【Java】IO系统概览
前言
对程序语言的设计者来说,创建一个好的输入/输出(IO)系统是一项艰难的任务。这艰难主要来自于要涵盖I/O的所有可能性。不仅存在各种I/O源端和想要与之通信的接收端(源端/接收端:文件、控制台和网络连接等),而且它们之间可能还需要以不同的方式进行通信(顺序、随机存取、缓冲、二进制、按字符、按行和按字等)。
Java类库的设计者通过创建大量的类来解决这个难题。在Java 1.0版本之后,Java的I/O类库发生显著改变,在原来面向字节的类中添加了面向字符和基于Unicode的类。在Java 1.4版本中,添加了nio类进来为了改进性能以及功能。因此,在熟练使用Java I/O类库之前,我们需要先学习相当数量的I/O类。
下面将概述Java的I/O类库中的类的含义以及使用方法。
I/O类库继承框架


输入和输出
什么是I/O流?
我们可以发现很多的类名都跟着一个Stream的后缀,即流。编程语言的I/O类库中也经常使用流这个抽象概念,它代表任何有能力产出数据的数据源对象或者有能力接收数据的接收端对象。“流”屏蔽了实际I/O设备中处理数据的细节。 例如,我们使用Java通过Http协议远程访问网络资源,获取网络数据(这叫做输入)。我们的主机与服务器就如同下图的管道两端的点,服务器响应给我们的数据,就通过这根管道流向我们。因为输入/输出的方式类似于流水在水管中流动,我们就称输入/输出为输入流/输出流。

输入和输出是站在程序的角度来讲的。程序读取外部的数据叫做输入,程序将数据送出外部叫做输出。
查看JDK文档我们可以知道,任何继承自InputStream和Reader的类都含有read方法,用于读取单个的字节或者字节数组;任何继承自OutputStream和Writer的类都含有Write方法,用于写单个的字节和字节数组。但是,我们通常都不用这些方法,这些方法之所以存在是因为可以供其他类使用。在Java中我们很少创建单一的流对象,而是通过叠合多个对象来提供所期望的功能(装饰器模式)。
InputStream 和 OutputStream
在Java 1.0中,类库的设计者限定与输入有关的类都应该从InputStram继承,与输出有关的类都应该从OutputStream继承。
**InputStream类型 **
InputStream是用来表示从不同的数据源产生输入的类。这些数据源包括:字节数组、String对象、文件、管道、一个由其他种类的流组成的序列方便我们可以将它们收集合并到一个流内和其他数据源,如Internet连接等。
每一种数据源都有相应的InputStream子类。FilterInputStream也属于一种InputStream,是装饰器类的基类,装饰器类可以将属性和有用的接口与输入流连接起来,为输入流提供更加丰富的功能。
OutputStream类型
OutputStream是用来表示程序输出要去往的地方:字节数组、文件或者管道。FilterOutputStream是属于OutputStream的,也是装饰器类的基类,“装饰器”类将属性和有用的接口与输出流连接了起来,为输出流提供更加多样的功能。
Reader和Writer
Java 1.1对基本的I/O类库进行了重大的修改,添加了Reader和Writer类以及继承自它们的子类。一眼看到Reader和Writer可能会认为是用于替代InputStream和OutputStream的类。但是,事实并非如此,尽管一些原始的流类库不再被使用。但是InputStream和OutputStream在以面向字节形式的I/O中仍然可以提供极有价值的功能,Reader和Writer则提供兼容Unicode与面向字符的I/O功能。
装饰器类FilterInputStream和FilterOutputStream
FilterInputStream和FilterOutputStream用来提供装饰器类的接口以控制特定的输入流(InputStream)和输出流(OutputStream)两个类。
通过FilterInputStream从InputStream中读取数据
FileterInputStream类可以完成两种不同的事情。
其中,DataInputStream可以直接读取由DataOutputStream写入文件的基本数据类型和String对象(使用以read开头的方法),二者搭配,我们就可以通过数据“流”,将基本类型的数据从一个地方迁移到另外一个地方。
DataInputStream和DataOutputStream的构造函数要求传入一个InputStream或者OutpurStream对象,于是我们就传入文件对象以做示范。
<img src="https://img2018.cnblogs.com/blog/1099419/201903/1099419-20190313090107506-702862891.png" 0>
其他的FilterInputStream子类则在内部修改InputStream类的行为:是否缓冲、是否保留它所读过的行(允许我们查询行数或者设置行数),以及是否把一个单一字符推回输入流等等。实现最后两个功能的类添加像是为了创建一个编译器(使用Java构建的编译器),一般情况下我们不会用到它们。
| 类 | 功能 | 构造器/如何使用 |
|---|---|---|
| DataInputStream | 与DataOutputStream搭配使用,可以按照可移植的方式从流中读取基本类型数据 | DataInputStream(InputStream in) ;包含用于读取基本数据类型的所有接口 |
| BufferedInputStream | 使用它可以防止每次读取时都得进行实际的写操作。代表“使用缓冲区”。 | BufferedInputStream(InputStream in) 、BufferedInputStream(InputStream in, int size);本质上不提供接口,只是向进程中添加缓冲区所必需的。与接口对象搭配 |
| LineNumberInputStream | 跟踪输入流中的行号;可以调用getLineNumber()和setLineNumber(int) | LineNumberInputStream(InputStream in);仅增加了行号 |
| PushbackInputStream | 具有“能弹出一个字节的缓冲区”,因此可以将读到的最后一个字符回退 | PushbackInputStream(InputStream in) 、PushbackInputStream(InputStream in, int size);通常作为编译器的扫描器 |
通过FilterOutputStream向OutputStream中写入
FilterOutputStream子类中地DataOutputStream可以将各种基本数据类型以及String对象格式化输出到“流”中;这样任何机器上使用DataInputStream就可以读取它们。
PrintStream最初的目的是为了便于以可视化格式打印所有基本数据类型以及String对象。它和DataOutputStream不同,后者的目的是将数据元素置于“流”中,使DataInputStream能够可移植地重构它们。DataOutputStream用于处理数据存储,PrintStream用于处理显示。
BufferedOutputStream是一个修改过的OutputStream,它对数据流使用缓冲技术;因此当每次向流中写入时,不必每次都进行实际的物理写动作。所以在进行输出时,我们可能更经常使用它。
| 类 | 功能 | 构造器/如何使用 |
|---|---|---|
| DataOutpurStream | 与DataInputStream搭配使用,因此可以安装可移植的方式向流中写入基类类型数据(int,char,long等) | DataOutputStream(OutputStream out) ; 包含用于写入基本类型数据的全部接口 |
| PrintStream | 用于产生格式化输出。 | 构造参数为OutputStream或者是指定的文件名或文件 |
| BufferedOutputStream | 使用它避免每次发送数据时都要进行实际的写操作。代表“使用缓冲区”。可以调用flush()函数清空缓冲区 | BufferedOutputStream(OutputStream out) 、BufferedOutputStream(OutputStream out, int size);本质上不提供接口,只是向进程中添加缓冲区所必需的。与接口对象搭配 |
随机访问文件RandomAccessFile
RandomAccessFile适用于由大小已知的记录组成的文件,我们就可以使用seek()将文件指针位置从一处转到另一处,然后读取或者修改记录。我们事先要知道每条记录的大小以及它们在文件中的位置,那么我们就可以实现随机访问。
RandomAccessFile不是InputStream或者OutputStream继承层次结构中的一部分。RandomAccessFile的工作方式类似于将DataInputStream和DataOutputStream组合起来使用。在Java 1.4中,RandomAccessFile的大多数功能将由nio存储映射文件所代替。
I/O流的典型使用方式
缓冲输入文件
若要打开一个文件进行字符输入,我们使用String或者File对象作为构造参数的FileReader。为了提高文件的读取速度,我们可以使用带缓冲(Buffer)的BufferedReader(读取一定数量的文件中字符先存放在BufferedReader中的Buffer中,即BufferedReader中的Buffer为一个字符数组。Buffer可以缓和一个字符一个字符进行读取的频繁操作的延迟,因为一个一个读取将大量时间都花费在了开始读取和结束读取操作上)。我们将FileReader的引用传递给BufferedReader的构造器,就构造出我们需要的对象,此对象还拥有读取一行字符串的readLine()方法。(这种方式也叫做装饰器模式,BufferedReader让我们的原本的对象拥有缓冲以及按行读取字符串的方法)。下面举例简单应用BufferedReader。
public class TestBufferedReader {
