数据采集与融合技术实践作业一
数据采集与融合技术实践作业一
gitee链接:https://gitee.com/wei-yuxuan6/myproject/tree/master/作业1
作业①
爬取大学排名信息实验
- 要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
- 输出信息:
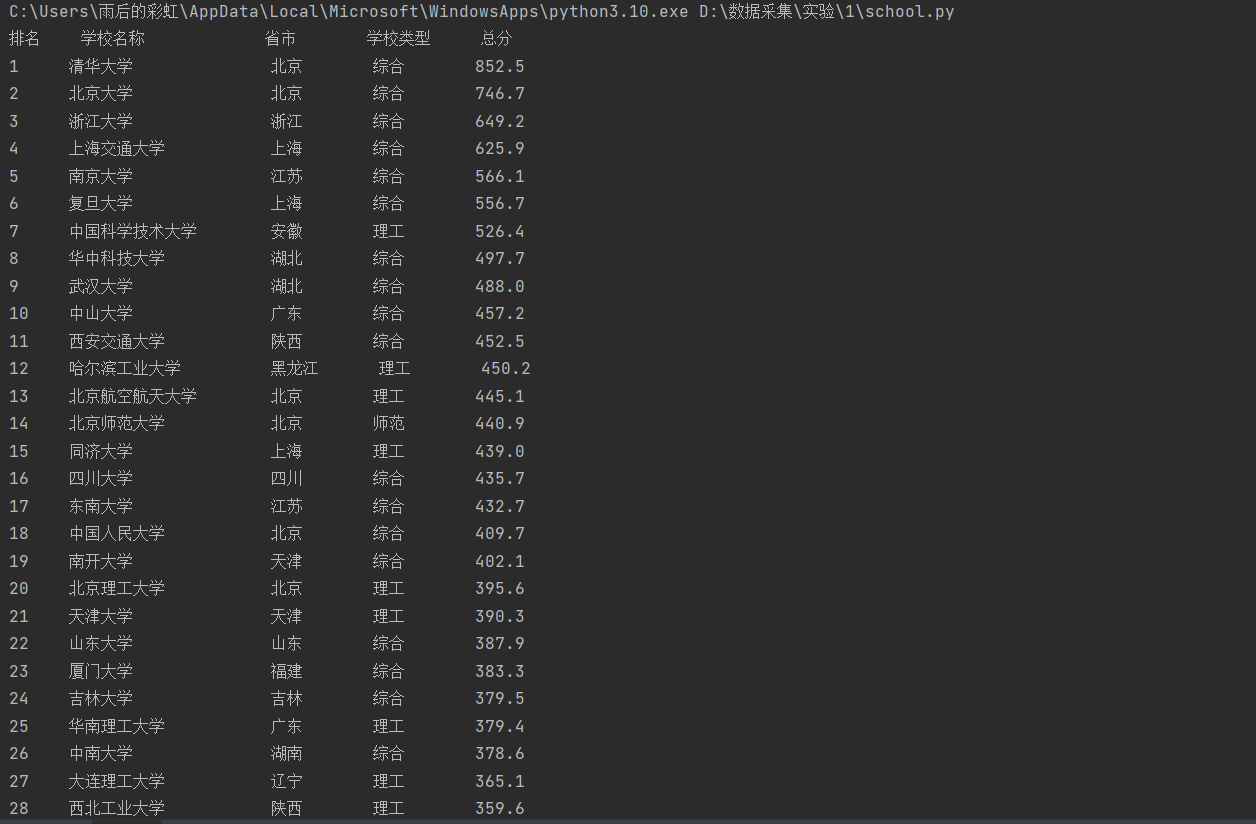
| 排名 | 学校名称 | 省市 | 学校类型 | 总分 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 852.5 |
| 2...... |
-
过程
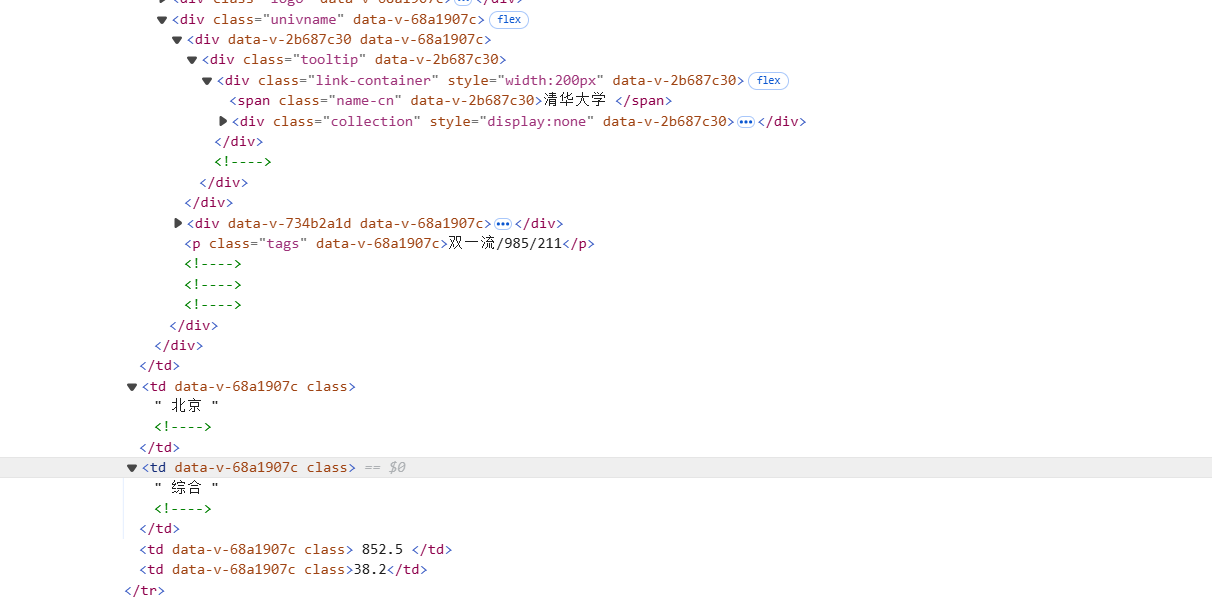
首先打开给定网址,使用F12查看页面源代码
发现所有的学校信息都包含在tbody标签中,每一条学校信息都包含在tr标签中

更进一步发现在每一条学校信息中,学校名称包含在class为'univname'的div下的class为'name-cn'的span标签中
查找其他信息,包括排名、省市、学校类型和总分,发现信息在td标签中
所以可以先找出所有的td标签,再通过访问列表索引的形式获取信息
-
部分代码
# 定义要抓取数据的URL,目标是上海软科发布的2020年中国大学排名页面
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
# 发送HTTP请求,并获取响应内容
response = requests.get(url)
# 设置响应内容的编码格式为UTF-8,确保中文字符显示正确
response.encoding = 'utf-8'
使用requests.get方法发送请求,获取响应后设置编码格式UTF-8,之后就可以使用response.text获取响应文本
# 使用BeautifulSoup解析响应的HTML内容,"lxml"为解析器类型
soup = BeautifulSoup(response.text, "lxml")
# 查找包含学校排名数据的表格主体
table = soup.find('tbody')
# 查找表格中的所有行(即每所学校的排名信息)
rows = table.find_all('tr')
# 打印表格的标题行,表示排名、学校名称、省市、学校类型、总分
print("{:<5} {:<15} {:<8} {:<8} {:<6}".format("排名", "学校名称", "省市", "学校类型", "总分"))
# 遍历每一行数据,并提取出学校排名和信息
for row in rows:
# 查找学校名称,包含在class为'univname'的div下的class为'name-cn'的span标签中
school = row.select("div[class='univname'] span[class='name-cn']")
# 提取学校名称,并去除前后空白字符
school = school[0].text.strip()
# 查找其他信息,包括排名、省市、学校类型和总分,信息在<td>标签中
info = row.select("td")
# 提取排名信息并去除空白字符
rank = info[0].text.strip()
# 提取学校所在的省市信息并去除空白字符
province = info[2].text.strip()
# 提取学校类型(如综合类、理工类等)并去除空白字符
typ = info[3].text.strip()
# 提取学校的总分信息并去除空白字符
score = info[4].text.strip()
# 格式化输出,每个字段设定固定宽度,方便对齐
# 对学校名称进行宽度控制,确保对齐
school_name = school.ljust(12, ' ') # 使用全角空格对齐
print("{:<5} {:<12} {:<8} {:<8} {:<6}".format(rank, school_name, province, typ, score))
这里使用了BeautifulSoup的find、find_all、CSS选择器结合的方法,查找其他信息时使用CSS选择器找出所有td标签,返回列表,排名字段在第一个td标签中,省市字段在第三个td标签中……
值得注意的是提取出来的文本都带有空白字符,所以需要使用.strip()方法进一步处理
刚开始尝试了几次输出发现输出内容不整齐,主要是学校与省市之间因为学校字段长度不同,是因为中文后面使用半角空格填充,所以学校字段长度不同填充后的长度也不同,所以使用全角空格将学校字段填充到12个字符
心得体会
复习了使用BeautifulSoup的find、find_all、CSS选择器查找HTML文档元素,还学会了如何对结果格式化输出(使用format和对中文的全角空格填充),主要是要查找HTML文档中各个元素的规律,定位到需要元素所在位置
作业②
商品比价定向爬虫实验
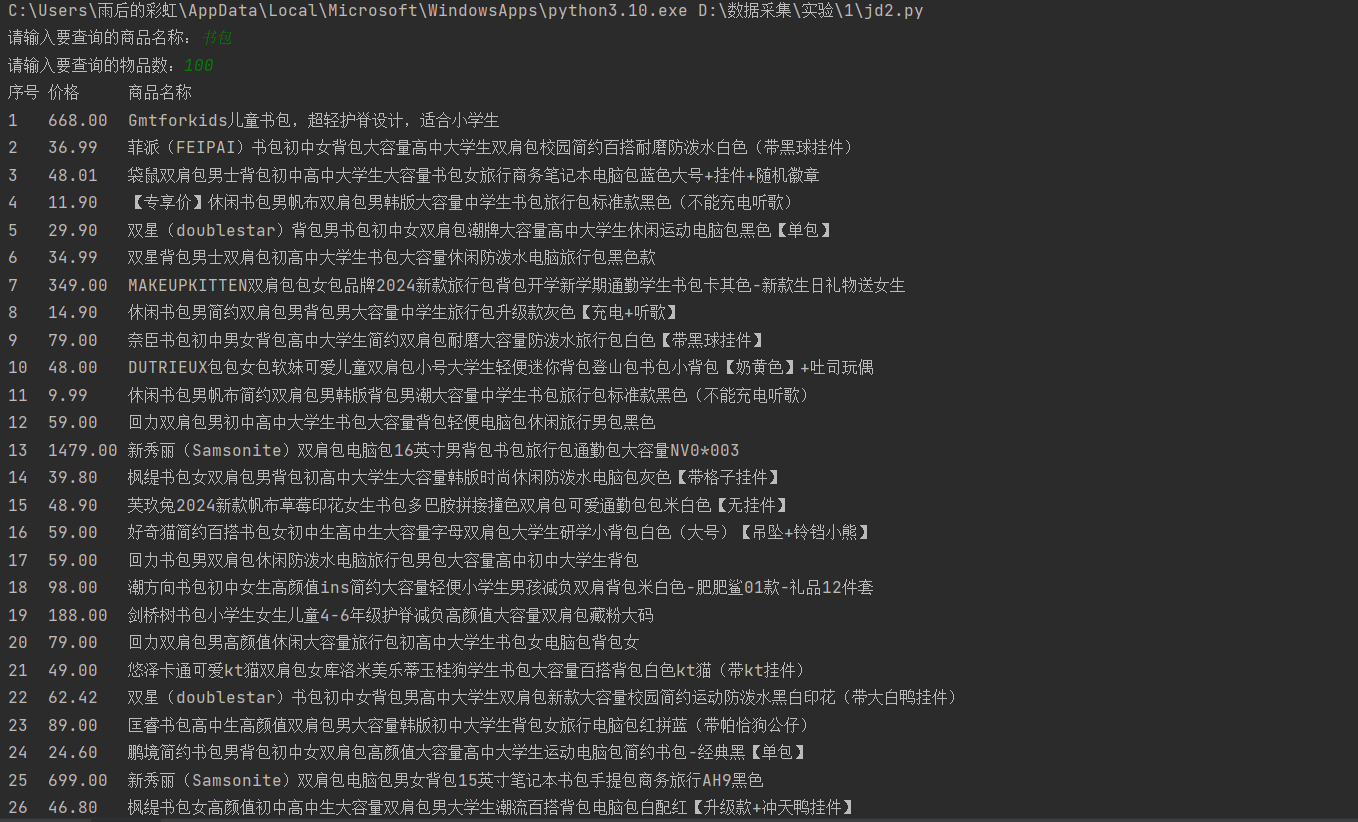
- 要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
- 输出信息:
| 序号 | 价格 | 商品名 |
|---|---|---|
| 1 | 65.00 | xxx |
| 2...... |
-
过程
这里爬取的是京东的商品数据
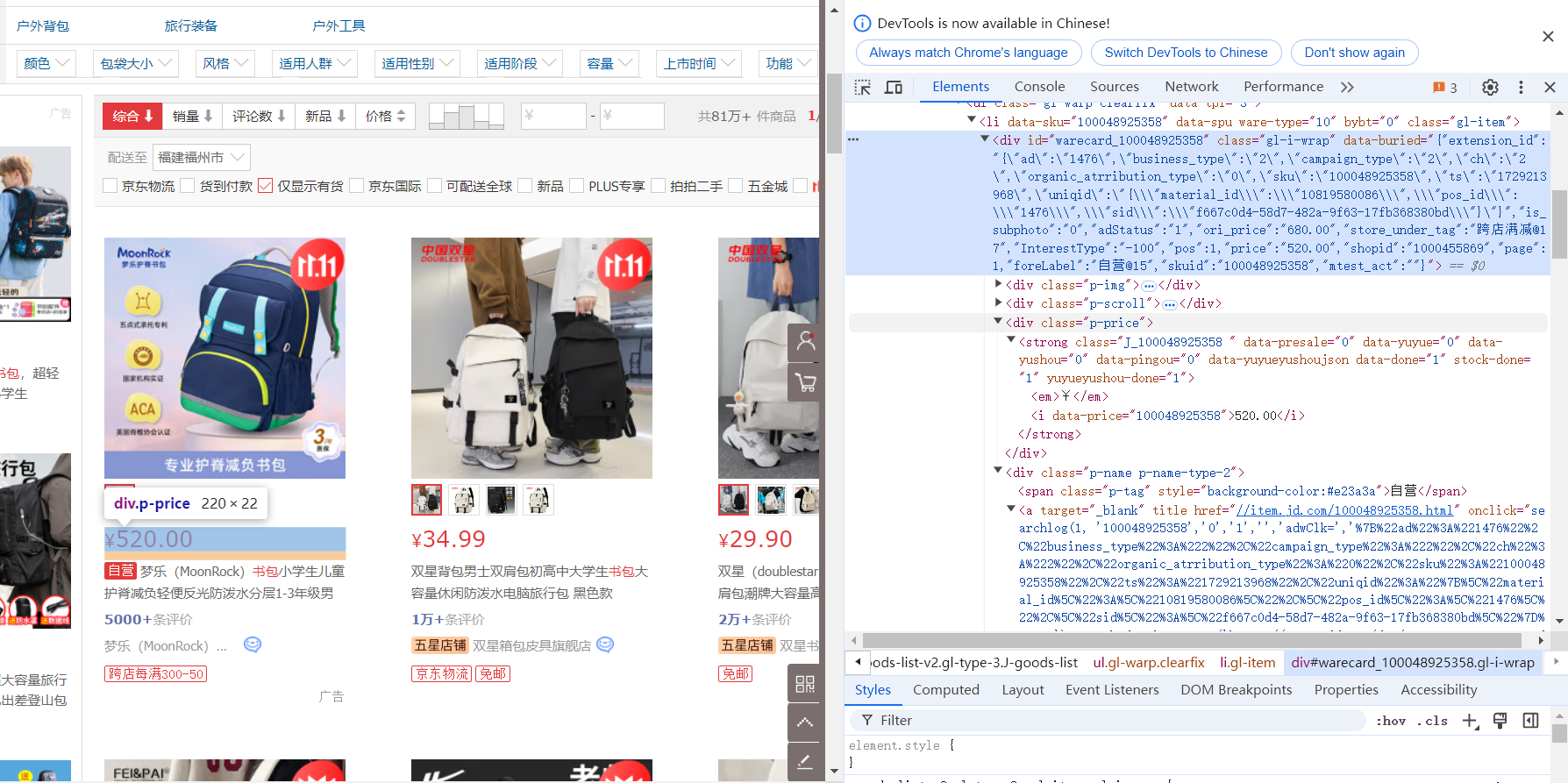
首先打开京东搜索“书包”,查看源代码并分析
发现每个商品都包含在li元素中,价格在class为"p-price"的div元素中,名字在class为"p-name p-name-type-2"的div下的em元素中
