综合设计——多源异构数据采集与融合应用综合实践
| 这个项目属于哪个课程 | 2024数据采集与融合技术实践 |
|---|---|
| 组名 | 在大大的数据里面挖呀挖呀挖 |
| 项目简介 | 项目名称:城市记忆 Logo: 项目需求:整合城市历史文化资源:需要以交互式的方式展示城市的历史发展、新旧照片、方言特色以及名人故事等内容。增强用户参与感:为用户提供交互性体验,如照片上色、语音生成、内容检索等。利用多媒体技术提升展示效果:通过地图、视频、音频、图像等多种形式,全方位展示城市记忆,构建沉浸式体验。 项目开展技术路线:python、html、JavaScript、flask、mysql |
| 团队成员学号 | 102202114农晨曦,102202118杨美荔、102202144傅钰、102202147赖越、102202150魏雨萱、102202152张静雯 |
| 这个项目的目标 | 建立多模块融合的城市记忆平台:打造一个集历史资源展示、文化传承和科技互动为一体的平台。 提升用户体验与交互性:通过地图导航、名人故事展示、黑白照片上色和方言音频生成等功能,让用户更生动地了解城市文化。 促进文化保护与传承:利用现代技术对城市历史资源进行数字化存档,帮助大众更便捷地探索与分享城市记忆。 探索跨学科技术融合:结合深度学习、多模态技术与地理信息系统等技术,提升文化展示的深度与广度。 |
| 其他参考文献 | 近20 年城市记忆研究综述 城市记忆与城市形态——从心理学、社会学视角探讨城市历史文化的延续 星火认知大模型Web API文档 |
| gitee链接 | gitee链接 |
综合设计——多源异构数据采集与融合应用综合实践
项目介绍
项目Logo

项目背景
城市记忆承载着一座城市的历史、文化与情感,其背后的故事和影像是研究城市变迁与文化保护的重要资源。然而,许多城市的历史资源缺乏系统化的整理与展示,普通大众难以方便地接触这些内容。随着人工智能与多媒体技术的快速发展,利用技术手段将历史内容与现代形式结合,可以更好地传递城市文化,增强公众的文化认同感。
功能介绍
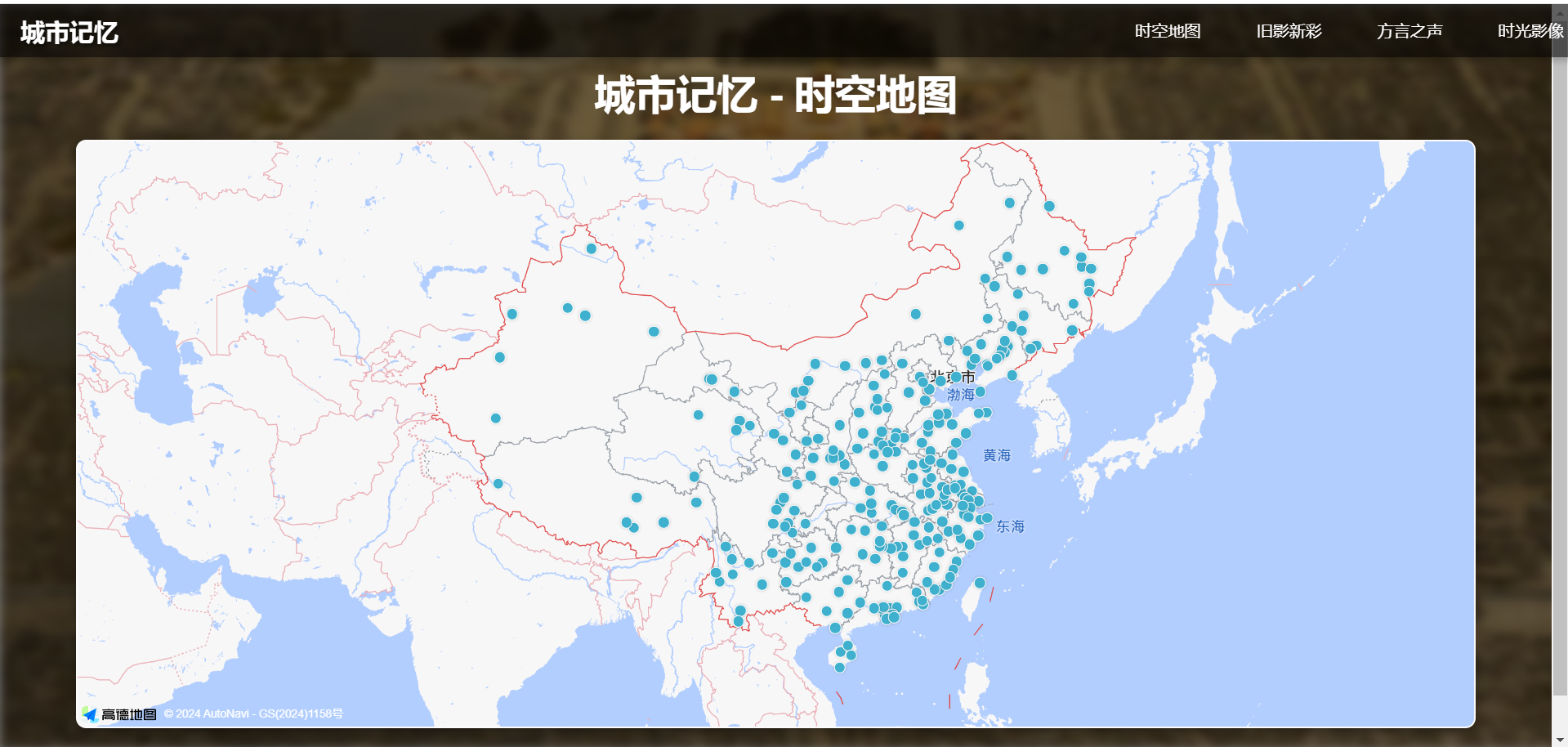
- 时空地图
功能描述:
用户通过交互式地图探索城市历史文化资源。
点击地图标记点:显示对应城市的方言音频、新旧照片对比、历史发展时间轴信息。
查看名人故事:点击标记点的“名人故事”按钮跳转到城市的名人集页面,展示与该城市相关的名人列表。
名人故事展示:点击名人列表中的名人姓名,可以查看详细的名人故事,包括其生平事迹、贡献和与城市的关联性。
技术实现:
使用 高德地图 API 提供地图展示与交互功能。
数据库存储包含城市地理信息及相关文化资源。
名人资源使用Spark 4.0 Ultra搜索并整理名人集和名人故事。 - 照片上色
功能描述:
用户上传黑白照片,系统自动将其转换为色彩丰富的上色照片,直观展现历史影像的色彩还原效果。
支持多种照片格式,快速处理。
生成对比图,展示黑白原图与上色图的差异。
技术实现:
使用 百度图片上色接口 提供高精度的图片上色服务。
后端实现文件上传和上色结果的高效存储与展示。 - 方言之声
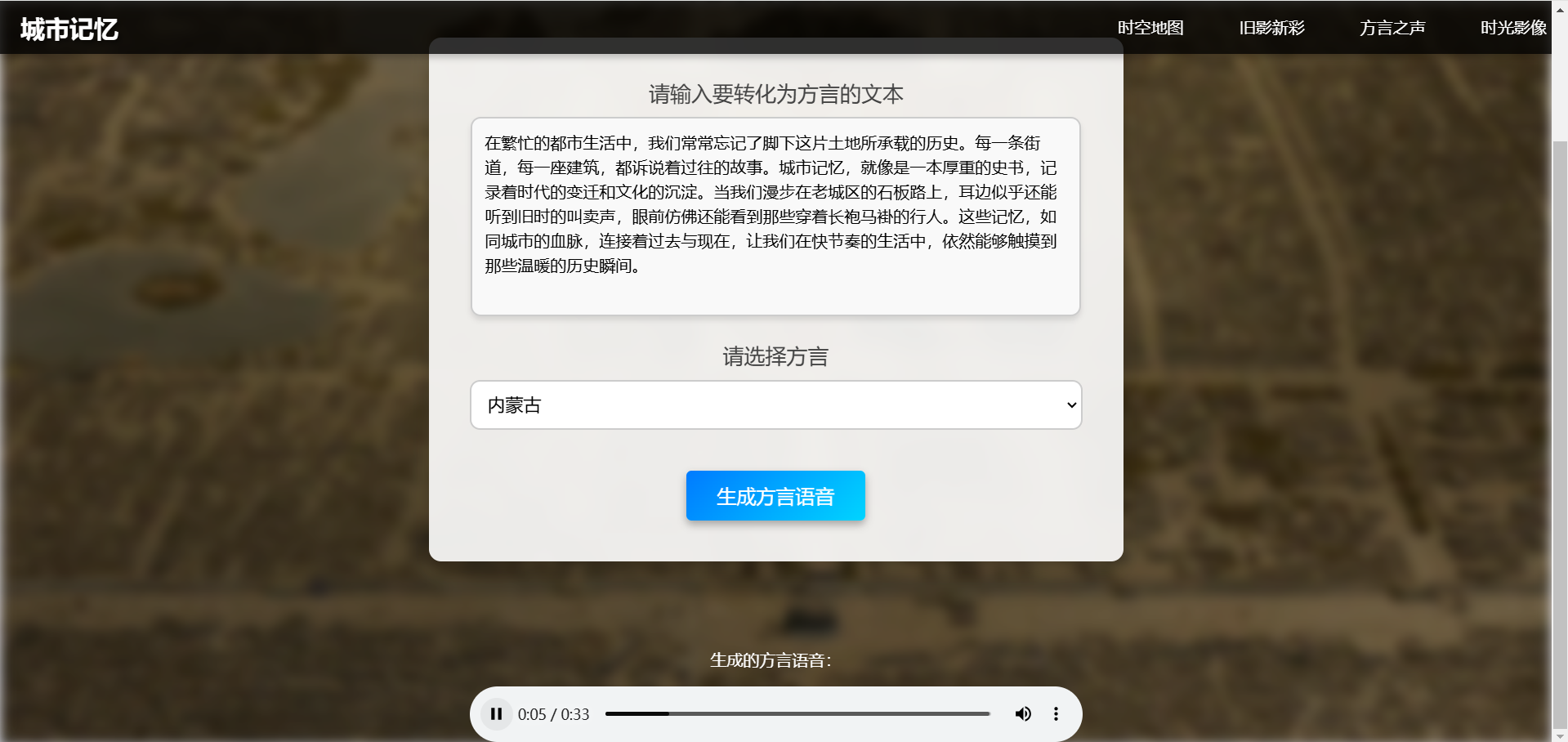
功能描述:
用户输入一段文本并选择城市名称,系统自动生成对应城市方言的音频文件。
支持多种方言生成,包括普通话、粤语、东北话等。
生成音频后提供播放功能,用户可以在线收听或下载保存。
技术实现:
使用 讯飞星火语音合成 API 实现高质量的多方言语音合成。 - 时光影像
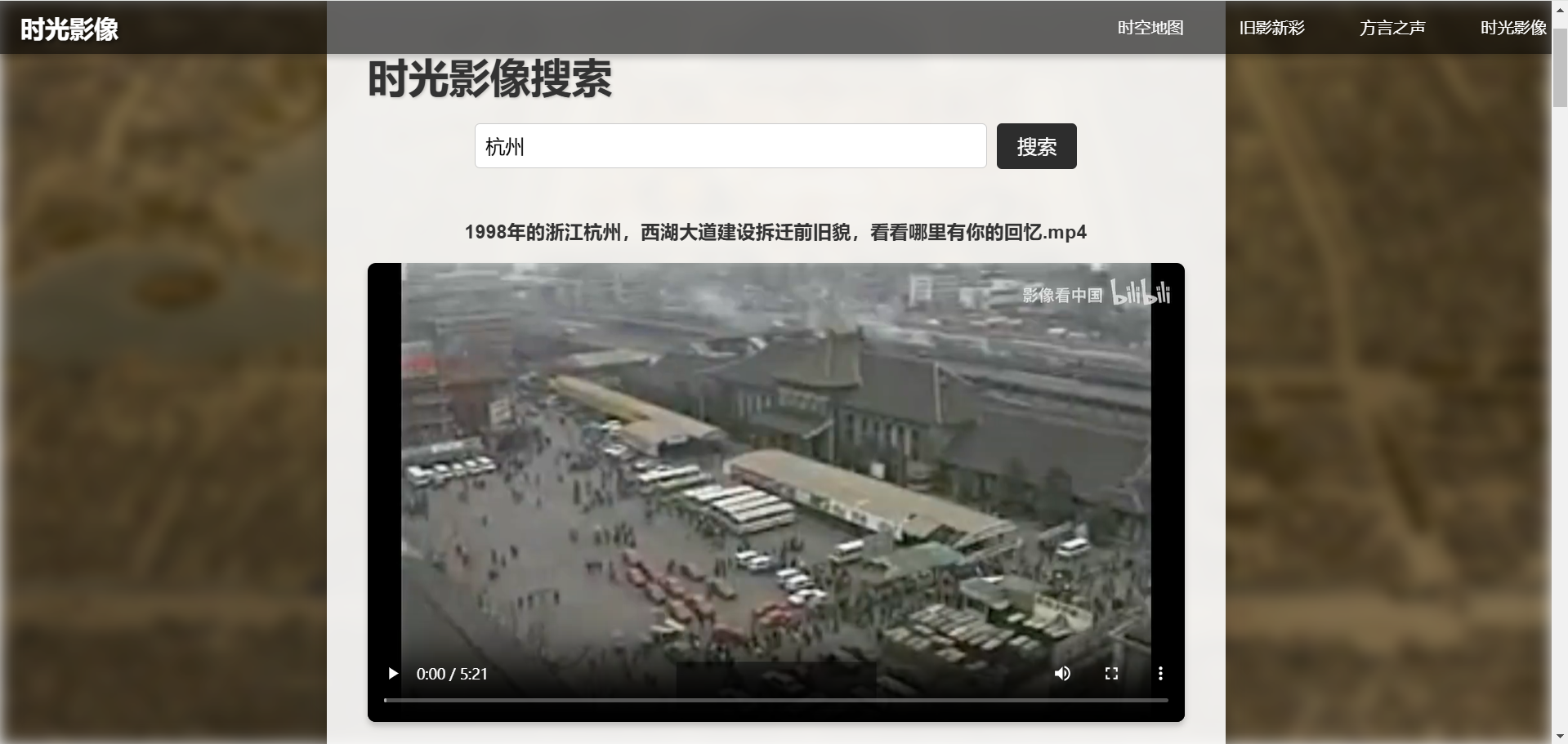
功能描述:
用户输入城市名称,系统搜索该城市的老视频并在页面中展示。
视频内容涵盖城市建设、名胜古迹、历史活动等主题。
视频可在线播放,支持用户分享和下载功能。
技术实现:
后端通过查询 MySQL 数据库,根据用户输入的城市关键词匹配相关视频链接。
视频资源通过动态渲染展示在页面,支持跨平台兼容的播放功能。
技术路线
- 前端
使用 HTML + CSS + JavaScript 开发实现页面布局与动画效果框架,支持动态渲染和响应式设计,兼容多种设备(PC 和移动端),提升视觉吸引力。
高德地图 API 集成,用于实现地图标记与交互功能。 - 后端
基于 Flask 框架开发 RESTful API,与前端交互。
集成第三方服务接口(高德地图API、百度AI图片上色接口、讯飞星火语音合成API、Spark4.0 UltraAPI)。
提供与 MySQL 数据库的高效交互,支持查询与数据更新。 - 数据库
使用 MySQL 数据库存储视频链接、名人信息和其他相关数据。
提供灵活的表结构设计,便于数据检索与扩展。 - AI 技术
图片上色:集成百度AI图片上色接口,实现黑白图像智能上色。
语音合成:调用讯飞星火语音合成API生成高质量方言语音。
数据检索:借助 Spark4.0 UltraAPI 快速检索与展示名人集和名人故事数据。 - 爬虫数据采集
使用 Python 爬虫技术 (如 Scrapy、Requests、BeautifulSoup 等)从各类公共数据源(如百科、城市历史网站、档案馆、哔哩哔哩)抓取城市历史数据、名人故事、黑白照片、老视频等内容,并存入数据库供后续处理和展示。
在搜索到名人之后使用Selenim同时爬取名人照片并展示。
动态加载和解析页面数据,清洗并规范化抓取到的信息,确保数据质量和一致性。 - 华为云多媒体资源管理
结合华为云OBS管理照片、音频与视频资源,确保高效访问与展示。 - 华为云应用部署
对象存储服务(OBS):用于存储历史照片、视频、音频等大规模多媒体资源,提供高效、稳定的访问与存储解决方案。
云数据库(RDS):采用 MySQL 数据库,支持名人信息、视频链接等结构化数据的高效存储与管理。
弹性云服务器(ECS):部署后端 Flask 服务,与前端实现高效数据交互。
提供灵活的计算能力,适应不同流量负载需求。
虚拟私有云(VPC)
弹性公网 IP(EIP):保障公网访问能力,实现外部用户访问网站的高可用性与稳定性。
部署需要配合宝塔面板:配合华为云弹性云服务器,简化网站部署与运维操作。提供便捷的环境配置管理、日志监控与故障排查工具。
结果展示
首页

时空地图
点击城市后出现方言音频、新旧照片、历史事件时间轴
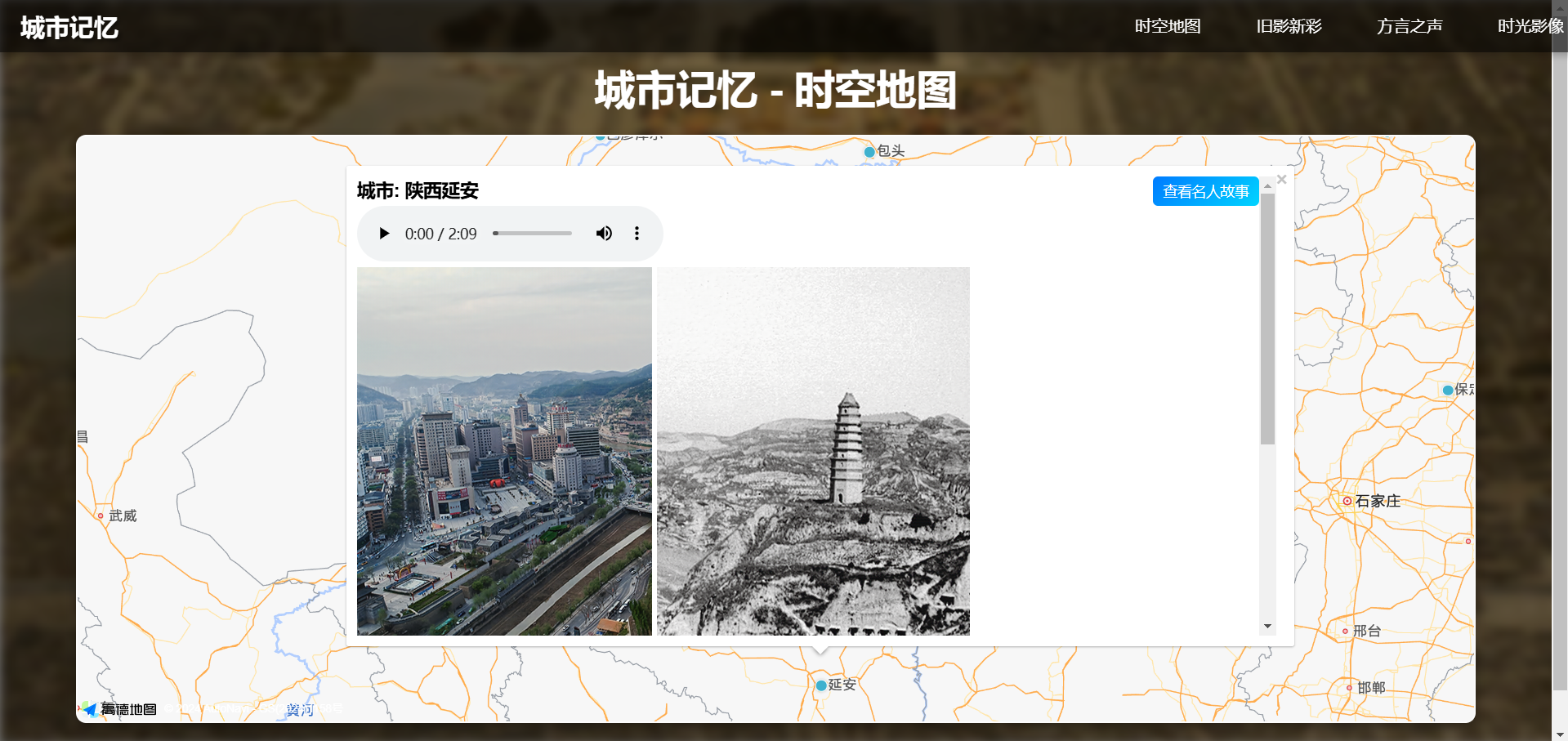
点击查看名人故事,跳转到名人集

点击一位名人跳转到名人故事

旧影新彩

方言之声
时光影像
个人分工
数据采集
我负责采集各个城市的新旧照片,刚开始想要从一些政府网站或者是城市博物馆爬取但是有的城市没有,而且比较分散,难度很大。然后又想到找看看是否有老照片网站可以直接大批量爬取,但是并没有找到符合要求的城市老照片网站,大部分都是历史事件的照片,所以这个方法也不行。最后只能使用百度图片搜索特定城市的新旧照片,提取图片url并下载。
使用了selenium模拟浏览器,并整理出了中国所有城市的xlsx文件,先定位搜索框输入关键字后搜索,等待进入图片页面之后点击需要的图片,程序获得该图片的url,并发送请求下载。
import os
import pandas as pd
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from PIL import Image
import requests
from io import BytesIO
# 设置 Chrome 浏览器配置
def setup_driver():
options = Options()
options.add_argument("--start-maximized") # 最大化窗口