public static String read(String fileName) {
BufferedReader br = null;
FileReader fReader = null;
StringBuilder sBuilder = new StringBuilder();
try {
fReader = new FileReader(fileName);
br = new BufferedReader(fReader);
String str = null;
//按行获取文件内容
while((str = br.readLine()) != null) {
sBuilder.append(str);
sBuilder.append("\n"); //readLine()删除了换行符
}
}catch (FileNotFoundException e) {
e.printStackTrace();
}catch (IOException e) {
e.printStackTrace();
}finally {
if (br != null) {
try {
br.close();
}catch (IOException e) {
e.printStackTrace();
}
}
if(fReader != null) {
try {
fReader.close();
}catch (IOException e) {
e.printStackTrace();
}
}
}
return sBuilder.toString();
}
public static void main(String[] args) {
System.out.println(read("mmdou.txt"));
}
}
/*
output:
This is mmdou.txt
To be or not to be that is a question.
*/
从内存输入
使用TestBufferedReader.read()返回的字符串来构造一个StringReader对象。然后调用StringReader的read()方法每次读取一个字符,并将其发送到控制台。
public class MemoryInput {
public static void main(String[] args) throws IOException {
StringReader in = new StringReader(TestBufferedReader.read("mmdou.txt"));
int ch;
while((ch = in.read()) != -1) {
System.out.print((char)ch); //read是以int形式返回下一字节,所以需要强制转换
}
}
}
/*
output:
This is mmdou.txt
To be or not to be that is a question.
*/
格式化的内存输入
若是要读取格式化数据,可以使用DataInputStream,它是面向字节的I/O类。创建DataInputStream需要提供InputStream类型参数。这里我们使用将ByteArrayInputStream作为传入给DataInputStream的InputStream。使用TestBufferedReader.read("dis.txt").getBytes()作为ByteArrayInputStream的构造参数。
public class FormattedMemoryInput {
public static void main(String[] args) throws IOException {
try {
DataInputStream dis = new DataInputStream(new ByteArrayInputStream
(TestBufferedReader.read("dis.txt").getBytes()));
while(true) {
System.out.print((char)dis.readByte());
}
}catch (EOFException e) {
System.err.println("End of file.");
}
}
}
/*
output:
Road
End of file.
*/
上面使用捕获异常来结束来检测输入流是否结束是不正确的用法!我们要判断输入是否结束可以使用avaliable()方法返回可以从此输入流中读取(或跳过)的字节数的估计值(在没有阻塞的情况下)。下面将使用avaliable()演示如何一个字节一个字节地读取文件:
public class TestEOF {
public static void main(String[] args) throws IOException{
DataInputStream in = new DataInputStream(new ByteArrayInputStream
(TestBufferedReader.read("dis.txt").getBytes()));
while(in.available() != 0) {
System.out.print((char)in.readByte());
}
}
}
基本的文件输出
FileWriter对象可以向文件写入数据。我们会创建一个与指定文件连接的FileWriter。通常,我们会使用BufferedWriter将其包装起来用以缓冲输出(缓冲往往可以显著增加I/O操作性能,就像前面一小节缓冲输入文件所解释一样)。在本例中,为了提供格式化机制,它被包装成了PrintWriter。安照这种方式创建的数据文件,可以被作为普通文本读取。
public class BasicFileOutput {
static String file = "BasicFileOutput.out";
public static void main(String[] args) throws IOException {
BufferedReader in = new BufferedReader(new
StringReader(TestBufferedReader.read("BasicFileOutput.java")));
//PrintWriter out = new PrintWriter(file) 等价于下面一句。此方式隐含帮我们执行所有装饰工作
PrintWriter out = new PrintWriter(new BufferedWriter(new FileWriter(file)));
int lineCount = 1;
String s;
while((s = in.readLine()) != null) {
//添加行号
out.println(lineCount++ + ":" + s);
}
//刷新缓冲区
out.flush();//or out.close();
System.out.println(TestBufferedReader.read(file));
}
}
存储和恢复数据
若是我们想要实现输出可供另外一个“流”恢复的数据,那么就需要使用DataOutpurStream写入数据,并用DataInputStream恢复数据。在介绍装饰器类FilterInputStream和FilterOutputStream时,我们介绍过这两个类,在此就不在使用例子说明。
我们使用DataOutputStream写入数据,Java保证我们可以使用DataInputStream准确地读取数据——无论读和写数据的平台多么地不同。
管道流
PipedInputStream、PipedOutputStream、PipedReader和PipedWriter用于任务之间的通信,将在后面介绍。
标准I/O
标准I/O这个术语参考的是Unix中"程序所使用的单一信息流"这个概念。程序的所有输入都可以来自于标准输入,它的所有输出也都可以发送到标准输出,以及所有错误信息都可以发送到标准错误。标准I/O的意义在于:我们可以很容易地把程序串联起来,一个程序的标准输出可以作为另一个程序的标准输入。
从标准输入中读取
按照标准I/O模型,Java提供了System.in、System.out、和System.err。查看System类的源码,我们可以发现,System.out和System.err是PrintStream对象,System.in却是没有未经包装的InputStream对象。所以,我们在读取System.in之前需要对其进行包装。
通常我们会使用readLine()一次一行地读取,为此,我们将System.in包装成BufferedReader。在创建BufferedReader时,我们需要使用InputStreamReader将System.in转换成Reader。InputStreamReader是一个适配器,接收InputStream对象并将其转换成Reader对象。
下面的例子将回显输入的每一行:
public class Echo {
public static void main(String[] args) throws IOException{
BufferedReader stdin = new BufferedReader(new InputStreamReader(System.in));
String s;
while((s = stdin.readLine()) != null && s.length() != 0) {
System.out.println(s);
}
}
}
将System.out转换成PrintWriter
System.out是一个PrintStream,而PrintStream是一个OutputStream。PrintWriter恰好有一个可以接受OutputStream作为参数的构造器。

public class ChangeSystemOut {
public static void main(String[] args) {
PrintWriter out = new PrintWriter(System.out, true);//若是不设置为true则看不到输出
out.println("Hello World!");
}
}
/*
output:
Hello World!
