【转】TCP/IP 传输层拥塞控制算法
[转载]
1. 介绍
互联网协议套件是一个网络通信模型以及整个网络传输协议家族, 由于该协议簇包含两个核心协议: TCP(传输控制协议) 和 IP(网际协议), 因此常被通称为 TCP/IP 协议族 .
TCP/IP 协议对于数据应该如何封装, 定址, 传输, 路由以及在目的地如何接收等基本过程都加以标准化. 它将通信过程 抽象化为四个层次 , 并采取协议堆栈的方式分别实现出不同通信协议, 实际使用的四层结构是七层 OSI 模型的简化.
我们可以看到 TCP/IP 协议栈是一个简化的分层模型, 是互联网世界连接一切的基石, 一起来看一张 七层模型 vs 四层模型 的简图:
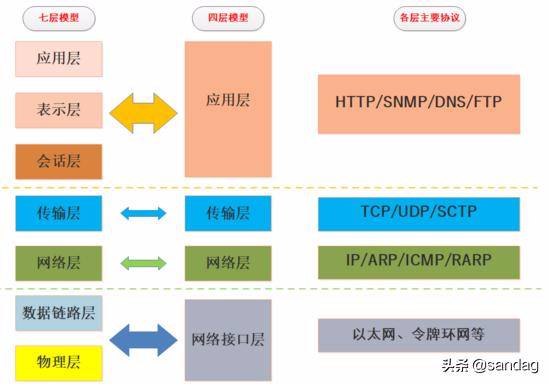
TCP/IP 协议栈过于庞大, 篇幅所限本文不再做更多细节的描述.
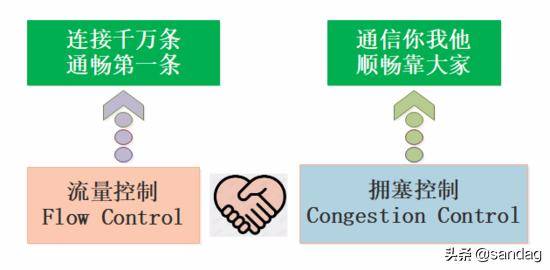
2. 流量控制和拥塞控制
TCP 是一种面向连接的, 可靠的, 全双工传输协议, 前辈们写了很多复杂的算法为其保驾护航, 其中有一组像海尔兄弟一样的算法: 流量控制和拥塞控制 , 这也是我们今天的主角.
2.1 流量控制简介
流量控制和拥塞控制从汉语字面上并不能很好的区分, 本质上这一对算法既有区别也有联系.
维基百科对于 流量控制 Flow Control 的说明:
- In data communications, flow control is the process of managing the rate of data transmission between two nodes to prevent a fast sender from overwhelming a slow receiver.
- It provides a mechanism for the receiver to control the transmission speed, so that the receiving node is not overwhelmed with data from transmitting node.
翻译一下:
在数据通信中, 流量控制是管理两个节点之间数据传输速率的过程, 以防止快速发送方压倒慢速接收方.
它为接收机提供了一种控制传输速度的机制, 这样接收节点就不会被来自发送节点的数据淹没.
可以看到流量控制是通信双方之间约定数据量的一种机制, 具体来说是借助于 TCP 协议的确认 ACK 机制和窗口协议来完成的.
窗口分为 固定窗口和可变窗口 , 可变窗口也就是 滑动窗口 , 简单来说就是通信双方根据接收方的接收情况动态告诉发送端可以发送的数据量, 从而实现发送方和接收方的数据 收发能力匹配 .
