C++ 对象内存模型
1. 先看一下整体代码的内存布局

from:https://manybutfinite.com/post/anatomy-of-a-program-in-memory/
2. 简单用个实例来体现程序中各个变量的内存位置(引用于《C专家编程》截图)
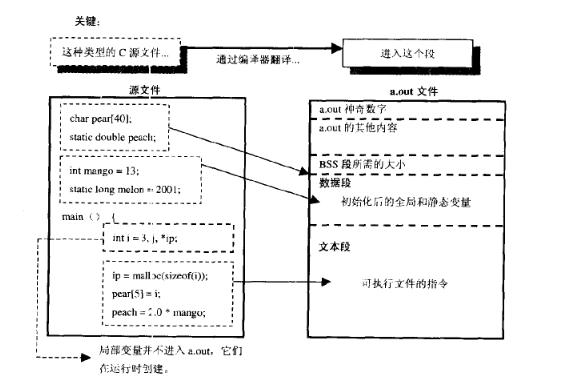
我们这边着重讲一下堆(heap),栈(stack)
- 堆(heap):堆是用于存放进程执行中被动态分配的内存段。它的大小并不固定,可动态扩张或缩减。当进程调用malloc等函数分配内存时。新分配的内存就被动态加入到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)
- 栈(stack):栈又称堆栈, 是用户存放程序暂时创建的局部变量,也就是说我们函数括弧“{}”中定义的变量(但不包含static声明的变量。static意味着在数据段中存放变量)
这里说个我自己困扰很久的问题,就是为什么堆是向上增长而栈向下增长????
也是网上搜到的个人觉得比较有说服力的解释:
历史原因:堆和栈的相向生长
在没有MMU的时代,为了最大的利用内存空间,堆和栈被设计为从两端相向生长。那么哪一个向上,哪一个向下呢?
人们对数据访问是习惯于向上的,比如你在堆中new一个数组,是习惯于把低元素放到低地址,把高位放到高地址,所以堆向上生长比较符合习惯。而栈则对方向不敏感,一般对栈的操作只有PUSH和pop,无所谓向上向下,所以就把堆放在了低端,把栈放在了高端
存储器的低端分配给堆栈使用,当堆栈指针减到0时就会产生堆栈溢出,检测堆栈指针是否为0是很容易实现的,在有MMU的情况下,页面越界即为堆栈溢出;若堆栈向高地址增长,在有MMU的情况下,亦可根据页面越界判断堆栈溢出,但无MMU时则不易实现,因为堆栈顶端可以随时变化。
这样设计可以使得堆和栈能够充分利用空闲的地址空间。如果栈向上涨的话,我们就必须得指定栈和堆的一个严格分界线,但这个分界线怎么确定呢?平均分?但是有的程序使用的堆空间比较多,而有的程序使用的栈空间比较多。所以就可能出现这种情况:一个程序因为栈溢出而崩溃的时候,其实它还有大量闲置的堆空间呢,但是我们却无法使用这些闲置的堆空间。所以呢,最好的办法就是让堆和栈一个向上涨,一个向下涨,这样它们就可以最大程度地共用这块剩余的地址空间,达到利用率的最大化!!
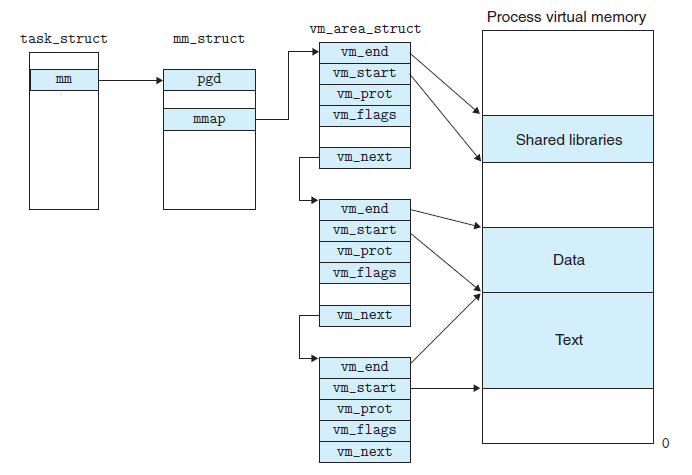
3. 虚拟内存内部实现
4. C++几种对象内存模型介绍(from:https://tangocc.github.io/2018/03/20/cpp-class-memory-struct/)
4.1 无继承
Class Base { public: int a; int b; virtual void function(); }
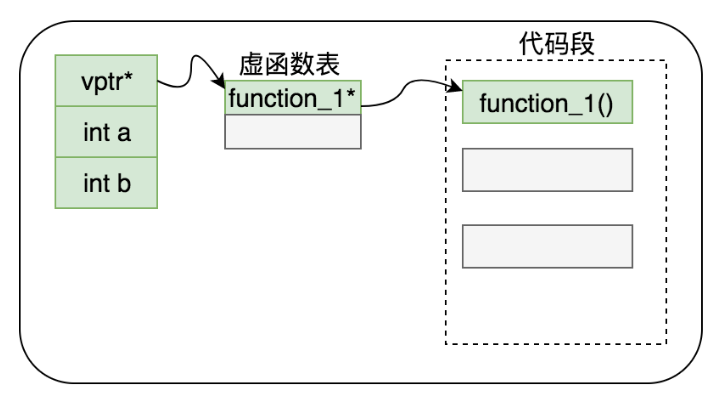
如上图所示,对于无继承状态的C++布局:
1)首先是虚函数表指针,该指针是由编译器 定义和初始化(编译阶段,编译器在构造函数内增加代码实现)
2)成员函数代码存储在 代码段,堆上构造虚函数表,将虚成员函数的地址存储在虚函数内。
3)数据成员按照声明的顺序布局;
4.2 单继承
Class Base {
public:
int a;
int b;
virtual void function();
}
Class Derive : public Base {
public:
int c;
virtual void function_2();
}

如上图所示,对于无继承状态的C++布局:
1) 首先是基类虚函数表指针
2) 基类数据成员
3) 子类数据成员
4) 子类实现基类的虚函数,并覆盖基类虚函数表中相应的函数的地址
5) 子类扩展基类的虚函数表,将子类的虚函数地址存储在基类虚函数表中
6) 内存中只存在一张虚函数表
4.3 多继承
Class Base1 {
public:
int a;
int b;
virtual void function_1();
}
Class Base2 {
public:
int c;
virtual void function_2();
}
Class Derive : public Base1,public Base2 {
