
MySQL Shell 使用指南
前言:
MySQL Shell 是官方提供的 MySQL 周边适配组件,是新一代的高级客户端,在 MySQL 8.0 及其以后的版本得以慢慢推广应用。之前笔者因为 MySQL 8.0 用得比较少,一直没有详细使用过这个工具,近期在捣鼓 MySQL 8.0,趁此机会,一起来学习下吧。
1.MySQL Shell 介绍与安装使用
MySQL Shell 是 MySQL 新一代的高级客户端和代码编辑器,是 Oracle 公司提供的一个交互式命令行工具。对比自带的客户端工具 mysql ,MySQL Shell 不仅可以通过它执行传统的 SQL 语句,还可以使用包括 Python 和 JavaScript 在内的编程语言与服务器进行交互,为用户提供更多的选择和灵活性,而且为 MySQL 的不同产品(如 MySQL Server,MySQL Router,MySQL Innodb Cluster等)提供了一个统一接口。与此同时 MySQL Shell 还集成了很多功能,例如数据库查询和更新,数据库管理,集群管理,插件支持,备份恢复等。
MySQL Shell 经常更新,包括修复和新功能。官方建议始终使用可用的最新版本,最新版本的 MySQL Shell 可以与任何版本的 MySQL 5.7 或 8.0 一起使用。与 mysql 客户端不同的是,MySQL Shell 需要独立安装,下面我们一起来学习安装下。
例如我们在 CentOS 7.9 系统上想安装 MySQL Shell 8.0.36 版本,我们需要进入 MySQL Shell 官方网站:https://dev.mysql.com/downloads/shell/8.0.html 然后选择对应系统及版本即可。有两种安装方式可以选择,一是下载二进制包,然后解压缩并配置好环境变量即能安装成功,二是下载 rpm 包,直接 rpm -ivh 即可安装,两种方法都非常简单方便。
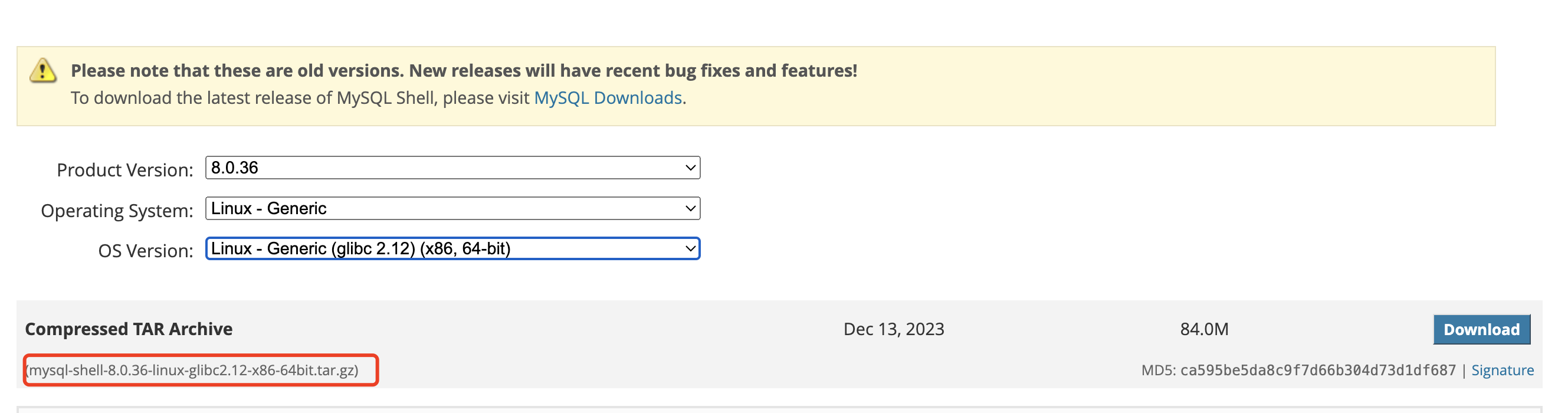
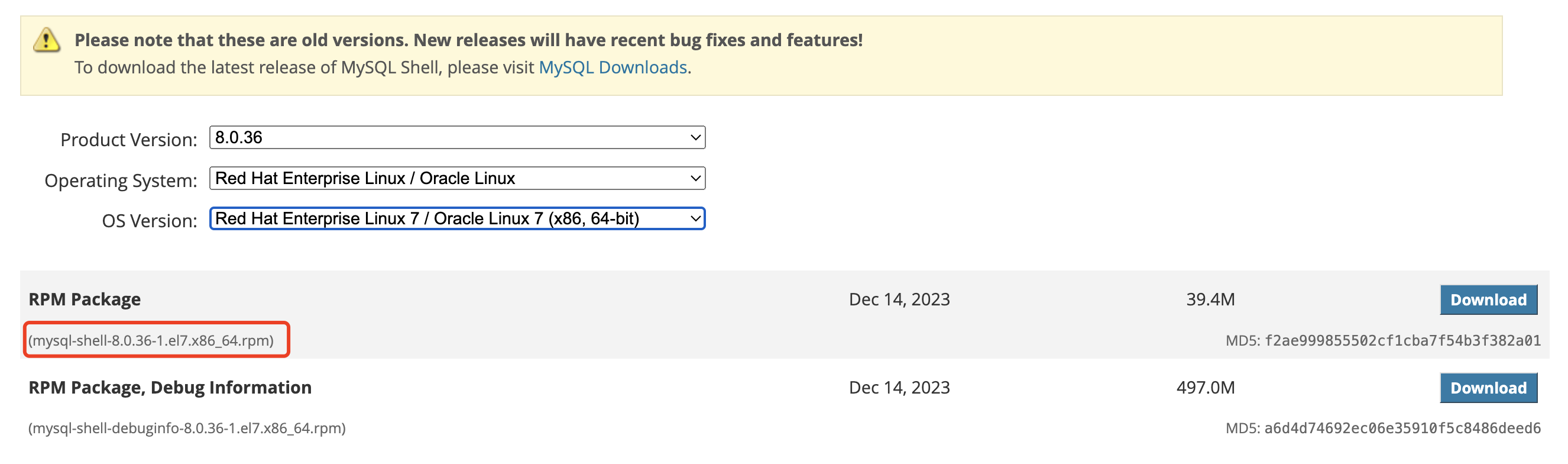
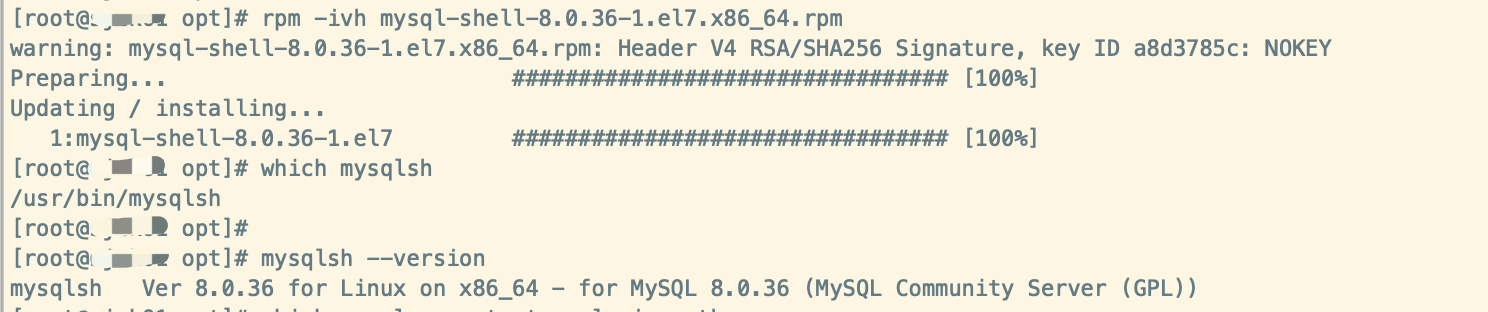
安装完成后,直接 mysqlsh 或者 mysqlsh -uroot -p -h127.0.0.1 -P3306 即可进入交互式命令行。MySQL Shell 可以执行 SQL、JavaScript 或 Python 代码,但一次只能激活一种语言。如果使用 SQL 模式,则语句将作为 SQL 处理,这意味着它们将发送到 MySQL 服务器执行;如果使用 JavaScript 模式,则语句将作为 JavaScript 代码进行处理;如果使用 Python 模式,则语句将作为 Python 代码进行处理。
在交互模式下运行 MySQL Shell 时,通过输入以下命令激活特定语言: \sql 、 \js 、 \py 。在批处理模式下运行 MySQL Shell 时,通过传递以下任一命令行选项来激活特定语言: --js 或 --py --sql 。如果未指定任何模式,则默认模式为 JavaScript。
# 批处理模式下 可用--js --py --sql 指定某种语言
[root@db01 ~]# mysqlsh --sql < /opt/world-db/world.sql
# 交互模式下 使用\sql 、 \js 、 \py 切换语言
[root@db01 ~]# mysqlsh
MySQL Shell 8.0.36
Copyright (c) 2016, 2023, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its affiliates.
Other names may be trademarks of their respective owners.
Type '\help' or '\?' for help; '\quit' to exit.
Creating a Classic session to 'root@localhost:3306'
Fetching schema names for auto-completion... Press ^C to stop.
Your MySQL connection id is 49
Server version: 8.0.36 MySQL Community Server - GPL
No default schema selected; type \use <schema> to set one.
MySQL localhost:3306 ssl JS >
MySQL localhost:3306 ssl JS > \sql
Switching to SQL mode... Commands end with ;
Fetching global names for auto-completion... Press ^C to stop.
MySQL localhost:3306 ssl SQL > \js
Switching to JavaScript mode...
MySQL localhost:3306 ssl JS > \py
Switching to Python mode...
MySQL localhost:3306 ssl Py >
当选择 SQL 语言时,MySQL Shell 与自带的 mysql 客户端用法基本一致,不同的是 MySQL Shell 可以使用 TAB 键进行自动补全,可补全系统关键字、库名、表名、字段名等。并且 MySQL Shell 支持使用 \history 命令显示执行过的历史命令。
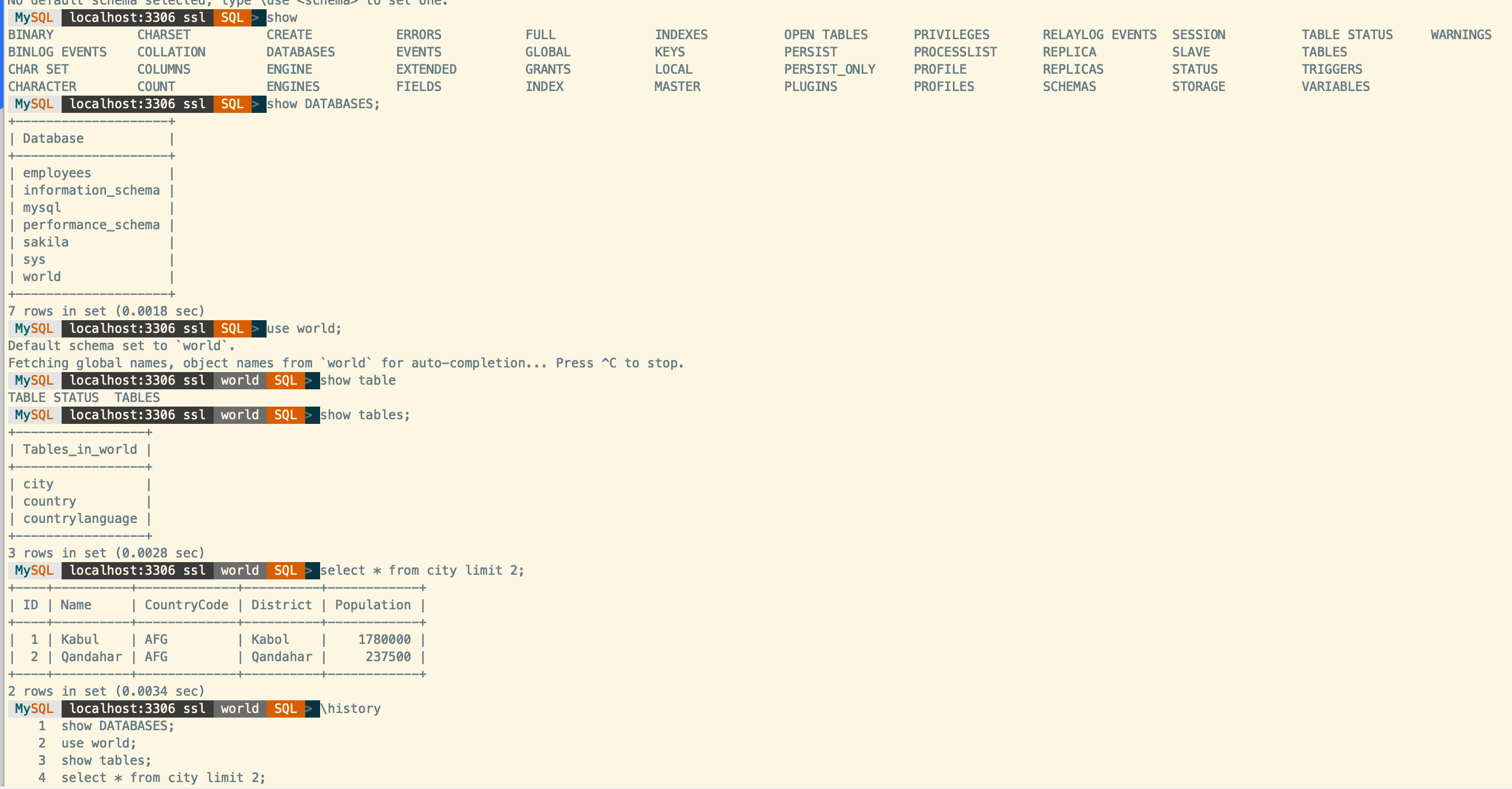
除了 SQL 语言外,MySQL Shell 还支持 JavaScript 和 Python 语言,这使得它超越了传统 SQL 命令行界面的限制,提供了更高级的功能和灵活性。特别是对于熟悉 js 及 Python 的同学,你可以编写 js 或 Python脚本,利用 MySQL Shell 来完成自动化脚本运行。下面我们简单来体验下:
# JavaScript 模式下
# 创建一个测试数据库
MySQL localhost:33060+ ssl JS > var db = session.createSchema('testDB');
MySQL localhost:33060+ ssl JS > print("Database 'testDB' created.");
Database 'testDB' created.
# 创建一个表
MySQL localhost:33060+ ssl JS > var sqlCreateTable = "CREATE TABLE testDB.myTable (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(255))";
MySQL localhost:33060+ ssl JS > var result = session.sql(sqlCreateTable).execute();
MySQL localhost:33060+ ssl JS > print("Table 'myTable' created.");
Table 'myTable' created.
