趣谈Linux操作系统学习笔记-内存管理(23讲)- 物理的页面是如何管理的
物理内存的组织方式
物理内存的布局平坦内存模型:
由于物理地址是连续的,页也是连续的,每个页大小也是一样的。因而对于任何一个地址,只要直接除一下每页的大小,很容易直接算出在哪一页。每个页有一个结构 struct page 表示,这个结构也是放在一个数组里面,这样根据页号,很容易通过下标找到相应的 struct page 结构
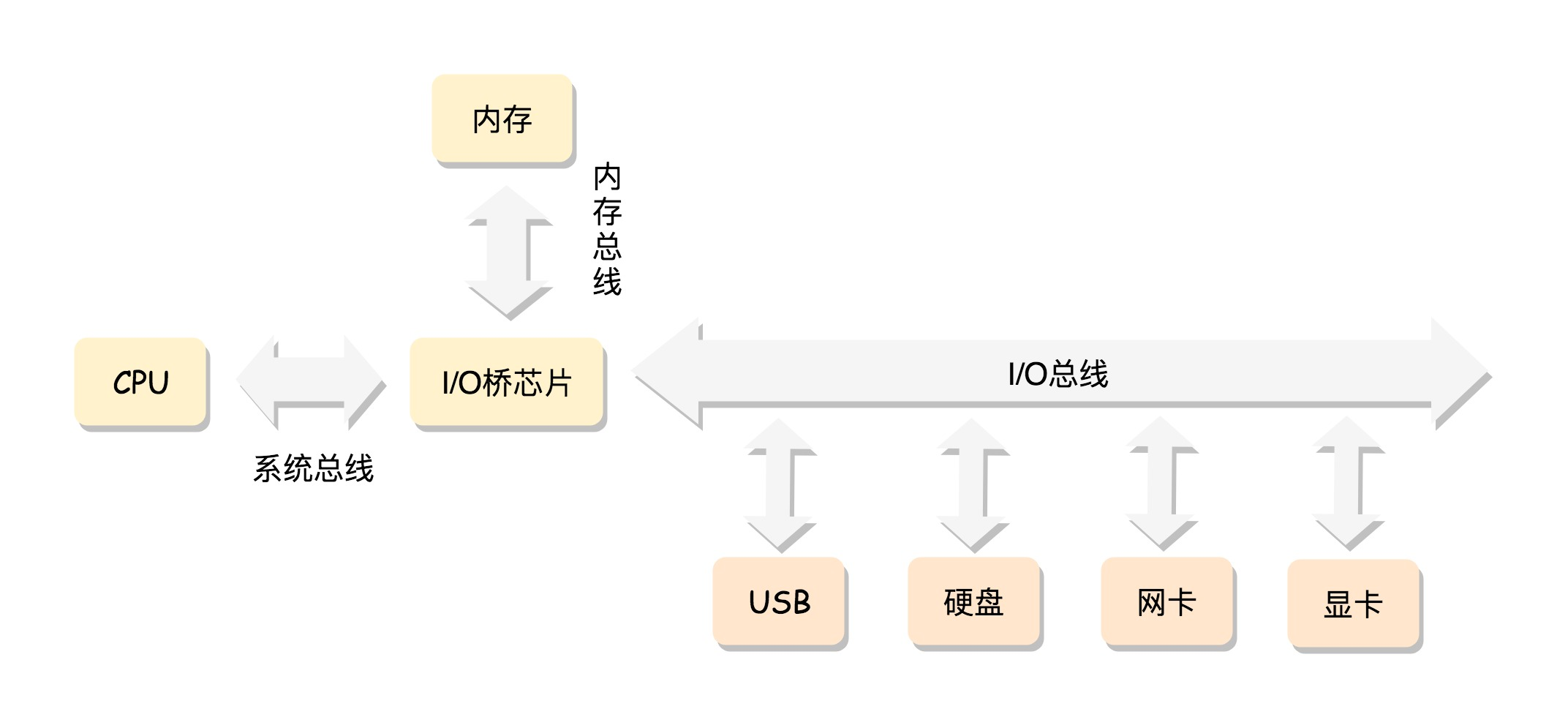
x86 的工作模式