options.add_argument("--disable-infobars") # 禁用提示栏
options.add_argument("--disable-extensions") # 禁用扩展
driver = webdriver.Chrome(options=options) # 创建 WebDriver 对象
return driver
# 从 Excel 读取省市数据
def read_excel(file_path):
df = pd.read_excel(file_path)
# 去掉包含空值的行
df = df.dropna(subset=['省份', '城市'])
search_terms = []
for index, row in df.iterrows():
province = row['省份']
city = row['城市']
if province==city:
search_terms.append(f"{province}新旧照片对比")
else:
search_terms.append(f"{province}{city}新旧照片对比")
return search_terms
# 搜索图片并等待用户选择
def search_images(driver, search_term):
driver.get("https://image.baidu.com/")
driver.switch_to.window(driver.window_handles[-1])
WebDriverWait(driver, 10,0.5).until(EC.presence_of_element_located((By.XPATH, "//*[@id='app']/div/div[1]/div/div["
"3]/div[2]/div[1]/form/span["
"1]/input")))
search_box=driver.find_element(By.XPATH,"//*[@id='app']/div/div[1]/div/div[3]/div[2]/div[1]/form/span[1]/input")
search_box.clear()
search_box.send_keys(search_term)
time.sleep(1.5)
search_box.send_keys(Keys.RETURN)
time.sleep(1.5)
# 下载图片到本地
def download_image(image_url, save_path):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/130.0.0.0 Safari/537.36",
"Cookie":"BDIMGISLOGIN=0; BDqhfp=%E5%8C%97%E4%BA%AC%E6%96%B0%E6%97%A7%E7%85%A7%E7%89%87%E5%AF%B9%E6%AF%94%26""
}
try:
response = requests.get(image_url, headers=headers)
response.raise_for_status()
img = Image.open(BytesIO(response.content))
img.save(save_path)
print(f"图片已保存到 {save_path}")
except Exception as e:
print(f"下载图片失败: {e}")
# 主函数
def main():
excel_path = "省市数据.xlsx" # 替换为你的 Excel 文件路径
save_dir = "新旧对比图片" # 替换为图片保存目录
os.makedirs(save_dir, exist_ok=True)
# 读取 Excel 数据
search_terms = read_excel(excel_path)