# Python 模式下
# 创建一个名为 mydb 的数据库
MySQL localhost:33060+ ssl Py > session.run_sql('CREATE DATABASE IF NOT EXISTS mydb')
Query OK, 1 row affected (0.0084 sec)
# 使用 mydb 数据库
MySQL localhost:33060+ ssl Py > session.run_sql('USE mydb')
Query OK, 0 rows affected (0.0008 sec)
# 创建一个名为 users 的表
MySQL localhost:33060+ ssl Py > session.run_sql('CREATE TABLE IF NOT EXISTS users (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(50), age INT)')
Query OK, 0 rows affected (0.0402 sec)
# 插入一些数据
MySQL localhost:33060+ ssl Py > session.run_sql("INSERT INTO users (name, age) VALUES ('Alice', 30), ('Bob', 25), ('Charlie', 35)")
Query OK, 3 rows affected (0.0090 sec)
Records: 3 Duplicates: 0 Warnings: 0
# 查询并打印记录
MySQL localhost:33060+ ssl Py > result = session.run_sql('SELECT * FROM users')
MySQL localhost:33060+ ssl Py > print(result.fetch_all())
[[1, "Alice", 30], [2, "Bob", 25], [3, "Charlie", 35]]
目前 MySQL Shell 比较常用的就是 util 模块了,util 模块提供了一系列实用工具函数,以下是 util 模块中的一些关键功能:
- 检查服务器升级: util.checkForServerUpgrade() 函数可以帮助检查MySQL服务器是否可以升级到新版本,并提供相关建议。
- 数据导入工具:
- importTable / import_table(JavaScript和Python中的命名差异): 通过传统MySQL协议,允许用户导入数据到 MySQL 表中,提供了一种替代 LOAD DATA INFILE 的方法。
- importJson / import_json: 利用X插件协议导入JSON格式的数据,提供了更高效的数据导入方式。
- 逻辑转储实用程序:在 MySQL Shell 8.0.21 版本中引入了一套新的逻辑转储实用程序,包括 util.dumpInstance(), util.dumpSchemas() 和 util.loadDump()。这些功能支持通过 zstd 或 gzip 压缩进行快速并行创建和恢复 MySQL 数据库的逻辑转储。
2.利用 MySQL Shell 进行备份恢复
下面我们来了解下如何使用 MySQL Shell 进行备份恢复,备份恢复程序需要在 JavaScript 语言下运行,可在批处理命令行执行,也可在交互模式下执行。下图是进行全量备份的截图,显示的信息还是非常全面的,包括备份了多少个数据库对象,多少个用户,备份速度及备份线程数量等等。
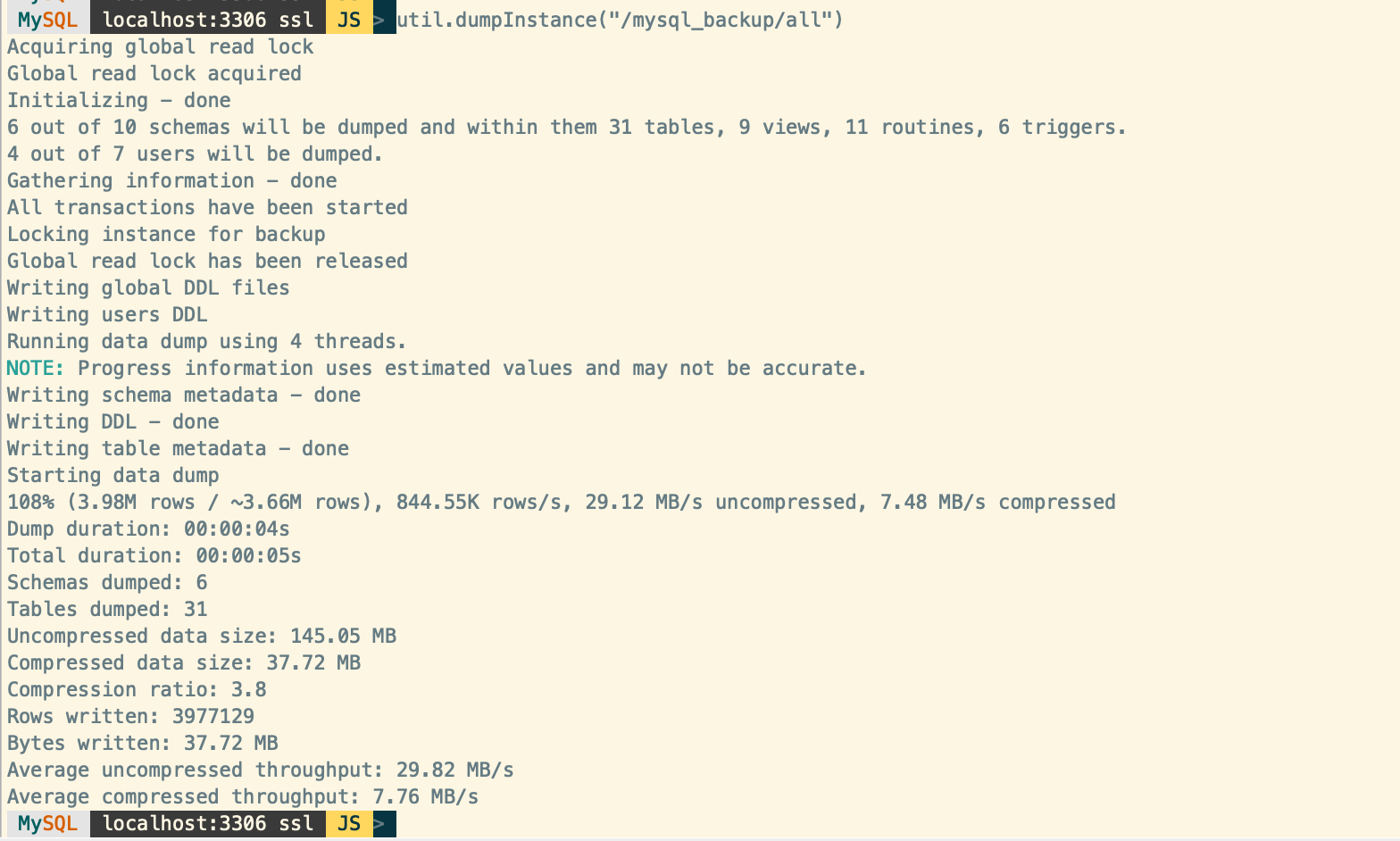
