DPDK同步互斥机制
参考资料:
《深入浅出DPDK》
DPDK官网:http://doc.dpdk.org/guides/prog_guide/
前言
前面章节我们已经对DPDK多核处理器做了分析,遵循资源局部化原则,解藕数据的跨核共享,使得性能可以有很好的水平扩展。但是,在实际情况下,CPU之间不同核的数据通信,数剧同步,临界区的保护等都是要面临的问题,这节主要准对这个问题来的
一. DPDK原子操作实现和应用
1)我们先介绍一下原子操作以及为什么DPDK中会用到原子操作
所谓原子操作,就是“不可中断的一个或一系列操作”。在单核心处理器系统中,能够在一条机器指令中完成的操作都可以认为是原子操作,因为中断只能发生于指令之间。这也是某些CPU指令系统中引入了test_and_set、test_and_clear等指令用于临界资源互斥的原因。
在对称多处理器(Symmetric Multi-Processor)结构中就不同了,由于系统中有多个处理器在独立地运行,即使能在单条指令中完成的操作也有可能受到干扰。
2)原子操作API
DPDK代码中提供了16,32和64位原子操作的API,以ret_atomic64_add() API源代码为例
二. DPDK无锁环形缓冲区
1) rte_ring 的数据结构定义
DPDK中的rte_ring的数据结构定义
1 /** 2 * An RTE ring structure. 3 * 4 * The producer and the consumer have a head and a tail index. The particularity 5 * of these index is that they are not between 0 and size(ring). These indexes 6 * are between 0 and 2^32, and we mask their value when we access the ring[] 7 * field. Thanks to this assumption, we can do subtractions between 2 index 8 * values in a modulo-32bit base: that's why the overflow of the indexes is not 9 * a problem. 10 */ 11 struct rte_ring { 12 /* 13 * Note: this field kept the RTE_MEMZONE_NAMESIZE size due to ABI 14 * compatibility requirements, it could be changed to RTE_RING_NAMESIZE 15 * next time the ABI changes 16 */ 17 char name[RTE_MEMZONE_NAMESIZE] __rte_cache_aligned; /**< Name of the ring. */ 18 int flags; /**< Flags supplied at creation. */ 19 const struct rte_memzone *memzone; 20 /**< Memzone, if any, containing the rte_ring */ 21 uint32_t size; /**< Size of ring. */ 22 uint32_t mask; /**< Mask (size-1) of ring. */ 23 uint32_t capacity; /**< Usable size of ring */ 24 25 char pad0 __rte_cache_aligned; /**< empty cache line */ 26 27 /** Ring producer status. */ 28 struct rte_ring_headtail prod __rte_cache_aligned; 29 char pad1 __rte_cache_aligned; /**< empty cache line */ 30 31 /** Ring consumer status. */ 32 struct rte_ring_headtail cons __rte_cache_aligned; 33 char pad2 __rte_cache_aligned; /**< empty cache line */ 34 };
2)环形缓冲区剖析
环形缓冲区支持队列管理。rte_ring并不是具有无限大小的链表,它具有如下属性:
- 先进先出(FIFO)
- 最大大小固定,指针存储在表中
- 无锁实现
- 多消费者或单消费者出队操作
- 多生产者或单生产者入队操作
- 批量出队 - 如果成功,将指定数量的元素出队,否则什么也不做
- 批量入队 - 如果成功,将指定数量的元素入队,否则什么也不做
- 突发出队 - 如果指定的数目出队失败,则将最大可用数目对象出队
- 突发入队 - 如果指定的数目入队失败,则将最大可入队数目对象入队
相比于链表,这个数据结构的优点如下:
- 更快;只需要一个sizeof(void *)的Compare-And-Swap指令,而不是多个双重比较和交换指令
- 与完全无锁队列像是
- 适应批量入队/出队操作。 因为指针是存储在表中的,应i多个对象的出队将不会产生于链表队列中一样多的cache miss。 此外,批量出队成本并不比单个对象出队高。
缺点:
- 大小固定
- 大量ring相比于链表,消耗更多的内存,空ring至少包含n个指针。
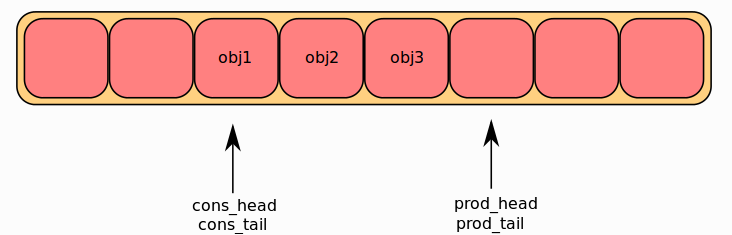
数据结构中存储的生产者和消费者头部和尾部指针显示了一个简化版本的ring。
3)linux 无锁缓冲区
参考:https://lwn.net/Articles/340400/
4)ring buffer解析
本节介绍ring buffer的运行方式。 Ring结构有两组头尾指针组成,一组被生产者调用,一组被消费者调用。 以下将简单称为 prod_head、prod_tail、cons_head 及 cons_tail。
每个图代表了ring的简化状态,是一个循环缓冲器。 本地变量的内容在图上方表示,Ring结构的内容在图下方表示。
4.1) 单生产者入队
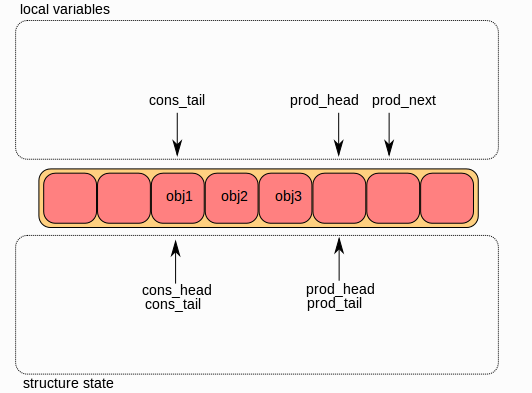
本节介绍了一个生产者向队列添加对象的情况。 在本例中,只有生产者头和尾指针(prod_head and prod_tail)被修改,只有一个生产者。
初始状态是将prod_head 和 prod_tail 指向相同的位置。
第一步:
首先, ring->prod_head 和 ring->cons_tail*复制到本地变量中。 *prod_next 本地变量指向下一个元素,或者,如果是批量入队的话,指向下几个元素。
如果ring中没有足够的空间存储元素的话(通过检查cons_tail来确定),则返回错误。
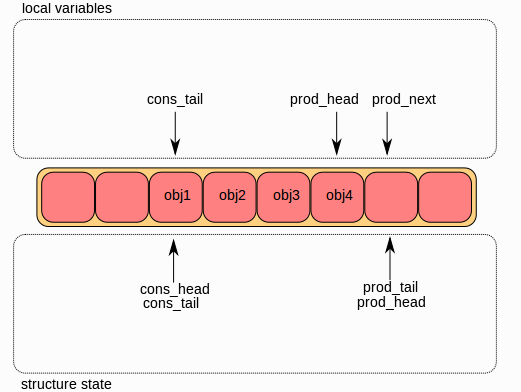
第二步:
第二步是在环结构中修改 ring->prod_head,以指向与prod_next相同的位置。
指向待添加对象的指针被复制到ring中。