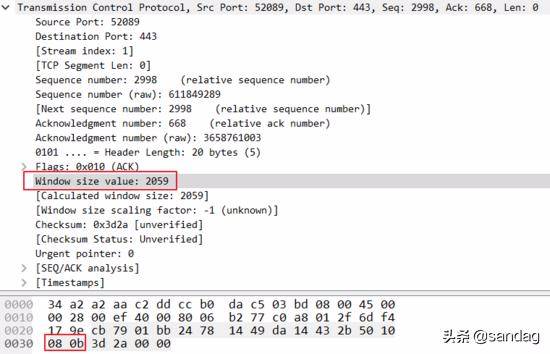
这个过程非常容易捕捉, 使用 wireshark 在电脑上抓或者 tcpdump 在服务器 上抓都可以看到, 大白在自己电脑上用 wireshark 抓了一条:
我们以两个主机交互来简单理解流量控制过程:
接收方回复报文头部解释:
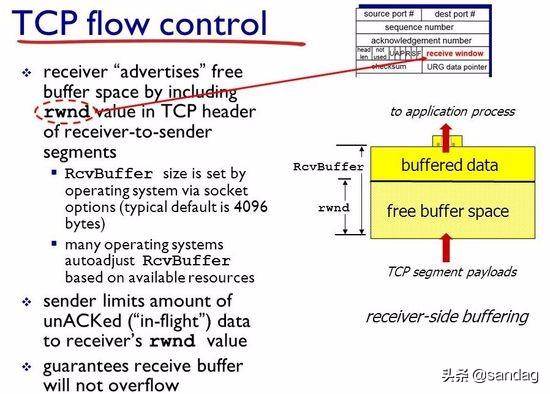
图中 RcvBuffer 是接收区总大小, buffered data 是当前已经占用的数据, 而 free buffer space 是当前剩余的空间, rwnd 的就是 free buffer space 区域的字节数.
HostB 把当前的 rwnd 值放入报文头部的接收窗口 receive Windows 字段中, 以此通知 HostA 自己还有多少可用空间, 而 HostA 则将未确认的数据量控制在 rwnd 值的范围内, 从而避免 HostB 的接收缓存溢出.
可见 流量控制是端到端微观层面的数据策略 , 双方在数据通信的过程中并不关心链路带宽情况, 只关心通信双方的接收发送缓冲区的空间大小, 可以说是个 速率流量匹配策略 .
流量控制就像现实生活中物流领域中 A 和 B 两个仓库, A 往 B 运送货物时只关心仓库 B 的剩余空间来调整自己的发货量, 而不关心高速是否拥堵.
2.2 拥塞控制的必要性
前面我们提到了微观层面点到点的流量控制, 但是我们不由地思考一个问题: 只有流量控制够吗? 答案是否定的.
我们还需要一个宏观层面的控去避免网络链路的拥堵, 否则再好的端到端流量控制算法也面临 丢包, 乱序, 重传 问题, 只能造成恶性循环.
我们从一个更高的角度去看 大量 TCP 连接复用网络链路 的通信过程:
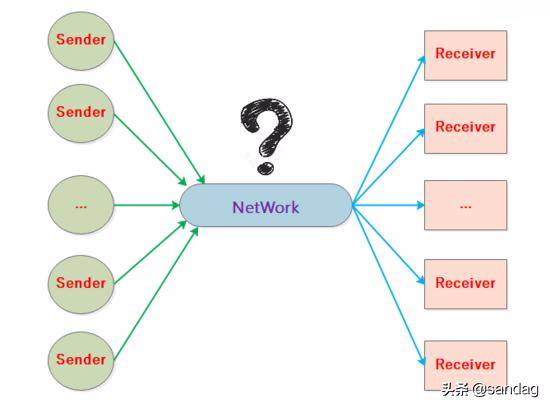
所以拥塞控制和每一条端到端的连接关系非常大, 这就是流量控制和拥塞控制的深层次联系, 所谓每一条连接都顺畅那么整个复杂的网络链路也很大程度是通畅的.
在展开拥塞控制之前我们先考虑几个问题:
如何感知拥塞
TCP 连接的发送方在向对端发送数据的过程中, 需要根据当前的网络状况来调整发送速率, 所以感知能力很关键.
在 TCP 连接的发送方一般是 基于丢包 来判断当前网络是否发生拥塞, 丢包可以由 重传超时 RTO 和重复确认 来做判断.
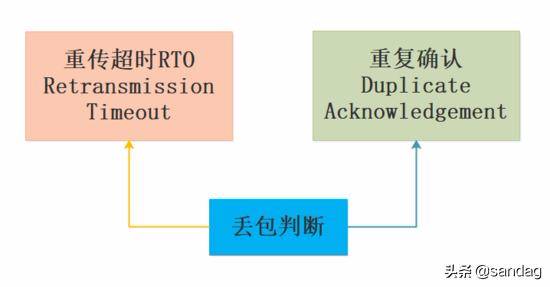
如何利用带宽
诚然拥塞影响很大, 但是一直低速发包对带宽利用率很低也是很不明智的做法, 因此要充分利用带宽就不能过低过高发送数据, 而是保持在一个动态稳定的速率来提高带宽利用率, 这个还是比较难的, 就像茫茫黑夜去躲避障碍物 .
