跳表
如何理解“跳表”?
对于一个单链表来讲,即便链表中存储的数据是有序的,如果我们要想在其中查找某个数据,也只能从头到尾遍历链表。这样查找效率就会很低,时间复杂度会很高,是 O(n)。
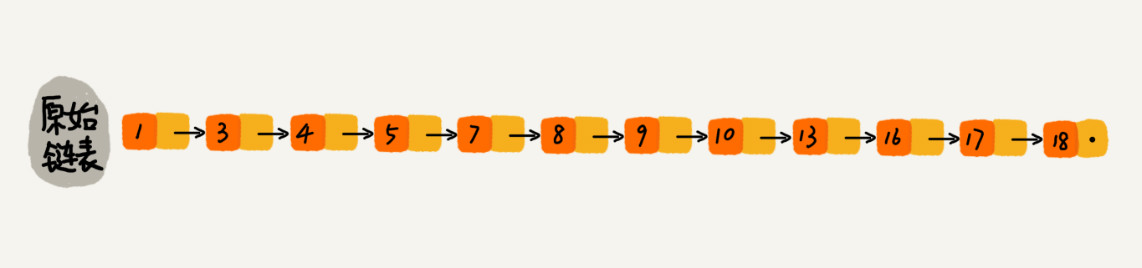
那怎么来提高查找效率呢?如果像图中那样,对链表建立一级“索引”,查找起来是不是就会更快一些呢?
每两个结点提取一个结点到上一级,我们把抽出来的那一级叫作索引或索引层。你可以看我画的图。图中的 down 表示 down 指针,指向下一级结点。
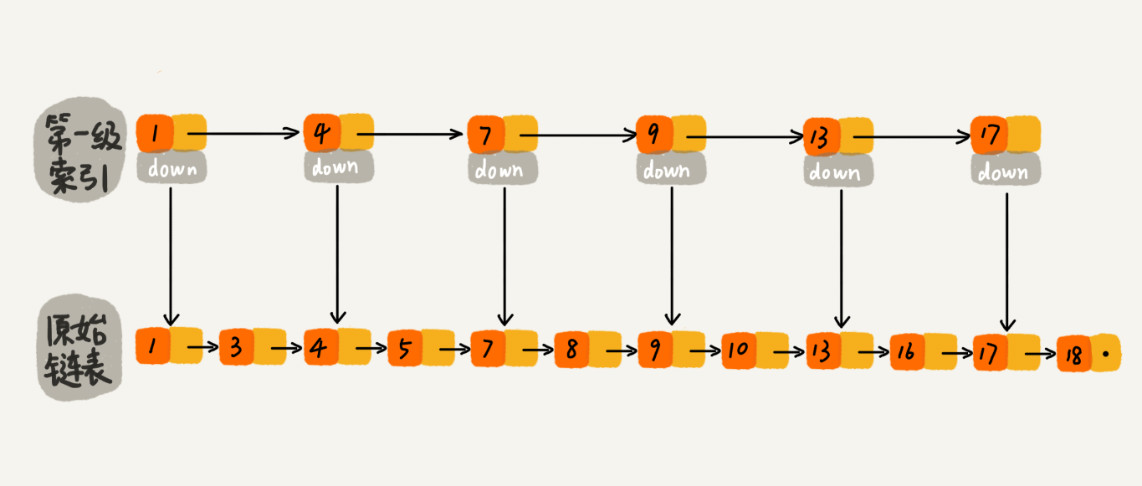
如果我们现在要查找某个结点,比如 16。我们可以先在索引层遍历,当遍历到索引层中值为 13 的结点时,我们发现下一个结点是 17,那要查找的结点 16 肯定就在这两个结点之间。然后我们通过索引层结点的 down 指针,下降到原始链表这一层,继续遍历。这个时候,我们只需要再遍历 2 个结点,就可以找到值等于 16 的这个结点了。这样,原来如果要查找 16,需要遍历 10 个结点,现在只需要遍历 7 个结点
从这个例子里,我们看出,加来一层索引之后,查找一个结点需要遍历的结点个数减少了,也就是说查找效率提高了
用跳表查询到底有多快?