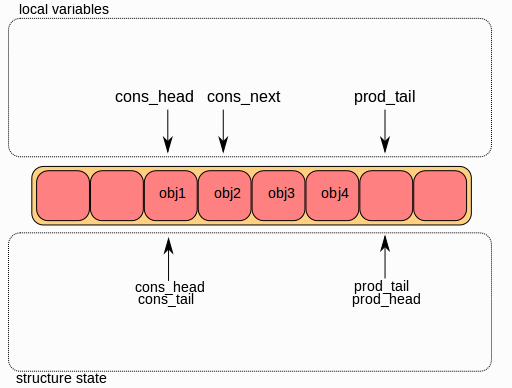
第三步:
一旦将对象添加到ring中,ring结构中的 ring->prod_tail 将被修改,指向与 ring->prod_head 相同的位置。 入队操作完成。
4.2)单消费者出列
第一步
首先,将 ring->cons_head 和 ring->prod_tail*复制到局部变量中。 *cons_next 本地变量指向表的下一个元素,或者在批量出队的情况下指向下几个元素。
如果ring中没有足够的对象用于出队(通过检查prod_tail),将返回错误。
第二步:
第二步是修改ring结构中 ring->cons_head,以指向cons_next相同的位置。
指向出队对象(obj1) 的指针被复制到用户指定的指针中。
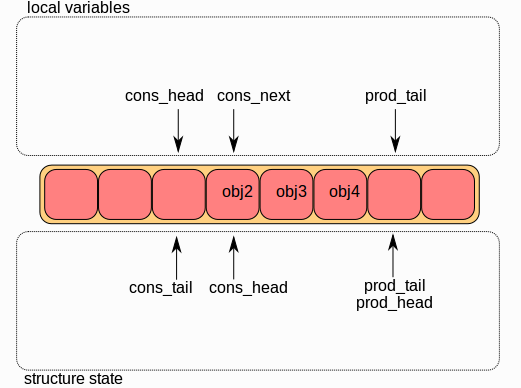
第三步:
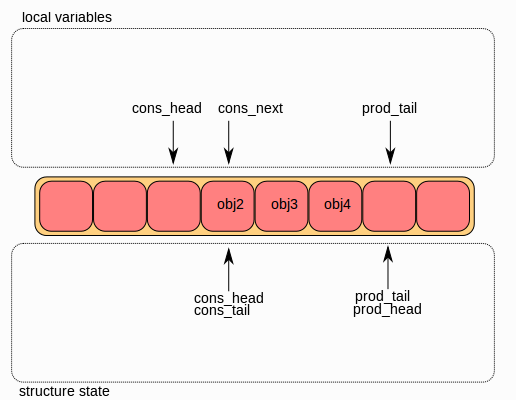
最后,ring中的ring->cons_tail被修改为指向ring->cons_head相同的位置。 出队操作完成
4.3 多生产者
本节说明两个生产者同时向ring中添加对象的情况。 在本例中,仅修改生产者头尾指针(prod_head and prod_tail)。
初始状态是将prod_head 和 prod_tail 指向相同的位置。
4.3.1. 多生产者入队第一步
在生产者的两个core上, ring->prod_head 及 ring->cons_tail 都被复制到局部变量。 局部变量prod_next指向下一个元素,或者在批量入队的情况下指向下几个元素。
如果ring中没有足够的空间用于入队(通过检查cons_tail),将返回错误。