拥塞时如何调整
拥塞发生时我们需要有一套应对措施来防止拥塞恶化并且恢复连接流量, 这也是拥塞控制算法的精要所在.
3. 理解拥塞控制
前面我们提了拥塞控制的必要性以及重要问题, 接下来一起看下前辈们是如何设计实现精彩的拥塞控制策略的吧!
3.1 拥塞窗口 cwnd
从流量控制可以知道接收方在 header 中给出了 rwnd 接收窗口大小, 发送方不能自顾自地按照接收方的 rwnd 限制来发送数据, 因为网络链路是复用的, 需要考虑当前链路情况来确定数据量, 这也是我们要提的另外一个变量 cwnd, 笔者找了一个关于 rwnd 和 cwnd 的英文解释:
- Congestion Windows (cwnd) is a TCP state variable that limits the amount of data the TCP can send into the network before receiving an ACK.
- The Receiver Windows (rwnd) is a variable that advertises the amount of data that the destination side can receive.
- Together, the two variables are used to regulate data flow in TCP connections, minimize congestion, and improve network performance.
笔者在 rfc5681 文档中也看到 cwnd 的定义:

这个解释指出了 cwnd 是在发送方维护的, cwnd 和 rwnd 并不冲突, 发送方需要结合 rwnd 和 cwnd 两个变量来发送数据, 如图所示:
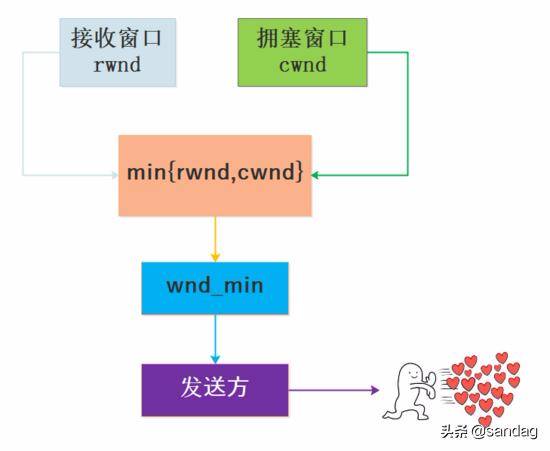
cwnd 的大小和 MSS 最大数据段有直接关系, MSS 是 TCP 报文段中的数据字段的最大长度, 即 MSS=TCP 报文段长度 - TCP 首部长度.
3.2 拥塞控制基本策略
拥塞控制是一个动态的过程 , 它既要提高带宽利用率发送尽量多的数据又要避免网络拥堵丢包 RTT 增大等问题, 基于这种高要求并不是单一策略可以搞定的, 因此 TCP 的拥塞控制策略实际上是 分阶段分策略的综合过程 :
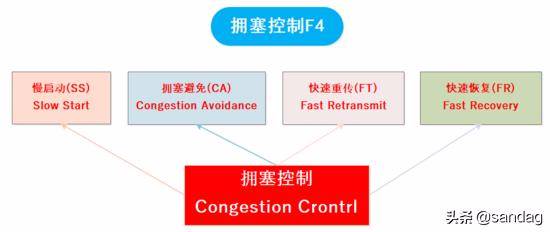
注: 有的版本的 TCP 算法不一定没有快速恢复阶段
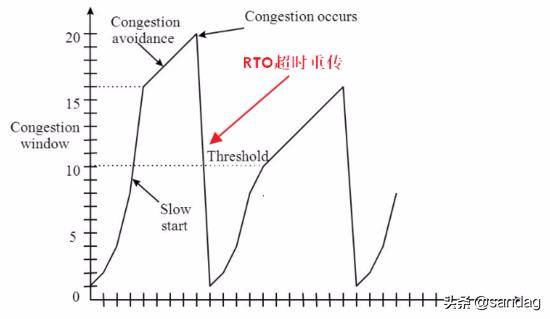
如图为典型的包含 4 个策略的拥塞控制:
如图为发生超时重传 RTO 时的过程:
3.3 TCP 算法常见版本
实际上 TCP 算法有很多版本, 每个版本存在一些差异, 在这里简单看一下维基百科的介绍:
算法命名规则
TCP + 算法名的命名方式最早出现在 Kevin Fall 和 Sally Floyd1996 年发布的论文中.