备份完成后,备份目录结果里可以查看结果如下:
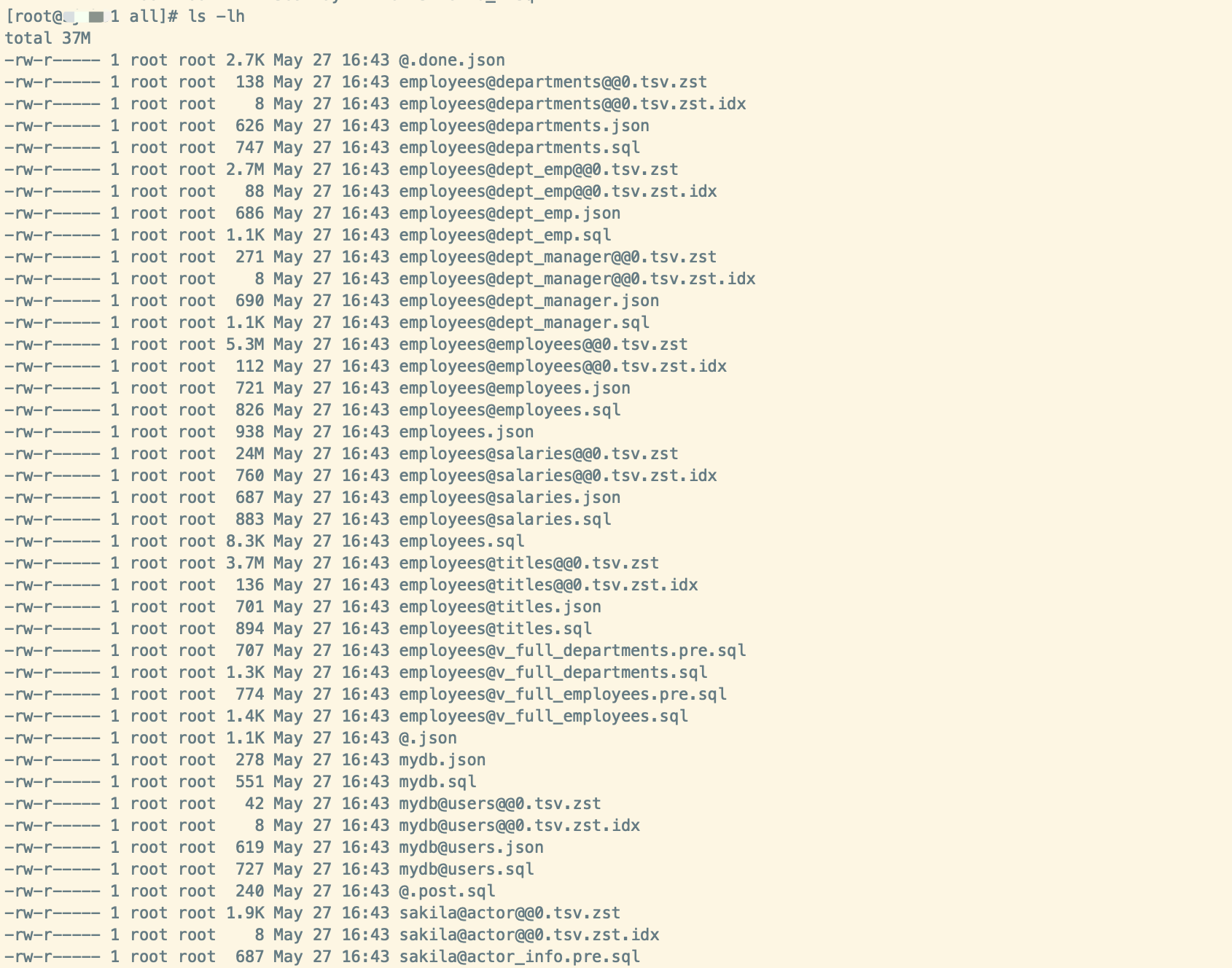
可以看到备份目录下有很多文件,其中主要文件解释:
- @.done.json:该文件记录了备份结束时间,每个库下每个表的大小等信息。
- @.json:该文件记录了客户端版本,备份类型(实例、库或表等),元数据信息以及binlog信息(点位及GTID)。
- @.sql、@.post.sql:这两个文件记录注释信息
- @.users.sql:数据库用户信息,包含创建用户以及授权的SQL脚本。
- 库名.json:记录此数据库下各类数据库对象信息,如表、视图、函数、存储过程等。
- 库名.sql:具体的建库SQL脚本以及创建函数、存储过程脚本。
- 库名@表名.json:记录对应表的元数据信息,包括库名,表名,字段名,主键等信息。
- 库名@表名.sql:具体的建表SQL脚本。
- 库名@表名.triggers.sql:若此表有触发器,则此文件记录触发器创建脚本。
- 库名@表名@@*.tsv.zst:这是实际的数据文件,.tsv 表示纯文本格式,.zst 表示数据被 zstd 压缩算法压缩。每个表的数据可能会被分割成多个 chunk,每个 chunk 一个文件。
- 库名@表名@@*.tsv.zst.idx:与数据文件配套的索引文件。
- 库名@视图名.pre.sql:创建视图预处理脚本,防止上下文依赖。
- 库名@视图名.sql:真正的创建视图SQL脚本
下面分享几种不同的备份场景:
# util.dumpInstance() 使用场景:
# 备份整个实例(默认4线程 采用zstd 压缩算法)
util.dumpInstance('/mysql_backup/all')
# 指定线程数和压缩算法
util.dumpInstance('/mysql_backup/all_gzip', {threads: 8, compression: 'gzip'})
# 不进行压缩
util.dumpInstance('/mysql_backup/all_none', {threads: 8, compression: 'none'})
# 排除某个库
util.dumpInstance('/mysql_backup/all_excludetest', {excludeSchemas: ['employees']})
# 排除指定库和指定用户
util.dumpInstance('/mysql_backup/all_excludedb', {excludeSchemas: ['mydb','testdb'],excludeUsers: ['root']})
# 指定备份特别库及用户
util.dumpInstance('/mysql_backup/testdb', {includeSchemas: ['testdb'],includeUsers: ['test_user']})
# 排除指定表
util.dumpInstance('/mysql_backup/all_excludetable', {excludeTables: ['employees.salaries']})
# 只备份数据库DDL结构
util.dumpInstance('/mysql_backup/all_nodata', {ddlOnly: true})
# 只备份数据
util.dumpInstance('/mysql_backup/all_noddl', {dataOnly: true})
# 不备份用户
util.dumpInstance('/mysql_backup/all_nouser', {users: false})
# util.dumpSchemas() 使用场景:
# 备份指定库
util.dumpSchemas(['employees', 'sakila'], '/mysql_backup/employees_sakila')
# 备份指定库 并排除特定表
util.dumpSchemas(['employees'], '/mysql_backup/employees_excludetable', {excludeTables: ['employees.salaries','employees.departments']})
# util.dumpTables() 使用场景:
# 备份指定表
util.dumpTables('employees', ['departments', 'dept_emp'], '/mysql_backup/employees_dept')
# 备份指定表的部分数据
util.dumpTables('employees', ['departments'], '/mysql_backup/employees_where', { where: {'employees.departments': "dept_no = 'd001'"} })
// 如果在批处理命令行下执行备份,类似命令如下:
mysqlsh -uroot -pxxxxx -h127.0.0.1 --js -e " util.dumpInstance('/mysql_backup/all_instance') "
相应的,util.loadDump() 用于从之前使用 util.dumpInstance()、util.dumpSchemas() 或 util.dumpTables() 创建的逻辑备份中恢复数据。在执行 util.loadDump() 之前,确保目标 MySQL 实例的 local_infile 系统变量设置为 ON,因为 loadDump 会使用 LOAD DATA LOCAL INFILE 语句来导入数据。
下面一起来学习下如何在不同场景下进行恢复:
# 只指定恢复目录,则会默认全部恢复
util.loadDump('/mysql_backup/all_instance')
# 恢复时指定并行加载的线程数
util.loadDump('/mysql_backup/all_instance', { threads: 8 })
# 恢复时忽略某些警告
util.loadDump('/mysql_backup/all_instance', { continueOnError: true })
# 恢复指定的数据库
util.loadDump('/mysql_backup/all_instance', { includeSchemas: ['mydb'] })
# 恢复指定的表
util.loadDump('/mysql_backup/all_instance', { includeTables: ['world.city'] })
# 排除特定的数据库或表
util.loadDump('/mysql_backup/all_instance', { excludeSchemas: ['db_to_exclude'] })
util.loadDump('/mysql_backup/all_instance', { excludeTables: ['db1.table_to_exclude'] })
# 恢复到不同的 MySQL 实例
mysqlsh -uroot -pxxxxx -hxxxxx --js -e "util.loadDump('/mysql_backup/all_instance')"