Fig. 4.9 Multiple producer enqueue first step
4.3.2. 多生产者入队第二步
第二步是修改ring结构中 ring->prod_head ,来指向prod_next相同的位置。 此操作使用比较和交换(CAS)指令,该指令以原子操作的方式执行以下操作:
- 如果ring->prod_head 与本地变量prod_head不同,则CAS操作失败,代码将在第一步重新启动。
- 否则,ring->prod_head设置为本地变量prod_next,CAS操作成功并继续下一步处理。
在图中,core1执行成功,core2重新启动。

Fig. 4.10 Multiple producer enqueue second step
4.3.3. 多生产者入队第三步
Core 2的CAS操作成功重试。
Core 1更新一个对象(obj4)到ring上。Core 2更新一个对象(obj5)到ring上

Fig. 4.11 Multiple producer enqueue third step
4.3.4. 多生产者入队地四步
每个core现在都想更新 ring->prod_tail。 只有ring->prod_tail等于prod_head本地变量,core才能更新它。 当前只有core 1满足,操作在core 1上完成。

Fig. 4.12 Multiple producer enqueue fourth step
4.3.5. 多生产者入队最后一步
一旦ring->prod_tail被core 1更新完,core 2也满足条件,允许更新。 Core 2上也完成了操作。

Fig. 4.13 Multiple producer enqueue last step
4.4.4. 32-bit取模索引
在前面的途中,prod_head, prod_tail, cons_head 和 cons_tail索引由箭头表示。 但是,在实际实现中,这些值不会假定在0和 size(ring)-1 之间。 索引值在 0 ~ 2^32 -1之间,当我们访问ring本身时,我们屏蔽他们的值。 32bit模数也意味着如果溢出32bit的范围,对索引的操作将自动执行2^32 模。
以下是两个例子,用于帮助解释索引值如何在ring中使用。
Note
为了简化说明,使用模16bit操作,而不是32bit。 另外,四个索引被定义为16bit无符号整数,与实际情况下的32bit无符号数相反。

Fig. 4.14 Modulo 32-bit indexes - Example 1
这个ring包含11000对象。

Fig. 4.15 Modulo 32-bit indexes - Example 2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号