TCP Tahoe 和 TCP Reno
这两个算法代号取自太浩湖 Lake Tahoe 和里诺市, 两者算法大致一致, 对于丢包事件判断都是以重传超时 retransmission timeout 和重复确认为条件, 但是对于重复确认的处理两者有所不同, 对于 超时重传 RTO 情况两个算法都是将拥塞窗口降为 1 个 MSS , 然后进入慢启动阶段.
TCP Tahoe 算法 : 如果收到三次重复确认即第四次收到相同确认号的分段确认, 并且分段对应包无负载分段和无改变接收窗口的话, Tahoe 算法则进入快速重传, 将慢启动阈值改为当前拥塞窗口的一半, 将拥塞窗口降为 1 个 MSS, 并重新进入慢启动阶段.
TCP Reno 算法 : 如果收到三次重复确认, Reno 算法则进入快速重传只将拥塞窗口减半来跳过慢启动阶段, 将慢启动阈值设为当前新的拥塞窗口值, 进入一个称为快速恢复的新设计阶段.
TCP New Reno
TCP New Reno 是对 TCP Reno 中快速恢复阶段的重传进行改善的一种改进算法, New Reno 在低错误率时运行效率和选择确认 SACK 相当, 在高错误率仍优于 Reno.
TCP BIC 和 TCP CUBIC
TCP BIC 旨在优化高速高延迟网络的拥塞控制, 其拥塞窗口算法使用二分搜索算法尝试找到能长时间保持拥塞窗口最大值, Linux 内核在 2.6.8 至 2.6.18 使用该算法作为默认 TCP 拥塞算法 .
CUBIC 则是比 BIC 更温和和系统化的分支版本, 其使用三次函数代替二分算法作为其拥塞窗口算法, 并且使用函数拐点作为拥塞窗口的设置值, Linux 内核在 2.6.19 后使用该算法作为默认 TCP 拥塞算法 .
TCP PRR
TCP PRR 是旨在恢复期间提高发送数据的准确性, 该算法确保恢复后的拥塞窗口大小尽可能接近慢启动阈值. 在 Google 进行的测试中, 能将平均延迟降低 3~10% 恢复超时减少 5%, PRR 算法后作为 Linux 内核 3.2 版本默认拥塞算法 .
TCP BBR
TCP BBR 是由 Google 设计于 2016 年发布的拥塞算法 , 该算法认为随着网络接口控制器逐渐进入千兆速度时, 分组丢失不应该被认为是识别拥塞的主要决定因素, 所以基于模型的拥塞控制算法能有更高的吞吐量和更低的延迟, 可以用 BBR 来替代其他流行的拥塞算法.
Google 在 YouTube 上应用该算法, 将全球平均的 YouTube 网络吞吐量提高了 4%, BBR 之后移植入 Linux 内核 4.9 版本 .
3.4 拥塞控制过程详解
我们以典型 慢启动, 拥塞避免, 快速重传, 快速恢复 四个过程进行阐述.
慢启动
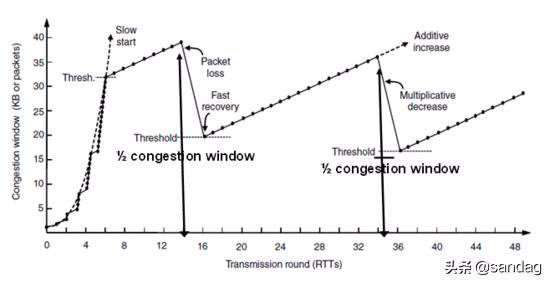
慢启动就是对于刚启动的网络连接, 发送速度不是一步到位而是试探性增长, 具体来说: 连接最初建立时发送方初始化拥塞窗口 cwnd 为 m, 之后发送方在一个 RTT 内 每收到一个 ACK 数据包时 cwnd 线性自增 1 , 发送方 每经过一个 RTT 时间, cwnd=cwnd*2 指数增长, 经过一段时间增长直到 cwnd 达到慢启动阈值 ssthresh.