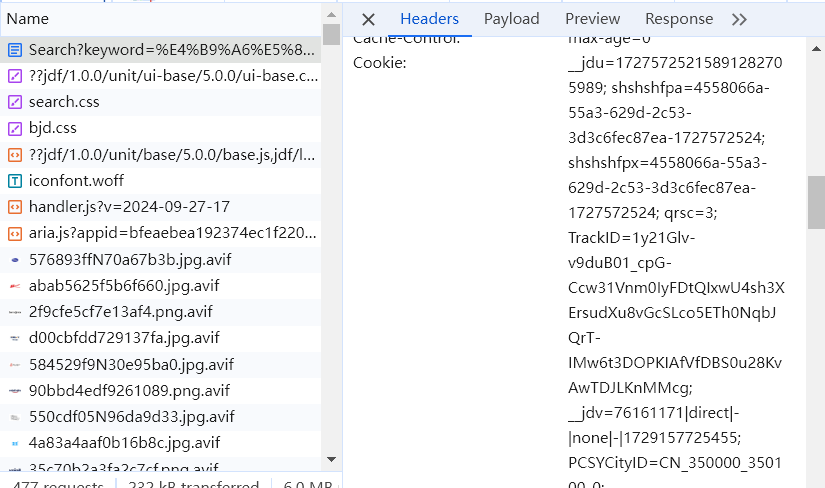
同时想要访问京东必须在请求中添加请求头(包括User-Agent和Cookie)
在Network中找到Search?开头的,点击Headers就可以找到对应的参数
-
部分代码
while (1): # 开始循环抓取网页数据,直到获取到指定数量的商品
# 构造URL,包含查询的商品名称和页数,使用 urllib.parse.quote 进行 URL 编码
url = "https://search.jd.com/Search?keyword=" + urllib.parse.quote(q) + \
"&qrst=1&wq=" + urllib.parse.quote(q) + "&stock=1&pvid=5977ce2bd05f4ea5ad2f9f78c0b1787b&isList=0&page=" \
+ str(i) + "&s=56&click=0&log_id=1729158516273.3620"
response = requests.get(url, headers=headers) # 发送请求,获取响应内容
response.encoding = 'utf-8' # 设置响应内容的编码格式为UTF-8,确保中文显示正常
首先构造URL,并使用requests.get发送请求,这里还使用了 urllib.parse.quote 进行 URL 编码,可以爬取不同商品(但是不同页面源代码不同,不一定能爬取到),还进行了翻页处理,每一页只有30个商品,想要爬取更多就需要翻页,通过查找URL的规律,页数在page=中体现
# 匹配价格信息,价格信息包含在 <i> 标签中
reg1 = r"<i data-price=[^>]*>.*?</i>"