print(f"读取到 {len(search_terms)} 个搜索关键词。")
# 设置浏览器
driver = setup_driver()
try:
for search_term in search_terms:
print(f"搜索关键词:{search_term}")
search_images(driver, search_term)
# 等待用户选择图片并点击进入详情页
input("请点击选择图片,点击进入详情页后按回车键继续...")
driver.switch_to.window(driver.window_handles[-1])
# 获取当前页面的图片 URL
WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.XPATH, '//*[@id="srcPic"]/div'))
)
image_url=driver.find_element(By.XPATH,'//*[@id="srcPic"]//img').get_attribute("src")
print(f"检测到图片 URL: {image_url}")
# 下载图片
file_name = search_term.replace(" ", "_") + ".jpg"
save_path = os.path.join(save_dir, file_name)
download_image(image_url, save_path)
# 等待用户确认下一步
next_step = input("继续下一个搜索?输入 'n' 退出,按回车键继续: ")
if next_step.lower() == 'n':
break
finally:
driver.quit()
if __name__ == "__main__":
main()
收集到的照片
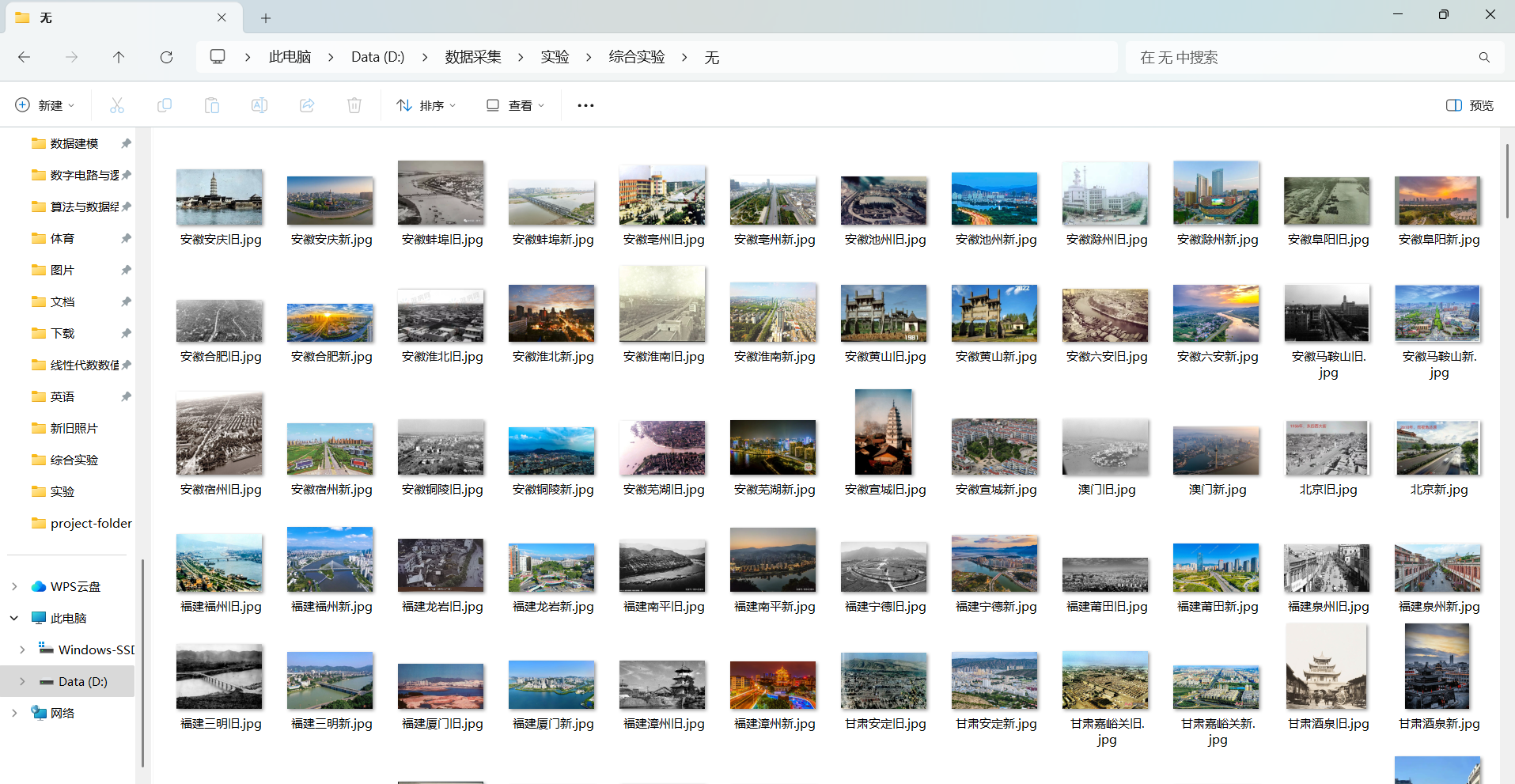
数据预处理及特征提取
在这个阶段我对采集到的图片数据进行预处理
首先统一每个城市的新旧照片大小,方便后续网站新旧照片对比图,还有对图片增强清晰度
import os
from PIL import Image, ImageFilter, ImageEnhance
# 输入和输出文件夹路径
input_dir = "./无" # 替换为你的输入文件夹路径
output_dir = "./调整后的照片" # 替换为你的输出文件夹路径
# 确保输出文件夹存在
os.makedirs(output_dir, exist_ok=True)
# 遍历文件夹中的文件
for filename in os.listdir(input_dir):
if filename.endswith("旧.jpg"): # 查找旧照片
city_name = filename.replace("旧.jpg", "") # 提取城市名称
old_photo_path = os.path.join(input_dir, filename)
new_photo_path = os.path.join(input_dir, f"{city_name}新.jpg")
# 检查是否存在对应的新照片
if not os.path.exists(new_photo_path):
print(f"未找到新照片: {city_name}新.jpg,跳过...")
continue
# 打开旧照片和新照片
try:
old_image = Image.open(old_photo_path).convert("RGB") # 确保旧照片为RGB模式
new_image = Image.open(new_photo_path).convert("RGB") # 确保新照片为RGB模式
except Exception as e:
print(f"加载图片失败: {city_name},错误: {e}")
continue
# 调整新照片大小为与旧照片一致
try:
new_image_resized = new_image.resize(old_image.size, Image.Resampling.LANCZOS)
# 使用 ImageEnhance 调整锐化强度
sharpness_factor = 1.2 # 锐化强度(1.0表示无变化,低于1.0是减弱,大于1.0是增强)
old_image_sharpened = ImageEnhance.Sharpness(old_image).enhance(sharpness_factor)
new_image_sharpened = ImageEnhance.Sharpness(new_image_resized).enhance(sharpness_factor)
# 保存调整后的图片
output_new_photo_path = os.path.join(output_dir, f"{city_name}新.jpg")
output_old_photo_path = os.path.join(output_dir, f"{city_name}旧.jpg")
new_image_sharpened.save(output_new_photo_path, format="JPEG")
old_image_sharpened.save(output_old_photo_path, format="JPEG")
print(f"已调整新照片大小并降低锐化强度: {output_new_photo_path}")
except Exception as e:
print(f"调整大小或降低锐化强度失败: {city_name},错误: {e}")
增加清晰度最开始使用了python的pillow库增强锐化以增加清晰度,但是效果不好
后面使用了 GFPGAN 模型进行图片修复,从而也联想到可以在网站中增加一个老照片上色功能,增强用户体验
import os
from deoldify.visualize import get_image_colorizer
from gfpgan import GFPGANer
# 文件路径配置
input_dir = './inputs/' # 输入照片文件夹
intermediate_dir = './intermediate/' # 修复后的中间文件夹
output_dir = './results/' # 上色后的结果文件夹
os.makedirs(intermediate_dir, exist_ok=True)
os.makedirs(output_dir, exist_ok=True)
# 初始化 GFPGAN
restorer = GFPGANer(model_path='./GFPGAN/experiments/pretrained_models/GFPGANv1.3.pth', upscale=2)
# 初始化 DeOldify
colorizer = get_image_colorizer(artistic=True)
# 批量处理图片
for file_name in os.listdir(input_dir):
if file_name.endswith('.jpg') or file_name.endswith('.png'):
input_path = os.path.join(input_dir, file_name)
intermediate_path = os.path.join(intermediate_dir, file_name)
output_path = os.path.join(output_dir, file_name)
# 1. 使用 GFPGAN 修复照片
_, restored_image, _ = restorer.enhance(input_path)