之后 cwnd 不再呈指数增长从而进入拥塞避免阶段 (注 cwnd 增长的单位是 MSS), 当然如果在慢启动阶段还未到达阈值 ssthresh 而出现丢包时进入快速重传等阶段, 需要注意的是 如果网络状况良好 RTT 时间很短, 那么慢启动阶段将很快到达一个比较高的发送速率 , 所以将 慢启动理解为试探启动 更形象.
拥塞避免
当慢启动阶段 cwnd 的值到达 ssthresh 时就不再疯狂增长, 进入更加理性的线性阶段直至发送丢包, 本次的阈值 ssthresh 是上一次发生丢包时 cwnd 的 1/2, 因此这是一个承上启下的过程.
本次发送丢包时仍然会调整 ssthresh 的值, 具体拥塞避免增长过程: 发送方每收到一个 ACK 数据包时将 cwnd=cwnd+1/cwnd, 每经过一个 RTT 将 cwnd 自增 1 .
超时重传和快速重传
TCP 作为一个可靠的协议面临的很大的问题就是丢包, 丢包就要重传因此发送方需要根据接收方回复的 ACK 来确认是否丢包了, 并且发送方在发送数据之后启动定时器, 如图所示:
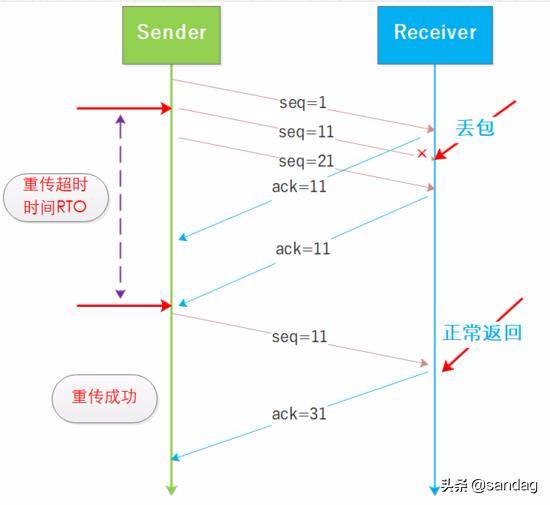
RTO 是随着复杂网络环境而动态变化的, 在拥塞控制中发生超时重传将会极大拉低 cwnd, 如果网络状况并没有那么多糟糕, 偶尔出现网络抖动造成丢包或者阻塞也非常常见 , 因此触发的慢启动将降低通信性能, 故出现了快速重传机制.
所谓 快速重传时相比超时重传而言的 , 重发等待时间会降低并且后续尽量避免慢启动, 来保证性能损失在最小的程度, 如图所示:
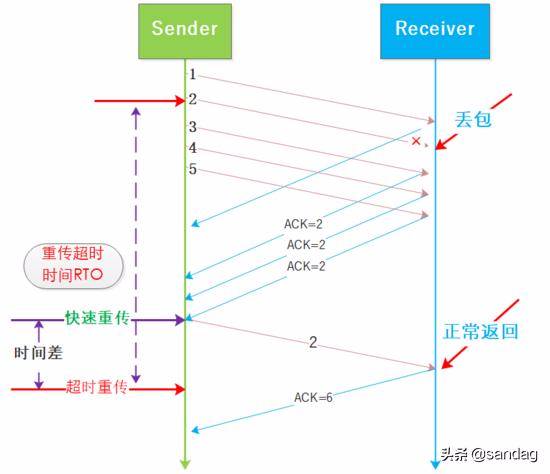
快速重传和超时重传的区别在于 cwnd 在发生拥塞时的取值, 超时重传会将 cwnd 修改为最初的值, 也就是慢启动的值, 快速重传将 cwnd 减半, 二者都将 ssthresh 设置为 cwnd 的一半 .
从二者的区别可以看到, 快速重传更加主动, 有利于保证链路的传输性能, 但是有研究表明 3 个 ACK 的机制同样存在问题, 本文就不做深入阐述了, 感兴趣的读者可以自主查阅.
快速重传是基于对网络状况没有那么糟糕的假设, 因此在实际网络确实还算好的时候, 快速重传还是很有用的, 在很差的网络环境很多算法都很难保证效率的.
快速恢复
在快速重传之后就会进入快速恢复阶段, 此时的 cwnd 为上次发生拥塞时的 cwnd 的 1/2, 之后 cwnd 再线性增加重复之前的过程.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号