内存屏障理解
内存屏障缘由
1. 单处理器下的乱序问题
2. 多处理器下的内存同步问题
举例:
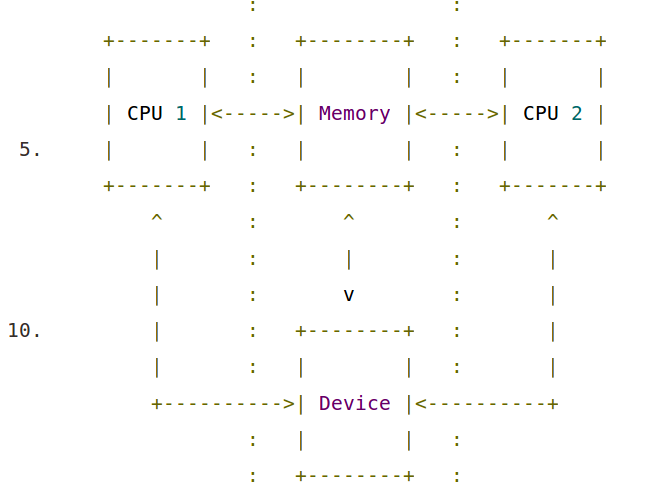
在如图的这种系统模型中,假设存在如下的内存访问操作:

由于处理器出于效率而引入的乱序执行(out-of-order execution)和缓存的关系, 对于内存来说, 最后x和y的值可以有如下组合:

因此,对于在操作系统这一层次编程的程序员来说,他们需要一个内存模型,以协调处理器间正确地使用共享内存,这个模型叫做内存一致性模型(memory consistency model)或简称内存模型(memory model)。
一种直观的内存模型叫做顺序一致性模型(sequential consistency model), 简单讲,顺序一致性模型保证两件事:
每个处理器(或线程)的执行顺序是按照最后汇编的二进制程序中指令的顺序来执行的,对于每个处理器(或线程),所有其他处理器(或线程)看到的执行顺序跟它的实际执行顺序一样。
这里的顺序有三种情况:
程序顺序(program order): 指给定的处理器上,程序最终编译后的二进制程序中的内存访问指令的顺序,因为编译器的优化可能会重排源程序中的指令顺序。执行顺序(execution order): 指给定的处理器上,内存访问指令的实际执行顺序。这可能由于处理器的乱序执行而与程序顺序不同。观察顺序(perceived order): 指给定的处理器上,其观察到的所有其他处理器的内存访问指令的实际执行顺序。这可能由于处理器的缓存及处理器间内存同步的优化而与执行顺序不同
何谓内存屏障
上文已经粗略描述了多处理架构下,为了提高并行度,充分挖掘处理器效率的做法会导致的一些与程序员期待的不同的执行结果的情况。本节更详细地描述这种情况, 即为何顺序一致性的模型难以保持的原因。
总的来说,在系统程序员关注的操作系统层面,会重排程序指令执行顺序的两个主要的来源是处理器优化和编译器优化。
内存屏障的种类
Linux内核实现的屏障种类有以下几种:
写屏障(write barriers)
-
定义: 在写屏障之前的所有写操作指令都会在写屏障之后的所有写操作指令更早发生。
-
注意1: 这种顺序性是相对这些动作的承接者,即内存来说。也就是说,在一个处理器上加入写屏障不能保证别的处理器上看到的就是这种顺序,也就是观察顺序与执行顺序无关。
-
注意2: 写屏障不保证屏障之前的所有写操作在屏障指令结束前结束。也就是说,写屏障序列化了写操作的发生顺序,却没保证操作结果发生的序列化。
读屏障(write barriers)
-
定义: 在读屏障之前的所有读操作指令都会在读屏障之后的所有读操作指令更早发生。另外,它还包含后文描述的数据依赖屏障的功能。
-
注意1: 这种顺序性是相对这些动作的承接者,即内存来说。也就是说,在一个处理器上加入读屏障不能保证别的处理器上实际执行的就是这种顺序,也就是观察顺序与执行顺序无关。
-
注意2: 读屏障不保证屏障之前的所有读操作在屏障指令结束前结束。也就是说,读屏障序列化了读操作的发生顺序,却没保证操作结果发生的序列化。
通用屏障(general barriers)
-
定义: 在通用屏障之前的所有写和读操作指令都会在通用屏障之后的所有写和读操作指令更早发生。
-
注意1: 这种顺序性是相对这些动作的承接者,即内存来说。也就是说,在一个处理器上加入通用屏障不能保证别的处理器上看到的就是这种顺序,也就是观察顺序与执行顺序无关。
-
注意2: 通用屏障不保证屏障之前的所有写和读操作在屏障指令结束前结束。也就是说,通用屏障序列化了写和读操作的发生顺序,却没保证操作结果发生的序列化。