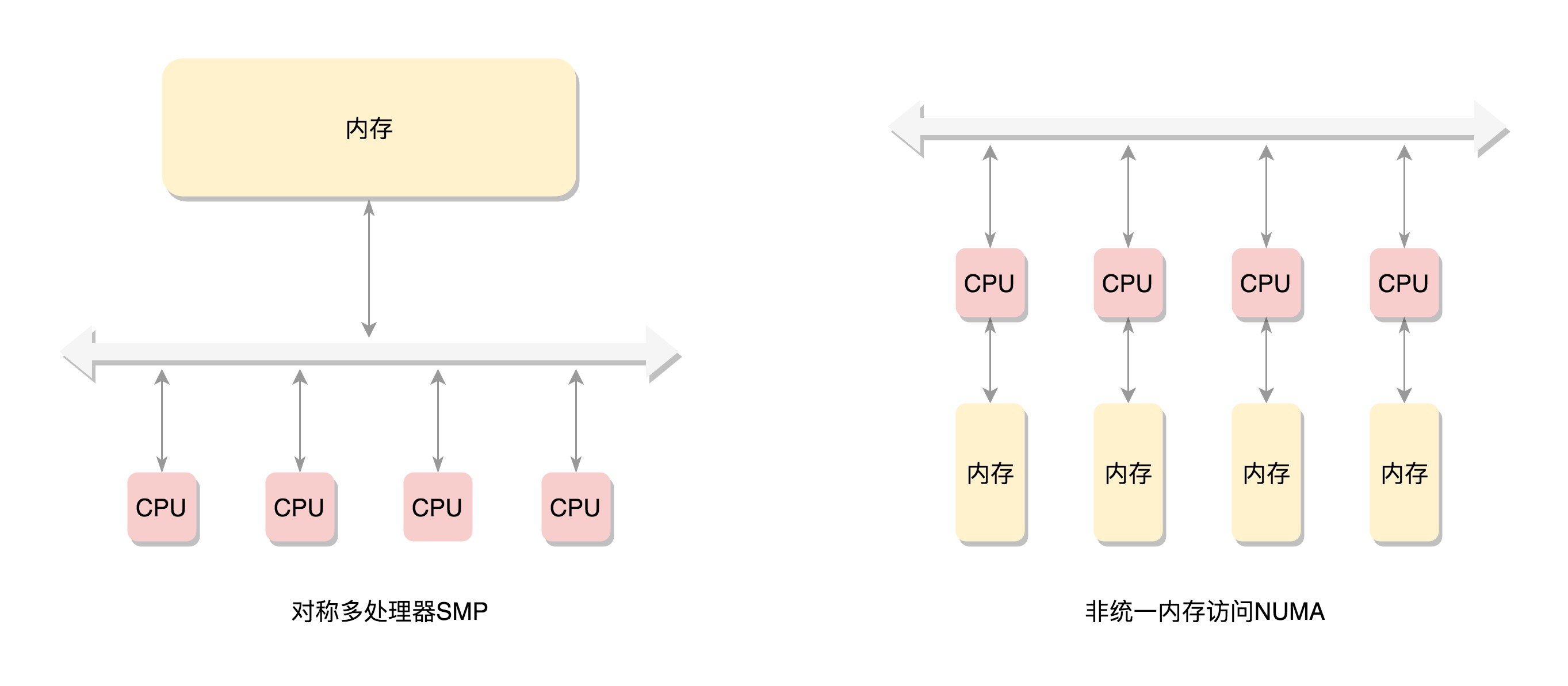
SMP(Symmetric multiprocessing):CPU 也会有多个,在总线的一侧。所有的内存条组成一大片内存,在总线的另一侧,所有的 CPU 访问内存都要过总线,而且距离都是一样的
NUMA(Non-uniform memory access):在这种模式下,内存不是一整块。每个 CPU 都有自己的本地内存,CPU 访问本地内存不用过总线,因而速度要快很多,每个 CPU 和内存在一起,称为一个 NUMA 节点。