*/
标准I/O重定向
Java的System类提供了一些简单的静态方法调用,以允许我们对标准输入、输出和错误I/O流进行重定向:

如果我们突然在显示器上创建大量输出,而且这些输出滚动得太快以至于无法阅读,此时重定向输出就显得很重要(我们可以将输出定向至其他地方一般为输出到一个文件中)。或者,我们想重复测试某个特定输入样例,此时重定向输入就很有必要(如将标准输入重定向至一个文件)。
下面简单演示这些方法的使用。
public class Redirecting {
public static void main(String[] args) throws IOException {
PrintStream console = System.out;
//带缓冲的输入流和输出流对象
BufferedInputStream in = new BufferedInputStream(new FileInputStream("Redirecting.java"));
PrintStream out = new PrintStream(new BufferedOutputStream(new FileOutputStream("test.out")));
System.setIn(in); //重定向标准输入为Redirecting.java文件
System.setOut(out); //重定向标准输出为test.out文件
System.setErr(out); //重定向标准错误未test.out
//读取重定向后的标准输入即Redirecting.java文件
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String s;
while((s = br.readLine()) != null) {
//将读取的数据重定向输出至test.out中
System.out.println(s);
}
out.close();
System.setOut(console);
}
}
这个程序将标准输入附接到文件上,并将标准输出和标准错误重定向到另外一个文件中。注意,在程序的开头处存储了对最初的System.out对象的引用,并且在结尾处将系统输出恢复到了该对象上。
I/O重定向操作的是字节流而不是字符流,所以使用InputStream和OutputStream。
新I/O(nio)
通道和缓冲器
JDK 1.4中的java.nio.*包中引入了新的Java I/O类库,目的在于提高速度。实际上,旧的I/O包已经使用nio重新实现过,以便充分利用这种速度提高。
速度的提高来自于所使用的结构更接近于操作系统执行I/O的方式:通道和缓冲器。我们可以将通道想象成包含煤层(数据)的矿藏,而缓冲器则是派送到矿藏的卡车。卡车满载而归,我们再从卡车上获得煤矿。即,我们没有直接与通道交互;我们只是和缓冲器交互,缓冲器与通道交互。所以,通道是向缓冲器发送数据和从缓冲器获得数据。
唯一直接与通道交互的缓冲器是ByteBuffer。查看JDK文档可以知道,它是一个基础的类也是一个抽象类:通过告知分配多少存储空间来创建一个ByteBuffer对象,并且还有一个方法集,用以原始字节形式或基本数据类型输出和读取数据。包含的这些方法也是抽象方法,没有办法输出和读取对象。
旧I/O类库中有三个类被修改了,用以产生FileChannel。这三个类为FIleInputStream、FileOutputStream以及用于随机读写的RandomAccessFile。这些都是字节操纵流,与底层的nio性质一致。Reader和Writer这种字符模式类不能用于产生通道,但是java.nio.channels.Channels类提供了实用方法,用以在通道中产生Reader和Writer。
下面的示例简单演示了三种类型的流用以产生可写的、可读可写以及可读的通道。
public class GetChannel {
private static final int BSIZE = 1024;
public static void main(String[] args) throws IOException{
//通过通道和缓冲器写文件
FileChannel fChannel = new FileOutputStream("data.txt").getChannel();
fChannel.write(ByteBuffer.wrap("Some text ".getBytes()));
fChannel.close();
//RandomAccessFile对文件的权限为可读可写 向文件data.txt末尾添加
fChannel = new RandomAccessFile("data.txt","rw").getChannel();
fChannel.position(fChannel.size());
fChannel.write(ByteBuffer.wrap("Some more".getBytes()));
fChannel.close();
//通过通道和缓冲器读文件
fChannel = new RandomAccessFile("data.txt").getChannel();
ByteBuffer buffer = ByteBuffer.allocate(BSIZE);
fChannel.read(buffer);
buffer.flip();//让别人做好读取字节的准备
while(buffer.hasRemaining()) {
System.out.print((char)buffer.get());
}
}
}
FileOutputStream、RandomAccessFile和RandomAccessFile都有一个getChannel()方法产生一个FileChannel与实际文件关联。在以上程序中,我们使用ByteBuffer向FileChannel通道中传入数据和获取数据,就像前面提过的,通道从缓冲器获取数据或者向缓冲器发送数据。
将字节存放于ByteBuffer中的方法之一是:使用一种“put”方法直接对它们进行填充,填入一个或多个字节,或者基本数据类型的值。不过,正如程序中所见可以使用warp()方法将已存在的字节数组“包装”到ByteBuffer中。这样,就不会再复制底层的数组,而是把它作为所产生的ByteBuffer的存储器,我们称之为数组支持的ByteBuffer。
从通道中获取数据,我们使用ByteBuffer.allocate()分配了缓冲器的大小。若是我们想要达到更快的速度,也可以使用allocateDirect(),这个将产生一个与操作系统有更高耦合性的“直接”缓冲器。但是,这种分配的开始也会很大,而且也会随着操作系统的不同而不同,因此需要依照实际来选择。
看ByteBuffer作为桥梁在两个通道之间传递数据(文件复制)的例子:
public class ChannelCopy {
private static final int BSIZE = 1024;
public static void main(String[] args) throws IOException{
FileChannel in = new FileInputStream("in.txt").getChannel();
FileChannel out = new FileOutputStream("out.txt").getChannel();
ByteBuffer buffer = ByteBuffer.allocate(BSIZE);
while((in.read(buffer)) != -1) {
buffer.flip(); //通知别人准备读取
out.write(buffer); //通道从buffer中获取数据
buffer.clear(); //清除buffer准备下一次数据的读取
}
}
}
