数据采集与融合技术实践作业二
数据采集与融合技术实践作业二
gitee链接:https://gitee.com/wei-yuxuan6/myproject/tree/master/作业2
作业①
爬取指定城市七日天气实验
-
要求:在中国气象网(http://www.weather.com.cn)给定城市集的 7日天气预报,并保存在数据库。
-
输出信息:
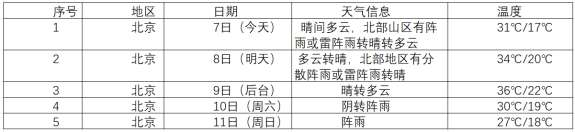
-
过程
打开中国天气网搜索一个城市,这里选择福州,打开检查查看网页结构,可以找到每天天气分别在一个ul元素下的li元素中,日期在li下的h1元素中,天气在li下的class为‘wea’的p元素文本中,温度在class为‘tem’下的p元素下的span元素和i元素文本中,因为有清楚的结构所以选择使用BeautifulSoup的CSS选择器查找HTML元素。
同时不同城市的URL不一样,主要是它们的城市编码不同,所以需要获得要爬取的城市的编码,并写在字典中,以便构造URL时使用
-
部分代码
# 获取指定城市的天气预报数据 # 获取指定城市的天气预报数据 def forecastCity(self, city): # 检查城市是否在城市编码字典中 if city not in self.cityCode.keys(): print(city + " code cannot be found") return # 构建天气预报页面的URL url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml" try: # 发送HTTP请求获取网页内容 req = urllib.request.Request(url, headers=self.headers) data = urllib.request.urlopen(req) data = data.read() # 处理网页编码问题 dammit = UnicodeDammit(data, ["utf-8", "gbk"]) data = dammit.unicode_markup # 使用BeautifulSoup解析网页数据 soup = BeautifulSoup(data, "lxml") # 提取包含天气信息的 <li> 标签 lis = soup.select("ul[class='t clearfix'] li") no=1 # 遍历每个 <li> 标签,提取天气信息 for li in lis: try: # 提取日期、天气状况、温度和风速信息 date = li.select('h1')[0].text weather = li.select('p[class="wea"]')[0].text temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text wind = li.select('p[class="win"] i')[0].text # 打印天气信息 weather = weather.ljust(10, ' ') # 使用全角空格对齐 print("{:<5} {:<5} {:<10} {:<10} {:<10} {:<10}".format(no,city, date, weather, temp, wind)) no+=1 # 将天气数据插入数据库 self.db.insert(city, date, weather, temp, wind) except Exception as err: # 捕捉并打印提取过程中可能出现的错误 print(err) except Exception as err: # 捕捉并打印请求过程中可能出现的错误 print(err)以上是构造请求(包括URL和请求头)、获得网页内容和提取信息并打印的过程,这里使用了urllib.request方法发送请求,使用urlopen获取网页内容并使用UnicodeDammit编码,还要将每一条天气插入数据库,URL中的self.cityCode[city]就是从字典中获取城市对应编码
# 定义数据库操作类,用于管理天气数据 class WeatherDB: # 打开数据库并创建表格 def openDB(self): # 连接到数据库文件,数据库文件名为 weathers.db self.con = sqlite3.connect("weathers.db") self.cursor = self.con.cursor() try: # 创建天气表,包含城市、日期、天气状况、温度和风速等字段,并设置城市和日期为主键 self.cursor.execute( "create table weathers(wCity varchar(16),wDate varchar(16),wWeather varchar(64),wTemp varchar(32)," "wWind varchar(16),constraint pk_weather primary key(wCity,wDate))") except: # 如果表已存在,清空表中的所有数据 self.cursor.execute("delete from weathers") # 关闭数据库连接 def closeDB(self): # 提交事务并关闭连接 self.con.commit() self.con.close() # 插入天气数据 def insert(self, city, date, weather, temp, wind): try: # 将天气数据插入到数据库中 self.cursor.execute( "insert into weathers(wCity,wDate,wWeather,wTemp,wWind)values(?,?,?,?,?)", (city, date, weather, temp, wind)) except Exception as err: # 如果插入失败,打印错误信息 print(err) # 显示数据库中的所有天气数据 def show(self): # 查询所有天气记录 self.cursor.execute("select * from weathers") rows = self.cursor.fetchall() # 打印表头 print("%-16s%-16s%-32s%-16s%-16s" % ("city", "date", "weather", "temp", "wind")) # 遍历每一行数据并打印 for row in rows: print("%-16s%-16s%-32s%-16s%-16s" % (row[0], row[1], row[2], row[3], row[4]))以上是数据库操作,包括打开数据库(要连接数据库文件),创建表,关闭数据库(关闭连接),插入数据,显示数据
-
结果
gitee链接:https://gitee.com/wei-yuxuan6/myproject/blob/master/作业2/1.py
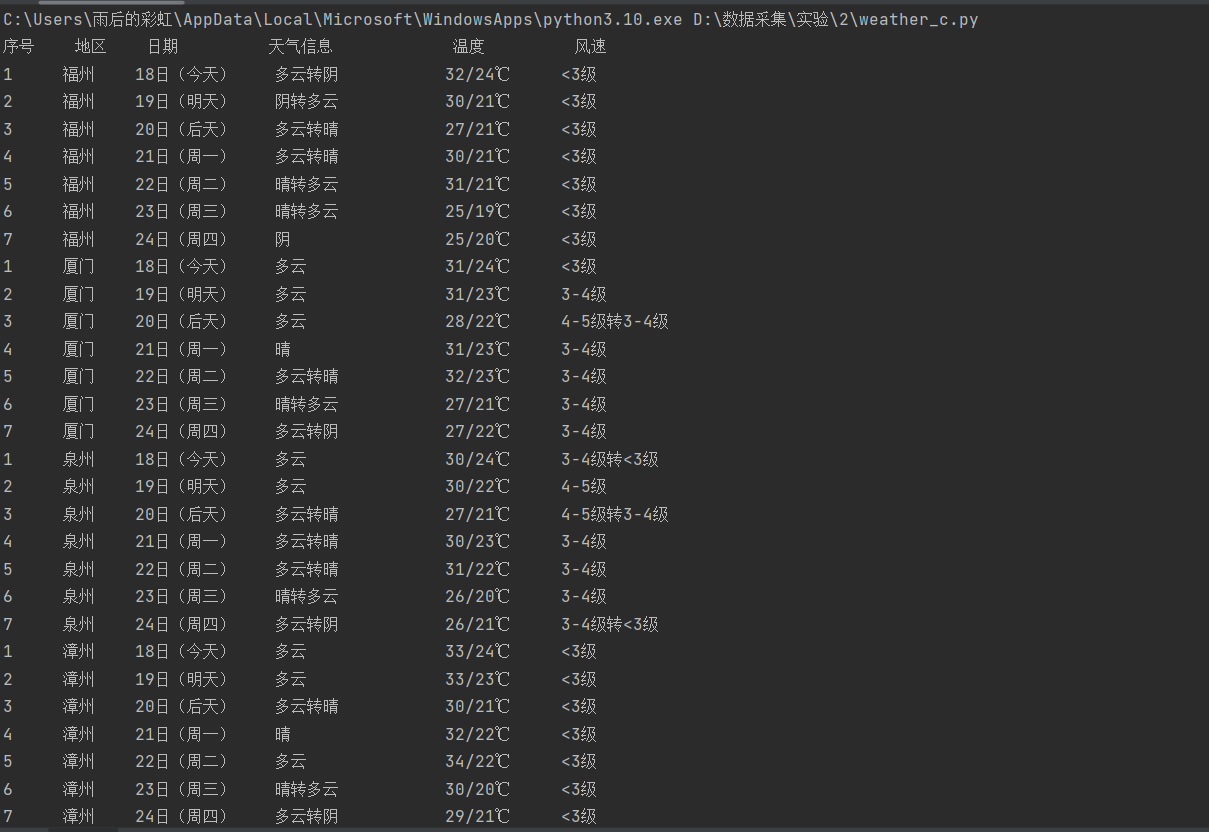
以上是直接打印的结果
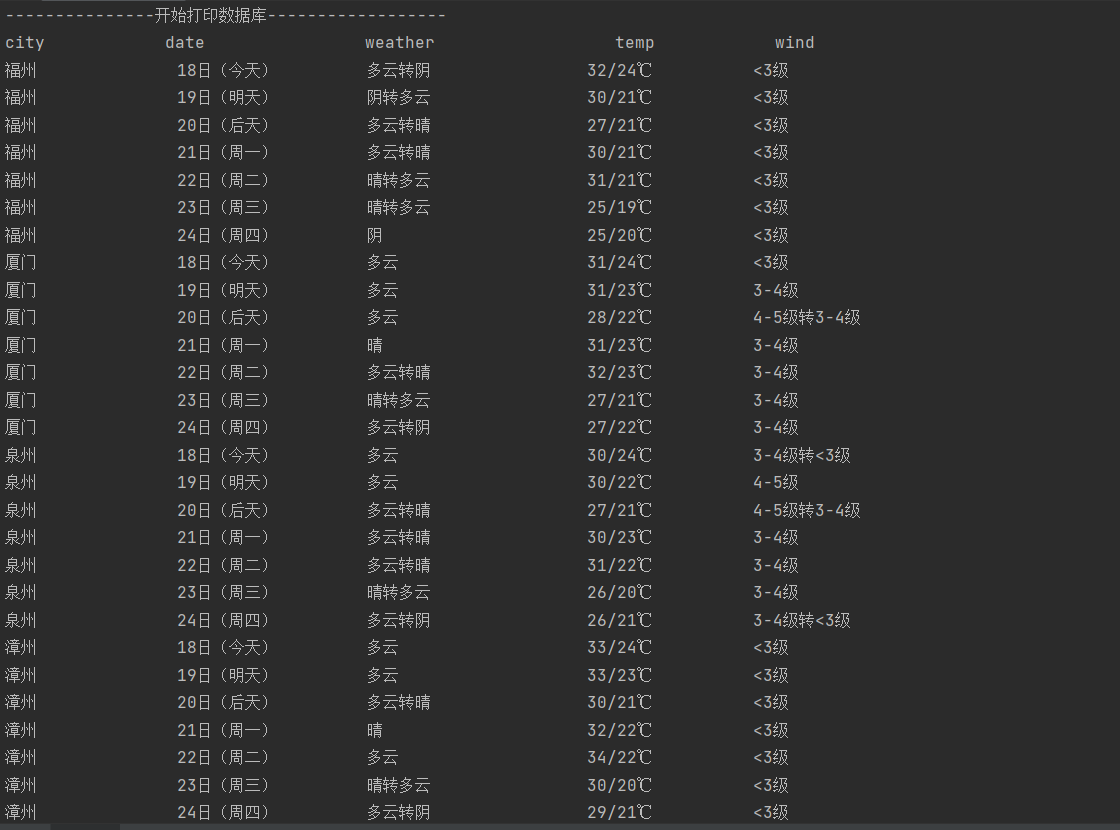
以上是数据库信息打印的结果
心得体会
本实验我主要学习到了数据库的相关操作,如何定义数据库和写数据库操作函数,以及在主程序中如何将数据写入数据库中和打印数据库信息;这段代码是在课本代码基础上的改进所以还学到了写代码时可以进行模块化设计:代码通过类和方法的组织,使得功能模块化,易于理解和维护。例如,数据库操作和网页解析被分别封装在WeatherDB和WeatherForecast类中,使得代码更具有可读性,这也是我写代码的时候需要改进的地方。
作业②
爬取股票相关信息实验
-
要求:用 requests 和 BeautifulSoup 库方法定向爬取股票相关信息,并存储在数据库中。
-
候选网站:东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/ -
技巧:在谷歌浏览器中进入 F12 调试模式进行抓包,查找股票列表加载使用的 url,并分析 api 返回的值,并根据所要求的参数可适当更改api 的请求参数。根据 URL 可观察请求的参数 f1、f2 可获取不同的数值,根据情况可删减请求的参数。
-
输出信息

-
过程
题目要求使用抓包的方式,查找股票加载时使用的URL,所以先进入要爬取的股票信息页面,按F12进入检查,选择NetWork,过滤出js,然后一一查看Preview看是否是需要的股票数据
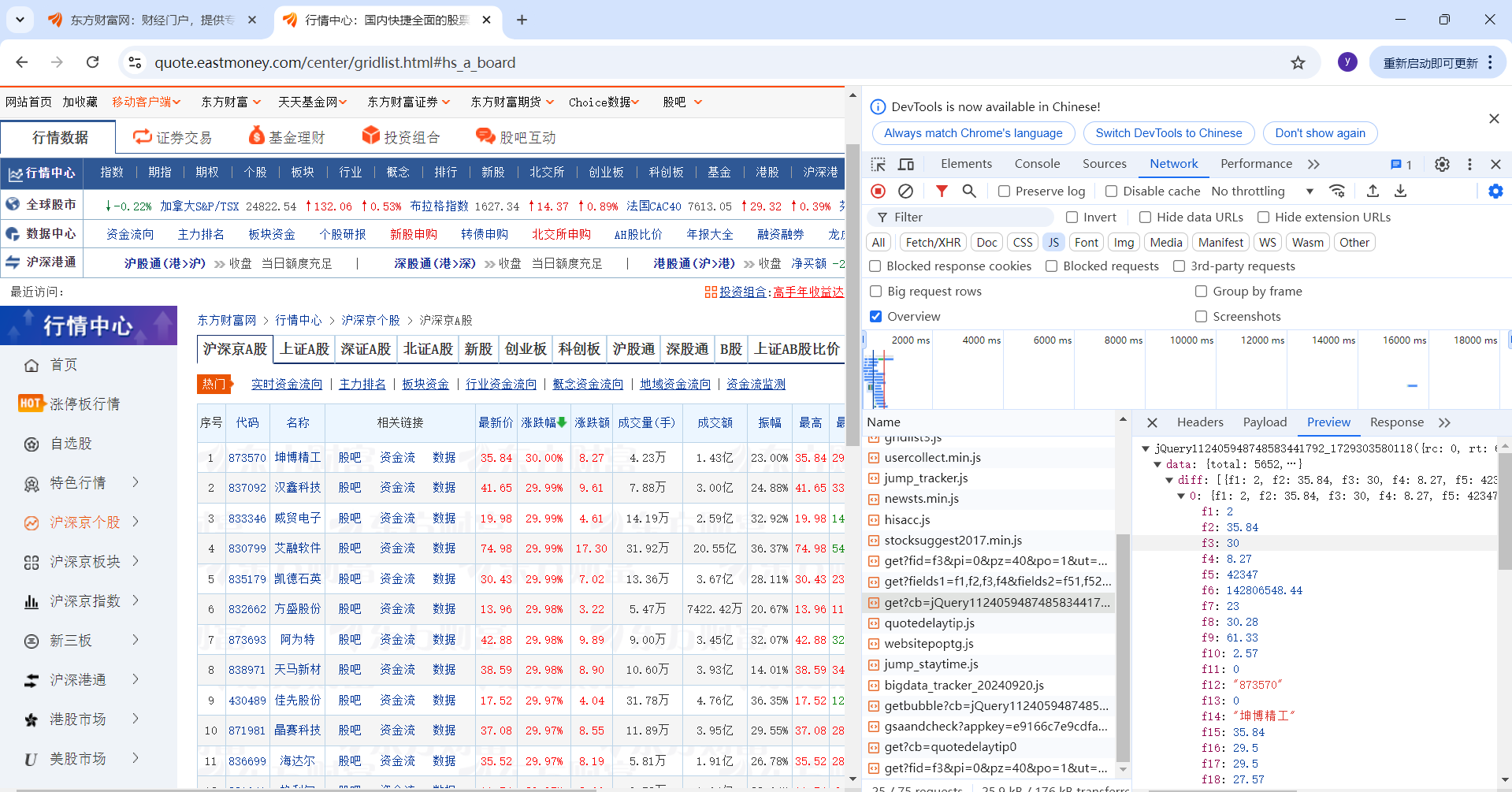
点击后出现这个页面,参数很多,数据量大,而且每一页只有20条数据
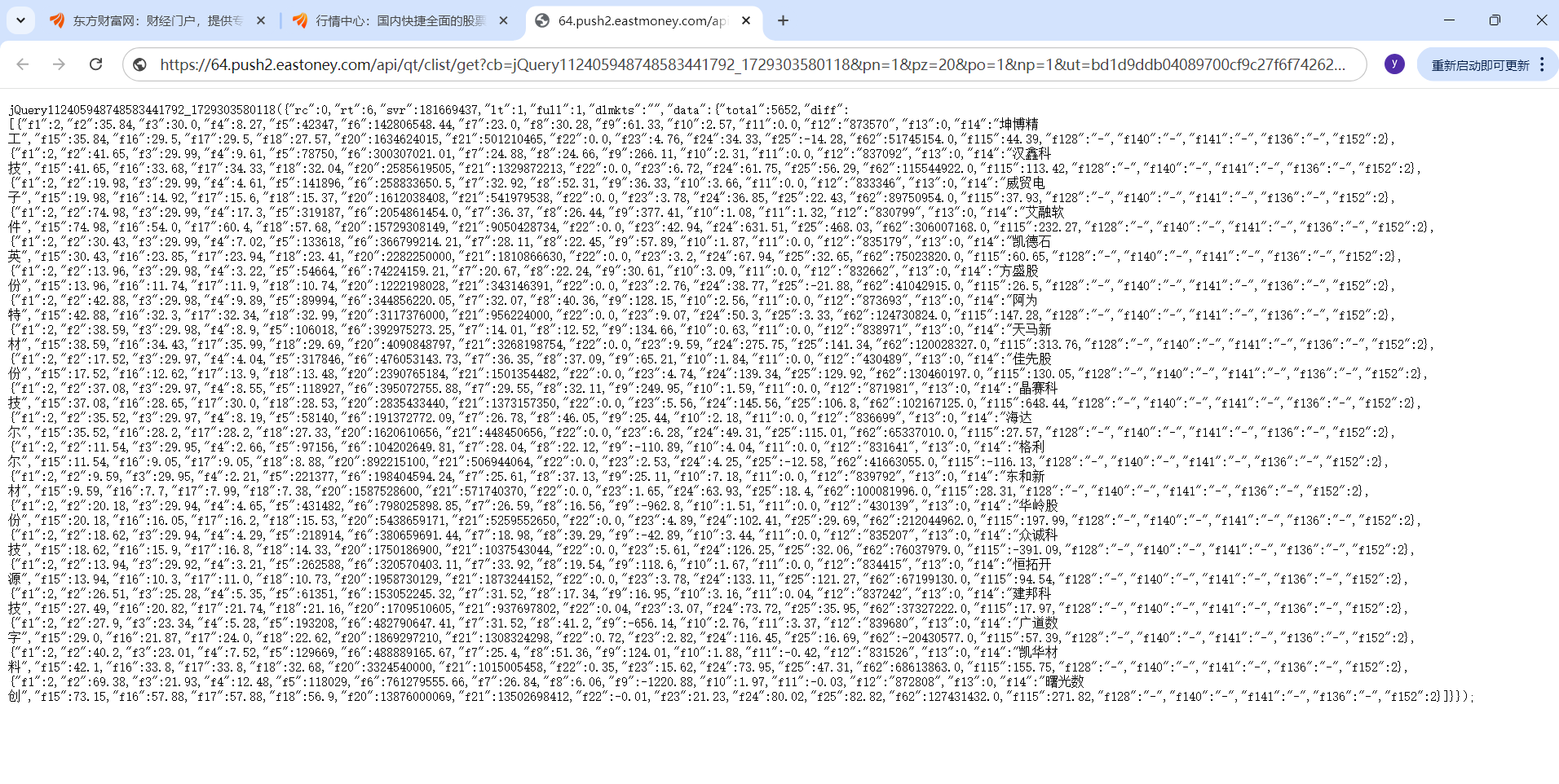
发现修改URL中field参数可以获得需要的数据,减少数据量,如:f2是最新价,f12是股票代码,f14是股票名称…… 还有就是修改pn参数可以翻页

以及不同的参数对应不同的股票
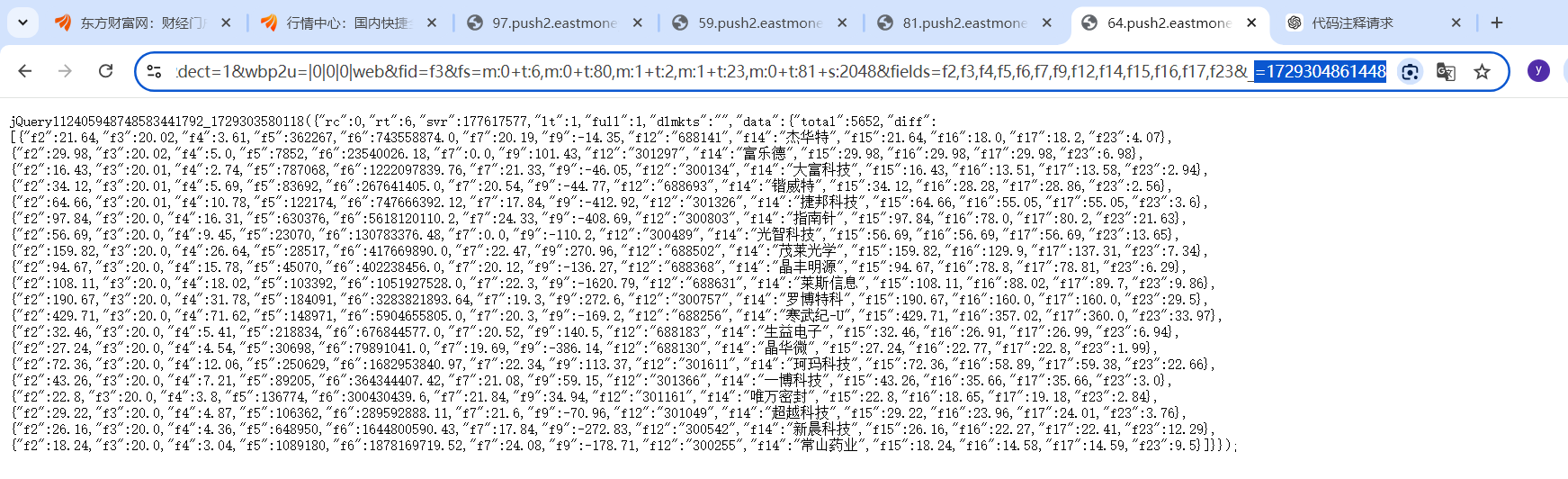
-
部分代码
# 主函数,获取用户指定数量的股票数据并保存到数据库中 def main(): name = input("请输入要获取的股票类型(沪深京A股、上证A股、深证A股、北证A股):") # 用户输入要获取的股票名称 num = input("请输入要获取的股票数:") # 用户输入要获取的股票数 page = int(num) // 20 + 1 # 计算需要抓取的页面数量,每页显示20个股票数据 i = 1 # 初始化页面计数器,表示当前抓取的页面 count = 1 # 初始化序号 stockdict = {"沪深京A股":"1729168586898","上证A股":"1729304861448","深证A股":"1729304977693","北证A股":"1729304992590"} # 存储股票数据的字典 db = StockDB() # 创建数据库操作对象 db.openDB() # 打开数据库并初始化表 # 打印表头,包含中文字段名,使用全角空格对齐 print("{:<5}{:<10}{:<10}{:<8}{:<8}{:<10}{:<10}{:<10}{:<8}{:<10}{:<8}{:<8}{:<8}{:<8}" .format("序号", "代码", "名称", "最新价", "涨跌幅", "涨跌额", "成交量", "成交额", "振幅", "最高", "最低", "今开", "市盈率", "市净率")) # 循环抓取网页数据,直到获取到指定数量的股票数据 while (1): # 无限循环,直到抓取到足够的股票数据 url = "https://77.