但是,在本地内存不足的情况下,每个 CPU 都可以去另外的 NUMA 节点申请内存,这个时候访问延时就会比较长,NUMA 往往是非连续内存模型。而非连续内存模型不一定就是 NUMA,有时候一大片内存的情况下,也会有物理内存地址不连续的情况
NUMA 方式讲解
节点pglist_data
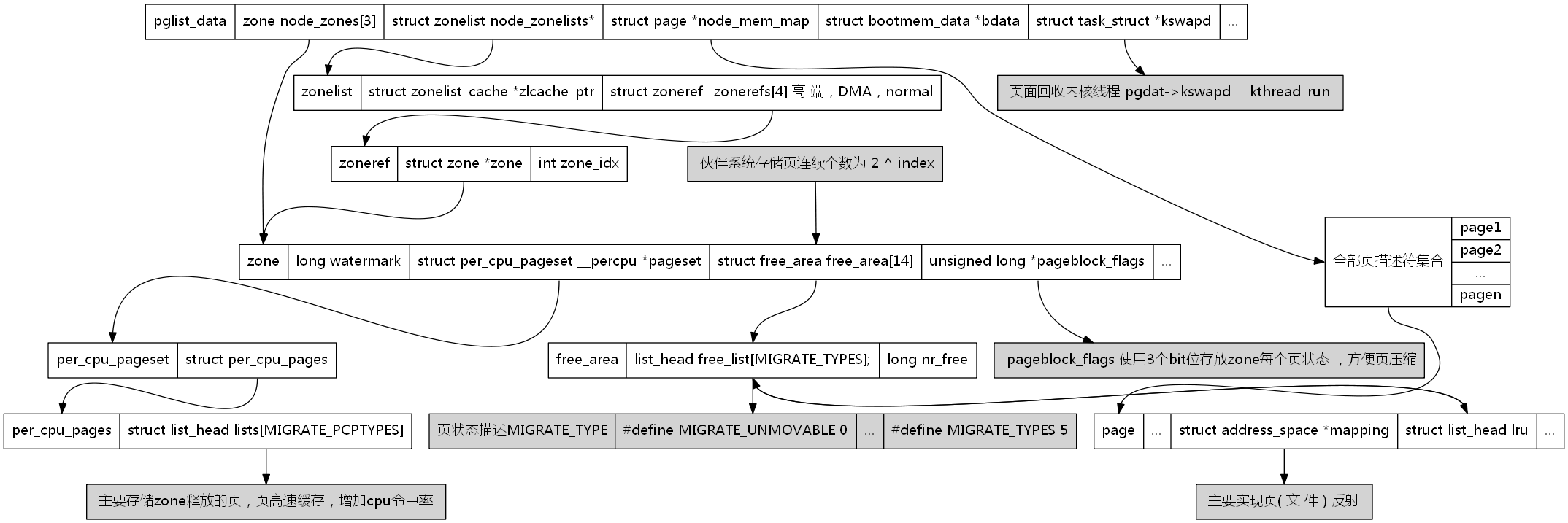
pglist_data结构主要组成 和 区域关系
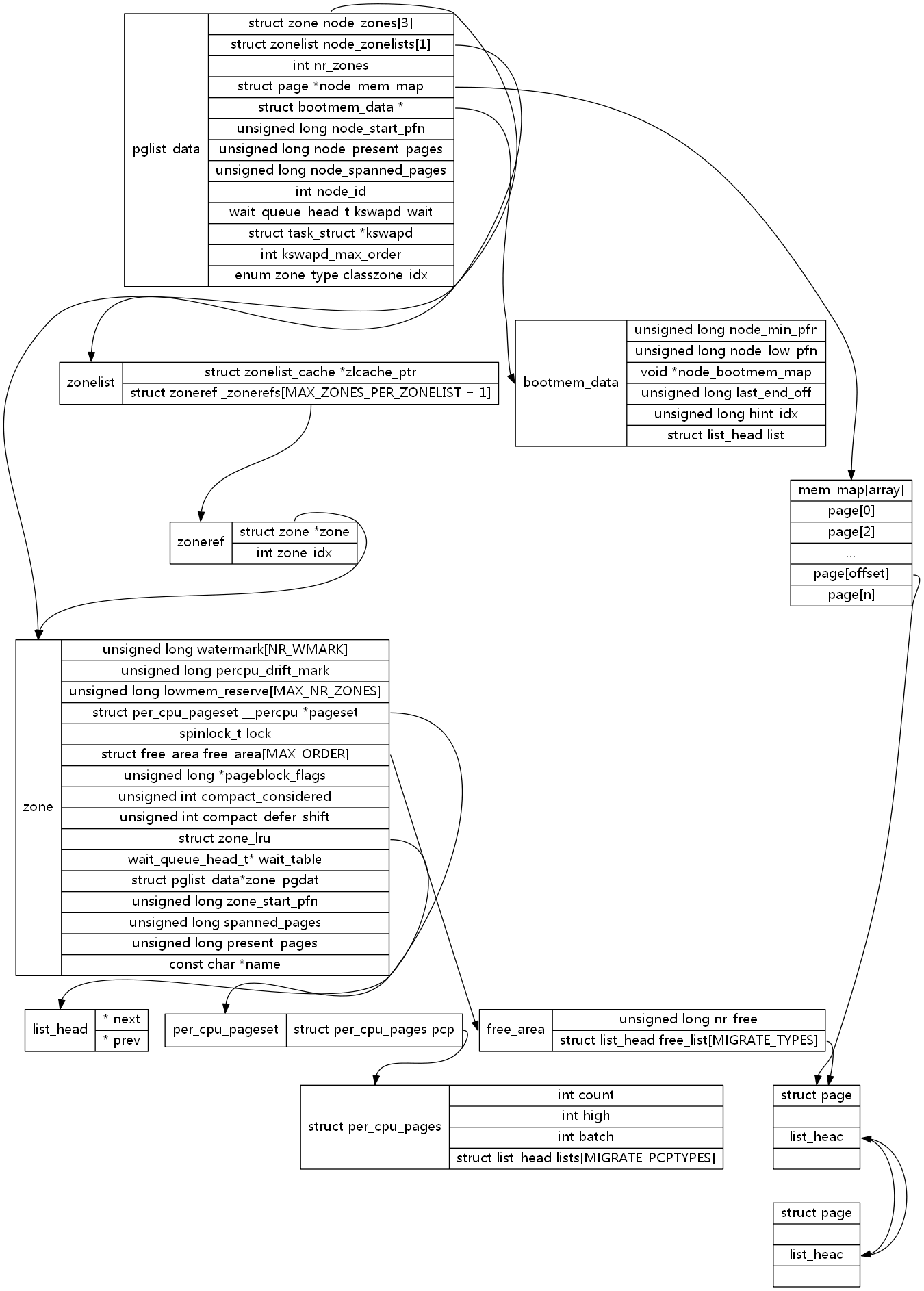
- node_zones 是一个数组,包含节点中各内存域(ZONE_DMA, ZONE_DMA32, ZONE_NORMAL...)的数据结构;
- node_zonelists 指定了节点的备用列表;
- nr_zones 指示了节点中不同内存域数目;
- node_mem_map 描述节点的所有物理内存页面。包含节点的所有内存域;
- bdata 系统启动自举内存分配器数据结构实例;
- node_start_pfn 当前NUMA节点第一页帧逻辑编号。在UMA总是0.