每两个结点会抽出一个结点作为上一级索引的结点,那第一级索引的结点个数大约就是 n/2,第二级索引的结点个数大约就是 n/4,第三级索引的结点个数大约就是 n/8,依次类推,也就是说,第 k 级索引的结点个数是第 k-1 级索引的结点个数的 1/2,那第 k级索引结点的个数就是 n/(2k)
假设索引有 h 级,最高级的索引有 2 个结点。通过上面的公式,我们可以得到 n/(2h)=2,从而求得 h=log2n-1。如果包含原始链表这一层,整个跳表的高度就是 log2n。我们在跳表中查询某个数据的时候,如果每一层都要遍历 m 个结点,那在跳表中查询一个数据的时间复杂度就是 O(m*logn)
那这个 m 的值是多少呢?按照前面这种索引结构,我们每一级索引都最多只需要遍历 3 个结点,也就是说 m=3,为什么是 3 呢?我来解释一下。
假设我们要查找的数据是 x,在第 k 级索引中,我们遍历到 y 结点之后,发现 x 大于 y,小于后面的结点 z,所以我们通过 y 的 down 指针,从第 k 级索引下降到第 k-1 级索引。在第 k-1 级索引中,y 和 z 之间只有 3 个结点(包含 y 和 z),所以,我们在 K-1 级索引中最多只需要遍历 3 个结点,依次类推,每一级索引都最多只需要遍历 3 个结点
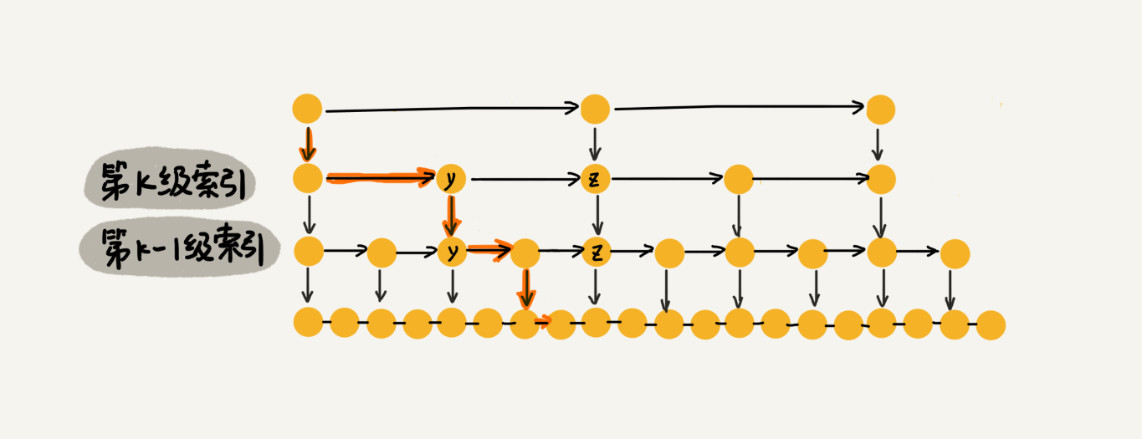
通过上面的分析,我们得到 m=3,所以在跳表中查询任意数据的时间复杂度就是 O(logn)
插入操作
先确定该元素要占据的层数 K(采用丢硬币的方式,这完全是随机的)。
然后在 Level 1 ... Level K 各个层的链表都插入元素。
用Update数组记录插入位置,同样从顶层开始,逐层找到每层需要插入的位置,再生成层数并插入。
例子:插入 119, K = 2

1 void insert(int key) 2 { 3 int p = head; 4 int update[MAX_LEVEL + 5]; 5 int k = rand_level(); 6 for (register int i = MAX_LEVEL; i; --i) 7 { 8 while (sl[p].next[i] ^ tail && sl[sl[p].next[i]].key < key) 9 p = sl[p].next[i]; 10 update[i] = p; 11 } 12 int temp; 13 new_node(temp, key); 14 for (register int i = k; i; --i) 15 { 16 sl[temp].next[i] = sl[update[i]].next[i]; 17 sl[update[i]].next[i] = temp; 18 } 19 }
查询操作
从最上层开始,如果key小于或等于当层后继节点的key,则平移一位;如果key更大,则层数减1,继续比较。最终一定会到第一层(想想为什么)
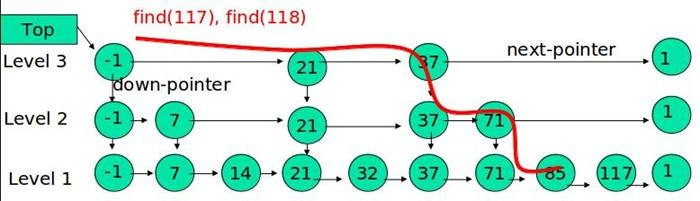
删除操作
1 void erase(int key) 2 { 3 int p = head; 4 int update[MAX_LEVEL + 5]; 5 for (register int i = MAX_LEVEL; i; --i) 6 { 7 while (sl[p].next[i] ^ tail && sl[sl[p].next[i]].key < key) 8 p = sl[p].next[i]; 9 update[i] = p; 10 } 11 free_node(sl[p].next[1]); 12 for (register int i = MAX_LEVEL; i; --i) 13 { 14 if (sl[sl[update[i]].next[i]].key == key) 15 sl[update[i]].next[i] = sl[sl[update[i]].next[i]].next[i]; 16 } 17 }
实例
题目:给出 n 个正整数,然后有 m 个询问,每个询问一个整数,询问该整数是否在 n 个正整数中出现过。
思路:用set就能实现,这里尝试用跳表(set本部就是平衡树,所有用SkipList能解决的,set也能解决一些)