打开两个FileChannel,一个用于读取一个用于写入。每次read()之后,数据就会被写入到缓冲器中,flip()则准备缓冲器以便它的信息可以由write()提取。write()操作之后,信息仍然存在缓冲器中,接着clear()操作则对所有的内部指针重新安排,以便缓冲器在另外一个read()操作前能够做好接受数据的准备。
然而,使用一个缓冲器当做桥梁完成这种操作不是最恰当的方法。特殊方法transferTo()和transferFrom()则允许我们将一个通道和另一个通道直接相连:
public class ChannelCopy2 {
private static final int BSIZE = 1024;
public static void main(String[] args) throws IOException{
FileChannel in = new FileInputStream("in.txt").getChannel();
FileChannel out = new FileOutputStream("out.txt").getChannel();
in.transferTo(0,in.size(),out);
}
}
将字节数据转换为字符串
public class BufferToText {
private static final int BSIZE = 1024;
public static void main(String[] args) throws IOException{
FileChannel fc = new FileOutputStream("data2.txt").getChannel();
fc.write(ByteBuffer.wrap("Some words ".getBytes()));
fc.close();
fc = new FileInputStream("data2.txt").getChannel();
ByteBuffer buffer = ByteBuffer.allocate(BSIZE);
fc.read(buffer);
buffer.flip();
//直接输出asCharBuffer()
System.out.println(buffer.asCharBuffer());
//-----------------------
//回到缓冲器数据开始部分
buffer.rewind();
//发现默认字符集
String enconding = System.getProperty("file.encoding");
//取出缓冲器中的数据进行解码
System.out.println("Decoding using " + enconding + ": " +Charset.forName(enconding).decode(buffer));
fc = new FileOutputStream("data2.txt").getChannel();
//在输出数据时进行编码
fc.write(ByteBuffer.wrap("some beautiful flowers".getBytes("UTF-16BE")));
fc.close();
//获取编码后的数据
fc = new FileInputStream("data2.txt").getChannel();
buffer.clear();
fc.read(buffer);
buffer.flip();
System.out.println(buffer.asCharBuffer());
//------------------------
fc = new FileOutputStream("data2.txt").getChannel();
buffer = ByteBuffer.allocate(12); //分配了24字节
//通过CharBuffer向ByteBuffer写入
buffer.asCharBuffer().put("Some");
fc.write(buffer);
fc.close();
fc = new FileInputStream("data2.txt").getChannel();
buffer.clear();
fc.read(buffer);
buffer.flip();
System.out.println(buffer.asCharBuffer());
}
}

在GetChannel.java程序中,为了输出文件中的信息,我们每次只读取一个字节的数据,然后将每个byte类型强制转换成char类型。这种方法看起来有点原始,如果我们查看java.nio.CharBuffer这个类,将会发现它有一个toString()方法的定义为:Returns a string containing the characters in this buffer(返回一个包含缓冲区所有字符的字符串)。ByteBuffer是具有asCharBuffer()方法返回一个CharBuffer。那么我们就可以使用此方式输出字符串,但是,从输出的第一行可以看出,这种方法不太恰当。
缓冲器容纳的是普通的字符,为了把它们转换成字符,我们要么在输入它们时对其进行编码,要么在将其从缓冲器输出时对它们进行解码。如程序中所写,使用java.nio.charset.Charset便可以实现这些功能。
我们看最后一个部分,我们通过CharBuffer向ByteBuffer中写入。为ByteBuffer分配了12字节。一个字符需要两个字符,ByteBuffer可以容纳6个字符,我们的"Some"占4个字符,可是我们看输出结果,发现剩下的两个没有内容的字符也会被输出。
获取基本数据类型
尽管ByteBuffer只能保存字节类型的数据,但是它具有可以从其所容纳的字节中产生出各种不同基本数据类型的方法。下面将展示如何使用这些方法来插入和读取各种数值。
public class GetData {
private static final int BSIZE = 1024;
public static void main(String[] args) {
ByteBuffer bb = ByteBuffer.allocate(BSIZE);
int i = 0;
//检测缓冲器的初始内容是否为0
while(i ++ < bb.limit()) {
if(bb.get() != 0)
System.out.println("nozero");
}
System.out.println("i = " + i);
bb.rewind();
bb.asCharBuffer().put("Happpy!");
char c;
while((c = bb.getChar()) != 0) {
System.out.print(c+"\t");
}
System.out.println();
bb.rewind();
bb.asShortBuffer().put((short)471142);//超过short类型最大值32767需要强制类型转换 会截断
System.out.println(bb.getShort());
bb.rewind();
bb.asIntBuffer().put(99471142);
System.out.println(bb.getInt());
bb.rewind();
bb.asLongBuffer().put(99471142);
System.out.println(bb.getLong());
bb.rewind();
bb.asFloatBuffer().put(99471142);
System.out.println(bb.getFloat());
bb.rewind();
bb.asDoubleBuffer().put(99471142);
System.out.println(bb.getDouble());
}
}
/*
output:
i = 1025
H a p p p y !