- node_present_pages 节点中页帧的数目;
- node_spanned_pages 节点以页帧为单位计算的数目。由于空洞的存在可能不等于node_present_pages,应该是大于等于node_present_pages;
- node_id 是全局节点ID;
- kswapd_wait: node的等待队列,交换守护列队进程的等待列表
- kswapd_max_order: 需要释放的区域的长度,以页阶为单位
1 enum zone_type { 2 #ifdef CONFIG_ZONE_DMA 3 ZONE_DMA, 4 #endif 5 #ifdef CONFIG_ZONE_DMA32 6 ZONE_DMA32, 7 #endif 8 ZONE_NORMAL, 9 #ifdef CONFIG_HIGHMEM 10 ZONE_HIGHMEM, 11 #endif 12 ZONE_MOVABLE, 13 __MAX_NR_ZONES 14 };
ZONE_DMA :是指可用于作 DMA(Direct Memory Access,直接内存存取)的内存。DMA 是这样一种机制:要把外设的数据读入内存或把内存的数据传送到外设,原来都要通过 CPU 控制完成,但是这会占用 CPU,影响 CPU 处理其他事情,所以有了 DMA 模式。CPU 只需向 DMA 控制器下达指令,让 DMA 控制器来处理数据的传送,数据传送完毕再把信息反馈给 CPU,这样就可以解放 CPU。
ZONE_NORMAL:
ZONE_HIGHMEM :是高端内存区,就是上一节讲的,对于 32 位系统来说超过 896M 的地方,对于 64 位没必要有的一段区域是直接映射区,就是上一节讲的,从物理内存到虚拟内存的内核区域,通过加上一个常量直接映射
ZONE_MOVABLE: 是可移动区域,通过将物理内存划分为可移动分配区域和不可移动分配区域来避免内存碎片
注意:上面对于区域的划分,都是针对物理内存的
页的分配
伙伴系统(Buddy System):
Linux 中的内存管理的“页”大小为 4KB。把所有的空闲页分组为 11 个页块链表,每个块链表分别包含很多个大小的页块,有 1、2、4、8、16、32、64、128、256、512 和 1024 个连续页的页块。最大可以申请 1024 个连续页,对应 4MB 大小的连续内存。每个页块的第一个页的物理地址是该页块大小的整数倍
