Redis高级进阶(一)
一、redis中的事务
在关系型数据库中事务是必不可少的一个核心功能,生活中也是处处可见,比如我们去银行转账,首先需要将A账户的钱划走,然后存到B账户上,这两个步骤必须在同一事务中,要么都执行,要么都不执行,不然钱凭空消失了,换了谁也无法接受。
同样,redis中也为我们提供了事务,原理是:先把一组同一事务中的命令发送给redis,然后redis进行依次执行。
1、事务的语法:
multi 命令1 命令2 ... exec
解释下语法:首先通过multi命令告诉redis:“下面我发给你的命令是属于同一事务的,你呢,先不要执行,可以把它们先存储起来”。redis回答:“okay啦”。而后我们就发送银行转账的命令1和命令2,这时redis将遵从约定不会执行命令,而是返回queued,表示把这两条命令存储到等待执行的事务队列中了。最后我们发送exec命令,redis开始依次执行在等待队列中的命令,完成一个事务的操作。
redis保证事务中所有命令要么全执行,要么都不执行。如果在发送exec前客户端断线了,redis会清空等待的事务队列,所有命令都不会执行。而一旦发送了exec,即使在执行过程中客户端断线了也没有关系,因为redis早已存储了命令。
下面我们模拟下银行转账的业务,从银行A转账5000到银行B,中间企图修改银行A的余额,这时看看能否转账成功并保证金额正确?
- 先给银行A 和B分别初始化10000元。
127.0.0.1:6379> set bankA 10000 OK 127.0.0.1:6379> get bankA "10000" 127.0.0.1:6379> set bankB 10000 OK 127.0.0.1:6379> get bankB "10000"
- 进行转账业务操作:
127.0.0.1:6379> multi OK 127.0.0.1:6379> decrby bankA 5000 QUEUED 127.0.0.1:6379> incrby bankB 5000 QUEUED 127.0.0.1:6379>
- 重新打开一个session,模拟修改银行A的余额,比如取10000元,这时钱被取了,余额为0
127.0.0.1:6379> decrby bankA 10000 (integer) 0 127.0.0.1:6379> get bankA "0"
- 到第一个session中执行事务
127.0.0.1:6379> exec 1) (integer) -5000 #这里假设余额可以透支,哈哈。变成﹣5000,而不是原来想的5000,如果实际业务,这时是无法进行转账的。事务保证了余额正确 2) (integer) 15000
2、事务错误处理
如果在执行一个事务时,里面某个命令出错了,redis怎么处理呢?在redis中,需要分析导致命令错误的原因,不同的原因会有不同的处理方式。
1)语法错误
语法错误是指该命令不存在或者参数个数不正确。对于这类错误,redis(2.6.5之后的版本)的处理方式是直接返回错误,全部不执行,即使里面有正确的命令。
127.0.0.1:6379> multi OK 127.0.0.1:6379> set key value QUEUED 127.0.0.1:6379> set key (error) ERR wrong number of arguments for 'set' command 127.0.0.1:6379> iiiget key (error) ERR unknown command 'iiiget' 127.0.0.1:6379> exec (error) EXECABORT Transaction discarded because of previous errors. 127.0.0.1:6379> get key (nil) #事务中有语法错误的命令,即使有一个命令正确也不会被执行 127.0.0.1:6379>
2)运行错误
运行错误是指命令在执行的时候报错,比如用散列的命令操作集合类型的键。这类错误在运行前redis是无法发现的,故事务中如出现这样错误的命令,其他正确的命令会依然被执行,即使是在错误命令之后的。需要小心为上,避免此类错误。
127.0.0.1:6379> multi OK 127.0.0.1:6379> set key 1 QUEUED 127.0.0.1:6379> sadd key 2 QUEUED 127.0.0.1:6379> set key 3 QUEUED 127.0.0.1:6379> exec 1) OK 2) (error) WRONGTYPE Operation against a key holding the wrong kind of value 3) OK 127.0.0.1:6379> get key "3"
可见sadd key 2出错了,但是set key 3依然被执行了。
redis中的事务不像关系型数据库有回滚机制,为此如出现这样的问题,开发者必须自己收拾造成这样的烂摊子了。
为了保证尽量不出现命令和数据类型不匹配的运行错误,事前规划数据库(如保证键名规范)是尤为重要的。
3、watch命令
watch命令可以监控一个和多个键,一旦被监控键的值被修改,阻止之后的一个事务执行(即执行exec时返回nil,但这时watch监控也会失效),还记得上面转账吗?当在转账事务过程中,bankA被取走了10000,余额变成0,这时操作转账时应该提示余额不足,无法转账。可以使用watch命令来阻止转账事务的执行。下面优化一下上面的转账业务:
127.0.0.1:6379> watch bankA #监控银行A账号 OK
127.0.0.1:6379> decrby bankA 10000
(integer) 0
127.0.0.1:6379> multi
OK 127.0.0.1:6379> decrby bankA 5000 QUEUED 127.0.0.1:6379> incrby bankB 5000 QUEUED 127.0.0.1:6379> exec (nil) 127.0.0.1:6379> get bankA "0" 127.0.0.1:6379> get bankB "10000" 127.0.0.1:6379>
