 一类的设计,在设计层面上就有丢消息的可能(比如定时刷盘,如果掉电就会丢消息)。哪怕只丢千分之一的消息,业务也必须用其他的手段来保证结果正确。
4、流量削峰和流控
当上下游系统处理能力存在差距的时候,利用消息队列 做一个通用的 “漏斗”,进行限流控制。在下游有能力处理的时候,再进行分发。
5、消息通讯
消息队列一般都内置了高效的通信机制,因此也可以用于单纯的消息通讯,比如实现点对点消息队列或者聊天室等。
五、初识RabbitMQ
是一个开源的消息代理和队列服务器,用来通过普通协议在完全不同的应用之间共享数据,RabbitMQ是使用Erlang(高并发语言)语言来编写的,并且RabbitMQ是基于AMQP协议的。
1、AMQP协议
Advanced Message Queuing Protocol(高级消息队列协议)
定义:具有现代特征的二进制协议,是一个提供统一消息服务的应用层标准高级消息队列协议,
是应用层协议的一个开放标准,为面向消息中间件设计。
2、AMQP专业术语:(多路复用->在同一个线程中开启多个通道进行操作)
- Server:又称broker,接受客户端的链接,实现AMQP实体服务
- Connection:连接,应用程序与broker的网络连接
- Channel:网络信道,几乎所有的操作都在channel中进行,Channel是进行消息读写的通道。客户端可以建立多个channel,每个channel代表一个会话任务。
- Message:消息,服务器与应用程序之间传送的数据,由Properties和Body组成.Properties可以对消息进行修饰,必须消息的优先级、延迟等高级特性;Body则是消息体内容。
- virtualhost: 虚拟地址,用于进行逻辑隔离,最上层的消息路由。一个virtual host里面可以有若干个Exchange和Queue,同一个Virtual Host 里面不能有相同名称的Exchange 或 Queue。
- Exchange:交换机,接收消息,根据路由键转单消息到绑定队列
- Binding: Exchange和Queue之间的虚拟链接,binding中可以包换routing key
- Routing key: 一个路由规则,虚拟机可用它来确定如何路由一个特定消息。(如负载均衡)
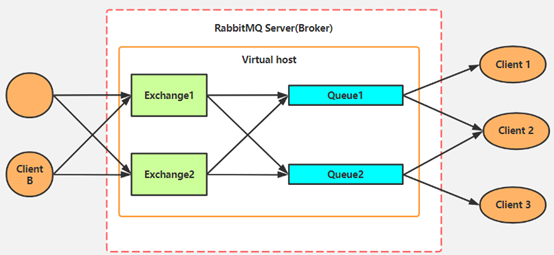
3、RabbitMQ整体架构
六、RabbitMQ六种队列模式
1、简单队列模式
最简单的工作队列,其中一个消息生产者,一个消息消费者,一个队列。也称为点对点模式。
2、工作队列
一个消息生产者,一个交换器,一个消息队列,多个消费者。同样也称为点对点模式。
3、发布订阅
无选择接收消息,一个消息生产者,一个交换器,多个消息队列,多个消费者。称为发布/订阅模式。
在应用中,只需要简单的将队列绑定到交换机上。一个发送到交换机的消息都会被转发到与该交换机绑定的所有队列上。很像子网广播,每台子网内的主机都获得了一份复制的消息。
4、路由模式
在发布/订阅模式的基础上,有选择的接收消息,也就是通过 routing 路由进行匹配条件是否满足接收消息。
路由模式跟发布订阅模式类似,然后在订阅模式的基础上加上了类型,订阅模式是分发到所有绑定到交换机的队列,路由模式只分发到绑定在交换机上面指定路由键的队列,我们可以看一下下面这张图:
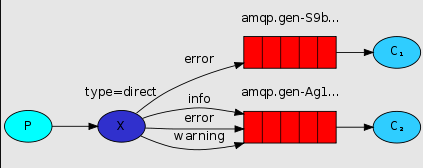
P 表示为生产者、 X 表示交换机、C1C2 表示为消费者,红色表示队列。
上图是一个结合日志消费级别的配图,在路由模式它会把消息路由到那些 binding key 与 routing key 完全匹配的 Queue 中,此模式也就是 Exchange 模式中的direct模式。
5、主题模式
同样是在发布/订阅模式的基础上,根据主题匹配进行筛选是否接收消息,比第四类更灵活。
topics 主题模式跟 routing 路由模式类似,只不过路由模式是指定固定的路由键 routingKey,而主题模式是可以模糊匹配路由键 routingKey,类似于SQL中 = 和 like 的关系。
6、RPC模式
与上面其他5种所不同之处,类模式是拥有请求/回复的。也就是有响应的,上面5种都没有。
RPC是指远程过程调用,也就是说两台服务器A,B,一个应用部署在A服务器上,想要调用B服务器上应用提供的函数/方法,由于不在一个内存空间,不能直接调用,需要通过网络来表达调用的语义和传达调用的数据。
为什么RPC呢?就是无法在一个进程内,甚至一个计算机内通过本地调用的方式完成的需求,比如不同的系统间的通讯,甚至不同的组织间的通讯。由于计算能力需要横向扩展,需要在多台机器组成的集群上部署应用,
RPC的协议有很多,比如最早的CORBA,Java RMI,Web Service的RPC风格,Hessian,Thrift,甚至Rest API。
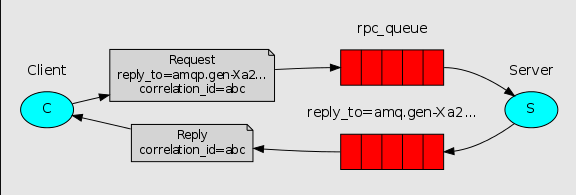
RPC的处理流程:
- 当客户端启动时,创建一个匿名的回调队列。
- 客户端为RPC请求设置2个属性:replyTo,设置回调队列名字;correlationId,标记request。
- 请求被发送到rpc_queue队列中。
- RPC服务器端监听rpc_queue队列中的请求,当请求到来时,服务器端会处理并且把带有结果的消息发送给客户端。接收的队列就是replyTo设定的回调队列。
- 客户端监听回调队列,当有消息时,检查correlationId属性,如果与request中匹配,那就是结果了。
才疏学浅,相关文档等仅供自我总结,如有相关问题可留言交流谢谢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号