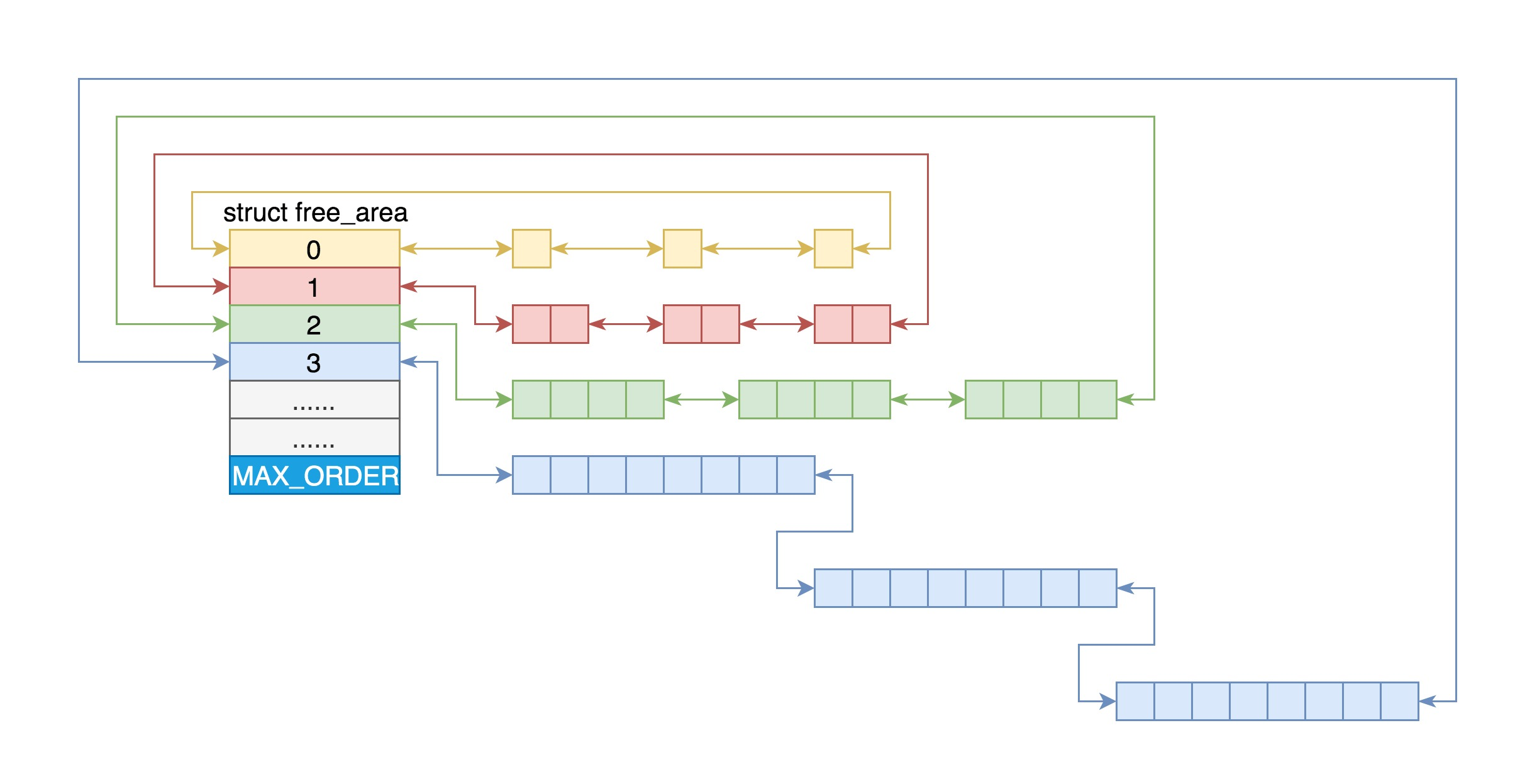
第 i 个页块链表中,页块中页的数目为 2^i
举例:要请求一个 128 个页的页块
1. 先检查 128 个页的页块链表是否有空闲块
2. 如果没有,则查 256 个页的页块链表;如果有空闲块的话,则将 256 个页的页块分成两份,一份使用,一份插入 128 个页的页块链表中。
3. 如果还是没有,就查 512 个页的页块链表;如果有的话,就分裂为 128、128、256 三个页块,一个 128 的使用,剩余两个插入对应页块链表。
源码分析:
1 static inline struct page * 2 alloc_pages(gfp_t gfp_mask, unsigned int order) 3 { 4 return alloc_pages_current(gfp_mask, order); 5 } 6 7 8 /** 9 * alloc_pages_current - Allocate pages. 10 * 11 * @gfp: 12 * %GFP_USER user allocation, 13 * %GFP_KERNEL kernel allocation, 14 * %GFP_HIGHMEM highmem allocation, 15 * %GFP_FS don't call back into a file system. 16 * %GFP_ATOMIC don't sleep. 17 * @order: Power of two of allocation size in pages. 0 is a single page. 18 * 19 * Allocate a page from the kernel page pool. When not in 20 * interrupt context and apply the current process NUMA policy. 21 * Returns NULL when no page can be allocated. 