# 匹配价格的具体数值,格式为“数字.数字”,如 "123.45"
reg2 = r"[0-9]+[.]+[0-9]+"
# 匹配商品名称信息,商品名称包含在 <div class="p-name p-name-type-2"> 标签中
reg3 = r"<div class=\"p-name p-name-type-2\">.*?</div>"
# 在每个商品名称信息中匹配商品名称,商品名称包含在 <em> 标签中,但不能以“¥”开头
reg4 = r"<em>[^¥].*?</em>"
# 匹配HTML标签,用于去除商品名称中的HTML标签
reg5 = r"<[^>]*>"
# 使用 re.findall 查找所有价格标签
pricetags = re.findall(reg1, response.text, re.S)
for pricetag in pricetags:
# 从每个价格标签中提取出价格数值
pricel = re.findall(reg2, pricetag)
price = pricel[0] # 获取第一个匹配的价格
pricelist.append(price) # 将价格添加到价格列表中
# 使用 re.findall 查找所有商品名称标签
nametags = re.findall(reg3, response.text, re.S)
for nametag in nametags:
# 去除HTML标签中的空格,避免空格影响后续处理
nametag = re.sub(r"\s+", '', nametag)
# 从商品名称中提取出实际的名称,并去除HTML标签
names = re.findall(reg4, nametag)
name = re.sub(reg5, '', names[0]) # 去除 HTML 标签,获取商品名称