12390
99471142
99471142
9.9471144E7
9.9471142E7
*/
向ByteBuffer插入基本类型数据的最简单的方法是:利用asCharBuffer()、asShortBuffer()等获得该缓冲器上的视图,然后使用该视图的put()方法。
视图缓冲器
视图缓冲器(view buffer)可以让我们通过某个特定的基本数据类型的视窗查看其底层的ByteBuffer。ByteBuffer依旧是实际存储数据的地方,“支持”着视图,因此,对视图的任何修改都会映射为对ByteBuffer中数据的修改。
如上面程序中所示,使用视图可以很方便地向ByteBuffer中插入数据与读取数据。
在同一个ByteBuffer上建立不同的视图缓冲器,将同一字节序列翻译成char、short、int、float、long和double类型的数据。
public class ViewBuffers {
public static void main(String[] args) {
ByteBuffer bb = ByteBuffer.wrap(new byte[] {0, 0, 0, 0, 0, 0, 0, 'a'});
bb.rewind();
System.out.print("Byte Buffer: " );
while(bb.hasRemaining()) {
System.out.print(bb.position() + ":" + bb.get() + ", ");
}
System.out.println();
//读取成字符
bb.rewind();
CharBuffer cb = bb.asCharBuffer();
System.out.print("Char Buffer: ");
while(cb.hasRemaining()) {
System.out.print(cb.position() + ":" + cb.get() + ", ");
}
System.out.println();
//读取短整型
bb.rewind();
ShortBuffer sb = bb.asShortBuffer();
System.out.print("Short Buffer: ");
while(sb.hasRemaining()) {
System.out.print(sb.position() + ":" + sb.get() + ", ");
}
System.out.println();
//读取成单精度浮点型
bb.rewind();
FloatBuffer fb = bb.asFloatBuffer();
System.out.print("Float Buffer: ");
while(fb.hasRemaining()) {
System.out.print(fb.position() + ":" + fb.get() + ", ");
}
System.out.println();
//读取整型
bb.rewind();
IntBuffer ib = bb.asIntBuffer();
System.out.print("Int Buffer: ");
while(ib.hasRemaining()) {
System.out.print(ib.position() + ":" + ib.get() + ", ");