restored_image.save(intermediate_path)
print(f'修复完成: {intermediate_path}')
左边是使用pillow的修复效果,右边是使用GPFGAN的效果


也尝试过特征提取将同一个城市新旧照片部分高亮出来,从而更好的观察城市变迁,但是生成的照片破坏了原来的照片,所以没有采取这个想法。
API调研
图片上色API比较了阿里云和百度的图像上色接口,阿里云需要使用SDK调用,百度使用http连接,相对来说百度的速度快一些。
方言语音合成API,该开始想要使用一些TTS模型,通过训练模仿发言者的口音,训练完成后,用户给出文本和城市,用该城市方言读出文本,但是确实是想得太简单了,首先收集到的方言都比较短,样本太少不能很好的学习到每个方言的特征,而且目前还没有成熟的方言大模型,所以是一次没有结果的尝试,后面直接使用了讯飞语音合成API,支持方言发言人。
搜索API,比较了百度ERNIE 4.0和讯飞Spark 4.0 Ultra,发现讯飞的搜索结果较为准确,而且回答的速度较快。
网站搭建
我负责接入方言语音合成API以及搜索API,还有对应模块的后端实现
调用讯飞语音合成 API:
通过 WebSocket 与讯飞 API 交互,将文本合成为音频文件。
使用鉴权机制构建安全的 WebSocket 连接 URL。
建立 WebSocket 连接后,按固定格式发送语音合成请求。
接收 API 返回的音频数据,并实时解码保存。
根据用户指定的方言,选择对应的讯飞发音人(vcn 参数)。
class Ws_Param(object):
# 初始化
def __init__(self, vcn, Text):
self.APPID = "f68721d9"
self.APIKey = "b259afc8d3be4670017f3ebba9bd0d37"
self.APISecret = "YTMyMWYyOTBhNjViNTBiMDMwMzRhMzIw"
self.Text = Text
self.vcn = vcn
# 公共参数(common)
self.CommonArgs = {"app_id": self.APPID}
self.BusinessArgs = {"aue": "lame", "sfl": 1, "auf": "audio/L16;rate=16000", "vcn": self.vcn, "tte": "utf8"}
self.Data = {"status": 2, "text": str(base64.b64encode(self.Text.encode('utf-8')), "UTF8")}
# 生成url
def create_url(self):
url = 'wss://tts-api.xfyun.cn/v2/tts'
# 生成RFC1123格式的时间戳
now = datetime.now()
date = format_date_time(mktime(now.timetuple()))
# 拼接字符串
signature_origin = "host: " + "ws-api.xfyun.cn" + "\n"
signature_origin += "date: " + date + "\n"
signature_origin += "GET " + "/v2/tts " + "HTTP/1.1"
# 进行hmac-sha256进行加密
signature_sha = hmac.new(self.APISecret.encode('utf-8'), signature_origin.encode('utf-8'),
digestmod=hashlib.sha256).digest()
signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8')
authorization_origin = "api_key=\"%s\", algorithm=\"%s\", headers=\"%s\", signature=\"%s\"" % (
self.APIKey, "hmac-sha256", "host date request-line", signature_sha)
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
# 将请求的鉴权参数组合为字典
v = {
"authorization": authorization,
"date": date,
"host": "ws-api.xfyun.cn"
}
# 拼接鉴权参数,生成url
url = url + '?' + urlencode(v)
# print("date: ",date)
# print("v: ",v)
# print('websocket url :', url)
return url
def on_message(ws, message):
try:
message = json.loads(message)
code = message["code"]
sid = message["sid"]
audio = message["data"]["audio"]
audio = base64.b64decode(audio)
status = message["data"]["status"]
print(message)
if status == 2:
print("ws is closed")
ws.close()
if code != 0:
errMsg = message["message"]
print("sid:%s call error:%s code is:%s" % (sid, errMsg, code))
else:
with open('./demo.mp3', 'ab') as f:
f.write(audio)
except Exception as e:
print("receive msg,but parse exception:", e)
# 收到websocket连接建立的处理
def on_open(ws, wsParam):
def run(*args):
d = {"common": wsParam.CommonArgs,
"business": wsParam.BusinessArgs,
"data": wsParam.Data,
}
d = json.dumps(d)
print("------>开始发送文本数据")
ws.send(d)
if os.path.exists('./demo.mp3'):
os.remove('./demo.mp3')
thread.start_new_thread(run, ())
@fangyan_bp.route('/generate_dialect', methods=['POST'])
def generate_dialect():
try:
data = request.get_json()
text = data.get("text", "").strip()
dialect = data.get("dialect", "putonghua")
if not text:
return jsonify({"error": "文本内容不能为空"}), 400
# 方言发音人选择
vcn_mapping = {
"anhuihefei": "x2_xiaofei",
"taiwan": "x4_twcn_ziwen_assist",
"shandong": "x2_xiaodong",
"shanghai": "x3_ziling",...