namelist.append(name) # 将商品名称添加到名称列表中
# 如果已经获取到用户指定数量的商品,就跳出循环
if count == int(num):
break
count += 1 # 计数器加1,表示已经处理了一个商品
i += 1 # 页面计数器加1,开始抓取下一页
if i > page: # 如果已经抓取到用户指定的页面数量,就跳出循环
break
time.sleep(1) # 暂停1秒,防止请求过于频繁,避免被服务器封禁
这里使用了正则表达式查找需要的元素
刚开始想要使用通过匹配li元素获得每个商品的信息,但是发现在每个商品中也有li元素,导致匹配错误,所以选择直接匹配价格信息,价格信息包含在i标签中有属性data-price,还要在找到的标签中匹配价格的具体数值,因为findall方法返回的是列表,所以可以直接通过索引使用如pricel[0](只有一个)
后面还直接匹配了商品名称信息,但是发现在商品名称信息中还有HTML标签以及尝试提取出的信息和有的标签之间有空格,所以使用了re.sub方法,找到所有HTML标签和空格都替换成空字符
比如以下标签

同时还记录了商品的个数,及页数便于翻页处理
因为不能直接输出结果(查找价格和名称在两个不同循环中),所以定义了两个列表分别存储价格和商品名称,最后格式化输出
心得体会
本次实验主要复习了正则表达式的使用,学会了使用正则表达式查找指定字符并替换,还有翻页处理,通过找到不同页URL的规律改变URL参数进行翻页。但是感觉自己对正则表达式的使用不太熟练,需要修改多次、进行多次调试才写出正确的正则表达式(所以将爬取到的HTML文件保存到本地,测试通过之后再访问网站),还需要进一步练习。
作业③
爬取网页图片实验
-
要求:爬取一个给定网页( https://news.fzu.edu.cn/yxfd.htm) 或者自选网页的所有JPEG和JPG格式文件
-