-
注意3: 通用屏障是最严格的屏障,这也意味着它的低效率。它可以替换在写屏障或读屏障出现的地方。
数据依赖屏障(data dependency barriers):
volatile关键字
voldatile关键字特性:
1. 具有“易变性”: 声明为volatile变量编译器会强制要求读内存,相关语句不会直接使用上一条语句对应的的寄存器内容,而是重新从内存中读取。
2. 具有”不可优化”性: volatile告诉编译器,不要对这个变量进行各种激进的优化,甚至将变量直接消除,保证代码中的指令一定会被执行。
3. 具有“顺序性”: 能够保证Volatile变量间的顺序性,编译器不会进行乱序优化。不过要注意与非volatile变量之间的操作,还是可能被编译器重排序的。
需要注意的是其含义跟原子操作无关,比如:volatile int a; a++; 其中a++操作实际对应三条汇编指令实现”读-改-写“操作(RMW),并非原子的。
为什么要使用 Volatile
Volatile 变量修饰符如果使用恰当的话,它比 synchronized 的使用和执行成本会更低,因为它不会引起线程上下文的切换和调度。
Volatile 的实现原理
那么 Volatile 是如何来保证可见性的呢?在 x86 处理器下通过工具获取 JIT 编译器生成的汇编指令来看看对 Volatile 进行写操作 CPU 会做什么事情。
1 0x01a3de1d: movb $0x0,0x1104800(%esi); 2 0x01a3de24: lock addl $0x0,(%esp);
有 volatile 变量修饰的共享变量进行写操作的时候会多第二行汇编代码,通过查 IA-32 架构软件开发者手册可知,lock 前缀的指令在多核处理器下会引发了两件事情。
- 将当前处理器缓存行的数据会写回到系统内存。
- 这个写回内存的操作会引起在其他 CPU 里缓存了该内存地址的数据无效。
总结:
volatile的作用是防止编译器对访存指令做优化,例如,在一个线程的一段代码里要定期读一个变量a,根据读到的不同值做不同事情,但这个a的修改是在另一个线程里做的,那编译器可能就认为a没有被改过从而不是去每次从内存里去读新的a(把a放在一个临时寄存器里,每次读寄存器)。
用volatile关键字修饰a的作用就是让使用a的代码每次都真正从内存里去读。volatile的作用仅此而已(没有保证原子性之类的作用,保证原子性该加锁还是要加锁)。
为什么追加 64 字节能够提高并发编程的效率呢?
因为对于英特尔酷睿 i7,酷睿, Atom 和 NetBurst, Core Solo 和 Pentium M 处理器的 L1,L2 或 L3 缓存的高速缓存行是 64 个字节宽,不支持部分填充缓存行,这意味着如果队列的头节点和尾节点都不足 64 字节的话,处理器会将它们都读到同一个高速缓存行中,在多处理器下每个处理器都会缓存同样的头尾节点,当一个处理器试图修改头接点时会将整个缓存行锁定,那么在缓存一致性机制的作用下,会导致其他处理器不能访问自己高速缓存中的尾节点,而队列的入队和出队操作是需要不停修改头接点和尾节点,所以在多处理器的情况下将会严重影响到队列的入队和出队效率。Doug lea 使用追加到 64 字节的方式来填满高速缓冲区的缓存行,避免头接点和尾节点加载到同一个缓存行,使得头尾节点在修改时不会互相锁定。
参考:https://my.oschina.net/u/269082/blog/873612/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号