其实 MySQL Shell备份恢复的参数还有很多,参考官方文档,部分整理如下:
util.dump 命令使用参考:
- 备份整个实例(instance):util.dumpInstance(destinationPath, options)
- 备份整个数据库(schema):util.dumpSchemas([schemas], destinationPath, options)
- 备份表(table):util.dumpTables(schema, [tables], destinationPath, options)
其中 destinationPath 指的是备份文件存放的路径,options 是备份可选的其他参数,一些主要参数说明如下:
- defaultCharacterSet:缺省字符集,默认为utf8mb4
- where: 设置导出数据的条件,可以指定通过where条件来导出表的数据
- ddlOnly: 仅仅导出表的ddl语句,默认为false
- dataOnly: 仅仅导出数据,默认false
- users: 导出用户,缺省为true, (Instance dump utility only)
- excludeUsers: 排除用户,缺省为false, (Instance dump utility only)
- includeUsers: 导出时指定包含的用户, (Instance dump utility only)
- excludeSchemas: 导出时指定排除的DB, (Instance dump utility only)
- includeSchemas: 导出时指定包含的DB, (Instance dump utility only)
- excludeTables: 导出时指定排除的表, (Instance dump utility and schema dump utility only)
- includeTables: 导出时指定包含的表, (Instance dump utility and schema dump utility only)
- events:是否备份定时器,默认为 true,(Instance dump utility and schema dump utility only)
- excludeEvents:忽略某些定时器的备份,(Instance dump utility and schema dump utility only)
- includeEvents:指定某些定时器的备份,(Instance dump utility and schema dump utility only)
- routines:是否备份函数和存储过程,默认为 true,(Instance dump utility and schema dump utility only)
- excludeRoutines:忽略某些函数和存储过程的备份,(Instance dump utility and schema dump utility only)
- includeRoutines:指定某些函数和存储过程的备份,(Instance dump utility and schema dump utility only)
- triggers:是否备份触发器,默认为 true,(All dump utilities)
- excludeTriggers:忽略某些触发器的备份,(All dump utilities)
- includeTriggers:指定某些触发器的备份,(All dump utilities)