输出信息:将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
-
过程
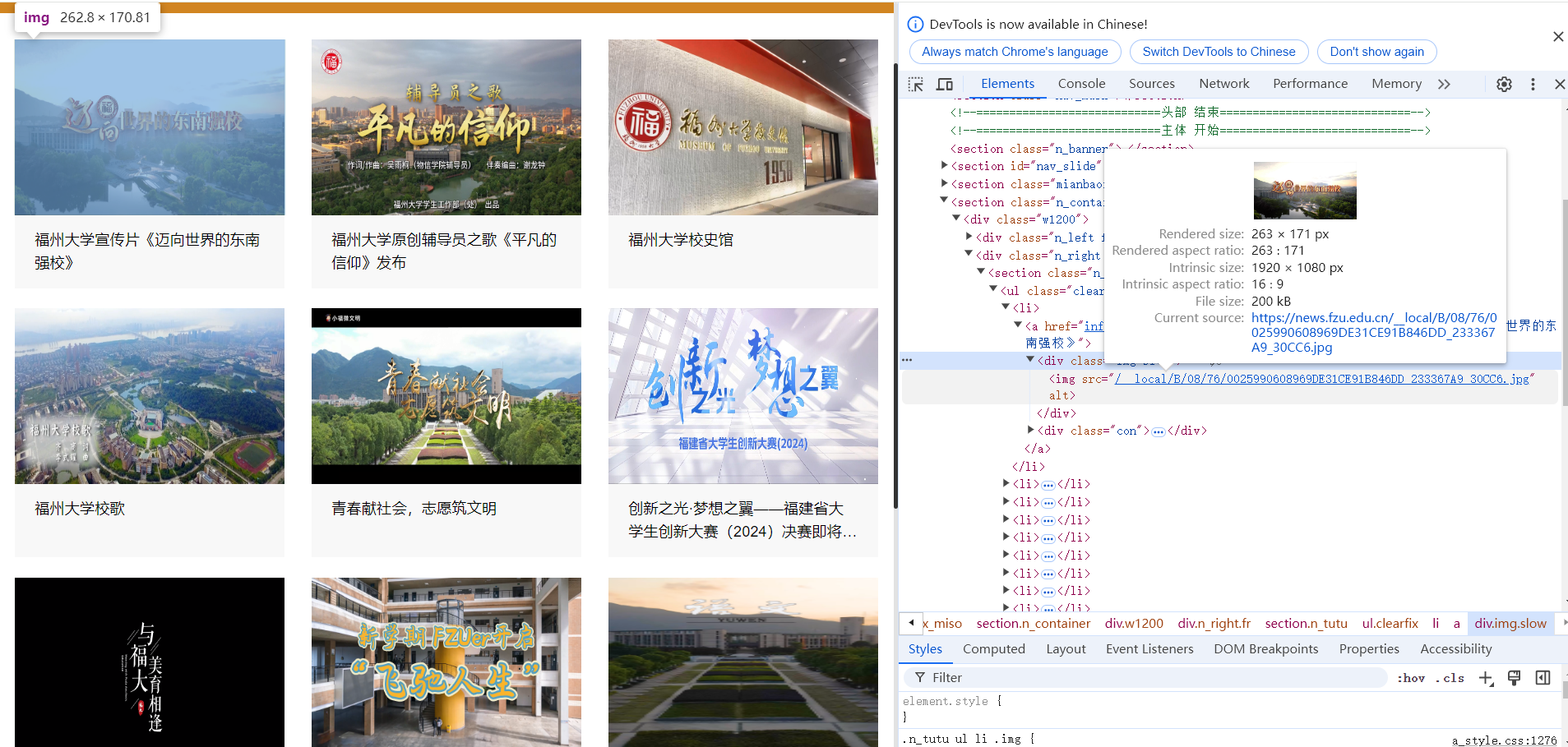
打开网页,分析页面源代码,该页面结构清晰
每个新闻在li元素中,图片连接在li下class='img slow'的div元素下的img的src属性中
所以选择使用BeautifulSoup的CSS选择器比较方便
但是在访问的时候要在获得的链接前加上"https://news.fzu.edu.cn"
-
部分代码
# 设置要爬取的网页地址
url = "https://news.fzu.edu.cn/yxfd.htm"
# 创建请求对象,用于向目标网页发送请求
req = urllib.request.Request(url)
# 打开URL并获取响应
response = urllib.request.urlopen(req)
# 读取响应内容并将其解码为 UTF-8 编码格式的文本
html = response.read().decode('utf-8')
# 使用BeautifulSoup解析网页内容,解析器使用'lxml'
soup = BeautifulSoup(html, "lxml")
这里使用了urllib.request发送请求,因为urllib.request提供了urllib.request.urlretrieve方法,后续可以直接将访问到的图片保存到本地
# 选择所有匹配的图像元素,图像元素包含在 <li> 标签下,class 属性为 'img slow'
items = soup.select("li div[class='img slow'] img")
# 初始化计数器,记录下载的图片数量
count = 1
filedir="D:/数据采集/实验/1/picture2/"