}
vcn = vcn_mapping.get(dialect, "x4_lingyuyan")
# 创建 WebSocket 参数
wsParam = Ws_Param(vcn=vcn, Text=text)
websocket.enableTrace(False)
wsUrl = wsParam.create_url()
# 保存音频文件
output_file = f"static/audio_{int(time.time())}.mp3"
ws = websocket.WebSocketApp(
wsUrl,
on_message=lambda ws, message: save_audio(message, output_file),
on_error=on_error,
on_close=on_close
)
ws.on_open = lambda ws: on_open(ws, wsParam) # 显式传递 wsParam
ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})
# 返回音频文件 URL
audio_url = f"/{output_file}"
return jsonify({"audio_url": audio_url}), 200
except Exception as e:
print("An error occurred:", str(e))
return jsonify({"error": "服务器内部错误", "details": str(e)}), 500
搜索AI接入的是Spark 4.0 Ultra,接入AI接口倒是不是很大的问题,主要是处理接口的返回结果,虽然返回的是json格式,但是因为设置了流式返回,所以需要每返回一个回答就处理一次,而且每次回答的结果不同,所以处理这些回答花的时间比较久。
def stream_famous_people():
try:
print(f"Requesting famous people data for city: {city}") # Debug: City being queried
response = requests.post(url, headers=headers, json=data, stream=True)
response.raise_for_status() # 错误处理
response.encoding = "utf-8"
print("Received response from AI API") # Debug: API Response received
# Iterate through the lines of the response stream
for line in response.iter_lines(decode_unicode=True):
if line:
line = line.strip() # 去除首尾空白字符
if line.startswith('data:'):
conten = line[5:].strip() # 移除'data:'前缀
if conten and conten != "[DONE]":
try:
# Check if the content is valid JSON and parse it
if conten.startswith("{") and conten.endswith("}"):
content_json = json.loads(conten) # 解析JSON数据
# Extract the 'choices' field, which contains the relevant data
choices = content_json.get("choices", [])
print("choices", choices)
for choice in choices:
delta = choice.get("delta", {})
content = delta.get("content", "")
# Clean the content and parse JSON if valid
cleaned_content = content.strip(",\n").strip()
print("cleaned_content", cleaned_content)
if cleaned_content.startswith("{") and cleaned_content.endswith("}"):
try:
famous_person = json.loads(cleaned_content) # 解析名人数据
print("famous_person", famous_person)
# Extract name and field
name = famous_person.get("name")
field = famous_person.get("field") or famous_person.get("domain")
print("name", name)
if name and field: # Only return if name or field exists
# Stream the famous person data to the client
yield f"data: {json.dumps({'name': name, 'field': field})}\n\n"
elif name and not field:
yield f"data: {json.dumps({'name':name,'field':''})}\n\n"
except json.JSONDecodeError as e:
print(f"Error parsing inner JSON: {e}")
except json.JSONDecodeError as e:
print(f"Error parsing JSON: {e}")
except Exception as e:
print(f"Error processing line: {e}")
yield "data: [DONE]\n\n" # Signal the end of the stream
except requests.exceptions.RequestException as e:
print(f"Error fetching data from AI API: {str(e)}") # Debug: Error fetching data
yield f"data: {json.dumps({'error': str(e)})}\n\n"
return Response(stream_famous_people(), content_type="text/event-stream")
以及根据API返回的结果需要爬取每个名人的图片并生成名人卡片
刚开始使用了百度图片的API,但是该API对python有反爬,所以还是只能使用selenium模拟浏览器爬取图片。
@mingrengushi_bp.route('/api/fetch_image', methods=['GET'])
def fetch_image():
name = request.args.get('name')
if not name:
return jsonify({"success": False, "message": "请提供名人名称"}), 400
search_url = f"https://image.baidu.com/search/index?tn=baiduimage&word={urllib.parse.quote(name)}"
# Configure Selenium to run headlessly
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
prefs = {"profile.managed_default_content_settings.images": 2} # Disable image loading
chrome_options.add_experimental_option("prefs", prefs)
driver = webdriver.Chrome(options=chrome_options)
try:
driver.get(search_url)
time.sleep(3) # Wait for images to load
# Find the first image on the page
image_element = driver.find_element(By.XPATH, "//img[@class='main_img img-hover']") # XPath to the main image
image_url = image_element.get_attribute("src")
if image_url:
return jsonify({"success": True, "message": "获取图片成功", "data": [image_url]})
else:
return jsonify({"success": False, "message": "未找到图片"}), 404
except Exception as e:
return jsonify({"success": False, "message": f"获取图片失败: {str(e)}"}), 500
finally:
driver.quit()
部署
将应用部署到华为云
首先购买弹性ECS服务器,因为在cloudshell或者其他工具进行部署只能使用命令,所以选择使用宝塔面板进行部署。
宝塔面板是可视化界面,可以直接在其中通过选择配置LNMP环境以及python环境,还有连接服务器中的mysql数据库。
在宝塔面板中直接添加python项目,通过配置端口,配置主机地址,添加反向代理,URL映射等就可以通过外网访问该项目了
因为项目中有用到selenium,所以需要额外下载chrome和chromedriver
心得体会
在这个项目中几乎所有过程都有参与,从数据采集到预处理、特征提取、数据存储以及应用搭建,应用的部署,收获了很多,首先是对多模态数据处理(图像、文本、音频、视频)的理解更加深入,熟悉了从零到一构建完整项目的过程,包括数据采集、数据处理、使用大模型接口和应用部署。通过“城市记忆”这个项目主题我也体会到 文化传承与技术结合的意义,技术不仅是工具,更是传播文化、保护历史的重要桥梁。
但是在项目过程中,也面临了一些挑战,比如多模态数据的融合复杂性、历史与现代数据的对应难点,以及用户内容管理的效率等问题。但是这些问题最终得到了有效解决,我也从中获得了宝贵的经验。同时也认识到了自己的不足,因为项目初期我在项目管理方面没有经验,导致整个项目的完成效率较低,进度落后,所以项目后期比较着急。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号