1 #include<cstdio> 2 #include<cstdlib> 3 using namespace std; 4 5 const int maxn = 100000 + 10; 6 const int max_level = 25; //层数上限 7 8 //定义节点 9 struct Node 10 { 11 int key; 12 int next[max_level + 1]; //next[i]表示这个节点在第i层的下一个编号 13 }node[maxn + 2]; 14 int node_tot, head, tail; 15 16 //生成层数 17 inline int rand_level() 18 { 19 int ret = 1; 20 while (rand() % 2 && ret <= max_level) 21 ret++; 22 return ret; 23 } 24 25 //分配新节点 //key默认为0,表示head、tail的值为0 26 inline void new_node(int& p, int key = 0) 27 { 28 p = ++node_tot; 29 node[p].key = key; 30 } 31 32 33 //初始化 34 inline void init() 35 { 36 new_node(head); new_node(tail); 37 for (register int i = 1; i <= max_level; i++) 38 node[head].next[i] = tail; 39 } 40 41 //插入操作 42 void insert(int key) 43 { 44 int p = head; 45 int update[max_level + 1]; 46 int K = rand_level(); 47 for (register int i = max_level; i; i--) 48 { 49 while (node[p].next[i] ^ tail && node[node[p].next[i]].key < key) p = node[p].next[i]; 50 update[i] = p; 51 } 52 int tmp; 53 new_node(tmp, key); 54 for (register int i = K; i; i--) 55 { 56 node[tmp].next[i] = node[update[i]].next[i]; 57 node[update[i]].next[i] = tmp; 58 } 59 } 60 61 //查找元素 62 int find(int key) 63 { 64 int p = head; 65 for(register int i = max_level; i; i--) 66 { 67 while (node[p].next[i] ^ tail && node[node[p].next[i]].key < key) 68 p = node[p].next[i]; 69 } 70 if (node[node[p].next[1]].key == key) return node[p].next[1] - 2; 71 else return -1; 72 } 73 74 int n, m; 75 76 int main() 77 { 78 srand(19260817); 79 scanf("%d%d", &n, &m); 80 init(); 81 int tmp; 82 while (n--) 83 { 84 scanf("%d", &tmp); 85 insert(tmp); 86 } 87 while (m--) 88 { 89 scanf("%d", &tmp); 90 int res = find(tmp); 91 if (res > 0) printf("YES\n"); 92 else printf("NO\n"); 93 } 94 return 0; 95 }
实例2
1 package skiplist; 2 3 import java.util.Random; 4 5 /** 6 * 跳表的一种实现方法。 7 * 跳表中存储的是正整数,并且存储的是不重复的。 8 * 9 * Author:ZHENG 10 */ 11 public class SkipList { 12 13 private static final int MAX_LEVEL = 16; 14 15 private int levelCount = 1; 16 17 private Node head = new Node(); // 带头链表 18 19 private Random r = new Random(); 20 21 public Node find(int value) { 22 Node p = head; 23 for (int i = levelCount - 1; i >= 0; --i) { 24 while (p.forwards[i] != null && p.forwards[i].data < value) { 25 p = p.forwards[i]; 26 } 27 } 28 29 if (p.forwards[0] != null && p.forwards[0].data == value) { 30 return p.forwards[0]; 31 } else { 32 return null; 33 } 34 } 35 36 public void insert(int value) { 37 int level = randomLevel(); 38 Node newNode = new Node(); 39 newNode.data = value; 40 newNode.maxLevel = level; 41 Node update[] = new Node[level]; 42 for (int i = 0; i < level; ++i) { 43 update[i] = head; 44 } 45 46 // record every level largest value which smaller than insert value in update[] 47 Node p = head; 48 for (int i = level - 1; i >= 0; --i) { 49 while (p.forwards[i] != null && p.forwards[i].data < value) { 50 p = p.forwards[i]; 51 } 52 update[i] = p;// use update save node in search path 53 } 54 55 // in search path node next node become new node forwords(next)for (int i = 0; i < level; ++i) { 56 newNode.forwards[i] = update[i].forwards[i]; 57 update[i].forwards[i] = newNode; 58 } 59 60 // update node hightif (levelCount < level) levelCount = level; 61 } 62 63 public void delete(int value) { 64 Node[] update = new Node[levelCount]; 65 Node p = head; 66 for (int i = levelCount - 1; i >= 0; --i) { 67 while (p.forwards[i] != null && p.forwards[i].data < value) { 68 p = p.forwards[i]; 69 } 70 update[i] = p; 71 } 72 73 if (p.forwards[0] != null && p.forwards[0].data == value) { 74 for (int i = levelCount - 1; i >= 0; --i) { 75 if (update[i].forwards[i] != null && update[i].forwards[i].data == value) { 76 update[i].forwards[i] = update[i].forwards[i].forwards[i]; 77 } 78 } 79 } 80 } 81 82 // 随机 level 次,如果是奇数层数 +1,防止伪随机private int randomLevel() { 83 int level = 1; 84 for (int i = 1; i < MAX_LEVEL; ++i) { 85 if (r.nextInt() % 2 == 1) { 86 level++; 87 } 88 } 89 90 return level; 91 } 92 93 public void printAll() { 94 Node p = head; 95 while (p.forwards[0] != null) { 96 System.out.print(p.forwards[0] + " "); 97 p = p.forwards[0]; 98 } 99 System.out.println(); 100 } 101 102 public class Node { 103 private int data = -1; 104 private Node forwards[] = new Node[MAX_LEVEL]; 105 private int maxLevel = 0; 106 107 @Override 108 public String toString() { 109 StringBuilder builder = new StringBuilder(); 110 builder.append("{ data: "); 111 builder.append(data); 112 builder.append("; levels: "); 113 builder.append(maxLevel); 114 builder.append(" }"); 115 116 return builder.toString(); 117 } 118 } 119 120 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号