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124018948720073959424_1729168586897&pn="+str(i)+"&pz=20" \ "&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6," \ "m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81&s:2048&fields=f2,f3,f4,f5,f6,f7,f9,f12,f14,f15,f16,f17," \ "f23&_="+stockdict[name] # 构造URL,包含股票类型和页数 respond = requests.get(url) # 发送HTTP GET请求获取数据 all = re.findall("\[.*?\]", respond.text) # 使用正则表达式提取包含股票数据的JSON数组 stocks = re.findall("{.*?}", all[0]) # 提取每一个股票的数据块 # 遍历股票数据并打印 for stock in stocks: data = json.loads(stock) # 将JSON数据转化为Python字典 data["f14"] = data["f14"].ljust(8, ' ') # 使用全角空格对齐名称字段 # 打印每个股票的信息 print("{:<5}{:<10}{:<8}{:<10}{:<10}{:<10}{:<10}{:<15}{:<10}{:<10}{:<10}{:<10}{:<10}{:<10}" .format(count, data["f12"], data["f14"], data["f2"], data["f3"], data["f4"], data["f5"], data["f6"], data["f7"], data["f15"], data["f16"], data["f17"], data["f9"], data["f23"])) # 将股票数据插入数据库 db.insert(count, data["f12"], data["f14"], data["f2"], data["f3"], data["f4"], data["f5"], data["f6"], data["f7"], data["f15"], data["f16"], data["f17"], data["f9"], data["f23"]) if count == int(num): # 如果已经获取到指定数量的股票数据,则退出循环 break count += 1 # 序号递增 if i == page: # 如果已经抓取到所有需要的页面,则退出循环 break i += 1 # 页数递增 print("-----------------开始输出数据库数据-----------------") db.show() # 输出数据库中的股票数据 print("-----------------数据库数据输出完毕-----------------") db.closeDB() # 关闭数据库连接以上是主函数,首先构造URL(包括fields参数,页面和股票类型),查看抓包后的数据发现每个股票信息都包含在{}中,而且是json类型的,所以先使用正则表达式匹配到每个股票信息再使用json.loads将json数据转化为字典,就可以直接通过键值对访问需要的字段了,如data["f14"]是股票名称,如果一页爬完还不能达到需要爬取的股票数要求就会翻页(在while循环中)
数据库操作与作业1类似这里就不放代码了 -
结果
gitee链接:https://gitee.com/wei-yuxuan6/myproject/blob/master/作业2/2.py
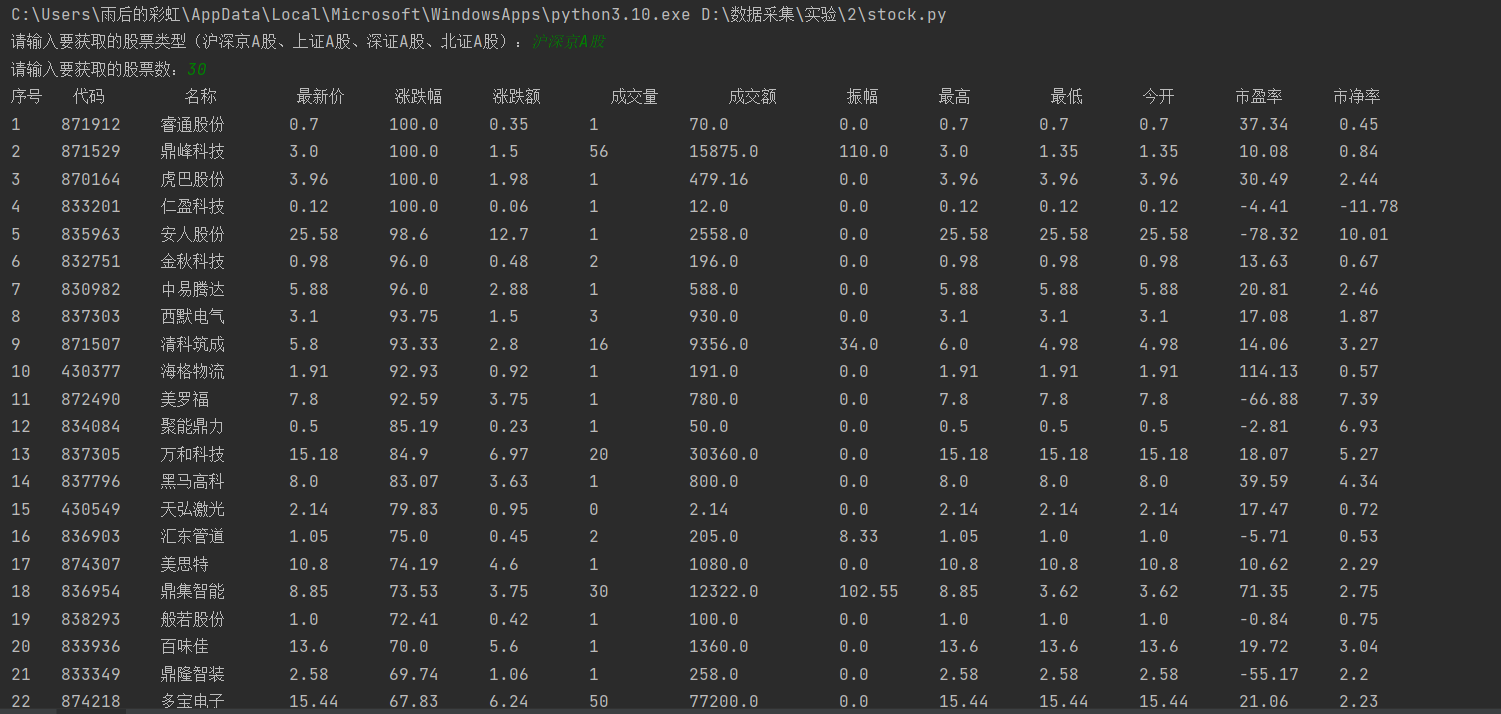
以上是直接输出结果
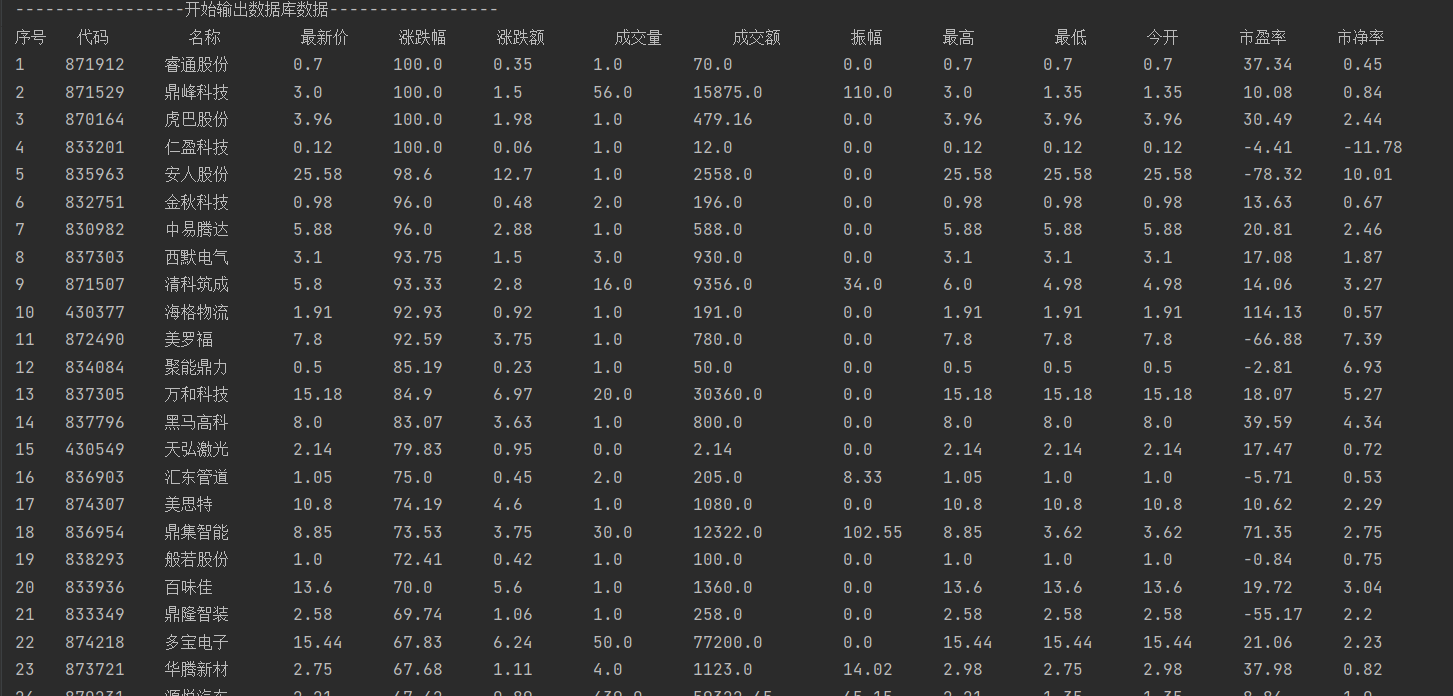
以上是数据库输出结果
心得体会
这个实验首次接触到了抓包,抓包即通过网络分析工具获取HTTP请求与响应的过程。通过分析API接口,获取了股票信息的URL,并找到了需要的参数和数据格式。学会了使用浏览器的开发者工具抓取API请求,并找出其中的关键字段。了解接口的请求方式、参数含义以及返回的JSON格式,能够高效地抓取所需的股票数据。
在抓取网页API接口时,学会了如何通过参数化控制抓取数据的数量和页数。url中的参数pn和pz分别代表页数和每页显示的股票数量(pz是后面才发现的)。通过计算页数,我能够根据用户输入的股票数来动态调整页面抓取,避免了手动干预抓取过程。这种方式让我体会到了网络抓包的灵活性和动态处理能力。
作业③
使用抓包爬取中国大学 2021 主榜实验
-
要求:爬取中国大学 2021 主榜
(https://www.shanghairanking.cn/rankings/bcur/2021) 所有院校信息,并存储在数据库中,同时将浏览器 F12 调试分析的过程录制 Gif 加入至博客中。 -
技巧:分析该网站的发包情况,分析获取数据的 api
-
输出信息:
排名 学校 省市 类型 总分 1 清华大学 北京 综合 969.2 -
过程
还是使用作业2的抓包方式,gif如下

得到如下数据,分析数据,这里使用了正则表达式匹配所需字段,先提取出所有学校信息(在univaData和indList之间),再找到所有学校名字(在univNameCn之后)findall返回所有学校名字列表,同样方式得到学校省份和类别列表

但是发现学校省份和类别都以字母形式呈现,最后在js的开头和结尾找到了字母与省份和类别的对应,所以定义了两个字典存储它们的映射关系
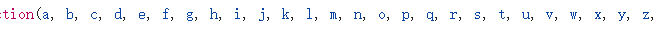

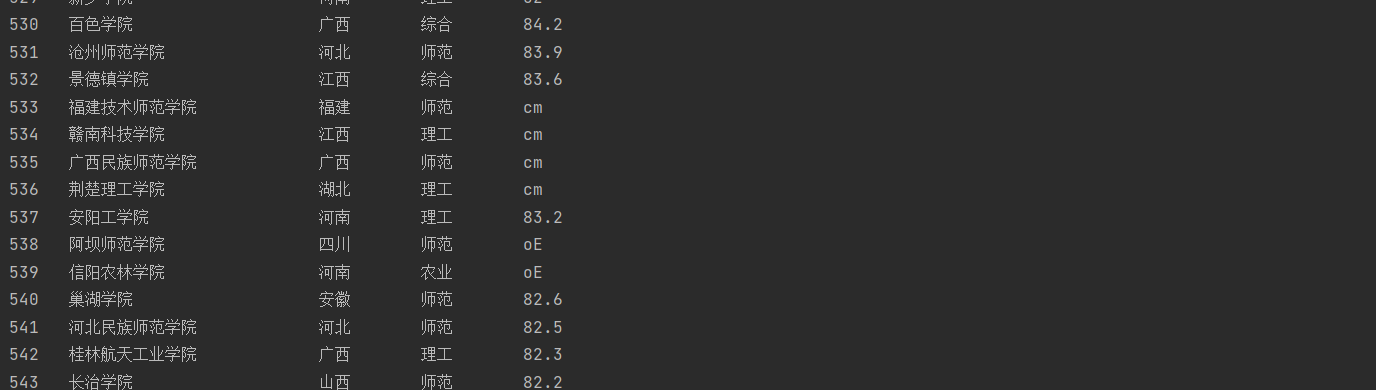
但是运行后发现有的总分也是需要通过映射才能得到实际总分,因为映射比较多不好找,所以目前没有找到更好的解决方法
-
部分代码
# 定义省份的字典,将编码映射为具体的省份名称 provincedict = { 'k': '江苏', 'n': '山东', 'o': '河南', 'p': '河北', 'q': '北京', 'r': '辽宁', 's': '陕西', 't': '四川', 'u': '广东', 'v': '湖北', 'w': '湖南', 'x': '浙江', 'y': '安徽', 'z': '江西', 'A': '黑龙江', 'B': '吉林', 'C': '上海', 'D': '福建', 'E': '山西', 'F': '云南', 'G': '广西', 'I': '贵州', 'J': '甘肃', 'K': '内蒙古', 'L': '重庆', 'M': '天津', 'N': '新疆', 'Y': '海南', 'aD': '宁夏', 'aE': '青海', 'aF': '西藏' } # 定义学校类型的字典,将编码映射为具体的学校类型 categorydict = {'e': '理工', 'f': '综合', 'h': '师范', 'm': '农业', 'T': '林业'} # 定义存储省份和学校类型的列表 provincelist = [] categorylist = [] # 创建数据库对象并打开数据库连接 db = SchoolsDB() db.openDB() # 抓取网页数据 url = "https://www.shanghairanking.cn/_nuxt/static/1728872418/rankings/bcur/2021/payload.js" response = requests.get(url) # 发送 GET 请求获取网页数据 # 解析抓取的数据 data = response.text univData = re.findall(r'univData:(.*?),indList', data) # 匹配所有高校数据部分 # 从数据中提取学校名称 univName = re.findall(r"univNameCn:\"(.*?)\"", univData[0]) # 提取省份编码,并使用 provincelist 映射为省份名称 province = re.findall(r"province:(.