二、生存时间
在实际开发中经常会遇到一些有时效的数据,比如限时优惠活动、缓存或验证码等,过一段时间需要删除这些数据。在关系数据库中一般需要维护一个额外的字段来存储过期时间,然后定期检测删除过期数据。而在redis中命令就可以搞定。
1、命令
expire key seconds:返回1表示设置成功,0表示设置失败或该键不存在;
127.0.0.1:6379> set lifecycle 'test life cycle' OK 127.0.0.1:6379> get lifecycle "test life cycle" 127.0.0.1:6379> expire lifecycle 30 #设置生存时间为30秒,最小单位是秒 (integer) 1 127.0.0.1:6379> ttl lifecycle #ttl查看还剩多久 (integer) 13 127.0.0.1:6379> ttl lifecycle (integer) 11 127.0.0.1:6379> ttl lifecycle (integer) 9 127.0.0.1:6379> ttl lifecycle (integer) 8 127.0.0.1:6379> ttl lifecycle #当时间到了删除后会返回-2,不存在的键也返回-2 (integer) -2
取消设置时间:persist key
除了专用的取消命令,set,getset命令也会清除key的生存时间。
pexpire key mileseconds 精确到毫秒
三、排序
在我们实际的开发中,很多地方用到排序这个功能,上节咱们说过有序集合就可以实现排序功能,是通过它分数,redis除了有序集合外还有sort命令,sort命令很复杂,能用好它不是很容易,而且一不小心就可能导致性能问题,下面就说说这些排序。
1、有序集合排序
有序集合常用的场景是大数据排序,如游戏玩家的排行榜,一般很少需要获得键中的所有数据。
2、sort命令
除了上面的有序集合,redis还提供了sort命令,它可以对列表、集合、有序集合类型键进行排序,并且完成如关系数据库中关联查询类似的任务。
- 对集合类型排序:
127.0.0.1:6379> sadd set_sort 5 2 1 0 7 9 (integer) 6
#不是说集合是无序的嘛,明明上面添加时无序的,这里打印出来怎么排序了呢?是这样的,集合常常用来存储对象的id,一般都是整数,对于这种情况,进行了优化,所以这里是排序了
127.0.0.1:6379> smembers set_sort 1) "0" 2) "1" 3) "2" 4) "5" 5) "7" 6) "9" 127.0.0.1:6379> sort set_sort desc #desc是按降序排序,当然这里的排序并不影响原始的数据 1) "9" 2) "7" 3) "5" 4) "2" 5) "1" 6) "0"
- 对列表排序:
127.0.0.1:6379> lpush mylist 2 -1 3 44 5 (integer) 5 127.0.0.1:6379> lrange mylist 0 -1 1) "5" 2) "44" 3) "3" 4) "-1" 5) "2" 127.0.0.1:6379> sort mylist 1) "-1" 2) "2" 3) "3" 4) "5" 5) "44"
- 对有序集合排序
127.0.0.1:6379> zadd myzset 0 tom 1 helen 2 allen 3 jack (integer) 4 127.0.0.1:6379> zrange myzset 0 -1 #这是按照分数排序取得结果 1) "tom" 2) "helen" 3) "allen" 4) "jack" 127.0.0.1:6379> sort myzset (error) ERR One or more scores can't be converted into double 127.0.0.1:6379> sort myzset alpha #通过sort按照字母字典排序后的结果,这时忽略有序集合的分数了,按照元素的字典排序。 1) "allen" 2) "helen" 3) "jack" 4) "tom"
当然,如果结果集数据太多,需要分页显示,这时可以用limit参数搞定:
limit offset count 表示从第offset起,共取得count个数据
127.0.0.1:6379> sort myzset alpha desc limit 2 2 #表示从第二条取2条记录 1) "helen" 2) "allen"
3、sort命令的参数
1)By参数
有时我们经常遇到对一个散列表中某个字段进行排序,比如写博客时按照文章的发布时间进行排序,取最新的文章放到首页,这个时候sort命令的by参数就可以派上用场了。
By参数的语法是:“by 参考键”,其中参考键可以是字符串类型或者散列类型键的某个字段(散列表示为:键名->字段名)如果提供了by参数,sort将不会再按照元素自身值进行排序,而是对每个元素使用元素值替换参考键中的第一个‘*’并获取其值,然后依据该值进行排序。
有点绕啊,下面举例说明:假如java类别下有4篇博客文章,可以按照下图建立文章类别和文章的数据模型。具体类别和文章的结构图如下:
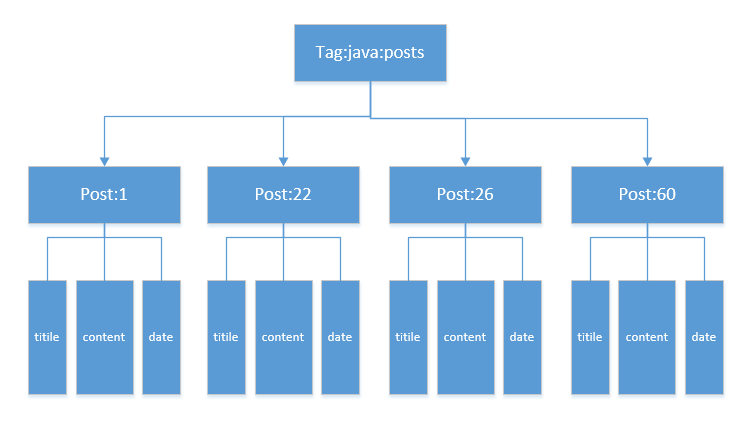
Tag:java:posts:表示文章的类别java,我们用集合类型表示,里面只存储文章的ID
Post:id:表示文章,有三个字段,我们用散列类型存储,一个id对应一个散列
这样模型可以这样建立了:
127.0.0.1:6379> hmset Post:1 title 'java study' content 'java is a good programming language' date '201509122110' OK 127.0.0.1:6379> hmset Post:22 title 'java study2' content 'java is a good programming language' date '201409121221' OK 127.0.0.1:6379> hmset Post:26 title 'java study3' content 'java is a good programming language' date '201709121221' OK 127.0.0.1:6379> hmset Post:60 title 'java study4' content 'java is a good programming language' date '201510221221' OK 127.0.0.1:6379> sadd Tag:java:posts 1 22 26 60 (integer) 4
这个时候我想对Tag:java:posts类别下的文章按照发布日期进行排序,可以这样来:
127.0.0.1:6379> smembers Tag:java:posts #排序之前直接取得的文章 1) "1" 2) "22" 3) "26" 4) "60" 127.0.0.1:6379> sort Tag:java:posts by Post:*->date desc #按照日期排序后的结果,这里by后面参数是散列类型的 1) "26" 2) "60" 3) "1" 4) "22"
当然了,by后面还可以跟上字符串类型,如下:
127.0.0.1:6379> lpush sortbylist 2 1 3 (integer) 3 127.0.0.1:6379> set item:1 50 OK 127.0.0.1:6379> set item:2 90 OK 127.0.0.1:6379> set item:3 20 OK 127.0.0.1:6379> sort sortbylist by item:* desc 1) "2" 2) "1" 3) "3"
2)get参数
上面事例中的文章排序后,如果我想获取文章标题,需要针对每个文章id进行hget,有没有觉得很麻烦呢?其实sort还提供了get参数,可以很轻松的获得文章的标题
get参数不影响排序,它的作用是返回get参数指定的键值。get参数和by参数一样,也支持散列和字符串类型的键,并使用*作为占位符,要实现排序后直接返回文章的标题,可以这样做:
127.0.0.1:6379> sort Tag:java:posts by Post:*->date desc get Post:*->title 1) "java study3" 2) "java study4" 3) "java study" 4) "java study2" 127.0.0.1:6379>
在一个sort中可以有多个get参数,但是by只能有一个,get #表示返回元素本身的值。还可以这样:
127.0.0.1:6379> sort Tag:java:posts by Post:*->date desc get Post:*->title get Post:*->date get #
1) "java study3"
2) "201709121221"
3) "26"
4) "java study4"
5) "201510221221"
6) "60"
7) "java study"
8) "201509122110"
9) "1"
10) "java study2"
11) "201409121221"
12) "22"
3)store参数
如果希望保存排序后的结果集,可以使用store参数,默认保存后的数据类型是列表类型,如果该键已存在,则覆盖它。
127.0.0.1:6379> sort Tag:java:posts by Post:*->date desc get Post:*->title get Post:*->date get # store sort.result (integer) 12 127.0.0.1:6379> lrange sort.result 0 -1 1) "java study3" 2) "201709121221" 3) "26" 4) "java study4" 5) "201510221221" 6) "60" 7) "java study" 8) "201509122110" 9) "1" 10) "java study2" 11) "201409121221" 12) "22" 127.0.0.1:6379>
store参数常常用来跟exprie命令实现排序结果的缓存功能,如上面提到的游戏排行榜数据,实现的伪代码如下
#判断是否存在排序结果的缓存 $isExistsCache = Exists cache.sort if ($isExistsCache = 1) #如果存在缓存,直接返回值 return lrange cache.sort 0 -1 else #如果不存在缓存,使用sort命令排序并将结果存入cache.sort缓存中 $sortResult=sort some.list store cache.sort #设置缓存的生存时间为10分钟 expire cache.sort 600 return $sortResult
4、性能优化
sort命令是redis中最强大复杂的命令之一,如果用不好很容易出现性能问题,sort命令的时间复杂度为:O(N+MlogM),其中N表示需要排序的元素个数,M表示返回的元素个数,当N数值很大时sort排序性能较低,并且redis在排序前会建立一个长度为N的容器来存储排序的元素,虽然是临时的,但是如果遇到大数据量的排序则会成为性能瓶颈。所以在开发中需要注意以下几个方面:
- 尽可能减少待排序键中的元素数量(降低N值)
- 使用limit参数只获得需要的值(减少M值)
- 如果排序的数据量较大,尽可能使用store将结果缓存

 浙公网安备 33010602011771号
浙公网安备 33010602011771号