public:
int d;
virtual void function_3();
}
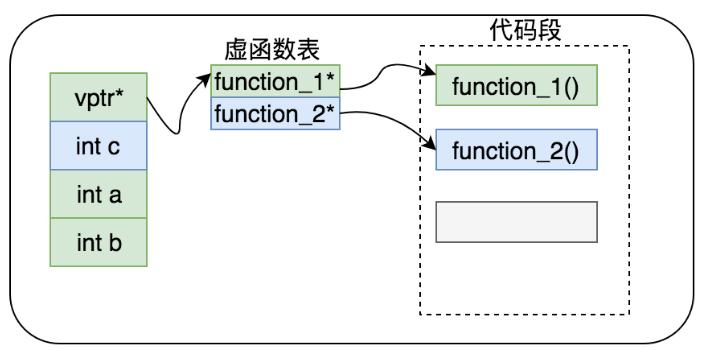
如上图所示,对于无继承状态的C++布局:
1) 首先是基类1虚函数表指针
2) 基类1数据成员
3) 基类2虚函数表指针
4) 基类2数据成员
5) 子类数据成员
6) 子类实现基类的虚函数,并覆盖基类虚函数表中相应的函数的地址
7) 子类扩展第一个基类的虚函数表,将子类的虚函数地址存储在基类虚函数表中
8) 内存中存在2张虚函数表
5. C++内存问题及常用的解决方法
5.1. 内存管理功能问题
由于C++语言对内存有主动控制权,内存使用灵活和效率高,但代价是不小心使用就会导致以下内存错误:
• memory overrun:写内存越界
• double free:同一块内存释放两次
• use after free:内存释放后使用
• wild free:释放内存的参数为非法值
• access uninitialized memory:访问未初始化内存
• read invalid memory:读取非法内存,本质上也属于内存越界
• memory leak:内存泄露
• use after return:caller访问一个指针,该指针指向callee的栈内内存
• stack overflow:栈溢出
常用的解决内存错误的方法
- 代码静态检测
静态代码检测是指无需运行被测代码,通过词法分析、语法分析、控制流、数据流分析等技术对程序代码进行扫描,找出代码隐藏的错误和缺陷,如参数不匹配,有歧义的嵌套语句,错误的递归,非法计算,可能出现的空指针引用等等。统计证明,在整个软件开发生命周期中,30%至70%的代码逻辑设计和编码缺陷是可以通过静态代码分析来发现和修复的。在C++项目开发过程中,因为其为编译执行语言,语言规则要求较高,开发团队往往要花费大量的时间和精力发现并修改代码缺陷。所以C++静态代码分析工具能够帮助开发人员快速、有效的定位代码缺陷并及时纠正这些问题,从而极大地提高软件可靠性并节省开发成本。
静态代码分析工具的优势:
1、自动执行静态代码分析,快速定位代码隐藏错误和缺陷。
2、帮助代码设计人员更专注于分析和解决代码设计缺陷。
3、减少在代码人工检查上花费的时间,提高软件可靠性并节省开发成本。
一些主流的静态代码检测工具:
免费的cppcheck,clang static analyzer;商用的coverity,pclint等
各个工具性能对比: http://www.51testing.com/html/19/n-3709719.html
- 代码动态检测
所谓的代码动态检测,就是需要再程序运行情况下,通过插入特殊指令,进行动态检测和收集运行数据信息,然后分析给出报告。
1. 为了检测内存非法使用,需要hook内存分配和操作函数。hook的方法可以是用C-preprocessor,也可以是在链接库中直接定义(因为Glibc中的malloc/free等函数都是weak symbol),或是用LD_PRELOAD。另外,通过hook strcpy(),memmove()等函数可以检测它们是否引起buffer overflow。
2. 为了检查内存的非法访问,需要对程序的内存进行bookkeeping,然后截获每次访存操作并检测是否合法。bookkeeping的方法大同小异,主要思想是用shadow memory来验证某块内存的合法性。至于instrumentation的方法各种各样。有run-time的,比如通过把程序运行在虚拟机中或是通过binary translator来运行;或是compile-time的,在编译时就在访存指令时就加入检查操作。另外也可以通过在分配内存前后加设为不可访问的guard page,这样可以利用硬件(MMU)来触发SIGSEGV,从而提高速度。
3. 为了检测栈的问题,一般在stack上设置canary,即在函数调用时在栈上写magic number或是随机值,然后在函数返回时检查是否被改写。另外可以通过mprotect()在stack的顶端设置guard page,这样栈溢出会导致SIGSEGV而不至于破坏数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号