*?),", univData[0]) for i in province: provincelist.append(provincedict[i]) # 根据编码从字典中获取省份名称 # 提取学校类型编码,并使用 categorylist 映射为学校类型 univCategory = re.findall(r"univCategory:(.*?),", univData[0]) for i in univCategory: categorylist.append(categorydict[i]) # 根据编码从字典中获取学校类型 # 提取学校的总分 score = re.findall(r"score:(.*?),", univData[0]) # 打印表头 print("{:<5} {:<21}{:<8} {:<8} {:<6}".format("排名", "学校名称", "省份", "学校类型", "总分")) # 遍历所有提取到的学校信息并插入数据库 for i in range(len(univName)): univName[i] = univName[i].ljust(15, ' ') # 使用全角空格对齐学校名称 # 插入学校信息到数据库 db.insert(i + 1, univName[i], provincelist[i], categorylist[i], score[i]) # 打印当前学校的排名、名称、省份、类型、总分 print("{:<5} {:<15} {:<8} {:<8} {:<6}".format(i + 1, univName[i],provincelist[i], categorylist[i], score[i]))
在得到学校省份和类型列表后在一一对它们进行映射,转化成实际省份和类型,存放到新的列表中
数据库部分代码与上面基本一致
- 部分结果
gitee链接:https://gitee.com/wei-yuxuan6/myproject/blob/master/作业2/3.py
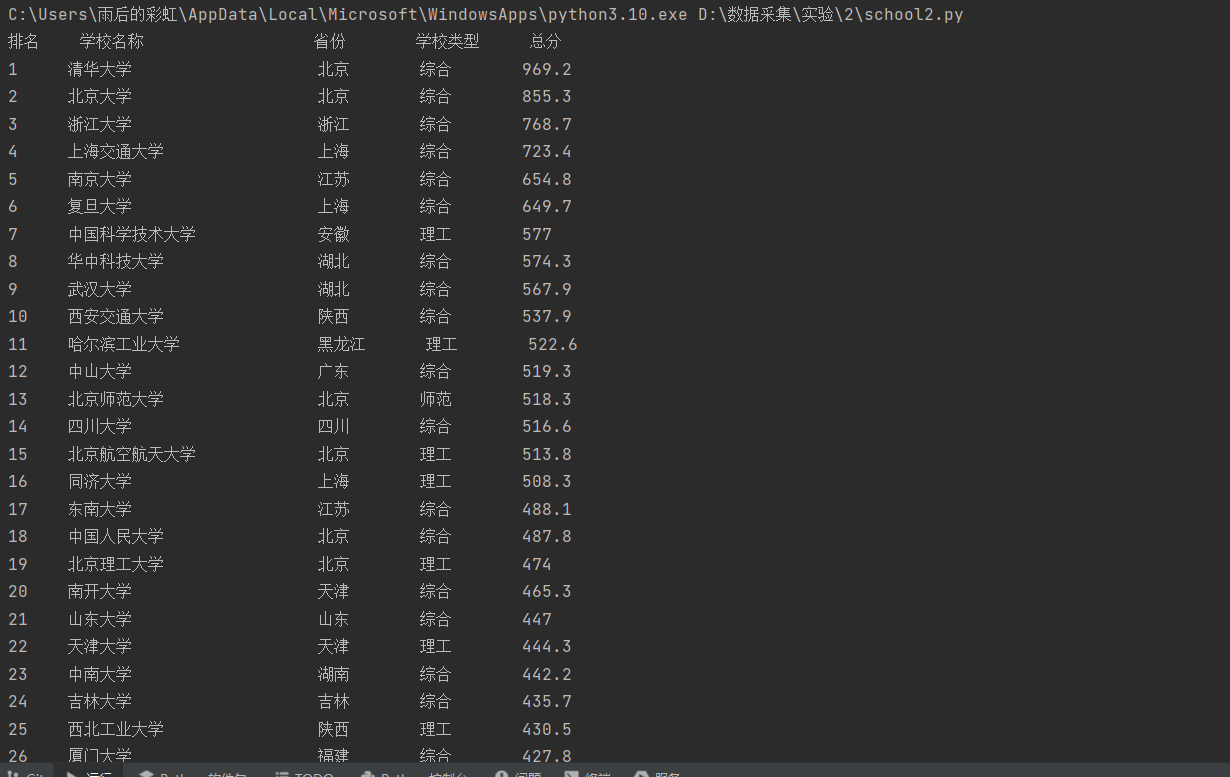
以上为直接输出结果
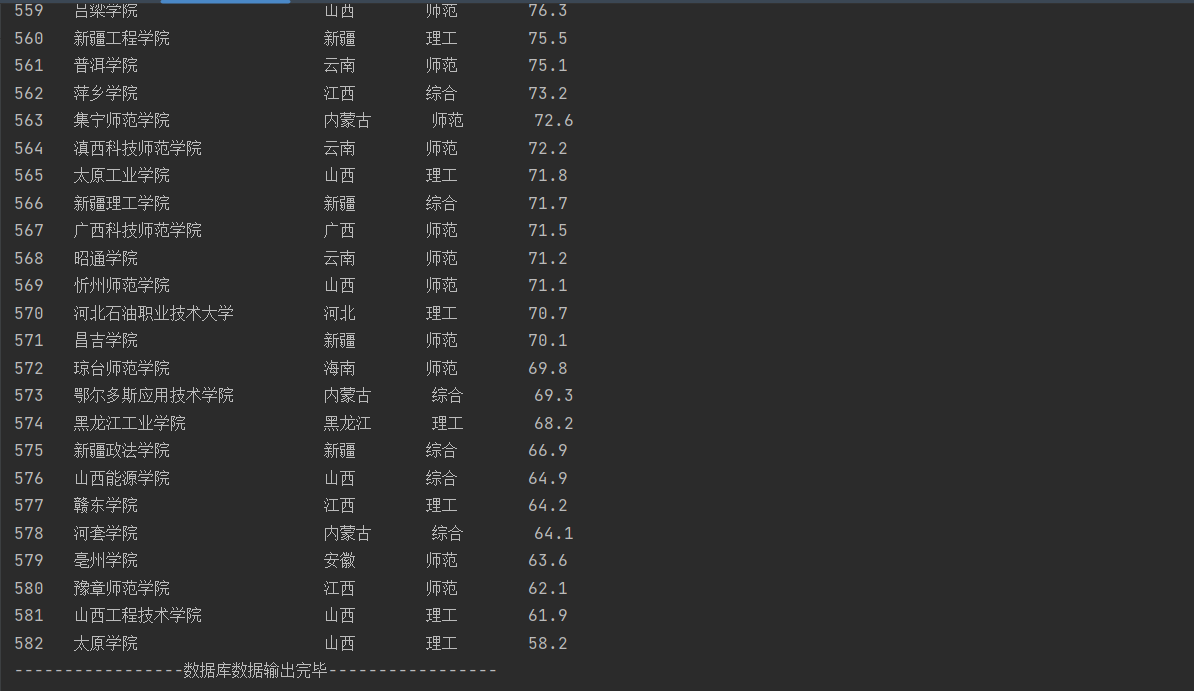
以上为数据库输出结果
心得体会
本次作业最大的收获是学习到了正则表达式的捕获组,如正则表达式r"province:(.?),"先匹配字符串中的 province:,(.?):是一个非贪婪模式的捕获组,表示匹配尽可能少的任意字符,直到遇到逗号 , 为止。() 括号用于捕获匹配到的内容,也就是说这里捕获的内容将被保存下来,这段正则表达式将会提取 univData: 和 , 之间的内容,并返回匹配到的内容。而r"province:.*?,"这个表达式会保存匹配到的字段包括province:和,就是不能提取需要的内容,它的作用是匹配。