- chunking:是否开启 chunk 级别的并行备份功能,默认为 true
- bytesPerChunk:每个 chunk 文件的大小,默认 64M
- threads:并发线程数,默认为 4
- compression:备份文件的压缩算法,默认为 zstd。也可设置为 gzip 或 none(不压缩)
- showProgress:是否打印进度信息,如果是 TTY 设备(命令行终端),则为 true,反之,则为 false
util.loadDump 命令使用参考:util.loadDump(dumpPath, options) ,dumpPath 代表备份文件的路径,options 指恢复可选参数。部分参数做以下说明:
- excludeEvents: 忽略某些定时器的导入
- excludeRoutines:忽略某些函数和存储过程的导入
- excludeSchemas: 忽略某些库的导入
- excludeTables: 忽略某些表的导入
- excludeTriggers:忽略某些触发器的导入
- excludeUsers: 忽略某些账号的导入
- includeEvents: 导入指定定时器
- includeRoutines:导入指定函数和存储过程
- includeSchemas: 导入指定库
- includeTables: 导入指定表
- includeTriggers:导入指定触发器
- includeUsers: 导入指定账号
- loadData: 是否导入数据,默认为 true
- loadDdl: 是否导入 DDL 语句,默认为 true
- loadUsers: 是否导入账号,默认为 false。注意,即使将 loadUsers 设置为 true,也不会导入当前正在执行导入操作的用户
- ignoreExistingObjects: 是否忽略已经存在的对象,默认为 off
- backgroundThreads: 获取元数据和 DDL文件内容的线程数。备份集如果存储在本地,backgroundThreads 默认和 threads 一致
- threads: 并发线程数,默认为 4
- maxBytesPerTransaction:指定单个 LOAD DATA 操作可加载的最大字节数。默认与 bytesPerChunk 一致。这个参数可用来规避大事务
- skipBinlog: 是否设置 sql_log_bin=0 ,默认 false
- updateGtidSet: 更新 GTID_PURGED。可设置:off(不更新,默认值), replace(替代目标实例的 GTID_PURGED), append(追加)
总结:
本篇文章主要介绍了 MySQL Shell 的安装与简单使用,利用比较大的篇幅介绍了 MySQL Shell 的备份恢复功能,还有更多高级功能没有介绍到,特别是对 MySQL InnoDB Cluster 和 MySQL InnoDB ReplicaSet 高可用集群的支持。可以看得出,MySQL Shell 确实更加强大和智能,在备份恢复方面确实有很多场景很实用,而且更加快速稳定,肯定会是 DBA 人员的一款得力工具。
参考:
|
作者:MySQL技术 出处:https://www.cnblogs.com/kunjian/ 本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。 如果文中有什么错误,欢迎指出。以免更多的人被误导。有需要沟通的,可以站内私信,文章留言,或者关注『MySQL技术』公众号私信我。一定尽力回答。 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号