}
System.out.println();
//读取长整型
bb.rewind();
LongBuffer lb = bb.asLongBuffer();
System.out.print("Long Buffer: ");
while(lb.hasRemaining()) {
System.out.print(lb.position() + ":" + lb.get() + ", ");
}
System.out.println();
//读取双精度浮点型
bb.rewind();
DoubleBuffer db = bb.asDoubleBuffer();
System.out.print("Double Buffer: ");
while(db.hasRemaining()) {
System.out.print(db.position() + ":" + db.get() + ", ");
}
}
}

下面的这张图可以形象说明以上输出的原因。
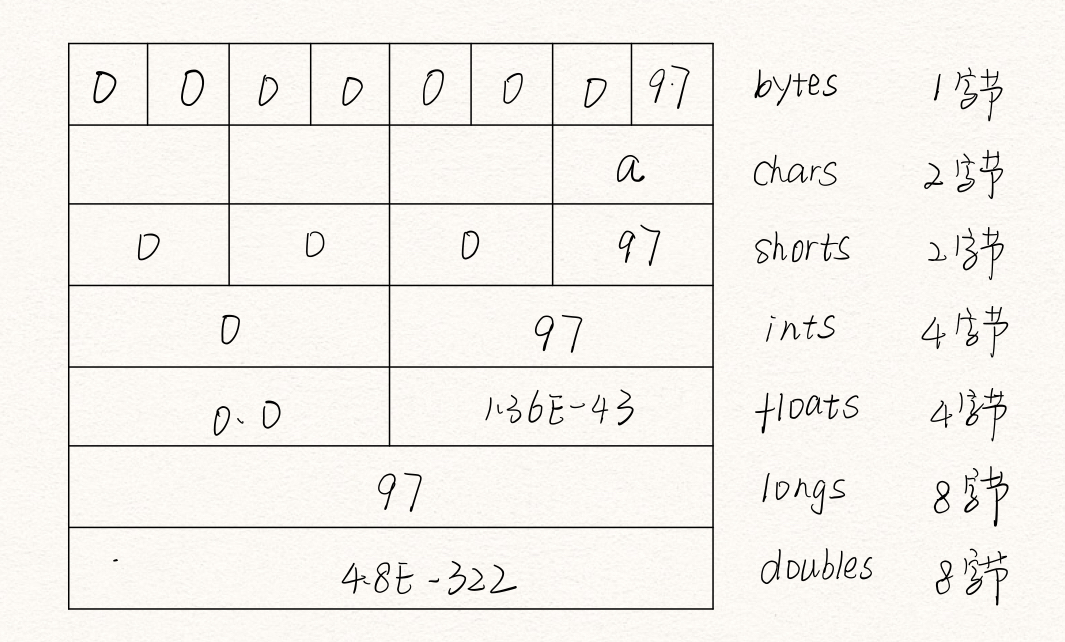
字节的存放顺序
不同的机器会以不同的字节排序方法来存储数据。有“big endian”(大端法)和“little endian”(小端法)两种。大端法是指将最高有效字节放到存放在存储器的低地址位;小端法是指将最低有效位放到放在存储器的高地址位。当存储量大于一个字节,比如int、float等,就需要考虑字节存储的顺序问题。
ByteBuffer是以大端法存数数据的,并且数据在网上传输也是大端法顺序。我们是可以使用ByteOrder.BIG_ENDIAN或者ByteOrder.LITTLE_ENDIAN的order()方法改变ByteBuffer的字节排序方式。
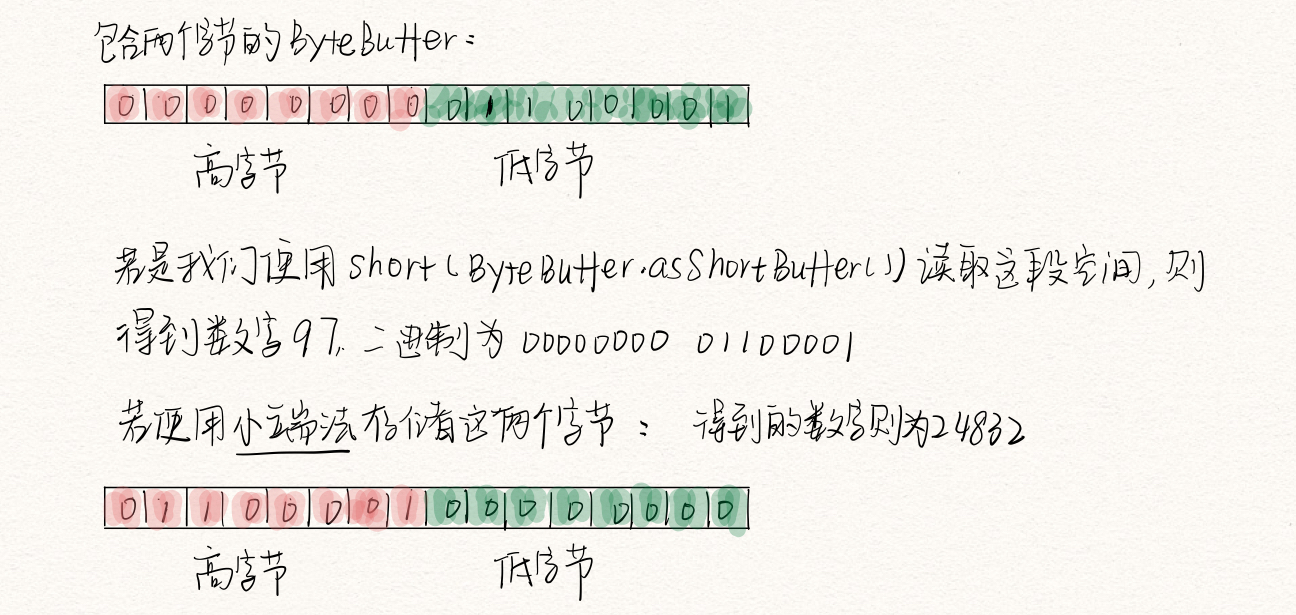
用缓冲器操作数据
nio类之间的关系
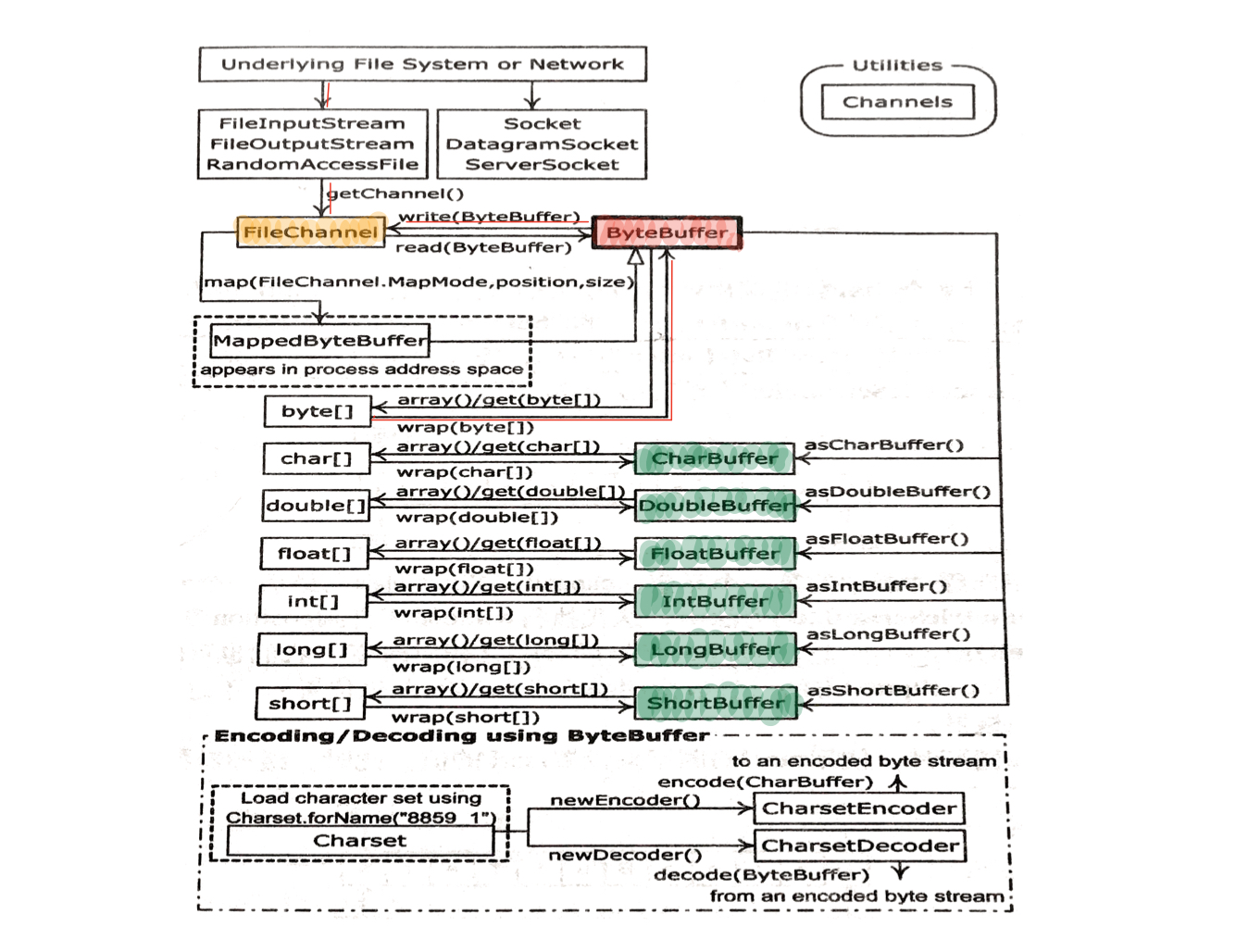
上面的这张图阐明了nio之间的关系,便于我们理解怎样去移动和转换数据。例如,想要把一个字节数组写到文件中去,那么我们就应该做以下事情:
- 使用ByteBuffer.wrap()方法把字节数组包装起来
- 然后,使用getChannel()方法在FileOutputStream上打开一个通道
- 最后,将ByteBuffer中的数据写到FileChannel中去
我们需要注意:ByteBuffer是将数据移进移出通道的唯一方式。我们不能将基本类型缓冲器转换成ByteBuffer,但是,我们可以经由基本类型缓冲器(视图缓冲器)来操纵ByteBuffer中的数据。
缓冲器的更多方法使用
Buffer由数据和可以高效地访问及操纵这些数据的四个索引组成,这四个索引是:mark(标记)、position(位置)、limit(界限)和capacity(容量)。下面是设置索引和复位索引以及查询它们的值的方法。
| 方法 | 含义 |
|---|---|
| capacity() | 返回缓冲区容量 |
| clear() | 清空缓冲区,将position设置为0,limit设置为容量。 |
| flip() | 将limit设置为position,position设置为0。此方法用于准备从缓冲区读取已经写入的方法 |
| limit() | 返回limit值 |
