
拉丁超立方体初始化种群(附Matlab代码)
拉丁超立方体初始化种群
1.引言
群智能算法一般以随机方式产生初始化种群的位置,但是这种方式可能导致种群内个体分布不均匀。拉丁超立方体抽样方法产生的初始种群位置,可以保证全空间填充和抽样非重叠,从而使种群分布均匀。
2.LHS抽样过程
step1: 确定抽样规模
step2: 将每维变量的定义域区间划分成个相等的小区间:
这样就将原来的一个超立方体划分成个小超立方体。
step3:产生一个的矩阵,的每列都是数列的一个随机全排列。
step4:的每行就对应一个被选中的小超立方体,在每个被选中的小超立方体内随机产生一个样本。
4.Matlab代码
% ======================================
% 拉丁超立方体初始化种群
% ======================================
% step1:清理运行环境
close all;
clear
clc
% step2:参数设置
n = 30; % 确定抽样规模
d = 2; % 维数
% step3:划分小超立方体
lb = (0:n-1)./n;
ub = (1:n)./n;
% step4:产生一个H*n的全排列矩阵
A = zeros(n, d);
for i=1:d
A(:,i) = randperm(n);
end
% step5:采样
H = zeros(n,d);
for i=1:n
for j=1:d
H(i,j) = unifrnd(lb(A(i,j)), ub(A(i,j)));
end
end
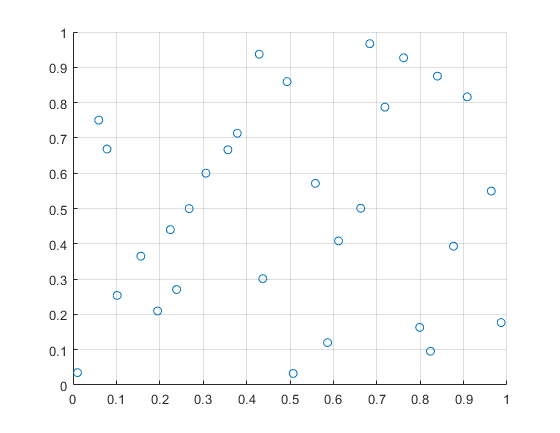
% step6:可视化
figure
scatter(H(:,1),H(:,2));
xlim([0, 1]);
ylim([0, 1]);
grid on;
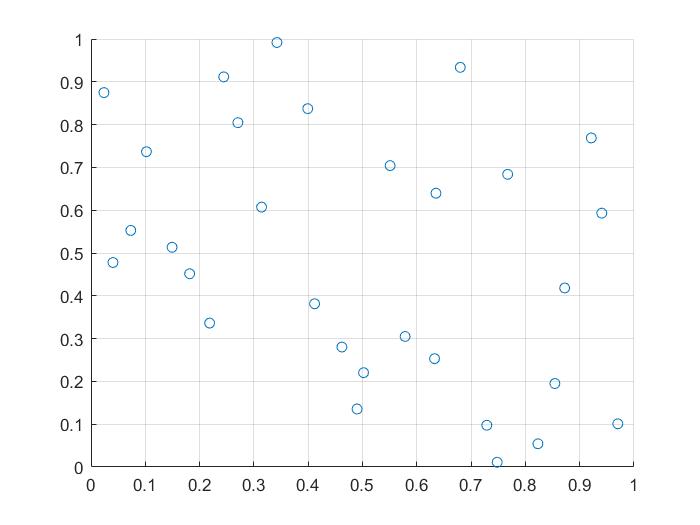
% 拉丁超立方体抽样函数
x = lhsdesign(30, 2);
% step6:可视化
figure
scatter(x(:,1),x(:,2));
xlim([0, 1]);
ylim([0, 1]);
grid on;
分类:
群智能优化算法
标签:
拉丁超立方体初始化种群
, 群智能算法


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 周边上新:园子的第一款马克杯温暖上架
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?
· 使用C#创建一个MCP客户端