os.makedirs(filedir, exist_ok=True)
# 循环遍历匹配到的所有图像元素
for item in items:
# 检查图片的src属性是否以 .jpg 或 .jpeg 结尾,判断是否为目标图片格式
if item['src'].endswith(".jpg") or item['src'].endswith(".jpeg"):
# 拼接完整的图片URL,"https://news.fzu.edu.cn" 是图片的基础地址
image_url = "https://news.fzu.edu.cn" + item['src']
# 下载图片,并保存到指定的文件夹,文件名使用当前计数器的值
urllib.request.urlretrieve(image_url, filedir + str(count) + ".jpg")
# 打印下载进度信息,包含图片编号和图片URL
print("正在下载第" + str(count) + "张图片, 地址为:" + image_url)
# 下载完成后计数器加1
count += 1
这里使用os.mkdirs创建文件夹
然后是匹配过程,还有因为题目要求爬取所有的jpg和jpeg文件,所以对获得的图片连接进行检查是否以.jpg和.jpeg结尾
然后拼接完整的图片URL并访问
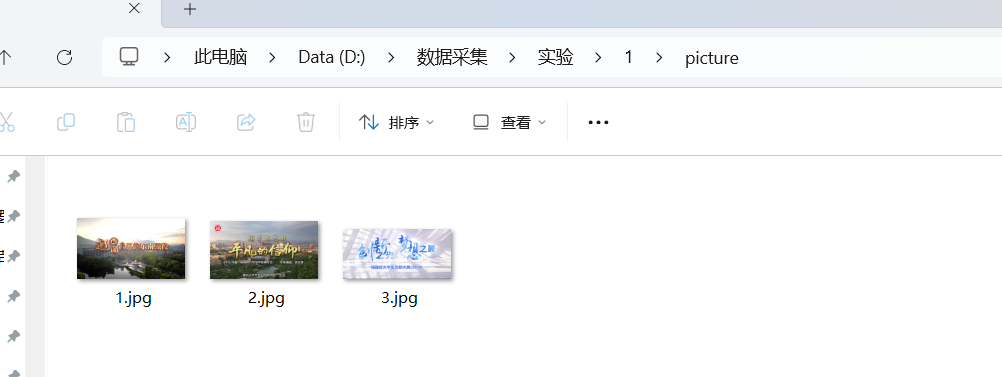
- 结果
gitee链接:https://gitee.com/wei-yuxuan6/myproject/tree/master/作业1/3

页面中一共只有3个jpg文件,没有jpeg文件
心得体会
本实验复习了在访问初始URL时获取新的URL并访问的过程,就是再次对新的URL发出请求的过程,同样使用urllib.request,与请求初始URL时相同,后续如果爬取的图片较多的话可以使用多线程提高爬取速度。