| limit(int lim) | 设置limit值 |
| mark() | 将mark设置为position |
| reset() | 将此缓冲区的位置重置为以前标记的位置 |
| position() | 返回position值 |
| position(int pos) | 设置position值 |
| remaining() | 返回(limit-position),即缓冲区还剩余多少空间 |
| hasRemaining() | 若有介于position和limit之间的元素,则返回true |
在缓冲器中插入和提取数据将会更新这些索引,用于反应所发生的变化。下面将通过一个简单的交换相邻字符来描绘这种变化过程。
public class UsingBuffers {
private static void symmetricScramble(CharBuffer buffer) {
while(buffer.hasRemaining()) {
buffer.mark();
char c1 = buffer.get();
char c2 = buffer.get();
buffer.reset();
buffer.put(c2).put(c1);
}
}
public static void main(String[] args) {
char[] data = "UsingBuffers".toCharArray();
ByteBuffer bb = ByteBuffer.allocate(data.length * 2);
CharBuffer cb = bb.asCharBuffer();
cb.put(data);
System.out.println(cb.rewind());
symmetricScramble(cb);
System.out.println(cb.rewind());
symmetricScramble(cb);
System.out.println(cb.rewind());
}
}
/*
output:
UsingBuffers
sUniBgfuefsr
UsingBuffers
*/
我们在这里采用的是分配一个底层的ByteBuffer,在其之上产生一个CharBuffer视图缓冲器来进行操作。
下面的这组图形描绘了交换相邻字符时,缓冲区内的变化情况:
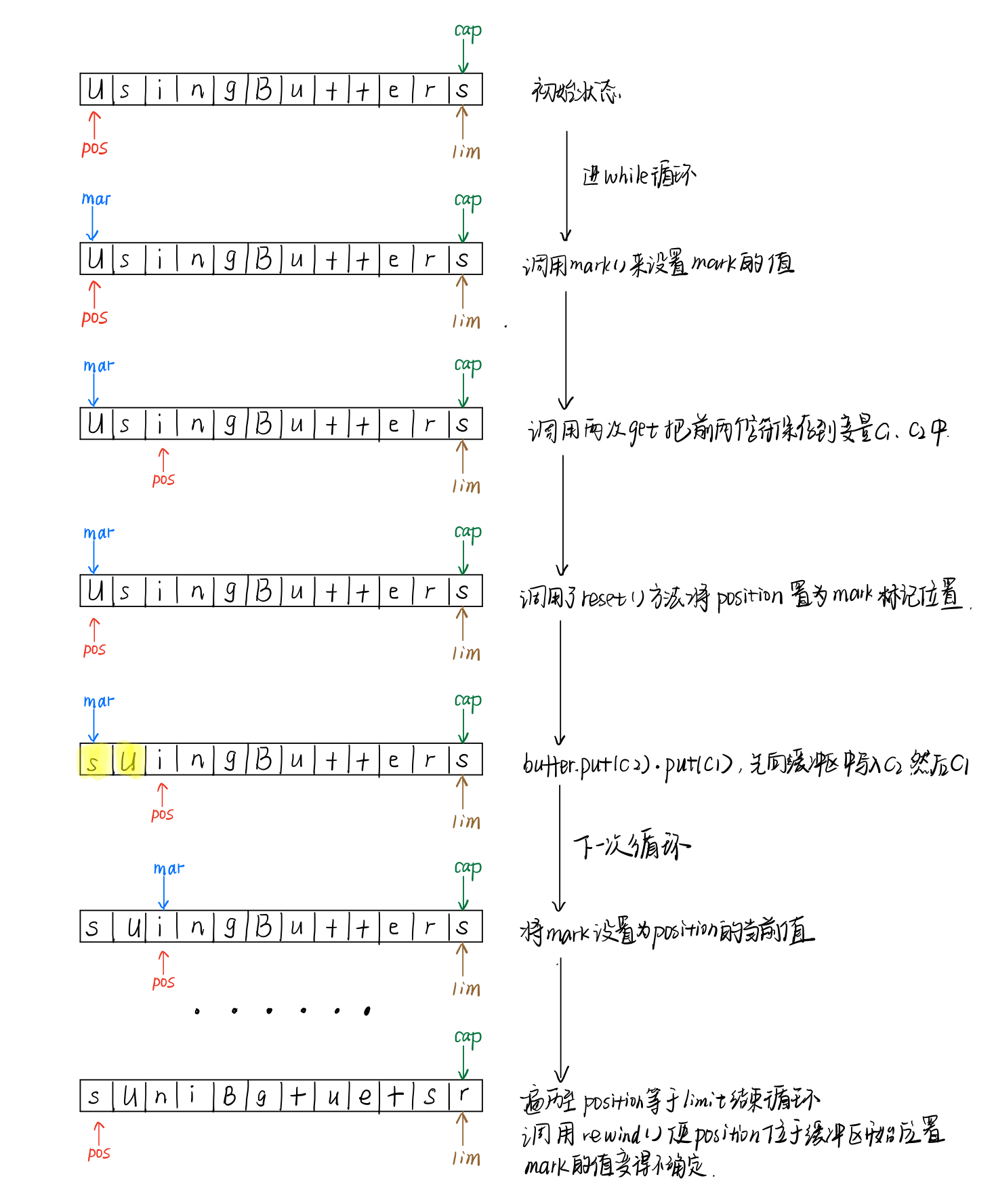
内存映射文件
大多数操作系统都可以利用虚拟内存实现来将一个文件或者文件的一部分“映射”到内存中。然后,这个文件就可以当做内存数组一样地访问,这比传统的文件操作要快的多。java.nio包中使得内存映射使用变得十分简单,我们若是要使用则先获得一个文件上的通道,然后调用map()产生mappedByteBuffer,这是一种特殊类型的直接缓冲器,还需要指定映射文件的初始位置和映射区域的长度,这也就说明我们可以只映射某个大文件的一小部分。
public class LargeMappedFiles {
static int lenght = 0x8FFFFFF; //128MB
public static void main(String[] args) throws Exception{
MappedByteBuffer out = new RandomAccessFile("test.txt", "rw").
getChannel().map(FileChannel.MapMode.READ_WRITE, 0, lenght);
for(int i=0; i<lenght; i++) {
out.put((byte)'x');
}
System.out.println("Finished writing");
for(int i=lenght/2; i<lenght/2+6; i++) {
System.out.println((char)out.get(i));
}
}
}
对象序列化
我们有时候会想将程序运行过程中的对象保存下来,等下一次运行程序时就可以被重建并且拥有拥有和它上一次相同的信息。Java的对象序列化就可以帮我们实现这些。Java的对象序列化将那些实现了Serializable接口的对象转换成一个字节序列,并且能够在以后将这个字节序列完全恢复为原来的对象。这一过程甚至可以通过网络进行,这也意味着序列化机制能够自动弥补不同操作系统之间的差异。
对象序列化是一项非常有趣的技术,它可以实现轻量级持久性(lightweight persistence)。"持久性"意味着一个对象的生命周期并不取决于程序是否正在执行;它可以生存在程序的调用之间。通过将一个序列化对象写入磁盘,然后在重新调用程序时恢复该对象,就可以实现持久性的效果。对象在程序中必须显示地序列化和反序列化还原。如果需要一个更严格的持久性机制,可以考虑Hibernate之类的工具。
对象序列化出现的原因主要是为了支持两种特性:
- Java的
远程方法调用(Remote Method Invocation, RMI),它使存活于其他计算机上的对象使用起来就像是存活在本机上一样。 - 对于Java Beans,对象的序列化也是需要的。使用一个Beans时,一般情况下是在设计阶段对它的状态信息进行配置。这种状态信息必须保存下来,并在程序启动时进行后期恢复;这种具体的工作就是由对象序列化完成的。
如何序列化和反序列化一个对象
序列化:首先该对象要实现了Serializeble接口(标记接口,不包括任何方法)。创建某些OutputStream对象,然后将要序列化的对象封装到一个ObjectOutputStream对象内。调用writeObject()方法便可以将对向序列化,并将其发送给OutputStream(对象序列化是基于字节的)。
反序列化:需要将一个InputStream封装到ObjectInputStream内,然后调用readObject(),获得的是一个指向Object的引用,需要向下转型设置成我们需要的对象。
对象序列化不仅保存了对象的“全景图”,而且还能追踪到对象内所包含的所有引用,并保存那些对象,接着又能对对象内包含的每个这样的引用进行追踪;依次类推。
public class Student implements Serializable {
private static final long serialVersionUID = 1L;//自动添加的一个序列号
private String name;
private Integer age;
public Student() {}
public Student(String n, Integer a){
name = n;
age = a;
}
@Override
public String toString(){
return "Student info [name=" + name + " , age=" + age + "]";
}
public static void main(String[] args){
//--------------序列化
ObjectOutputStream oops = null;
try{
//将对象写入文件
Student stu = new Student("sakura", 20);
oops = new ObjectOutputStream(new FileOutputStream("E://test.txt"));
oops.writeObject(stu);
}
catch(Exception e){
e.printStackTrace();
}
finally{
if(oops != null){
try{
oops.close();
}
catch(Exception e){
e.printStackTrace();
}
}
}
//-----------反序列化
ObjectInputStream oips = null;
try{
oips = new ObjectInputStream(new FileInputStream("E://test.txt"));
//将Student对象的信息读取出来组装成一个Object对象,然后向下转型为Student对象
Student stu_back = (Student)oips.readObject();//向下转型
System.out.println(stu_back);
}
catch (Exception e) {
e.printStackTrace();
}
finally{
if(oips != null){
try{
oips.close();
}
catch (Exception e) {
e.printStackTrace();
}
}
}
}
}
/*
output:
Student info [name=sakura , age=20]
*/
注意在对一个Serializable对象进行还原的过程中,没有调用任何构造器,包括默认的构造器。整个对象都是通过从InputStream中取得数据恢复而来的。对象序列化的文件内容:
transient(瞬时)关键字
当我们进行对序列化进行控制时,可能某个特定的子对象不想让Java的序列化机制自动保存与恢复。比如子对象保存的是密码等敏感信息。那么我们就可以使用transient(瞬时)关键字逐个字段地关闭序列化。
比如在上例中不想保留age域:
private transient Integer age;
将对象序列化然后反序列化后的结果为:
Student info [name=sakura , age=null]
没有被序列化的属性的值将为null

序列化的算法
每个对象都是用序列号(serila number)(序列号代替了对象的内存地址)保存的,这也是这种机制称为序列化的原因。序列化的算法大致如下:
- 对你遇到的每一个对象引用都关联一个序列号
- 对于每个对象,当第一次遇到时,保存其对象数据到输出流中
- 如果某个对象之前已经被保存过了,那么只写出“与之前保存过的序列号为x的对象相同”
在读回对象时,整个过程是反过来的
- 对于对象输入流中的对象,在第一次遇到其序列号时,构建它,并使用流中数据来初始化它,然后记录这个序列号和新对象之前的关联
- 当遇见“与之前保存过的序列号为x的对象相同”标记时,获取与这个顺序号相关联的对象的引用
File类
最后,我们简单介绍下File类。这个名字具有一定的误导性,我们可能会认为它指代的是一个文件,但是事实却并非如此。它既可以代表一个特定的文件的名称,又能代表目录下的一组文件的名称。使用FilePath可能更准确来命名这个类。这个类表示的是文件和目录名的抽象表示。具体的使用不再过多介绍,查看JDK文档便可以了解。
小结
本篇博客大体介绍了Java I/O流的一个发展(字符流到字节流的)、使用装饰器类让流对象具有更多的功能、I/O流的典型使用方式、Java中的标准I/O、NIO中的速度的提升靠的是通道和缓冲区(缓冲区内数据变化时缓冲区的状态变化)和对象序列化。
Java来创建一个合适的流对象要先创建很多的类确实是有点麻烦的,但是理解每个类对象实现的功能是什么以及组装好一个新对象可以拥有什么功能的话,这样的组装也就显得不是那么的麻烦。
Java语言很多时候都是使用基本的类、属性和方法来对操作系统层面的操作进行描述。它只有描述能力,并没有直接操作能力(应该说几乎所有语言都是如此,到底都还是对操作系统调用的封装)。博客一开始就介绍的流还可以理解为:对操作系统层面操作的一个抽象描述以及封装。
对Java中I/O类库的介绍暂记以上。
参考:
[1] Eckel B. Java编程思想(第四版)[M]. 北京: 机械工业出版社, 2007
[2] Cay S,Horstmann. Java核心技术 卷Ⅱ高级特性(第10版)[M]. 北京: 机械工业出版社, 2018.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号