22 */ 23 struct page *alloc_pages_current(gfp_t gfp, unsigned order)//gfp 表示希望在哪个区域中分配这个内存 order:就是表示分配 2 的 order 次方个页 24 { 25 struct mempolicy *pol = &default_policy; 26 struct page *page; 27 ...... 28 page = __alloc_pages_nodemask(gfp, order, 29 policy_node(gfp, pol, numa_node_id()), 30 policy_nodemask(gfp, pol)); //伙伴系统的核心方法 31 ...... 32 return page; 33 }
1) __alloc_pages_nodemask -> get_page_from_freelist: 在一个循环中先看当前节点的 zone。如果找不到空闲页,则再看备用节点的 zone
2) 每一个 zone,都有伙伴系统维护的各种大小的队列,就像上面伙伴系统原理里讲的那样。这里调用 rmqueue 就很好理解了,就是找到合适大小的那个队列,把页面取下来
3) 接下来的调用链是 rmqueue->__rmqueue->__rmqueue_smallest: 在伙伴系统的 free_area 找 2^order 大小的页块。如果链表的第一个不为空,就找到了;如果为空,就到更大的 order 的页块链表里面去找
总结:
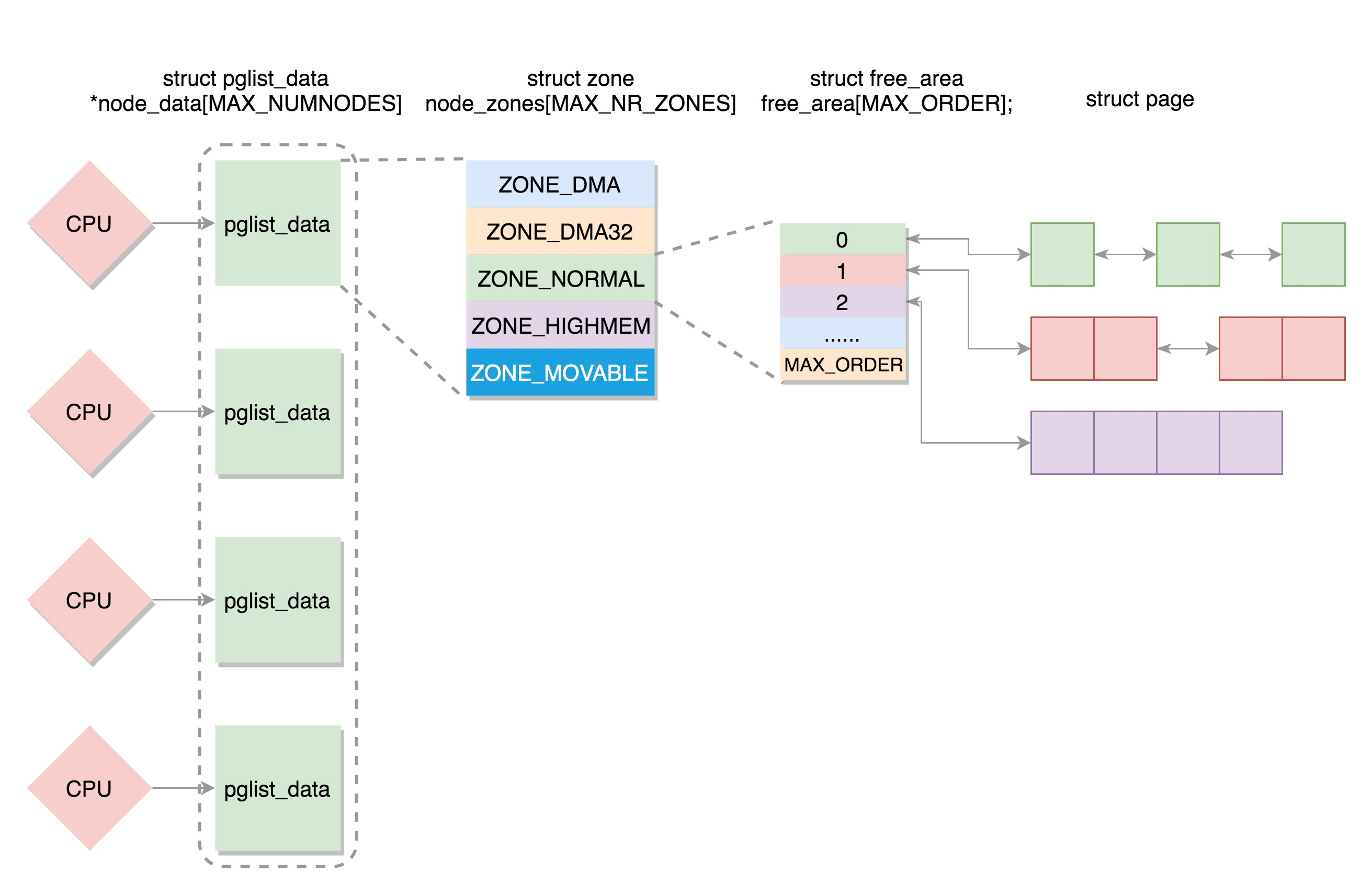
如果有多个 CPU,那就有多个节点。
每个节点用 struct pglist_data 表示,放在一个数组里面。
每个节点分为多个区域,每个区域用 struct zone 表示,也放在一个数组里面。
每个区域分为多个页。为了方便分配,空闲页放在 struct free_area 里面,使用伙伴系统进行管理和分配,每一页用 struct page 表示。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号