AdaBoost分类算法
AdaBoost:Adaptive Boosting(自适应提升),是Boosting系列算法的典型代表。AdaBoost简单来讲,就是多个弱分类器,可能基于单层决策树,也可能基于其他算法;前一个弱分类器得到一个分类结果,根据它的错误率给这个分类器一个权重,还要更新样本的权重;基于这个权重矩阵,再去训练出下一个弱分类器,依次循环,直到错误率为0或者收敛,就得到了一系列弱分类器;将这些弱分类器的结果加权求和,组成一个强分类器,能得到一个较为准确的分类结果。
既然是boosting家族的一员,那么AdaBoost如何解决Boosting中的两个问题:
1.每一轮如何改变训练数据的权重,以获取不同的弱分类器?
AdaBoost会提高被前一轮弱分类器错误分类样本的权值,降低被正确分类样本的权值。
2.如何将弱分类器组合成一个强分类器?
AdaBoost通过加权表决,加大分类误差率小的弱分类器的权值,使其在表决中起较大的作用,减小分类误差率大的弱分类器的权值,使其在表决中起较小的作用。
Adaboost算法流程:
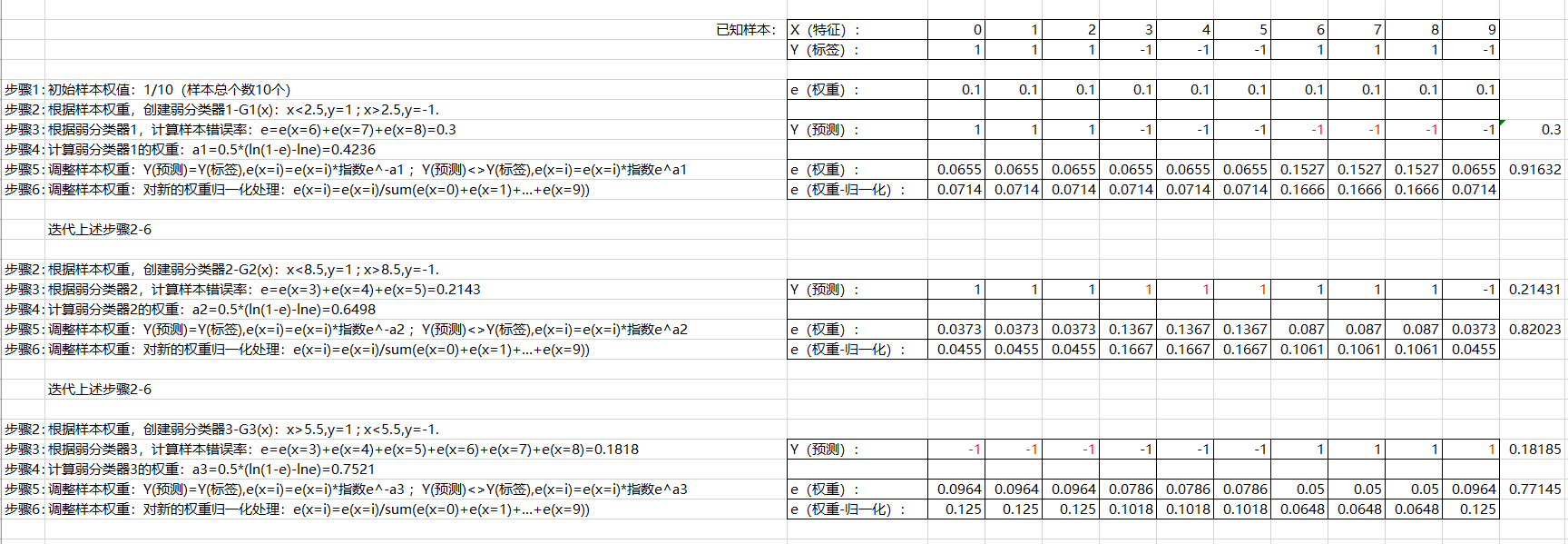
1)给数据中的每一个样本赋初始权重:1/样本总个数
2)训练数据中的每一个样本,得到第一个分类器:G1(x)
3) 根据第一个分类器的预测结果,计算该分类器的错误率:e=sum(所有错误样本的权重)
4)根据错误率计算该分类器的权重:a1=0.5*(ln(1-e)-lne)
5)根据分类器权重、预测结果、样本原权重,计算样本新权重。分错的样本权重增加,分对的样本权重减小:
Y(预测)=Y(标签),新权重=原权重*指数e^-a1;Y(预测)<>Y(标签),新权重=原权重*指数e^a1
6)对样本新权重归一化处理:样本新权重/sum(所有样本新权重)
重复上述步骤2~6,直到步骤3中分类器错误率达到收敛状态,或者达到迭代次数T次,迭代结束。
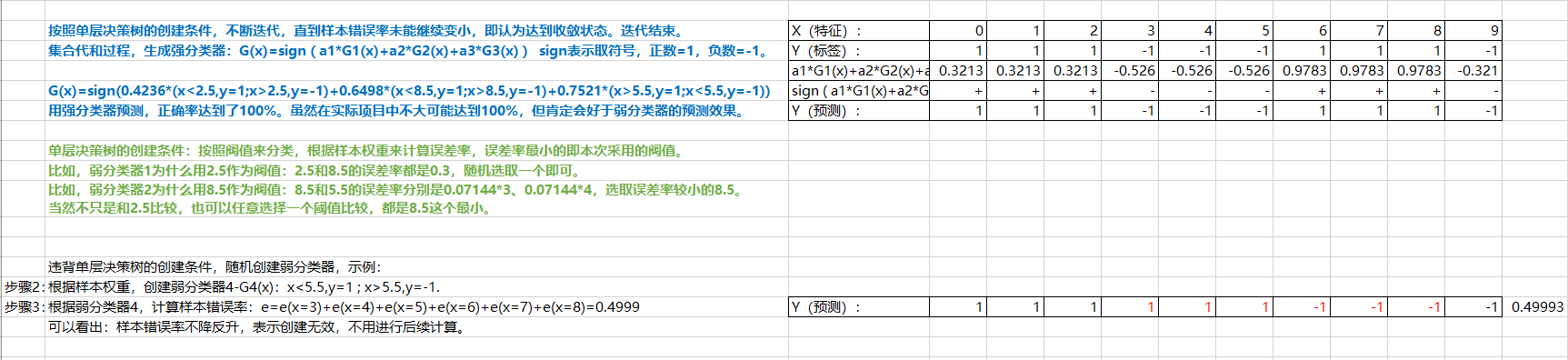
将所有弱分类器加权求和,得到强分类器:G(x)=sign(f(x)) f(x)=a1*G1(x)+a2*G2(x)+a3*G3(x)
sign表示取符号,正数=1,负数=-1,表示二分类1/-1结果。f(x)的绝对值可以看作是确信率。
示例:
AdaBoost中使用最多的弱分类器是单层决策树:只有一层条件判断,结果是-1或1。下面就以最简单的单层决策树分类示例,阐述AdaBoost对弱分类器的迭代加强、生成强分类器和理想预测结果的过程。
学习参考:
